 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCACR:Reinforcing Temporal Answer Grounding in Instructional Video via Candidate-Aware Causal Reasoning
Jun 11, 2026The task of temporal answer grounding in instructional video (TAGV), which aims to locate precise video segments that respond to natural language queries, is increasingly important for direct video answer retrieval. This task remains challenging due to the need to comprehend semantically complex questions and to address the significant length mismatch between untrimmed videos and short target moments. Existing methods often suffer from sensitivity to irrelevant content or insufficient visual reasoning capabilities. To tackle these limitations, we propose a Candidate-Aware Causal Reasoning (CACR) framework. Our approach first employs a Visual-Language Pre-training based Candidate Selection (VBCS) algorithm to efficiently generate K candidate segments, then applies a temporal logic reasoning module enhanced by a rejection reward mechanism and optimized via Group Relative Policy Optimization (GRPO) for robust inference. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art performance in terms of mean Intersection-over-Union (mIoU), providing a new perspective for reasoning-based retrieval in long videos.
Reinforcing Temporal Answer Grounding in Instructional Video via Candidate-Aware Causal Reasoning
Jun 07, 2026The task of temporal answer grounding in instructional video (TAGV), which aims to locate precise video segments that respond to natural language queries, is increasingly important for direct video answer retrieval. This task remains challenging due to the need to comprehend semantically complex questions and to address the significant length mismatch between untrimmed videos and short target moments. Existing methods often suffer from sensitivity to irrelevant content or insufficient visual reasoning capabilities. To tackle these limitations, we propose a Candidate-Aware Causal Reasoning (CACR) framework. Our approach first employs a Visual-Language Pre-training based Candidate Selection (VBCS) algorithm to efficiently generate K candidate segments, then applies a temporal logic reasoning module enhanced by a rejection reward mechanism and optimized via Group Relative Policy Optimization (GRPO) for robust inference. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art performance in terms of mean Intersection-over-Union (mIoU), providing a new perspective for reasoning-based retrieval in long videos.
VICR: Visual In-Context Restoration for Real-World Image Super-Resolution
May 30, 2026Real-world image super-resolution (Real-ISR) requires balancing structural fidelity to degraded observations with realistic detail synthesis. However, existing generative Real-ISR methods often rely on entangled conditioning mechanisms, leading to structural drift or semantically inconsistent details. To address this issue, we propose Visual In-Context Restoration (VICR), a Diffusion Transformer (DiT)-based framework that formulates Real-ISR as image completion. Specifically, we introduce a decoupled visual prior injection mechanism that derives local and global cues from the low-quality (LQ) image: local cues help recover image structures and support high-frequency detail synthesis, while global cues guide overall generation and promote semantic consistency. For ambiguous regions under severe degradation, VICR employs an inference-time agent to refine semantic prompts using visual evidence from the LQ input while keeping model parameters fixed. Experiments show that VICR achieves state-of-the-art performance across multiple Real-ISR benchmarks with only 127M trainable parameters.
SwiftGS: Episodic Priors for Immediate Satellite Surface Recovery
Mar 19, 2026Rapid, large-scale 3D reconstruction from multi-date satellite imagery is vital for environmental monitoring, urban planning, and disaster response, yet remains difficult due to illumination changes, sensor heterogeneity, and the cost of per-scene optimization. We introduce SwiftGS, a meta-learned system that reconstructs 3D surfaces in a single forward pass by predicting geometry-radiation-decoupled Gaussian primitives together with a lightweight SDF, replacing expensive per-scene fitting with episodic training that captures transferable priors. The model couples a differentiable physics graph for projection, illumination, and sensor response with spatial gating that blends sparse Gaussian detail and global SDF structure, and incorporates semantic-geometric fusion, conditional lightweight task heads, and multi-view supervision from a frozen geometric teacher under an uncertainty-aware multi-task loss. At inference, SwiftGS operates zero-shot with optional compact calibration and achieves accurate DSM reconstruction and view-consistent rendering at significantly reduced computational cost, with ablations highlighting the benefits of the hybrid representation, physics-aware rendering, and episodic meta-training.
NeuroPareto: Calibrated Acquisition for Costly Many-Goal Search in Vast Parameter Spaces
Feb 03, 2026The pursuit of optimal trade-offs in high-dimensional search spaces under stringent computational constraints poses a fundamental challenge for contemporary multi-objective optimization. We develop NeuroPareto, a cohesive architecture that integrates rank-centric filtering, uncertainty disentanglement, and history-conditioned acquisition strategies to navigate complex objective landscapes. A calibrated Bayesian classifier estimates epistemic uncertainty across non-domination tiers, enabling rapid generation of high-quality candidates with minimal evaluation cost. Deep Gaussian Process surrogates further separate predictive uncertainty into reducible and irreducible components, providing refined predictive means and risk-aware signals for downstream selection. A lightweight acquisition network, trained online from historical hypervolume improvements, guides expensive evaluations toward regions balancing convergence and diversity. With hierarchical screening and amortized surrogate updates, the method maintains accuracy while keeping computational overhead low. Experiments on DTLZ and ZDT suites and a subsurface energy extraction task show that NeuroPareto consistently outperforms classifier-enhanced and surrogate-assisted baselines in Pareto proximity and hypervolume.
Composite Monte Carlo Decision Making under High Uncertainty of Novel Coronavirus Epidemic Using Hybridized Deep Learning and Fuzzy Rule Induction
Mar 22, 2020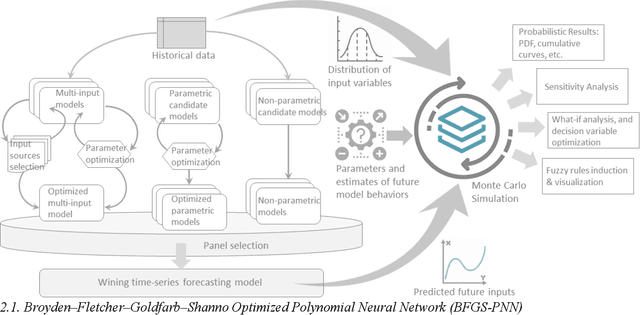
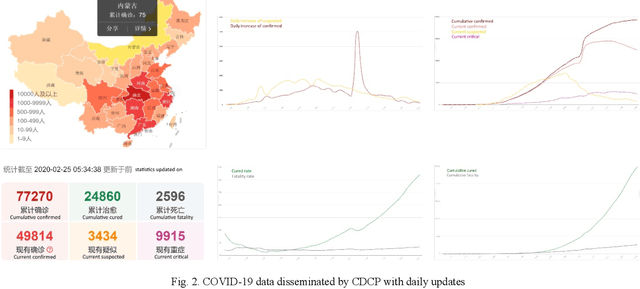
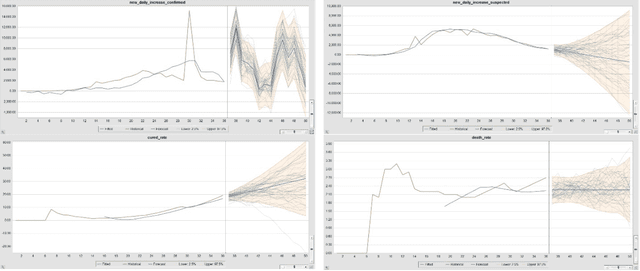

In the advent of the novel coronavirus epidemic since December 2019, governments and authorities have been struggling to make critical decisions under high uncertainty at their best efforts. Composite Monte-Carlo (CMC) simulation is a forecasting method which extrapolates available data which are broken down from multiple correlated/casual micro-data sources into many possible future outcomes by drawing random samples from some probability distributions. For instance, the overall trend and propagation of the infested cases in China are influenced by the temporal-spatial data of the nearby cities around the Wuhan city (where the virus is originated from), in terms of the population density, travel mobility, medical resources such as hospital beds and the timeliness of quarantine control in each city etc. Hence a CMC is reliable only up to the closeness of the underlying statistical distribution of a CMC, that is supposed to represent the behaviour of the future events, and the correctness of the composite data relationships. In this paper, a case study of using CMC that is enhanced by deep learning network and fuzzy rule induction for gaining better stochastic insights about the epidemic development is experimented. Instead of applying simplistic and uniform assumptions for a MC which is a common practice, a deep learning-based CMC is used in conjunction of fuzzy rule induction techniques. As a result, decision makers are benefited from a better fitted MC outputs complemented by min-max rules that foretell about the extreme ranges of future possibilities with respect to the epidemic.