 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Extragradient-Based Bilinearly-Coupled Saddle-Point Optimization
Jun 17, 2022
We consider the smooth convex-concave bilinearly-coupled saddle-point problem, $\min_{\mathbf{x}}\max_{\mathbf{y}}~F(\mathbf{x}) + H(\mathbf{x},\mathbf{y}) - G(\mathbf{y})$, where one has access to stochastic first-order oracles for $F$, $G$ as well as the bilinear coupling function $H$. Building upon standard stochastic extragradient analysis for variational inequalities, we present a stochastic \emph{accelerated gradient-extragradient (AG-EG)} descent-ascent algorithm that combines extragradient and Nesterov's acceleration in general stochastic settings. This algorithm leverages scheduled restarting to admit a fine-grained nonasymptotic convergence rate that matches known lower bounds by both \citet{ibrahim2020linear} and \citet{zhang2021lower} in their corresponding settings, plus an additional statistical error term for bounded stochastic noise that is optimal up to a constant prefactor. This is the first result that achieves such a relatively mature characterization of optimality in saddle-point optimization.
Learning in Congestion Games with Bandit Feedback
Jun 04, 2022
Learning Nash equilibria is a central problem in multi-agent systems. In this paper, we investigate congestion games, a class of games with benign theoretical structure and broad real-world applications. We first propose a centralized algorithm based on the optimism in the face of uncertainty principle for congestion games with (semi-)bandit feedback, and obtain finite-sample guarantees. Then we propose a decentralized algorithm via a novel combination of the Frank-Wolfe method and G-optimal design. By exploiting the structure of the congestion game, we show the sample complexity of both algorithms depends only polynomially on the number of players and the number of facilities, but not the size of the action set, which can be exponentially large in terms of the number of facilities. We further define a new problem class, Markov congestion games, which allows us to model the non-stationarity in congestion games. We propose a centralized algorithm for Markov congestion games, whose sample complexity again has only polynomial dependence on all relevant problem parameters, but not the size of the action set.
On Gap-dependent Bounds for Offline Reinforcement Learning
Jun 01, 2022
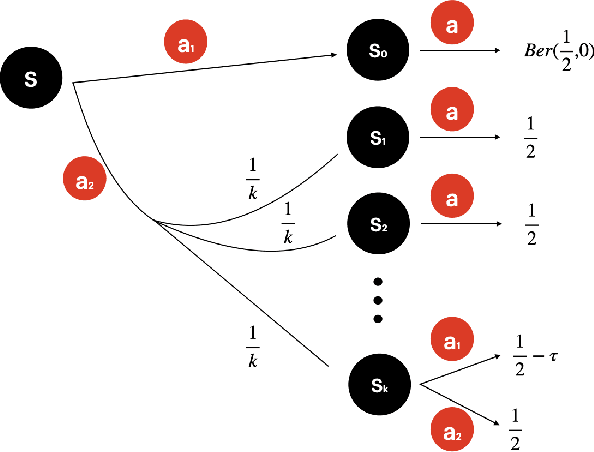
This paper presents a systematic study on gap-dependent sample complexity in offline reinforcement learning. Prior work showed when the density ratio between an optimal policy and the behavior policy is upper bounded (the optimal policy coverage assumption), then the agent can achieve an $O\left(\frac{1}{\epsilon^2}\right)$ rate, which is also minimax optimal. We show under the optimal policy coverage assumption, the rate can be improved to $O\left(\frac{1}{\epsilon}\right)$ when there is a positive sub-optimality gap in the optimal $Q$-function. Furthermore, we show when the visitation probabilities of the behavior policy are uniformly lower bounded for states where an optimal policy's visitation probabilities are positive (the uniform optimal policy coverage assumption), the sample complexity of identifying an optimal policy is independent of $\frac{1}{\epsilon}$. Lastly, we present nearly-matching lower bounds to complement our gap-dependent upper bounds.
Provably Efficient Offline Multi-agent Reinforcement Learning via Strategy-wise Bonus
Jun 01, 2022This paper considers offline multi-agent reinforcement learning. We propose the strategy-wise concentration principle which directly builds a confidence interval for the joint strategy, in contrast to the point-wise concentration principle that builds a confidence interval for each point in the joint action space. For two-player zero-sum Markov games, by exploiting the convexity of the strategy-wise bonus, we propose a computationally efficient algorithm whose sample complexity enjoys a better dependency on the number of actions than the prior methods based on the point-wise bonus. Furthermore, for offline multi-agent general-sum Markov games, based on the strategy-wise bonus and a novel surrogate function, we give the first algorithm whose sample complexity only scales $\sum_{i=1}^mA_i$ where $A_i$ is the action size of the $i$-th player and $m$ is the number of players. In sharp contrast, the sample complexity of methods based on the point-wise bonus would scale with the size of the joint action space $\Pi_{i=1}^m A_i$ due to the curse of multiagents. Lastly, all of our algorithms can naturally take a pre-specified strategy class $\Pi$ as input and output a strategy that is close to the best strategy in $\Pi$. In this setting, the sample complexity only scales with $\log |\Pi|$ instead of $\sum_{i=1}^mA_i$.
Provable General Function Class Representation Learning in Multitask Bandits and MDPs
May 31, 2022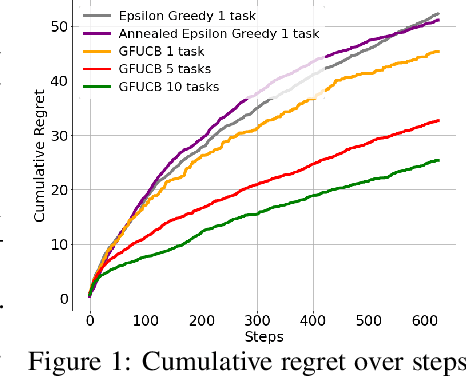
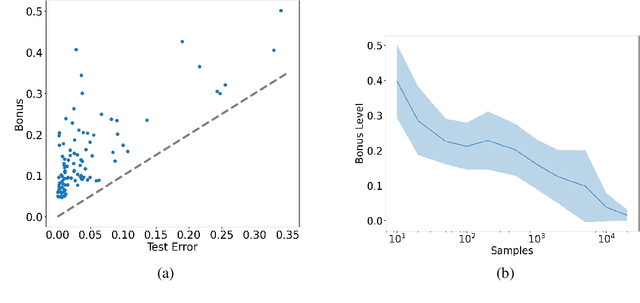
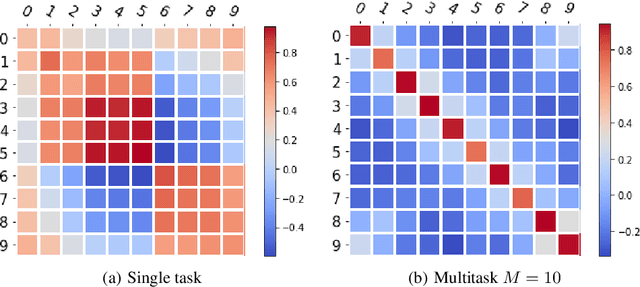
While multitask representation learning has become a popular approach in reinforcement learning (RL) to boost the sample efficiency, the theoretical understanding of why and how it works is still limited. Most previous analytical works could only assume that the representation function is already known to the agent or from linear function class, since analyzing general function class representation encounters non-trivial technical obstacles such as generalization guarantee, formulation of confidence bound in abstract function space, etc. However, linear-case analysis heavily relies on the particularity of linear function class, while real-world practice usually adopts general non-linear representation functions like neural networks. This significantly reduces its applicability. In this work, we extend the analysis to general function class representations. Specifically, we consider an agent playing $M$ contextual bandits (or MDPs) concurrently and extracting a shared representation function $\phi$ from a specific function class $\Phi$ using our proposed Generalized Functional Upper Confidence Bound algorithm (GFUCB). We theoretically validate the benefit of multitask representation learning within general function class for bandits and linear MDP for the first time. Lastly, we conduct experiments to demonstrate the effectiveness of our algorithm with neural net representation.
Variance-Aware Sparse Linear Bandits
May 26, 2022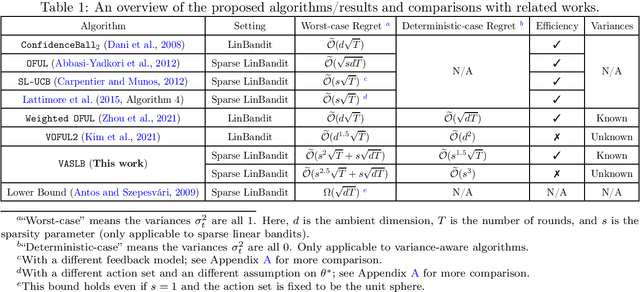
It is well-known that the worst-case minimax regret for sparse linear bandits is $\widetilde{\Theta}\left(\sqrt{dT}\right)$ where $d$ is the ambient dimension and $T$ is the number of time steps (ignoring the dependency on sparsity). On the other hand, in the benign setting where there is no noise and the action set is the unit sphere, one can use divide-and-conquer to achieve an $\widetilde{\mathcal O}(1)$ regret, which is (nearly) independent of $d$ and $T$. In this paper, we present the first variance-aware regret guarantee for sparse linear bandits: $\widetilde{\mathcal O}\left(\sqrt{d\sum_{t=1}^T \sigma_t^2} + 1\right)$, where $\sigma_t^2$ is the variance of the noise at the $t$-th time step. This bound naturally interpolates the regret bounds for the worst-case constant-variance regime ($\sigma_t = \Omega(1)$) and the benign deterministic regimes ($\sigma_t = 0$). To achieve this variance-aware regret guarantee, we develop a general framework that converts any variance-aware linear bandit algorithm to a variance-aware algorithm for sparse linear bandits in a ``black-box'' manner. Specifically, we take two recent algorithms as black boxes to illustrate that the claimed bounds indeed hold, where the first algorithm can handle unknown-variance cases and the second one is more efficient.
Nearly Minimax Algorithms for Linear Bandits with Shared Representation
Mar 29, 2022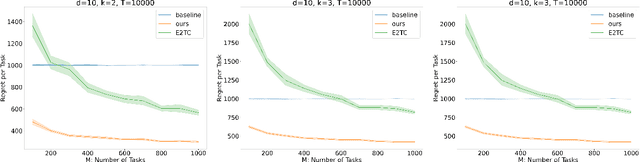
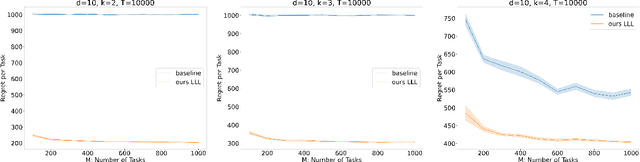
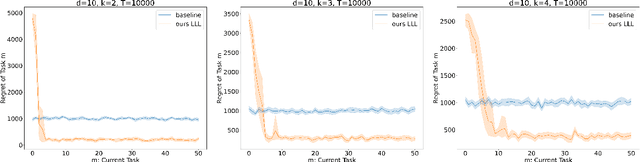
We give novel algorithms for multi-task and lifelong linear bandits with shared representation. Specifically, we consider the setting where we play $M$ linear bandits with dimension $d$, each for $T$ rounds, and these $M$ bandit tasks share a common $k(\ll d)$ dimensional linear representation. For both the multi-task setting where we play the tasks concurrently, and the lifelong setting where we play tasks sequentially, we come up with novel algorithms that achieve $\widetilde{O}\left(d\sqrt{kMT} + kM\sqrt{T}\right)$ regret bounds, which matches the known minimax regret lower bound up to logarithmic factors and closes the gap in existing results [Yang et al., 2021]. Our main technique include a more efficient estimator for the low-rank linear feature extractor and an accompanied novel analysis for this estimator.
Horizon-Free Reinforcement Learning in Polynomial Time: the Power of Stationary Policies
Mar 24, 2022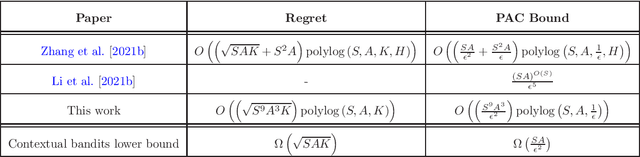
This paper gives the first polynomial-time algorithm for tabular Markov Decision Processes (MDP) that enjoys a regret bound \emph{independent on the planning horizon}. Specifically, we consider tabular MDP with $S$ states, $A$ actions, a planning horizon $H$, total reward bounded by $1$, and the agent plays for $K$ episodes. We design an algorithm that achieves an $O\left(\mathrm{poly}(S,A,\log K)\sqrt{K}\right)$ regret in contrast to existing bounds which either has an additional $\mathrm{polylog}(H)$ dependency~\citep{zhang2020reinforcement} or has an exponential dependency on $S$~\citep{li2021settling}. Our result relies on a sequence of new structural lemmas establishing the approximation power, stability, and concentration property of stationary policies, which can have applications in other problems related to Markov chains.
Understanding Curriculum Learning in Policy Optimization for Solving Combinatorial Optimization Problems
Feb 11, 2022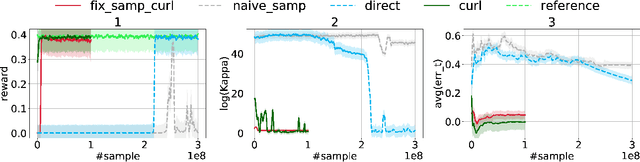
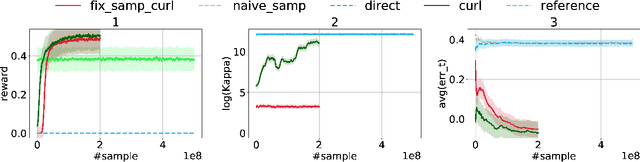
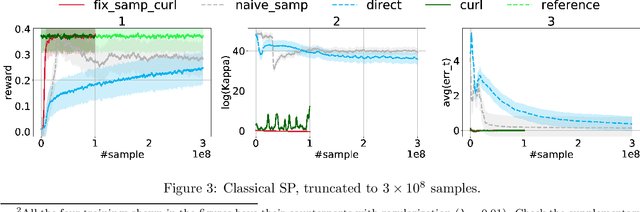
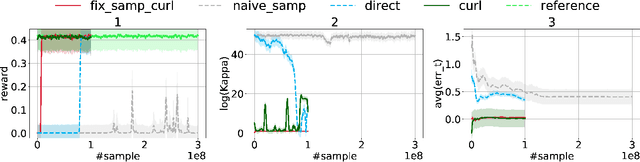
Over the recent years, reinforcement learning (RL) has shown impressive performance in finding strategic solutions for game environments, and recently starts to show promising results in solving combinatorial optimization (CO) problems, inparticular when coupled with curriculum learning to facilitate training. Despite emerging empirical evidence, theoretical study on why RL helps is still at its early stage. This paper presents the first systematic study on policy optimization methods for solving CO problems. We show that CO problems can be naturally formulated as latent Markov Decision Processes (LMDPs), and prove convergence bounds on natural policy gradient (NPG) for solving LMDPs. Furthermore, our theory explains the benefit of curriculum learning: it can find a strong sampling policy and reduce the distribution shift, a critical quantity that governs the convergence rate in our theorem. For a canonical combinatorial problem, Secretary Problem, we formally prove that distribution shift is reduced exponentially with curriculum learning. Our theory also shows we can simplify the curriculum learning scheme used in prior work from multi-step to single-step. Lastly, we provide extensive experiments on Secretary Problem and Online Knapsack to empirically verify our findings.
TransFollower: Long-Sequence Car-Following Trajectory Prediction through Transformer
Feb 04, 2022Car-following refers to a control process in which the following vehicle (FV) tries to keep a safe distance between itself and the lead vehicle (LV) by adjusting its acceleration in response to the actions of the vehicle ahead. The corresponding car-following models, which describe how one vehicle follows another vehicle in the traffic flow, form the cornerstone for microscopic traffic simulation and intelligent vehicle development. One major motivation of car-following models is to replicate human drivers' longitudinal driving trajectories. To model the long-term dependency of future actions on historical driving situations, we developed a long-sequence car-following trajectory prediction model based on the attention-based Transformer model. The model follows a general format of encoder-decoder architecture. The encoder takes historical speed and spacing data as inputs and forms a mixed representation of historical driving context using multi-head self-attention. The decoder takes the future LV speed profile as input and outputs the predicted future FV speed profile in a generative way (instead of an auto-regressive way, avoiding compounding errors). Through cross-attention between encoder and decoder, the decoder learns to build a connection between historical driving and future LV speed, based on which a prediction of future FV speed can be obtained. We train and test our model with 112,597 real-world car-following events extracted from the Shanghai Naturalistic Driving Study (SH-NDS). Results show that the model outperforms the traditional intelligent driver model (IDM), a fully connected neural network model, and a long short-term memory (LSTM) based model in terms of long-sequence trajectory prediction accuracy. We also visualized the self-attention and cross-attention heatmaps to explain how the model derives its predictions.