 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
May 14, 2026Aligning streaming autoregressive (AR) video generators with human preferences is challenging. Existing reinforcement learning methods predominantly rely on noise-based exploration and SDE-based surrogate policies that are mismatched to the deterministic ODE dynamics of distilled AR models, and tend to perturb low-level appearance rather than the high-level semantic storyline progression critical for long-horizon coherence. To address these limitations, we present KVPO, an ODE-native online Group Relative Policy Optimization (GRPO) framework for aligning streaming video generators. For diversity exploration, KVPO introduces a causal-semantic exploration paradigm that relocates the source of variation from stochastic noise to the historical KV cache. By stochastically routing historical KV entries, it constructs semantically diverse generation branches that remain strictly on the data manifold. For policy modeling, KVPO introduces a velocity-field surrogate policy based on Trajectory Velocity Energy (TVE), which quantifies branch likelihood in flow-matching velocity space and yields a reward-weighted contrastive objective fully consistent with the native ODE formulation. Experiments on multiple distilled AR video generators demonstrate consistent gains in visual quality, motion quality, and text-video alignment across both single-prompt short-video and multi-prompt long-video settings.
Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
May 10, 2026Autoregressive (AR) video diffusion models adopt a streaming generation framework, enabling long-horizon video generation with real-time responsiveness, as exemplified by the Self Forcing training paradigm. However, existing AR video diffusion models still suffer from significant attention complexity and severe memory overhead due to the redundant key-value (KV) caches across historical frames, which limits scalability. In this paper, we tackle this challenge by introducing KV cache compression into autoregressive video diffusion. We observe that attention heads in mainstream AR diffusion models exhibit markedly distinct attention patterns and functional roles that remain stable across samples and denoising steps. Building on our empirical study of head-wise functional specialization, we divide the attention heads into two categories: static heads, which focus on transitions across autoregressive chunks and intra-frame fidelity, and dynamic heads, which govern inter-frame motion and consistency. We then propose Forcing-KV, a hybrid KV cache compression strategy that performs structured static pruning for static heads and dynamic pruning based on segment-wise similarity for dynamic heads. While maintaining output quality, our method achieves a generation speed of over 29 frames per second on a single NVIDIA H200 GPU along with 30% cache memory reduction, delivering up to 1.35x and 1.50x speedups on LongLive and Self Forcing at 480P resolution, and further scaling to 2.82x speedup at 1080P resolution. Code and demo videos are provided at https://zju-jiyicheng.github.io/Forcing-KV-Page.
Enhancing Segment-Based Speech Emotion Recognition by Deep Self-Learning
Mar 30, 2021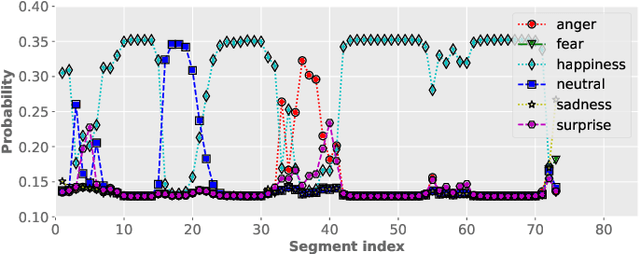
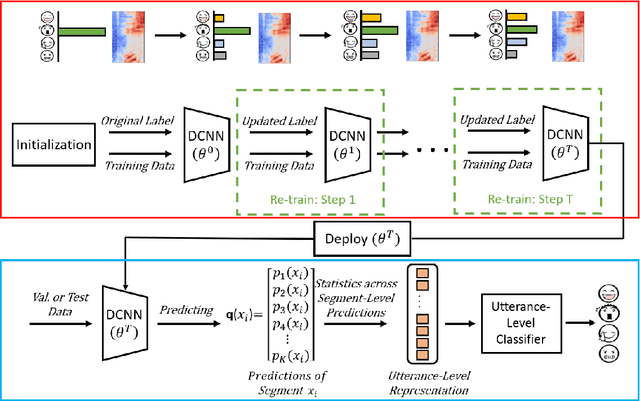
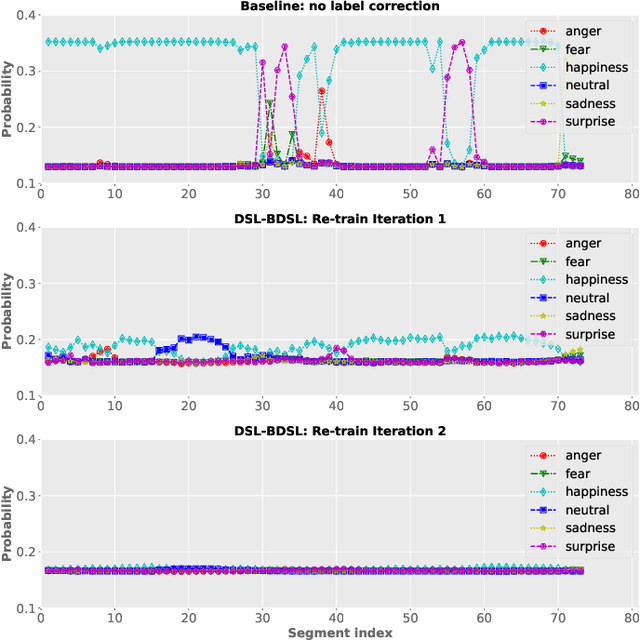
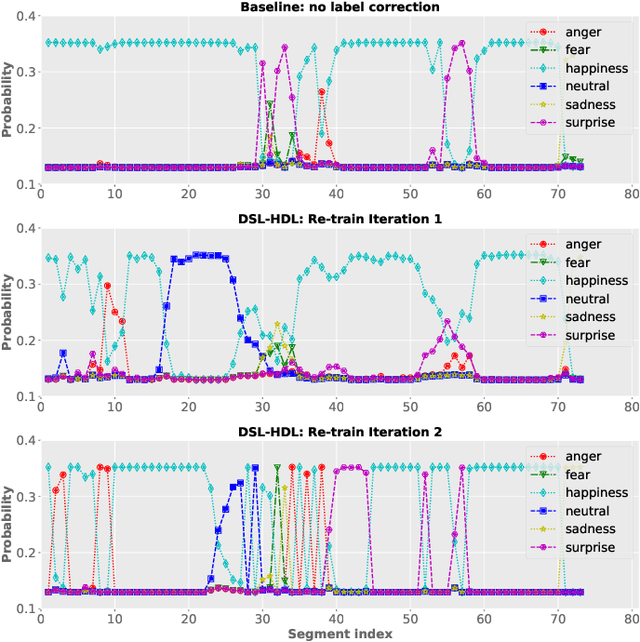
Despite the widespread utilization of deep neural networks (DNNs) for speech emotion recognition (SER), they are severely restricted due to the paucity of labeled data for training. Recently, segment-based approaches for SER have been evolving, which train backbone networks on shorter segments instead of whole utterances, and thus naturally augments training examples without additional resources. However, one core challenge remains for segment-based approaches: most emotional corpora do not provide ground-truth labels at the segment level. To supervisely train a segment-based emotion model on such datasets, the most common way assigns each segment the corresponding utterance's emotion label. However, this practice typically introduces noisy (incorrect) labels as emotional information is not uniformly distributed across the whole utterance. On the other hand, DNNs have been shown to easily over-fit a dataset when being trained with noisy labels. To this end, this work proposes a simple and effective deep self-learning (DSL) framework, which comprises a procedure to progressively correct segment-level labels in an iterative learning manner. The DSL method produces dynamically-generated and soft emotion labels, leading to significant performance improvements. Experiments on three well-known emotional corpora demonstrate noticeable gains using the proposed method.