 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Sensitivity Evaluation Framework for Clinical Diagnosis
Apr 18, 2025



Large language models (LLMs) have demonstrated impressive performance across various domains. However, for clinical diagnosis, higher expectations are required for LLM's reliability and sensitivity: thinking like physicians and remaining sensitive to key medical information that affects diagnostic reasoning, as subtle variations can lead to different diagnosis results. Yet, existing works focus mainly on investigating the sensitivity of LLMs to irrelevant context and overlook the importance of key information. In this paper, we investigate the sensitivity of LLMs, i.e. GPT-3.5, GPT-4, Gemini, Claude3 and LLaMA2-7b, to key medical information by introducing different perturbation strategies. The evaluation results highlight the limitations of current LLMs in remaining sensitive to key medical information for diagnostic decision-making. The evolution of LLMs must focus on improving their reliability, enhancing their ability to be sensitive to key information, and effectively utilizing this information. These improvements will enhance human trust in LLMs and facilitate their practical application in real-world scenarios. Our code and dataset are available at https://github.com/chenwei23333/DiagnosisQA.
A Structure-aware Generative Model for Biomedical Event Extraction
Aug 20, 2024Biomedical Event Extraction (BEE) is a challenging task that involves modeling complex relationships between fine-grained entities in biomedical text. BEE has traditionally been formulated as a classification problem. With the recent technological advancements in large language models (LLMs), generation-based models that cast event extraction as a sequence generation problem have attracted much attention from the NLP research communities. However, current generative models often overlook the importance of cross-instance information from complex event structures such as nested events and overlapping events, which contribute to over 20% of the events in the benchmark datasets. In this paper, we propose an event structure-aware generative model named GenBEE, which can capture complex event structures in biomedical text for biomedical event extraction. In particular, GenBEE constructs event prompts that distill knowledge from LLMs for incorporating both label semantics and argument dependency relationships into the proposed model. In addition, GenBEE also generates prefixes with event structural prompts to incorporate structural features for improving the model's overall performance. We have evaluated the proposed GenBEE model on three widely used biomedical event extraction benchmark datasets, namely MLEE, GE11, and PHEE. Experimental results show that GenBEE has achieved state-of-the-art performance on the MLEE and GE11 datasets, and achieved competitive results when compared to the state-of-the-art classification-based models on the PHEE dataset.
An Event Structure-aware Generative Model for Biomedical Event Extraction
Aug 15, 2024Biomedical Event Extraction (BEE) is a challenging task that involves modeling complex relationships between fine-grained entities in biomedical text. BEE has traditionally been formulated as a classification problem. With the recent technological advancements in large language models (LLMs), generation-based models that cast event extraction as a sequence generation problem have attracted much attention from the NLP research communities. However, current generative models often overlook the importance of cross-instance information from complex event structures such as nested events and overlapping events, which contribute quite significantly in the benchmark datasets. In this paper, we propose an event structure-aware generative model called GenBEE, which can capture complex event structures in biomedical text for biomedical event extraction. In particular, GenBEE constructs event prompts that distill knowledge from LLMs for incorporating both label semantics and argument dependency relationships into the proposed model. In addition, GenBEE also generates prefixes with event structural prompts to incorporate structural features for improving the model's overall performance. We have evaluated the proposed GenBEE model on three widely used biomedical event extraction benchmark datasets, namely MLEE, GE11, and PHEE. Experimental results show that GenBEE has achieved state-of-the-art performance on the MLEE and GE11 datasets, and achieved competitive results when compared to the state-of-the-art classification-based models on the PHEE dataset.
A Multimodal Data-driven Framework for Anxiety Screening
Mar 16, 2023Early screening for anxiety and appropriate interventions are essential to reduce the incidence of self-harm and suicide in patients. Due to limited medical resources, traditional methods that overly rely on physician expertise and specialized equipment cannot simultaneously meet the needs for high accuracy and model interpretability. Multimodal data can provide more objective evidence for anxiety screening to improve the accuracy of models. The large amount of noise in multimodal data and the unbalanced nature of the data make the model prone to overfitting. However, it is a non-differentiable problem when high-dimensional and multimodal feature combinations are used as model inputs and incorporated into model training. This causes existing anxiety screening methods based on machine learning and deep learning to be inapplicable. Therefore, we propose a multimodal data-driven anxiety screening framework, namely MMD-AS, and conduct experiments on the collected health data of over 200 seafarers by smartphones. The proposed framework's feature extraction, dimension reduction, feature selection, and anxiety inference are jointly trained to improve the model's performance. In the feature selection step, a feature selection method based on the Improved Fireworks Algorithm is used to solve the non-differentiable problem of feature combination to remove redundant features and search for the ideal feature subset. The experimental results show that our framework outperforms the comparison methods.
Dialogue State Distillation Network with Inter-Slot Contrastive Learning for Dialogue State Tracking
Feb 16, 2023



In task-oriented dialogue systems, Dialogue State Tracking (DST) aims to extract users' intentions from the dialogue history. Currently, most existing approaches suffer from error propagation and are unable to dynamically select relevant information when utilizing previous dialogue states. Moreover, the relations between the updates of different slots provide vital clues for DST. However, the existing approaches rely only on predefined graphs to indirectly capture the relations. In this paper, we propose a Dialogue State Distillation Network (DSDN) to utilize relevant information of previous dialogue states and migrate the gap of utilization between training and testing. Thus, it can dynamically exploit previous dialogue states and avoid introducing error propagation simultaneously. Further, we propose an inter-slot contrastive learning loss to effectively capture the slot co-update relations from dialogue context. Experiments are conducted on the widely used MultiWOZ 2.0 and MultiWOZ 2.1 datasets. The experimental results show that our proposed model achieves the state-of-the-art performance for DST.
Semantic Pivoting Model for Effective Event Detection
Nov 01, 2022



Event Detection, which aims to identify and classify mentions of event instances from unstructured articles, is an important task in Natural Language Processing (NLP). Existing techniques for event detection only use homogeneous one-hot vectors to represent the event type classes, ignoring the fact that the semantic meaning of the types is important to the task. Such an approach is inefficient and prone to overfitting. In this paper, we propose a Semantic Pivoting Model for Effective Event Detection (SPEED), which explicitly incorporates prior information during training and captures semantically meaningful correlations between input and events. Experimental results show that our proposed model achieves state-of-the-art performance and outperforms the baselines in multiple settings without using any external resources.
Machine Learning for Food Review and Recommendation
Jan 15, 2022Food reviews and recommendations have always been important for online food service websites. However, reviewing and recommending food is not simple as it is likely to be overwhelmed by disparate contexts and meanings. In this paper, we use different deep learning approaches to address the problems of sentiment analysis, automatic review tag generation, and retrieval of food reviews. We propose to develop a web-based food review system at Nanyang Technological University (NTU) named NTU Food Hunter, which incorporates different deep learning approaches that help users with food selection. First, we implement the BERT and LSTM deep learning models into the system for sentiment analysis of food reviews. Then, we develop a Part-of-Speech (POS) algorithm to automatically identify and extract adjective-noun pairs from the review content for review tag generation based on POS tagging and dependency parsing. Finally, we also train a RankNet model for the re-ranking of the retrieval results to improve the accuracy in our Solr-based food reviews search system. The experimental results show that our proposed deep learning approaches are promising for the applications of real-world problems.
Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with $1/n$ Parameters
Feb 17, 2021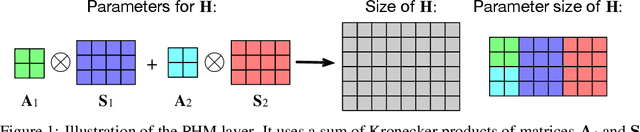
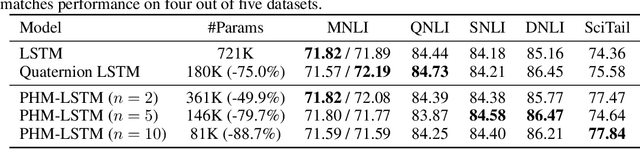
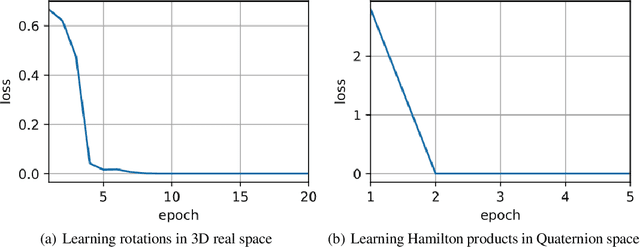
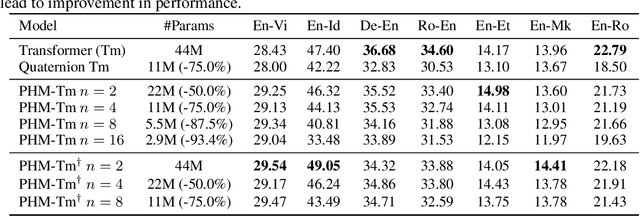
Recent works have demonstrated reasonable success of representation learning in hypercomplex space. Specifically, "fully-connected layers with Quaternions" (4D hypercomplex numbers), which replace real-valued matrix multiplications in fully-connected layers with Hamilton products of Quaternions, both enjoy parameter savings with only 1/4 learnable parameters and achieve comparable performance in various applications. However, one key caveat is that hypercomplex space only exists at very few predefined dimensions (4D, 8D, and 16D). This restricts the flexibility of models that leverage hypercomplex multiplications. To this end, we propose parameterizing hypercomplex multiplications, allowing models to learn multiplication rules from data regardless of whether such rules are predefined. As a result, our method not only subsumes the Hamilton product, but also learns to operate on any arbitrary nD hypercomplex space, providing more architectural flexibility using arbitrarily $1/n$ learnable parameters compared with the fully-connected layer counterpart. Experiments of applications to the LSTM and Transformer models on natural language inference, machine translation, text style transfer, and subject verb agreement demonstrate architectural flexibility and effectiveness of the proposed approach.
Collecting and Analyzing Multidimensional Data with Local Differential Privacy
Jun 28, 2019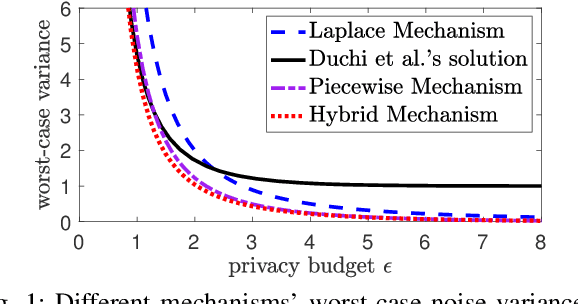
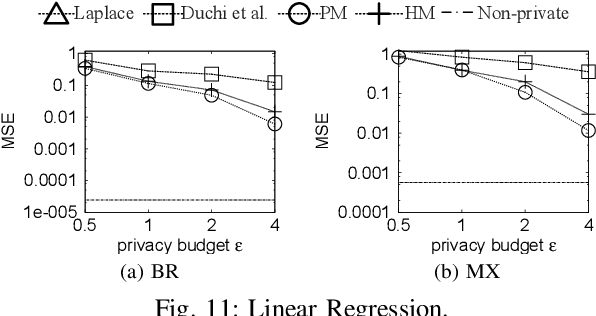
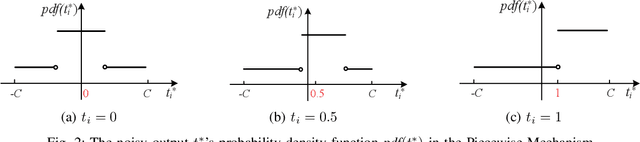
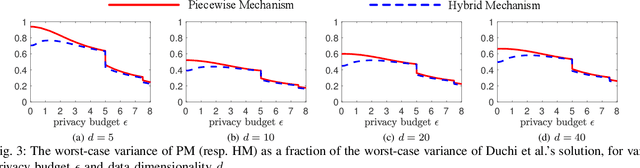
Local differential privacy (LDP) is a recently proposed privacy standard for collecting and analyzing data, which has been used, e.g., in the Chrome browser, iOS and macOS. In LDP, each user perturbs her information locally, and only sends the randomized version to an aggregator who performs analyses, which protects both the users and the aggregator against private information leaks. Although LDP has attracted much research attention in recent years, the majority of existing work focuses on applying LDP to complex data and/or analysis tasks. In this paper, we point out that the fundamental problem of collecting multidimensional data under LDP has not been addressed sufficiently, and there remains much room for improvement even for basic tasks such as computing the mean value over a single numeric attribute under LDP. Motivated by this, we first propose novel LDP mechanisms for collecting a numeric attribute, whose accuracy is at least no worse (and usually better) than existing solutions in terms of worst-case noise variance. Then, we extend these mechanisms to multidimensional data that can contain both numeric and categorical attributes, where our mechanisms always outperform existing solutions regarding worst-case noise variance. As a case study, we apply our solutions to build an LDP-compliant stochastic gradient descent algorithm (SGD), which powers many important machine learning tasks. Experiments using real datasets confirm the effectiveness of our methods, and their advantages over existing solutions.
Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks
Jun 11, 2019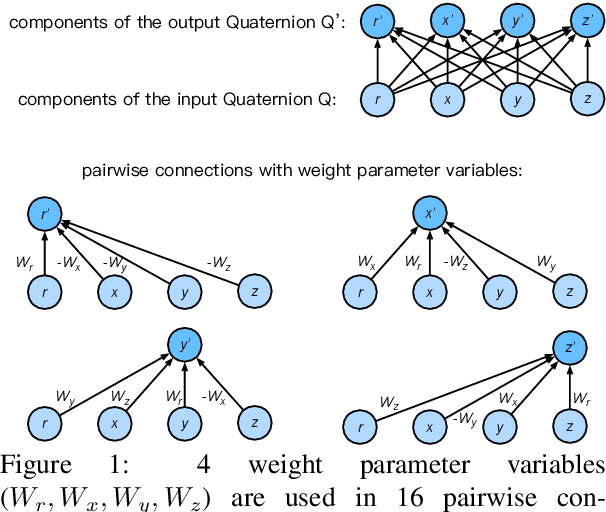



Many state-of-the-art neural models for NLP are heavily parameterized and thus memory inefficient. This paper proposes a series of lightweight and memory efficient neural architectures for a potpourri of natural language processing (NLP) tasks. To this end, our models exploit computation using Quaternion algebra and hypercomplex spaces, enabling not only expressive inter-component interactions but also significantly ($75\%$) reduced parameter size due to lesser degrees of freedom in the Hamilton product. We propose Quaternion variants of models, giving rise to new architectures such as the Quaternion attention Model and Quaternion Transformer. Extensive experiments on a battery of NLP tasks demonstrates the utility of proposed Quaternion-inspired models, enabling up to $75\%$ reduction in parameter size without significant loss in performance.