 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
Sep 14, 2023



The rapid advancement of artificial intelligence (AI) technology has led to the prioritization of standardizing the processing, coding, and transmission of video using neural networks. To address this priority area, the Moving Picture, Audio, and Data Coding by Artificial Intelligence (MPAI) group is developing a suite of standards called MPAI-EEV for "end-to-end optimized neural video coding." The aim of this AI-based video standard project is to compress the number of bits required to represent high-fidelity video data by utilizing data-trained neural coding technologies. This approach is not constrained by how data coding has traditionally been applied in the context of a hybrid framework. This paper presents an overview of recent and ongoing standardization efforts in this area and highlights the key technologies and design philosophy of EEV. It also provides a comparison and report on some primary efforts such as the coding efficiency of the reference model. Additionally, it discusses emerging activities such as learned Unmanned-Aerial-Vehicles (UAVs) video coding which are currently planned, under development, or in the exploration phase. With a focus on UAV video signals, this paper addresses the current status of these preliminary efforts. It also indicates development timelines, summarizes the main technical details, and provides pointers to further points of reference. The exploration experiment shows that the EEV model performs better than the state-of-the-art video coding standard H.266/VVC in terms of perceptual evaluation metric.
Extreme Image Compression using Fine-tuned VQGAN Models
Aug 07, 2023



Recent advances in generative compression methods have demonstrated remarkable progress in enhancing the perceptual quality of compressed data, especially in scenarios with low bitrates. Nevertheless, their efficacy and applicability in achieving extreme compression ratios ($<0.1$ bpp) still remain constrained. In this work, we propose a simple yet effective coding framework by introducing vector quantization (VQ)-based generative models into the image compression domain. The main insight is that the codebook learned by the VQGAN model yields strong expressive capacity, facilitating efficient compression of continuous information in the latent space while maintaining reconstruction quality. Specifically, an image can be represented as VQ-indices by finding the nearest codeword, which can be encoded using lossless compression methods into bitstreams. We then propose clustering a pre-trained large-scale codebook into smaller codebooks using the K-means algorithm. This enables images to be represented as diverse ranges of VQ-indices maps, resulting in variable bitrates and different levels of reconstruction quality. Extensive qualitative and quantitative experiments on various datasets demonstrate that the proposed framework outperforms the state-of-the-art codecs in terms of perceptual quality-oriented metrics and human perception under extremely low bitrates.
SpikeCodec: An End-to-end Learned Compression Framework for Spiking Camera
Jun 25, 2023



Recently, the bio-inspired spike camera with continuous motion recording capability has attracted tremendous attention due to its ultra high temporal resolution imaging characteristic. Such imaging feature results in huge data storage and transmission burden compared to that of traditional camera, raising severe challenge and imminent necessity in compression for spike camera captured content. Existing lossy data compression methods could not be applied for compressing spike streams efficiently due to integrate-and-fire characteristic and binarized data structure. Considering the imaging principle and information fidelity of spike cameras, we introduce an effective and robust representation of spike streams. Based on this representation, we propose a novel learned spike compression framework using scene recovery, variational auto-encoder plus spike simulator. To our knowledge, it is the first data-trained model for efficient and robust spike stream compression. Extensive experimental results show that our method outperforms the conventional and learning-based codecs, contributing a strong baseline for learned spike data compression.
Optimization-Inspired Cross-Attention Transformer for Compressive Sensing
Apr 27, 2023



By integrating certain optimization solvers with deep neural networks, deep unfolding network (DUN) with good interpretability and high performance has attracted growing attention in compressive sensing (CS). However, existing DUNs often improve the visual quality at the price of a large number of parameters and have the problem of feature information loss during iteration. In this paper, we propose an Optimization-inspired Cross-attention Transformer (OCT) module as an iterative process, leading to a lightweight OCT-based Unfolding Framework (OCTUF) for image CS. Specifically, we design a novel Dual Cross Attention (Dual-CA) sub-module, which consists of an Inertia-Supplied Cross Attention (ISCA) block and a Projection-Guided Cross Attention (PGCA) block. ISCA block introduces multi-channel inertia forces and increases the memory effect by a cross attention mechanism between adjacent iterations. And, PGCA block achieves an enhanced information interaction, which introduces the inertia force into the gradient descent step through a cross attention block. Extensive CS experiments manifest that our OCTUF achieves superior performance compared to state-of-the-art methods while training lower complexity. Codes are available at https://github.com/songjiechong/OCTUF.
Machine Perception-Driven Image Compression: A Layered Generative Approach
Apr 14, 2023



In this age of information, images are a critical medium for storing and transmitting information. With the rapid growth of image data amount, visual compression and visual data perception are two important research topics attracting a lot attention. However, those two topics are rarely discussed together and follow separate research path. Due to the compact compressed domain representation offered by learning-based image compression methods, there exists possibility to have one stream targeting both efficient data storage and compression, and machine perception tasks. In this paper, we propose a layered generative image compression model achieving high human vision-oriented image reconstructed quality, even at extreme compression ratios. To obtain analysis efficiency and flexibility, a task-agnostic learning-based compression model is proposed, which effectively supports various compressed domain-based analytical tasks while reserves outstanding reconstructed perceptual quality, compared with traditional and learning-based codecs. In addition, joint optimization schedule is adopted to acquire best balance point among compression ratio, reconstructed image quality, and downstream perception performance. Experimental results verify that our proposed compressed domain-based multi-task analysis method can achieve comparable analysis results against the RGB image-based methods with up to 99.6% bit rate saving (i.e., compared with taking original RGB image as the analysis model input). The practical ability of our model is further justified from model size and information fidelity aspects.
Diffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation
Mar 21, 2023



In this paper, a novel Diffusion-based 3D Pose estimation (D3DP) method with Joint-wise reProjection-based Multi-hypothesis Aggregation (JPMA) is proposed for probabilistic 3D human pose estimation. On the one hand, D3DP generates multiple possible 3D pose hypotheses for a single 2D observation. It gradually diffuses the ground truth 3D poses to a random distribution, and learns a denoiser conditioned on 2D keypoints to recover the uncontaminated 3D poses. The proposed D3DP is compatible with existing 3D pose estimators and supports users to balance efficiency and accuracy during inference through two customizable parameters. On the other hand, JPMA is proposed to assemble multiple hypotheses generated by D3DP into a single 3D pose for practical use. It reprojects 3D pose hypotheses to the 2D camera plane, selects the best hypothesis joint-by-joint based on the reprojection errors, and combines the selected joints into the final pose. The proposed JPMA conducts aggregation at the joint level and makes use of the 2D prior information, both of which have been overlooked by previous approaches. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets show that our method outperforms the state-of-the-art deterministic and probabilistic approaches by 1.5% and 8.9%, respectively. Code is available at https://github.com/paTRICK-swk/D3DP.
Learning to Compress Unmanned Aerial Vehicle (UAV) Captured Video: Benchmark and Analysis
Jan 15, 2023During the past decade, the Unmanned-Aerial-Vehicles (UAVs) have attracted increasing attention due to their flexible, extensive, and dynamic space-sensing capabilities. The volume of video captured by UAVs is exponentially growing along with the increased bitrate generated by the advancement of the sensors mounted on UAVs, bringing new challenges for on-device UAV storage and air-ground data transmission. Most existing video compression schemes were designed for natural scenes without consideration of specific texture and view characteristics of UAV videos. In this work, we first contribute a detailed analysis of the current state of the field of UAV video coding. Then we propose to establish a novel task for learned UAV video coding and construct a comprehensive and systematic benchmark for such a task, present a thorough review of high quality UAV video datasets and benchmarks, and contribute extensive rate-distortion efficiency comparison of learned and conventional codecs after. Finally, we discuss the challenges of encoding UAV videos. It is expected that the benchmark will accelerate the research and development in video coding on drone platforms.
SMR: Satisfied Machine Ratio Modeling for Machine Recognition-Oriented Image and Video Compression
Nov 13, 2022



Tons of images and videos are fed into machines for visual recognition all the time. Like human vision system (HVS), machine vision system (MVS) is sensitive to image quality, as quality degradation leads to information loss and recognition failure. In recent years, MVS-targeted image processing, particularly image and video compression, has emerged. However, existing methods only target an individual machine rather than the general machine community, thus cannot satisfy every type of machine. Moreover, the MVS characteristics are not well leveraged, which limits compression efficiency. In this paper, we introduce a new concept, Satisfied Machine Ratio (SMR), to address these issues. SMR statistically measures the image quality from the machine's perspective by collecting and combining satisfaction scores from a large quantity and variety of machine subjects, where such scores are obtained with MVS characteristics considered properly. We create the first large-scale SMR dataset that contains over 22 million annotated images for SMR studies. Furthermore, a deep learning-based model is proposed to predict the SMR for any given compressed image or video frame. Extensive experiments show that using the SMR model can significantly improve the performance of machine recognition-oriented image and video compression. And the SMR model generalizes well to unseen machines, compression frameworks, and datasets.
Cross Modal Compression: Towards Human-comprehensible Semantic Compression
Sep 06, 2022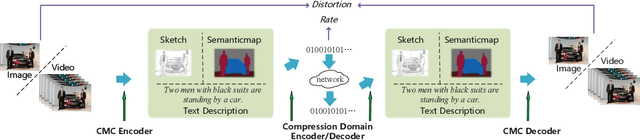
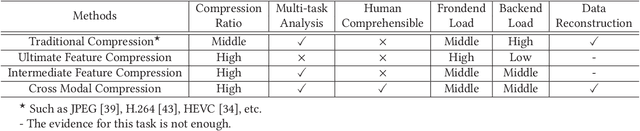
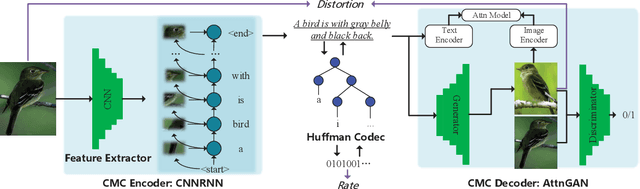

Traditional image/video compression aims to reduce the transmission/storage cost with signal fidelity as high as possible. However, with the increasing demand for machine analysis and semantic monitoring in recent years, semantic fidelity rather than signal fidelity is becoming another emerging concern in image/video compression. With the recent advances in cross modal translation and generation, in this paper, we propose the cross modal compression~(CMC), a semantic compression framework for visual data, to transform the high redundant visual data~(such as image, video, etc.) into a compact, human-comprehensible domain~(such as text, sketch, semantic map, attributions, etc.), while preserving the semantic. Specifically, we first formulate the CMC problem as a rate-distortion optimization problem. Secondly, we investigate the relationship with the traditional image/video compression and the recent feature compression frameworks, showing the difference between our CMC and these prior frameworks. Then we propose a novel paradigm for CMC to demonstrate its effectiveness. The qualitative and quantitative results show that our proposed CMC can achieve encouraging reconstructed results with an ultrahigh compression ratio, showing better compression performance than the widely used JPEG baseline.