 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinFormer: A Linear-based Lightweight Transformer Architecture For Time-Aware MIMO Channel Prediction
Oct 28, 2024



The emergence of 6th generation (6G) mobile networks brings new challenges in supporting high-mobility communications, particularly in addressing the issue of channel aging. While existing channel prediction methods offer improved accuracy at the expense of increased computational complexity, limiting their practical application in mobile networks. To address these challenges, we present LinFormer, an innovative channel prediction framework based on a scalable, all-linear, encoder-only Transformer model. Our approach, inspired by natural language processing (NLP) models such as BERT, adapts an encoder-only architecture specifically for channel prediction tasks. We propose replacing the computationally intensive attention mechanism commonly used in Transformers with a time-aware multi-layer perceptron (TMLP), significantly reducing computational demands. The inherent time awareness of TMLP module makes it particularly suitable for channel prediction tasks. We enhance LinFormer's training process by employing a weighted mean squared error loss (WMSELoss) function and data augmentation techniques, leveraging larger, readily available communication datasets. Our approach achieves a substantial reduction in computational complexity while maintaining high prediction accuracy, making it more suitable for deployment in cost-effective base stations (BS). Comprehensive experiments using both simulated and measured data demonstrate that LinFormer outperforms existing methods across various mobility scenarios, offering a promising solution for future wireless communication systems.
TLD: A Vehicle Tail Light signal Dataset and Benchmark
Sep 04, 2024



Understanding other drivers' intentions is crucial for safe driving. The role of taillights in conveying these intentions is underemphasized in current autonomous driving systems. Accurately identifying taillight signals is essential for predicting vehicle behavior and preventing collisions. Open-source taillight datasets are scarce, often small and inconsistently annotated. To address this gap, we introduce a new large-scale taillight dataset called TLD. Sourced globally, our dataset covers diverse traffic scenarios. To our knowledge, TLD is the first dataset to separately annotate brake lights and turn signals in real driving scenarios. We collected 17.78 hours of driving videos from the internet. This dataset consists of 152k labeled image frames sampled at a rate of 2 Hz, along with 1.5 million unlabeled frames interspersed throughout. Additionally, we have developed a two-stage vehicle light detection model consisting of two primary modules: a vehicle detector and a taillight classifier. Initially, YOLOv10 and DeepSORT captured consecutive vehicle images over time. Subsequently, the two classifiers work simultaneously to determine the states of the brake lights and turn signals. A post-processing procedure is then used to eliminate noise caused by misidentifications and provide the taillight states of the vehicle within a given time frame. Our method shows exceptional performance on our dataset, establishing a benchmark for vehicle taillight detection. The dataset is available at https://huggingface.co/datasets/ChaiJohn/TLD/tree/main
A Learnable Color Correction Matrix for RAW Reconstruction
Sep 04, 2024



Autonomous driving algorithms usually employ sRGB images as model input due to their compatibility with the human visual system. However, visually pleasing sRGB images are possibly sub-optimal for downstream tasks when compared to RAW images. The availability of RAW images is constrained by the difficulties in collecting real-world driving data and the associated challenges of annotation. To address this limitation and support research in RAW-domain driving perception, we design a novel and ultra-lightweight RAW reconstruction method. The proposed model introduces a learnable color correction matrix (CCM), which uses only a single convolutional layer to approximate the complex inverse image signal processor (ISP). Experimental results demonstrate that simulated RAW (simRAW) images generated by our method provide performance improvements equivalent to those produced by more complex inverse ISP methods when pretraining RAW-domain object detectors, which highlights the effectiveness and practicality of our approach.
Towards Dynamic Resource Allocation and Client Scheduling in Hierarchical Federated Learning: A Two-Phase Deep Reinforcement Learning Approach
Jun 21, 2024



Federated learning (FL) is a viable technique to train a shared machine learning model without sharing data. Hierarchical FL (HFL) system has yet to be studied regrading its multiple levels of energy, computation, communication, and client scheduling, especially when it comes to clients relying on energy harvesting to power their operations. This paper presents a new two-phase deep deterministic policy gradient (DDPG) framework, referred to as ``TP-DDPG'', to balance online the learning delay and model accuracy of an FL process in an energy harvesting-powered HFL system. The key idea is that we divide optimization decisions into two groups, and employ DDPG to learn one group in the first phase, while interpreting the other group as part of the environment to provide rewards for training the DDPG in the second phase. Specifically, the DDPG learns the selection of participating clients, and their CPU configurations and the transmission powers. A new straggler-aware client association and bandwidth allocation (SCABA) algorithm efficiently optimizes the other decisions and evaluates the reward for the DDPG. Experiments demonstrate that with substantially reduced number of learnable parameters, the TP-DDPG can quickly converge to effective polices that can shorten the training time of HFL by 39.4% compared to its benchmarks, when the required test accuracy of HFL is 0.9.
MM-KWS: Multi-modal Prompts for Multilingual User-defined Keyword Spotting
Jun 11, 2024In this paper, we propose MM-KWS, a novel approach to user-defined keyword spotting leveraging multi-modal enrollments of text and speech templates. Unlike previous methods that focus solely on either text or speech features, MM-KWS extracts phoneme, text, and speech embeddings from both modalities. These embeddings are then compared with the query speech embedding to detect the target keywords. To ensure the applicability of MM-KWS across diverse languages, we utilize a feature extractor incorporating several multilingual pre-trained models. Subsequently, we validate its effectiveness on Mandarin and English tasks. In addition, we have integrated advanced data augmentation tools for hard case mining to enhance MM-KWS in distinguishing confusable words. Experimental results on the LibriPhrase and WenetPhrase datasets demonstrate that MM-KWS outperforms prior methods significantly.
Quality of Experience Oriented Cross-layer Optimization for Real-time XR Video Transmission
Apr 15, 2024



Extended reality (XR) is one of the most important applications of beyond 5G and 6G networks. Real-time XR video transmission presents challenges in terms of data rate and delay. In particular, the frame-by-frame transmission mode of XR video makes real-time XR video very sensitive to dynamic network environments. To improve the users' quality of experience (QoE), we design a cross-layer transmission framework for real-time XR video. The proposed framework allows the simple information exchange between the base station (BS) and the XR server, which assists in adaptive bitrate and wireless resource scheduling. We utilize the cross-layer information to formulate the problem of maximizing user QoE by finding the optimal scheduling and bitrate adjustment strategies. To address the issue of mismatched time scales between two strategies, we decouple the original problem and solve them individually using a multi-agent-based approach. Specifically, we propose the multi-step Deep Q-network (MS-DQN) algorithm to obtain a frame-priority-based wireless resource scheduling strategy and then propose the Transformer-based Proximal Policy Optimization (TPPO) algorithm for video bitrate adaptation. The experimental results show that the TPPO+MS-DQN algorithm proposed in this study can improve the QoE by 3.6% to 37.8%. More specifically, the proposed MS-DQN algorithm enhances the transmission quality by 49.9%-80.2%.
Real-time Extended Reality Video Transmission Optimization Based on Frame-priority Scheduling
Feb 08, 2024



Extended reality (XR) is one of the most important applications of 5G. For real-time XR video transmission in 5G networks, a low latency and high data rate are required. In this paper, we propose a resource allocation scheme based on frame-priority scheduling to meet these requirements. The optimization problem is modelled as a frame-priority-based radio resource scheduling problem to improve transmission quality. We propose a scheduling framework based on multi-step Deep Q-network (MS-DQN) and design a neural network model based on convolutional neural network (CNN). Simulation results show that the scheduling framework based on frame-priority and MS-DQN can improve transmission quality by 49.9%-80.2%.
On the performance of an integrated communication and localization system: an analytical framework
Sep 08, 2023Quantifying the performance bound of an integrated localization and communication (ILAC) system and the trade-off between communication and localization performance is critical. In this letter, we consider an ILAC system that can perform communication and localization via time-domain or frequency-domain resource allocation. We develop an analytical framework to derive the closed-form expression of the capacity loss versus localization Cramer-Rao lower bound (CRB) loss via time-domain and frequency-domain resource allocation. Simulation results validate the analytical model and demonstrate that frequency-domain resource allocation is preferable in scenarios with a smaller number of antennas at the next generation nodeB (gNB) and a larger distance between user equipment (UE) and gNB, while time-domain resource allocation is preferable in scenarios with a larger number of antennas and smaller distance between UE and the gNB.
A Hard and Soft Hybrid Slicing Framework for Service Level Agreement Guarantee via Deep Reinforcement Learning
Mar 06, 2022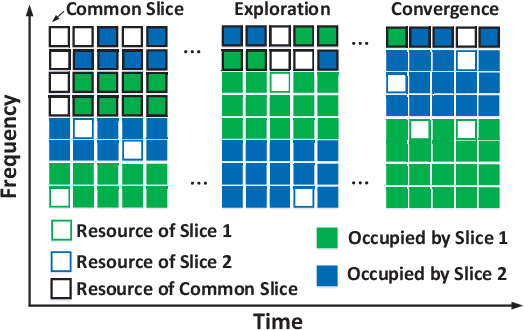
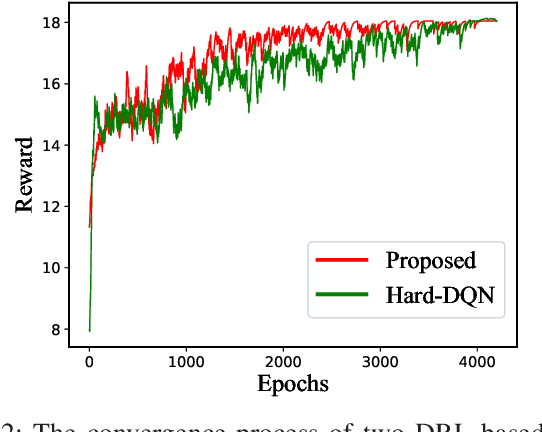
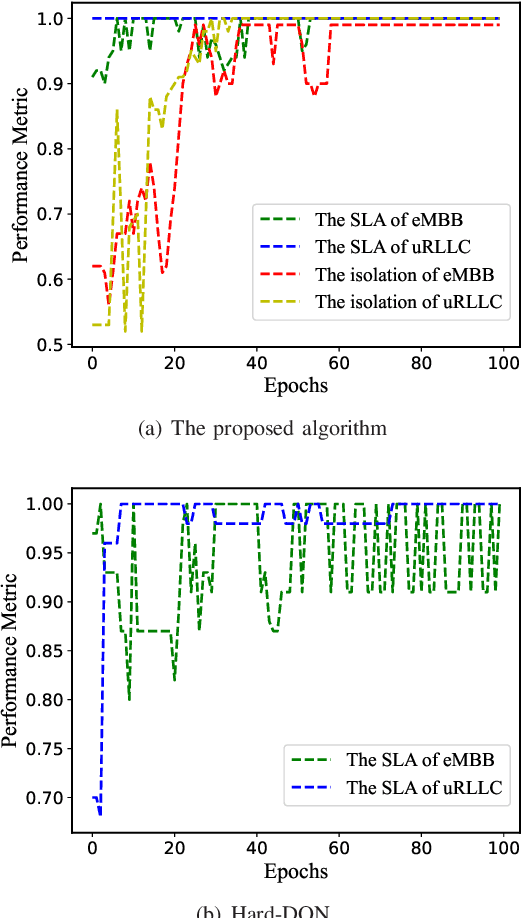
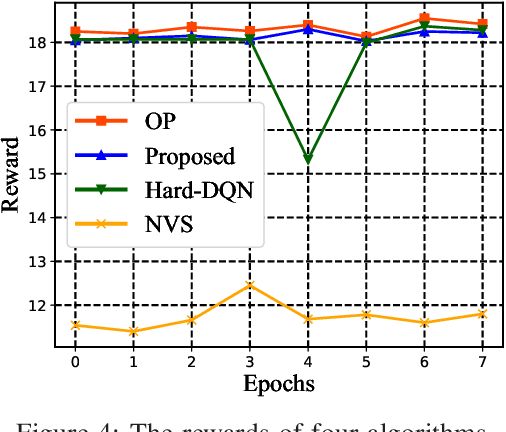
Network slicing is a critical driver for guaranteeing the diverse service level agreements (SLA) in 5G and future networks. Recently, deep reinforcement learning (DRL) has been widely utilized for resource allocation in network slicing. However, existing related works do not consider the performance loss associated with the initial exploration phase of DRL. This paper proposes a new performance-guaranteed slicing strategy with a soft and hard hybrid slicing setting. Mainly, a common slice setting is applied to guarantee slices' SLA when training the neural network. Moreover, the resource of the common slice tends to precisely redistribute to slices with the training of DRL until it converges. Furthermore, experiment results confirm the effectiveness of our proposed slicing framework: the slices' SLA of the training phase can be guaranteed, and the proposed algorithm can achieve the near-optimal performance in terms of the SLA satisfaction ratio, isolation degree and spectrum maximization after convergence.
TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance
Nov 16, 2021
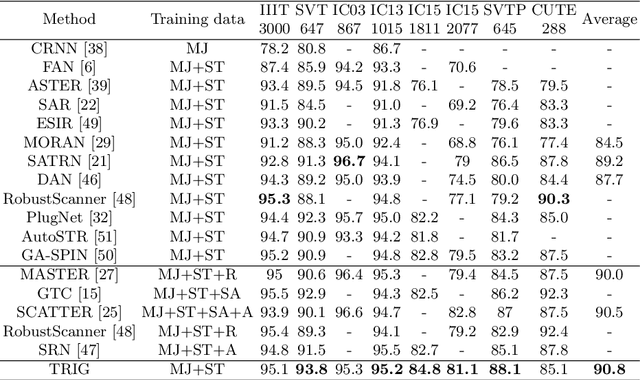
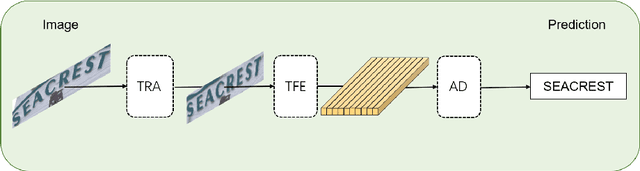
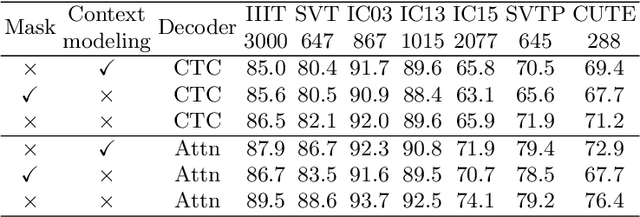
Scene text recognition (STR) is an important bridge between images and text, attracting abundant research attention. While convolutional neural networks (CNNS) have achieved remarkable progress in this task, most of the existing works need an extra module (context modeling module) to help CNN to capture global dependencies to solve the inductive bias and strengthen the relationship between text features. Recently, the transformer has been proposed as a promising network for global context modeling by self-attention mechanism, but one of the main shortcomings, when applied to recognition, is the efficiency. We propose a 1-D split to address the challenges of complexity and replace the CNN with the transformer encoder to reduce the need for a context modeling module. Furthermore, recent methods use a frozen initial embedding to guide the decoder to decode the features to text, leading to a loss of accuracy. We propose to use a learnable initial embedding learned from the transformer encoder to make it adaptive to different input images. Above all, we introduce a novel architecture for text recognition, named TRansformer-based text recognizer with Initial embedding Guidance (TRIG), composed of three stages (transformation, feature extraction, and prediction). Extensive experiments show that our approach can achieve state-of-the-art on text recognition benchmarks.