 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021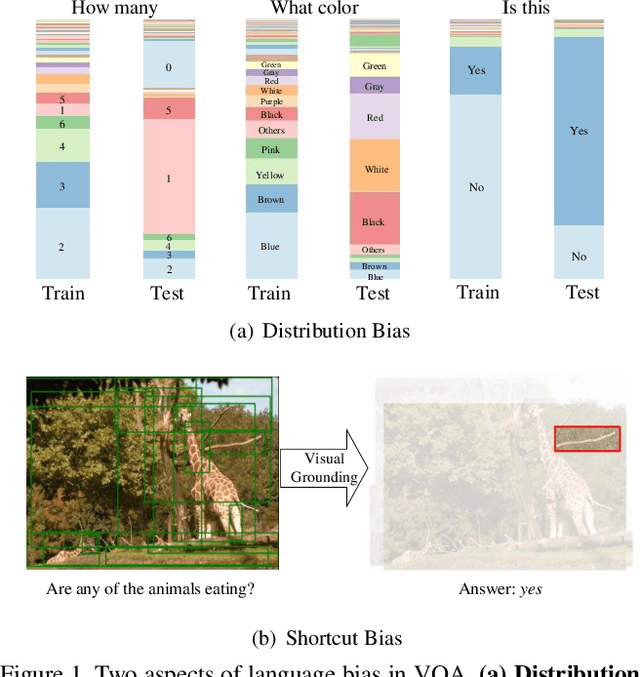
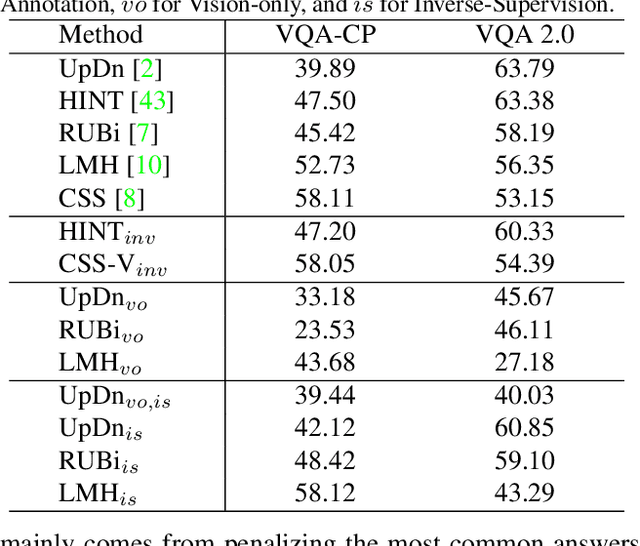
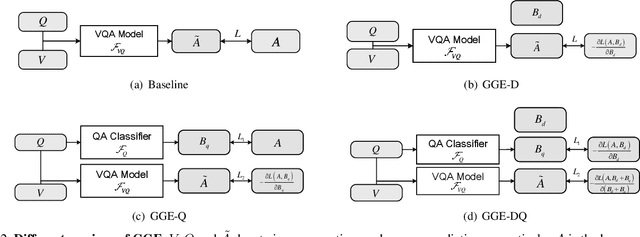
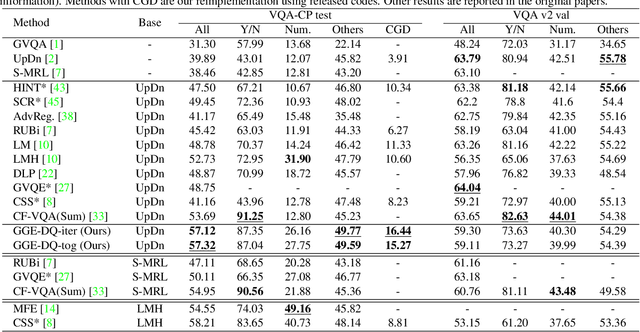
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
Fast Batch Nuclear-norm Maximization and Minimization for Robust Domain Adaptation
Aug 04, 2021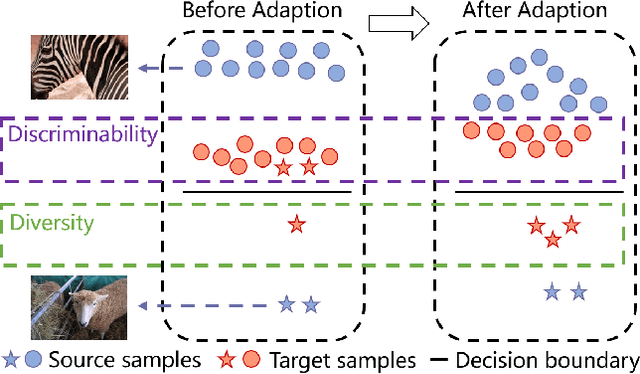
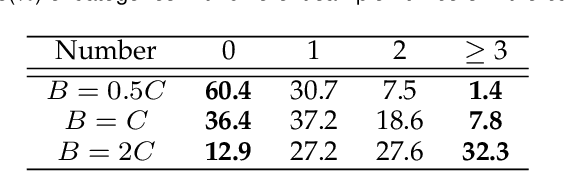
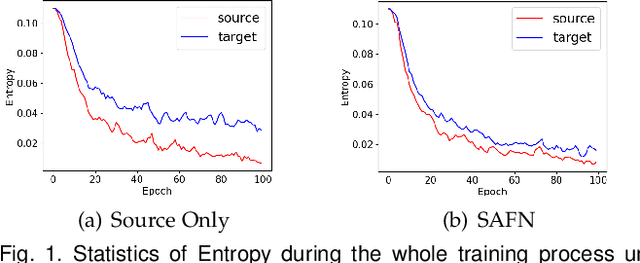
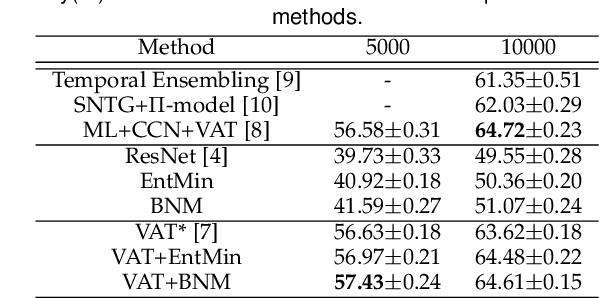
Due to the domain discrepancy in visual domain adaptation, the performance of source model degrades when bumping into the high data density near decision boundary in target domain. A common solution is to minimize the Shannon Entropy to push the decision boundary away from the high density area. However, entropy minimization also leads to severe reduction of prediction diversity, and unfortunately brings harm to the domain adaptation. In this paper, we investigate the prediction discriminability and diversity by studying the structure of the classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. The nuclear-norm is an upperbound of the former, and a convex approximation of the latter. Accordingly, we propose Batch Nuclear-norm Maximization and Minimization, which performs nuclear-norm maximization on the target output matrix to enhance the target prediction ability, and nuclear-norm minimization on the source batch output matrix to increase applicability of the source domain knowledge. We further approximate the nuclear-norm by L_{1,2}-norm, and design multi-batch optimization for stable solution on large number of categories. The fast approximation method achieves O(n^2) computational complexity and better convergence property. Experiments show that our method could boost the adaptation accuracy and robustness under three typical domain adaptation scenarios. The code is available at https://github.com/cuishuhao/BNM.
Learning Invariant Representation with Consistency and Diversity for Semi-supervised Source Hypothesis Transfer
Jul 20, 2021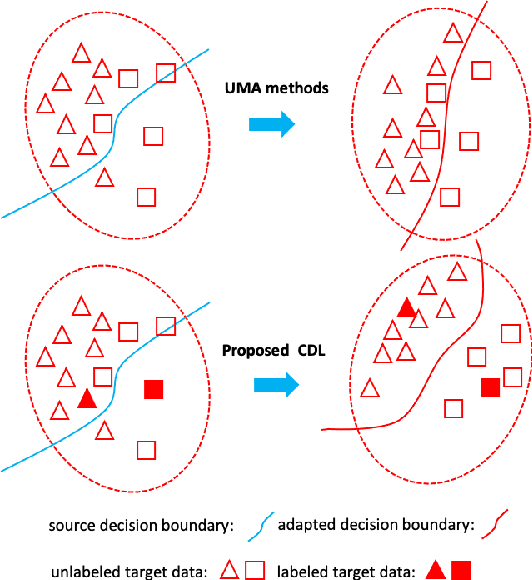

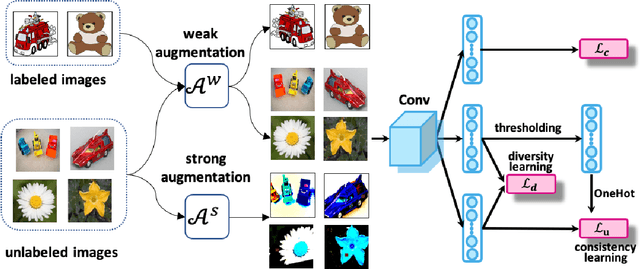
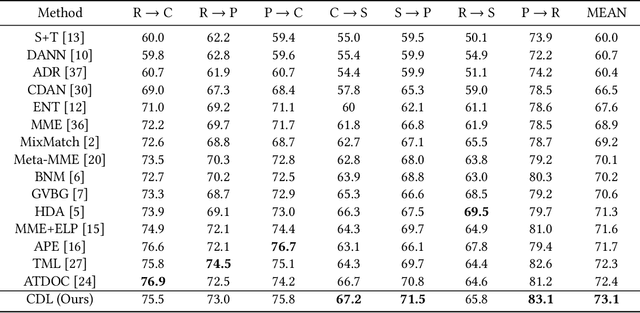
Semi-supervised domain adaptation (SSDA) aims to solve tasks in target domain by utilizing transferable information learned from the available source domain and a few labeled target data. However, source data is not always accessible in practical scenarios, which restricts the application of SSDA in real world circumstances. In this paper, we propose a novel task named Semi-supervised Source Hypothesis Transfer (SSHT), which performs domain adaptation based on source trained model, to generalize well in target domain with a few supervisions. In SSHT, we are facing two challenges: (1) The insufficient labeled target data may result in target features near the decision boundary, with the increased risk of mis-classification; (2) The data are usually imbalanced in source domain, so the model trained with these data is biased. The biased model is prone to categorize samples of minority categories into majority ones, resulting in low prediction diversity. To tackle the above issues, we propose Consistency and Diversity Learning (CDL), a simple but effective framework for SSHT by facilitating prediction consistency between two randomly augmented unlabeled data and maintaining the prediction diversity when adapting model to target domain. Encouraging consistency regularization brings difficulty to memorize the few labeled target data and thus enhances the generalization ability of the learned model. We further integrate Batch Nuclear-norm Maximization into our method to enhance the discriminability and diversity. Experimental results show that our method outperforms existing SSDA methods and unsupervised model adaptation methods on DomainNet, Office-Home and Office-31 datasets. The code is available at https://github.com/Wang-xd1899/SSHT.
Mining Latent Structures for Multimedia Recommendation
Apr 19, 2021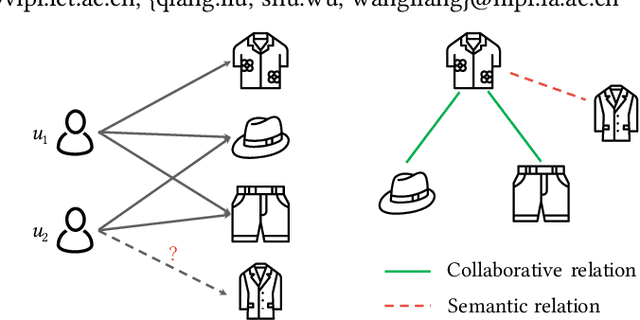
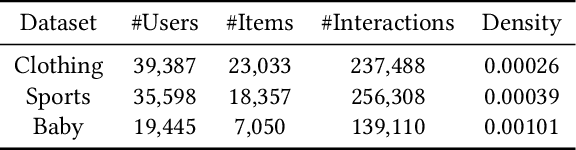
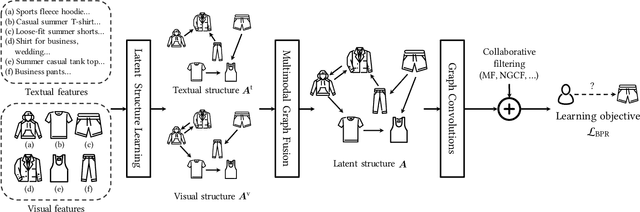
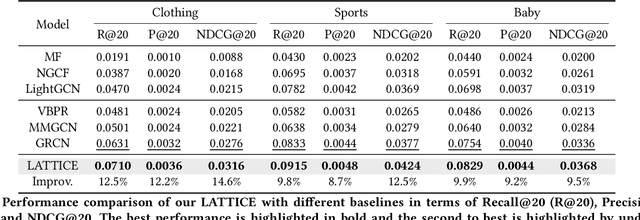
Multimedia content is of predominance in the modern Web era. Investigating how users interact with multimodal items is a continuing concern within the rapid development of recommender systems. The majority of previous work focuses on modeling user-item interactions with multimodal features included as side information. However, this scheme is not well-designed for multimedia recommendation. Specifically, only collaborative item-item relationships are implicitly modeled through high-order item-user-item relations. Considering that items are associated with rich contents in multiple modalities, we argue that the latent item-item structures underlying these multimodal contents could be beneficial for learning better item representations and further boosting recommendation. To this end, we propose a LATent sTructure mining method for multImodal reCommEndation, which we term LATTICE for brevity. To be specific, in the proposed LATTICE model, we devise a novel modality-aware structure learning layer, which learns item-item structures for each modality and aggregates multiple modalities to obtain latent item graphs. Based on the learned latent graphs, we perform graph convolutions to explicitly inject high-order item affinities into item representations. These enriched item representations can then be plugged into existing collaborative filtering methods to make more accurate recommendations. Extensive experiments on three real-world datasets demonstrate the superiority of our method over state-of-the-art multimedia recommendation methods and validate the efficacy of mining latent item-item relationships from multimodal features.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021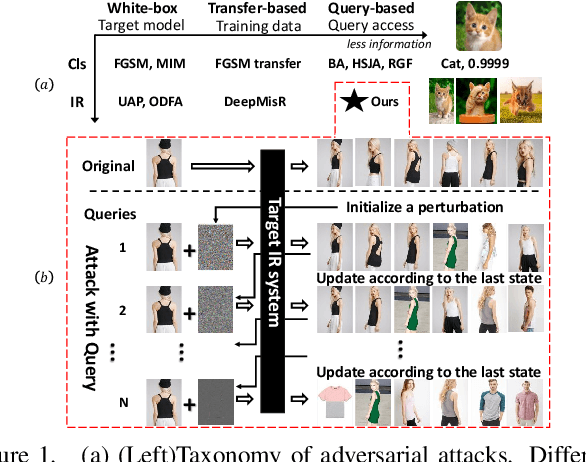
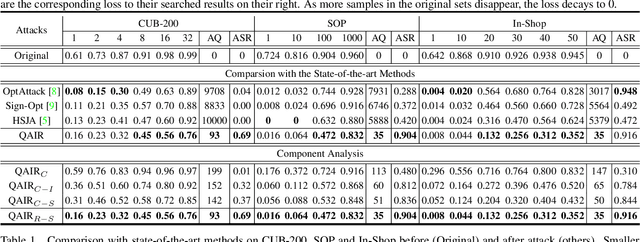
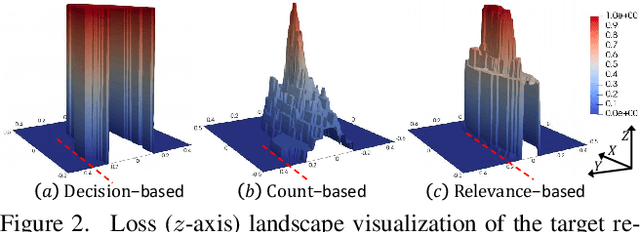
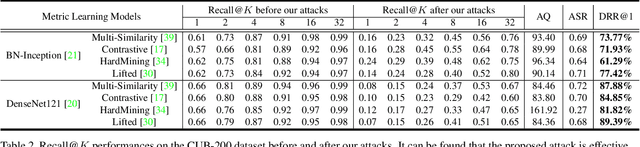
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Composite Adversarial Attacks
Dec 10, 2020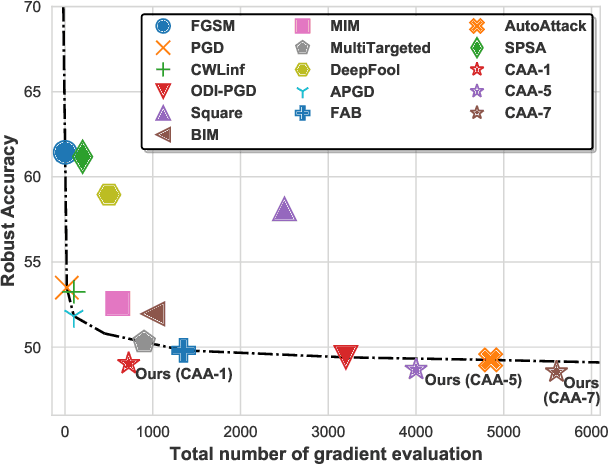

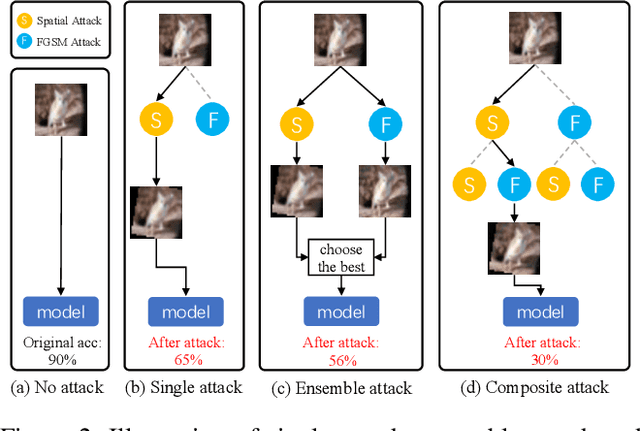
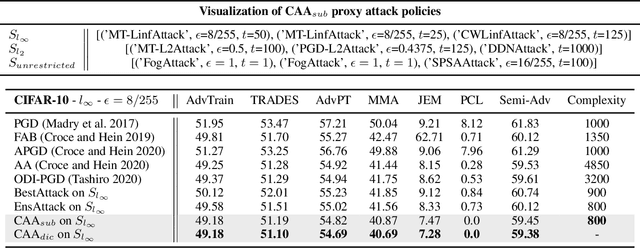
Adversarial attack is a technique for deceiving Machine Learning (ML) models, which provides a way to evaluate the adversarial robustness. In practice, attack algorithms are artificially selected and tuned by human experts to break a ML system. However, manual selection of attackers tends to be sub-optimal, leading to a mistakenly assessment of model security. In this paper, a new procedure called Composite Adversarial Attack (CAA) is proposed for automatically searching the best combination of attack algorithms and their hyper-parameters from a candidate pool of \textbf{32 base attackers}. We design a search space where attack policy is represented as an attacking sequence, i.e., the output of the previous attacker is used as the initialization input for successors. Multi-objective NSGA-II genetic algorithm is adopted for finding the strongest attack policy with minimum complexity. The experimental result shows CAA beats 10 top attackers on 11 diverse defenses with less elapsed time (\textbf{6 $\times$ faster than AutoAttack}), and achieves the new state-of-the-art on $l_{\infty}$, $l_{2}$ and unrestricted adversarial attacks.
Heuristic Domain Adaptation
Nov 30, 2020



In visual domain adaptation (DA), separating the domain-specific characteristics from the domain-invariant representations is an ill-posed problem. Existing methods apply different kinds of priors or directly minimize the domain discrepancy to address this problem, which lack flexibility in handling real-world situations. Another research pipeline expresses the domain-specific information as a gradual transferring process, which tends to be suboptimal in accurately removing the domain-specific properties. In this paper, we address the modeling of domain-invariant and domain-specific information from the heuristic search perspective. We identify the characteristics in the existing representations that lead to larger domain discrepancy as the heuristic representations. With the guidance of heuristic representations, we formulate a principled framework of Heuristic Domain Adaptation (HDA) with well-founded theoretical guarantees. To perform HDA, the cosine similarity scores and independence measurements between domain-invariant and domain-specific representations are cast into the constraints at the initial and final states during the learning procedure. Similar to the final condition of heuristic search, we further derive a constraint enforcing the final range of heuristic network output to be small. Accordingly, we propose Heuristic Domain Adaptation Network (HDAN), which explicitly learns the domain-invariant and domain-specific representations with the above mentioned constraints. Extensive experiments show that HDAN has exceeded state-of-the-art on unsupervised DA, multi-source DA and semi-supervised DA. The code is available at https://github.com/cuishuhao/HDA.
Semantic Editing On Segmentation Map Via Multi-Expansion Loss
Oct 16, 2020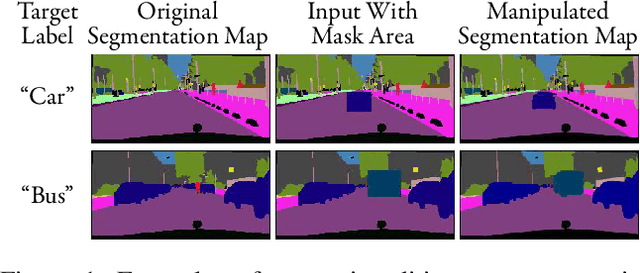


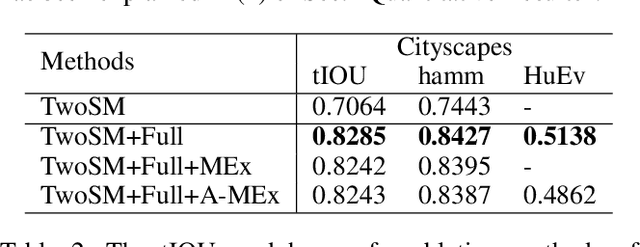
Semantic editing on segmentation map has been proposed as an intermediate interface for image generation, because it provides flexible and strong assistance in various image generation tasks. This paper aims to improve quality of edited segmentation map conditioned on semantic inputs. Even though recent studies apply global and local adversarial losses extensively to generate images for higher image quality, we find that they suffer from the misalignment of the boundary area in the mask area. To address this, we propose MExGAN for semantic editing on segmentation map, which uses a novel Multi-Expansion (MEx) loss implemented by adversarial losses on MEx areas. Each MEx area has the mask area of the generation as the majority and the boundary of original context as the minority. To boost convenience and stability of MEx loss, we further propose an Approximated MEx (A-MEx) loss. Besides, in contrast to previous model that builds training data for semantic editing on segmentation map with part of the whole image, which leads to model performance degradation, MExGAN applies the whole image to build the training data. Extensive experiments on semantic editing on segmentation map and natural image inpainting show competitive results on four datasets.
Label Decoupling Framework for Salient Object Detection
Aug 25, 2020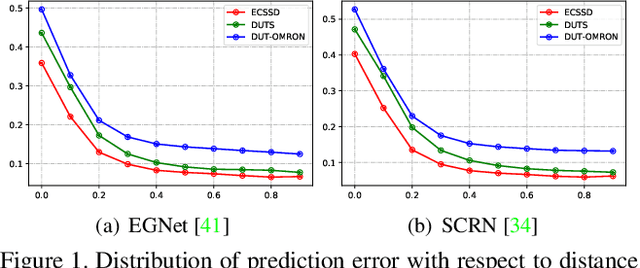
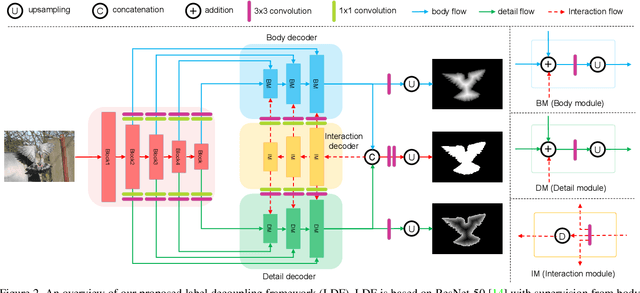
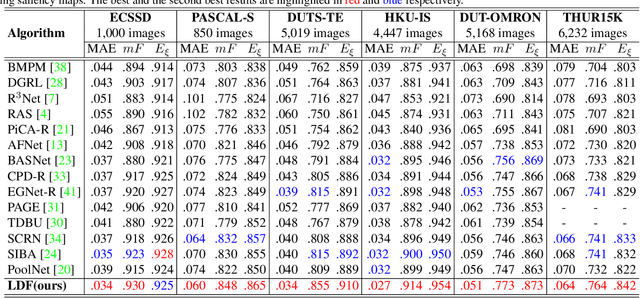

To get more accurate saliency maps, recent methods mainly focus on aggregating multi-level features from fully convolutional network (FCN) and introducing edge information as auxiliary supervision. Though remarkable progress has been achieved, we observe that the closer the pixel is to the edge, the more difficult it is to be predicted, because edge pixels have a very imbalance distribution. To address this problem, we propose a label decoupling framework (LDF) which consists of a label decoupling (LD) procedure and a feature interaction network (FIN). LD explicitly decomposes the original saliency map into body map and detail map, where body map concentrates on center areas of objects and detail map focuses on regions around edges. Detail map works better because it involves much more pixels than traditional edge supervision. Different from saliency map, body map discards edge pixels and only pays attention to center areas. This successfully avoids the distraction from edge pixels during training. Therefore, we employ two branches in FIN to deal with body map and detail map respectively. Feature interaction (FI) is designed to fuse the two complementary branches to predict the saliency map, which is then used to refine the two branches again. This iterative refinement is helpful for learning better representations and more precise saliency maps. Comprehensive experiments on six benchmark datasets demonstrate that LDF outperforms state-of-the-art approaches on different evaluation metrics.
Sharp Multiple Instance Learning for DeepFake Video Detection
Aug 11, 2020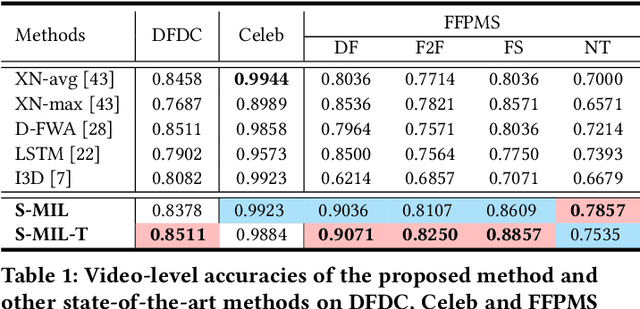
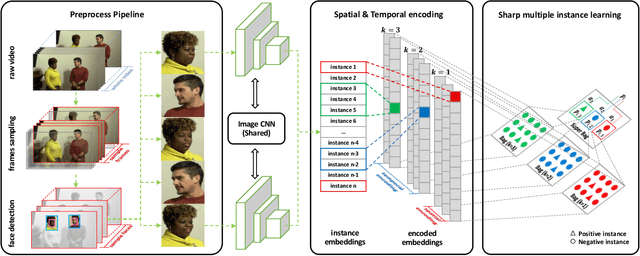
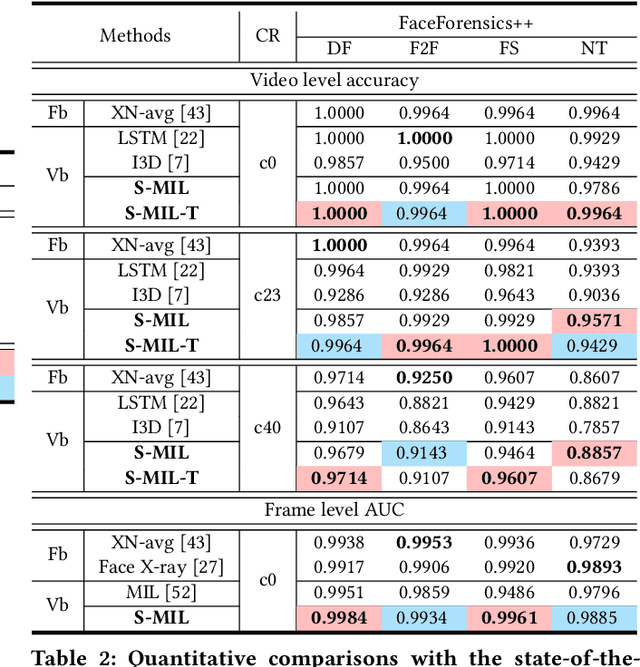

With the rapid development of facial manipulation techniques, face forgery has received considerable attention in multimedia and computer vision community due to security concerns. Existing methods are mostly designed for single-frame detection trained with precise image-level labels or for video-level prediction by only modeling the inter-frame inconsistency, leaving potential high risks for DeepFake attackers. In this paper, we introduce a new problem of partial face attack in DeepFake video, where only video-level labels are provided but not all the faces in the fake videos are manipulated. We address this problem by multiple instance learning framework, treating faces and input video as instances and bag respectively. A sharp MIL (S-MIL) is proposed which builds direct mapping from instance embeddings to bag prediction, rather than from instance embeddings to instance prediction and then to bag prediction in traditional MIL. Theoretical analysis proves that the gradient vanishing in traditional MIL is relieved in S-MIL. To generate instances that can accurately incorporate the partially manipulated faces, spatial-temporal encoded instance is designed to fully model the intra-frame and inter-frame inconsistency, which further helps to promote the detection performance. We also construct a new dataset FFPMS for partially attacked DeepFake video detection, which can benefit the evaluation of different methods at both frame and video levels. Experiments on FFPMS and the widely used DFDC dataset verify that S-MIL is superior to other counterparts for partially attacked DeepFake video detection. In addition, S-MIL can also be adapted to traditional DeepFake image detection tasks and achieve state-of-the-art performance on single-frame datasets.
* Accepted at ACM MM 2020. 11 pages, 8 figures, with appendix