 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuang Xu
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023
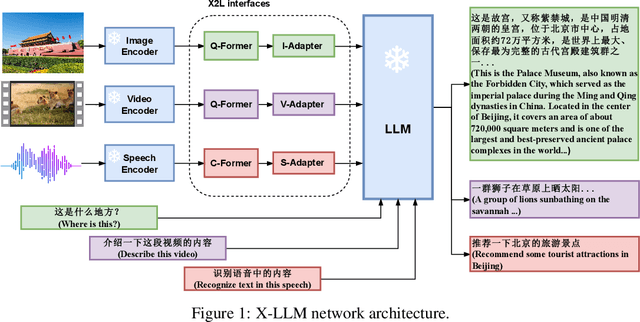
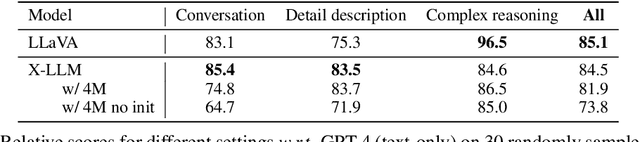


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
Spherical Space Feature Decomposition for Guided Depth Map Super-Resolution
Mar 15, 2023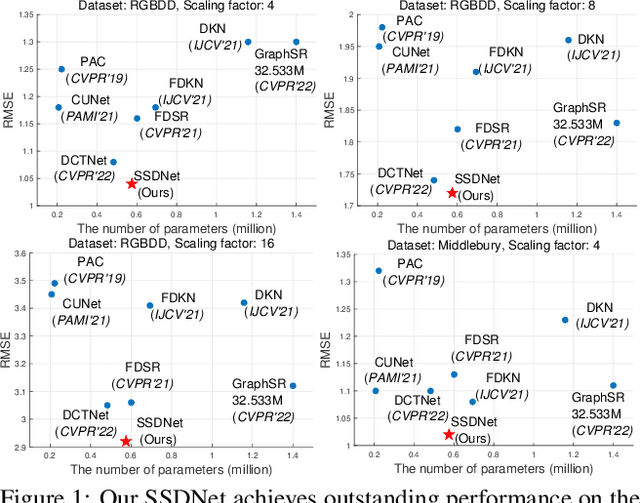
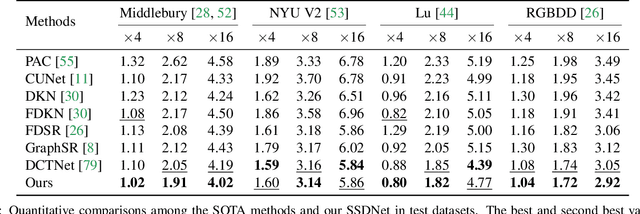
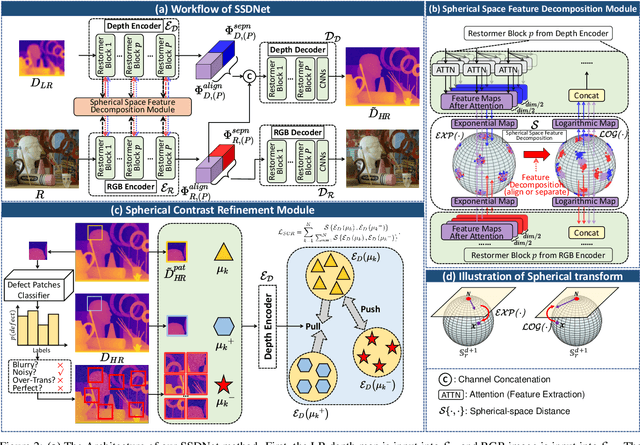

Guided depth map super-resolution (GDSR), as a hot topic in multi-modal image processing, aims to upsample low-resolution (LR) depth maps with additional information involved in high-resolution (HR) RGB images from the same scene. The critical step of this task is to effectively extract domain-shared and domain-private RGB/depth features. In addition, three detailed issues, namely blurry edges, noisy surfaces, and over-transferred RGB texture, need to be addressed. In this paper, we propose the Spherical Space feature Decomposition Network (SSDNet) to solve the above issues. To better model cross-modality features, Restormer block-based RGB/depth encoders are employed for extracting local-global features. Then, the extracted features are mapped to the spherical space to complete the separation of private features and the alignment of shared features. Shared features of RGB are fused with the depth features to complete the GDSR task. Subsequently, a spherical contrast refinement (SCR) module is proposed to further address the detail issues. Patches that are classified according to imperfect categories are input to the SCR module, where the patch features are pulled closer to the ground truth and pushed away from the corresponding imperfect samples in the spherical feature space via contrastive learning. Extensive experiments demonstrate that our method can achieve state-of-the-art results on four test datasets and can successfully generalize to real-world scenes. Code will be released.
DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion
Mar 13, 2023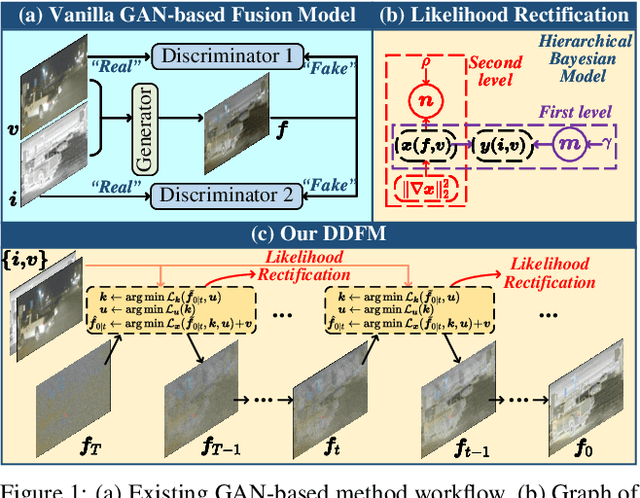
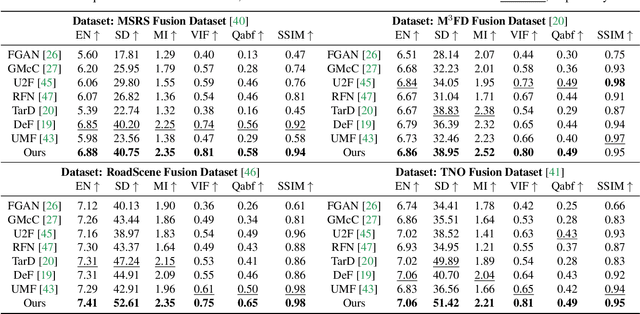
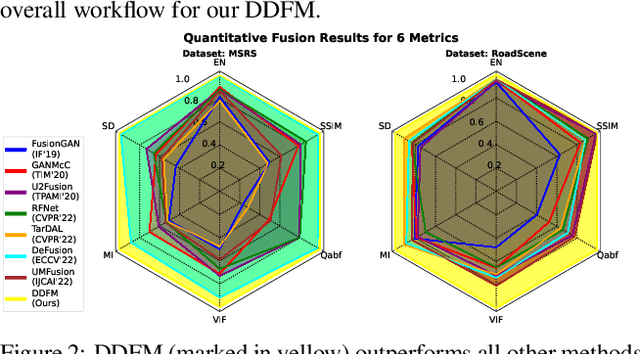
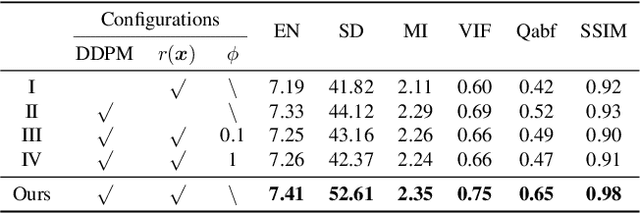
Multi-modality image fusion aims to combine different modalities to produce fused images that retain the complementary features of each modality, such as functional highlights and texture details. To leverage strong generative priors and address challenges such as unstable training and lack of interpretability for GAN-based generative methods, we propose a novel fusion algorithm based on the denoising diffusion probabilistic model (DDPM). The fusion task is formulated as a conditional generation problem under the DDPM sampling framework, which is further divided into an unconditional generation subproblem and a maximum likelihood subproblem. The latter is modeled in a hierarchical Bayesian manner with latent variables and inferred by the expectation-maximization algorithm. By integrating the inference solution into the diffusion sampling iteration, our method can generate high-quality fused images with natural image generative priors and cross-modality information from source images. Note that all we required is an unconditional pre-trained generative model, and no fine-tuning is needed. Our extensive experiments indicate that our approach yields promising fusion results in infrared-visible image fusion and medical image fusion. The code will be released.
Matching-based Term Semantics Pre-training for Spoken Patient Query Understanding
Mar 02, 2023
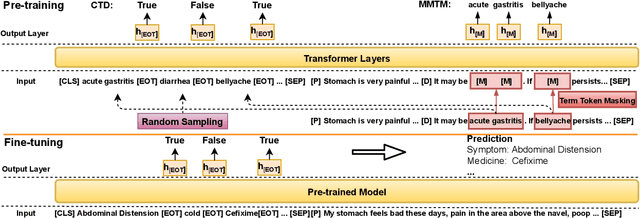
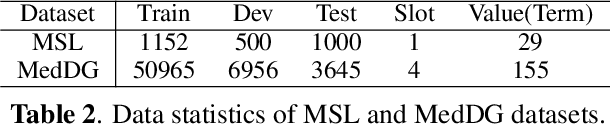
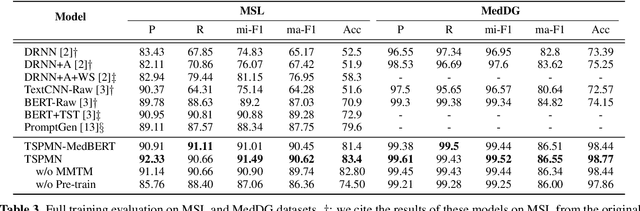
Medical Slot Filling (MSF) task aims to convert medical queries into structured information, playing an essential role in diagnosis dialogue systems. However, the lack of sufficient term semantics learning makes existing approaches hard to capture semantically identical but colloquial expressions of terms in medical conversations. In this work, we formalize MSF into a matching problem and propose a Term Semantics Pre-trained Matching Network (TSPMN) that takes both terms and queries as input to model their semantic interaction. To learn term semantics better, we further design two self-supervised objectives, including Contrastive Term Discrimination (CTD) and Matching-based Mask Term Modeling (MMTM). CTD determines whether it is the masked term in the dialogue for each given term, while MMTM directly predicts the masked ones. Experimental results on two Chinese benchmarks show that TSPMN outperforms strong baselines, especially in few-shot settings.
Knowledge Transfer from Pre-trained Language Models to Cif-based Speech Recognizers via Hierarchical Distillation
Jan 30, 2023
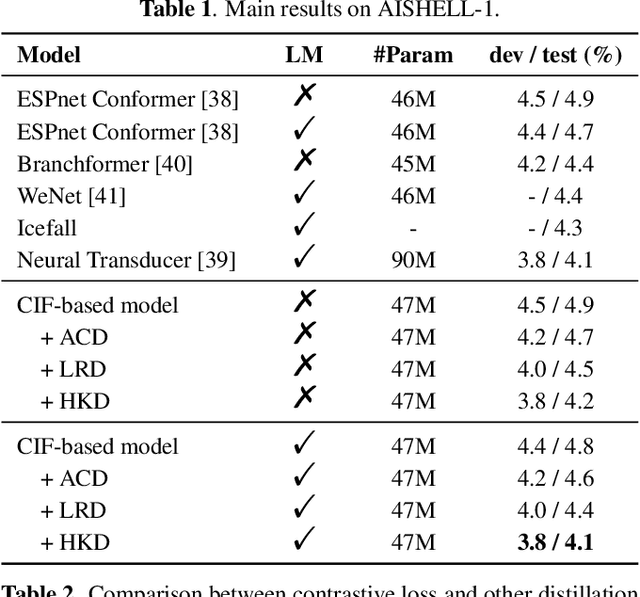
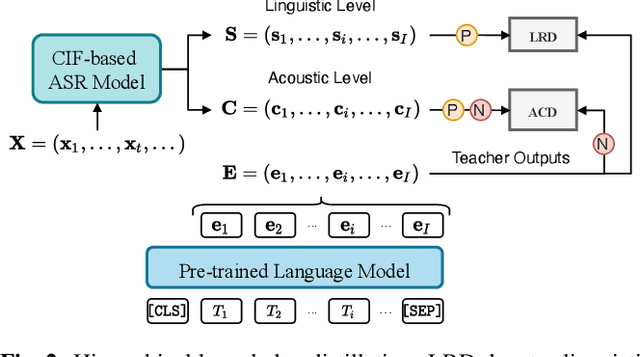
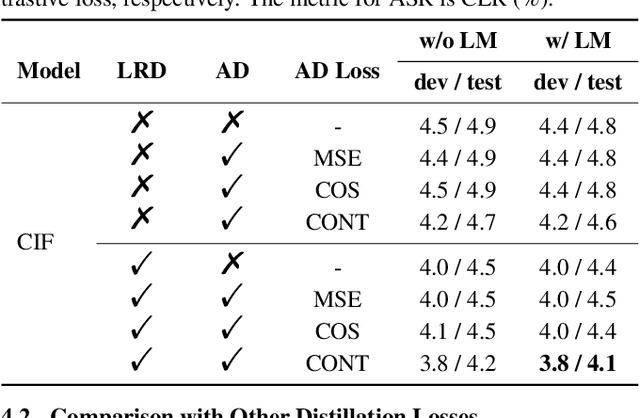
Large-scale pre-trained language models (PLMs) with powerful language modeling capabilities have been widely used in natural language processing. For automatic speech recognition (ASR), leveraging PLMs to improve performance has also become a promising research trend. However, most previous works may suffer from the inflexible sizes and structures of PLMs, along with the insufficient utilization of the knowledge in PLMs. To alleviate these problems, we propose the hierarchical knowledge distillation on the continuous integrate-and-fire (CIF) based ASR models. Specifically, we distill the knowledge from PLMs to the ASR model by applying cross-modal distillation with contrastive loss at the acoustic level and applying distillation with regression loss at the linguistic level. On the AISHELL-1 dataset, our method achieves 15% relative error rate reduction over the original CIF-based model and achieves comparable performance (3.8%/4.1% on dev/test) to the state-of-the-art model.
CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Nov 26, 2022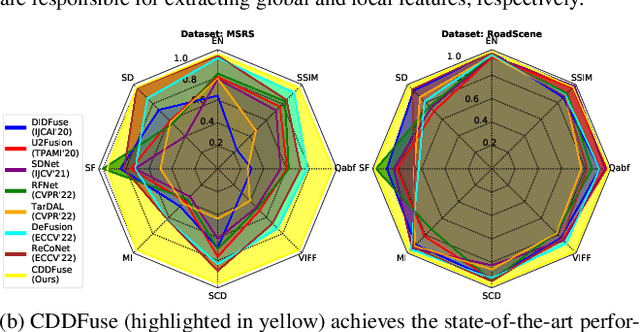
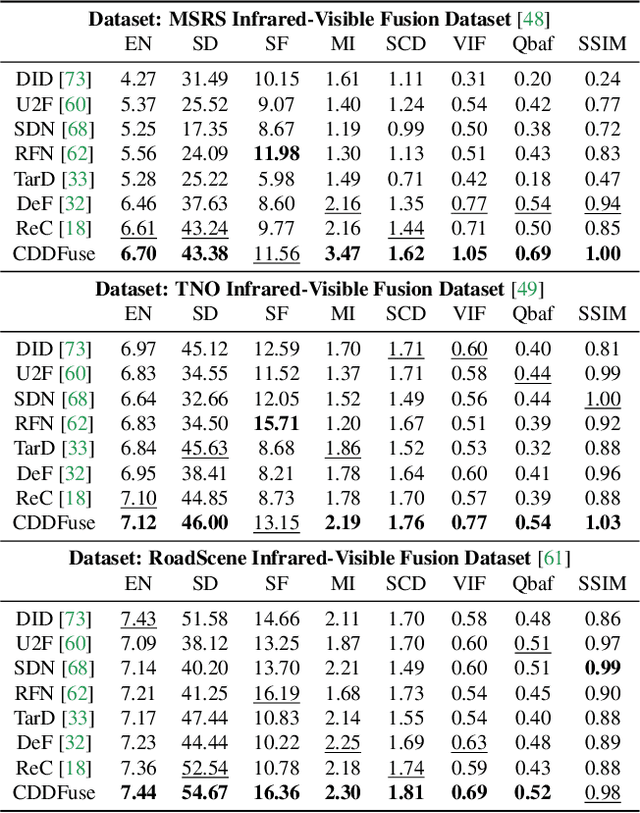
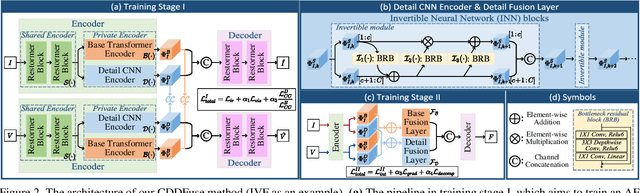
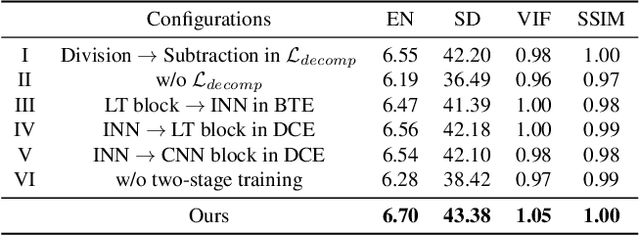
Multi-modality (MM) image fusion aims to render fused images that maintain the merits of different modalities, e.g., functional highlight and detailed textures. To tackle the challenge in modeling cross-modality features and decomposing desirable modality-specific and modality-shared features, we propose a novel Correlation-Driven feature Decomposition Fusion (CDDFuse) network for end-to-end MM feature decomposition and image fusion. In the first stage of the two-stage architectures, CDDFuse uses Restormer blocks to extract cross-modality shallow features. We then introduce a dual-branch Transformer-CNN feature extractor with Lite Transformer (LT) blocks leveraging long-range attention to handle low-frequency global features and Invertible Neural Networks (INN) blocks focusing on extracting high-frequency local information. Upon the embedded semantic information, the low-frequency features should be correlated while the high-frequency features should be uncorrelated. Thus, we propose a correlation-driven loss for better feature decomposition. In the second stage, the LT-based global fusion and INN-based local fusion layers output the fused image. Extensive experiments demonstrate that our CDDFuse achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. We also show that CDDFuse can boost the performance in downstream infrared-visible semantic segmentation and object detection in a unified benchmark.
Improving Cross-Modal Understanding in Visual Dialog via Contrastive Learning
Apr 15, 2022
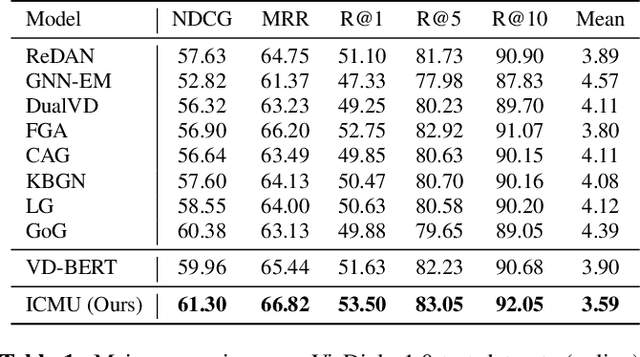
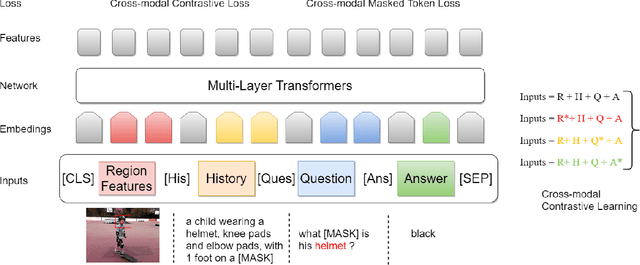
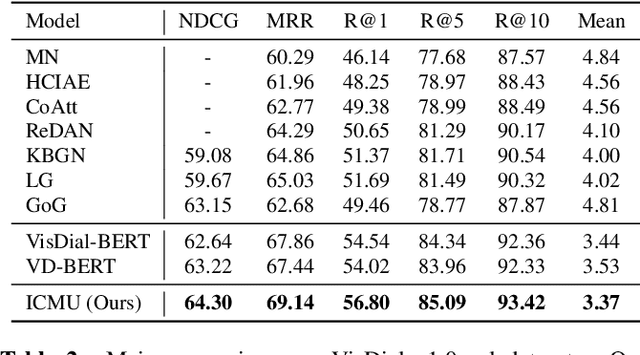
Visual Dialog is a challenging vision-language task since the visual dialog agent needs to answer a series of questions after reasoning over both the image content and dialog history. Though existing methods try to deal with the cross-modal understanding in visual dialog, they are still not enough in ranking candidate answers based on their understanding of visual and textual contexts. In this paper, we analyze the cross-modal understanding in visual dialog based on the vision-language pre-training model VD-BERT and propose a novel approach to improve the cross-modal understanding for visual dialog, named ICMU. ICMU enhances cross-modal understanding by distinguishing different pulled inputs (i.e. pulled images, questions or answers) based on four-way contrastive learning. In addition, ICMU exploits the single-turn visual question answering to enhance the visual dialog model's cross-modal understanding to handle a multi-turn visually-grounded conversation. Experiments show that the proposed approach improves the visual dialog model's cross-modal understanding and brings satisfactory gain to the VisDial dataset.
Two-Level Supervised Contrastive Learning for Response Selection in Multi-Turn Dialogue
Mar 01, 2022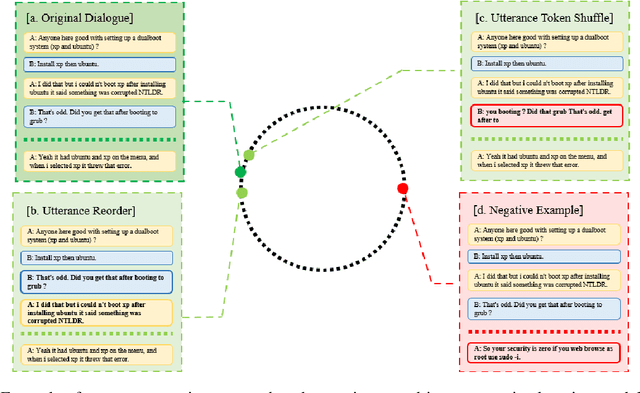
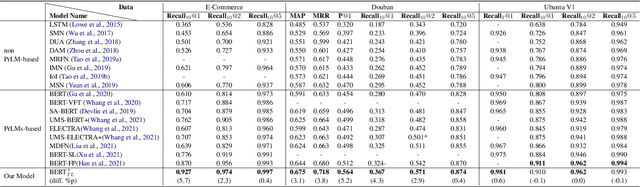
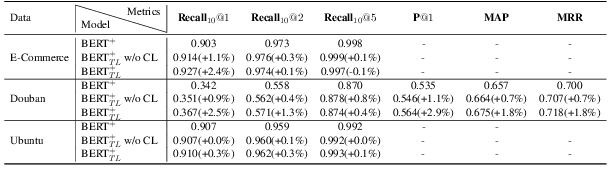
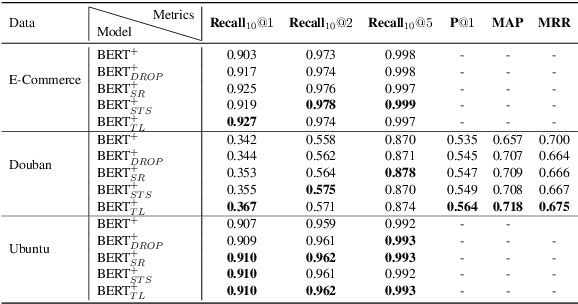
Selecting an appropriate response from many candidates given the utterances in a multi-turn dialogue is the key problem for a retrieval-based dialogue system. Existing work formalizes the task as matching between the utterances and a candidate and uses the cross-entropy loss in learning of the model. This paper applies contrastive learning to the problem by using the supervised contrastive loss. In this way, the learned representations of positive examples and representations of negative examples can be more distantly separated in the embedding space, and the performance of matching can be enhanced. We further develop a new method for supervised contrastive learning, referred to as two-level supervised contrastive learning, and employ the method in response selection in multi-turn dialogue. Our method exploits two techniques: sentence token shuffling (STS) and sentence re-ordering (SR) for supervised contrastive learning. Experimental results on three benchmark datasets demonstrate that the proposed method significantly outperforms the contrastive learning baseline and the state-of-the-art methods for the task.
VLP: A Survey on Vision-Language Pre-training
Feb 21, 2022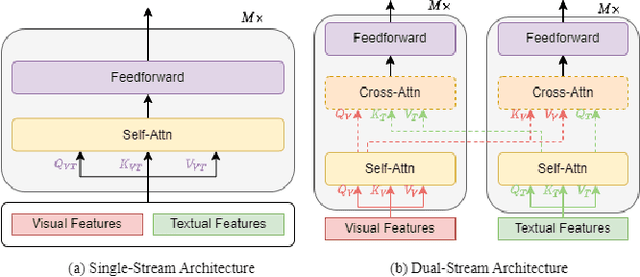
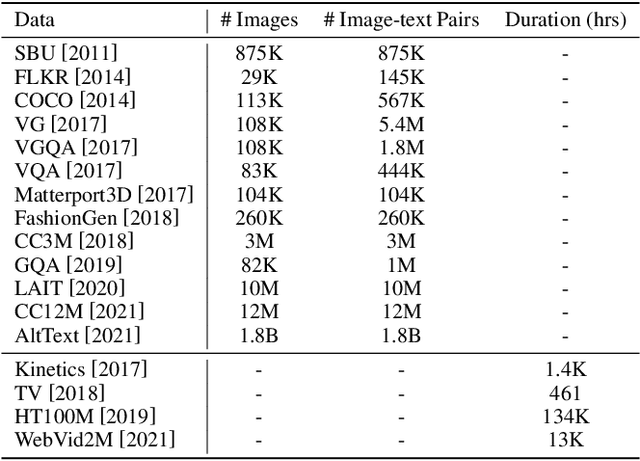
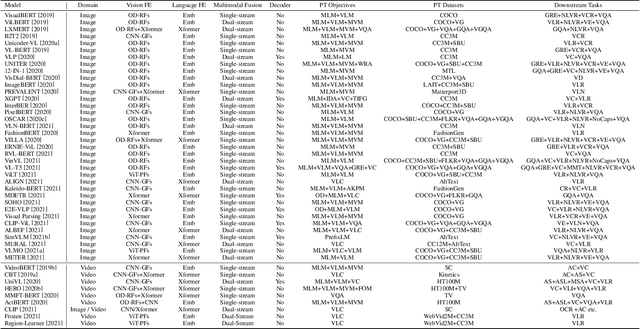
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.
Discrete Cosine Transform Network for Guided Depth Map Super-Resolution
Apr 14, 2021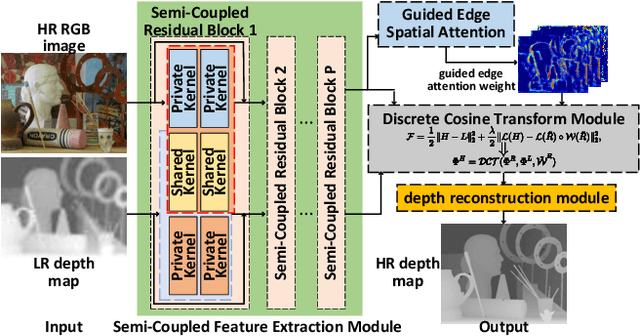
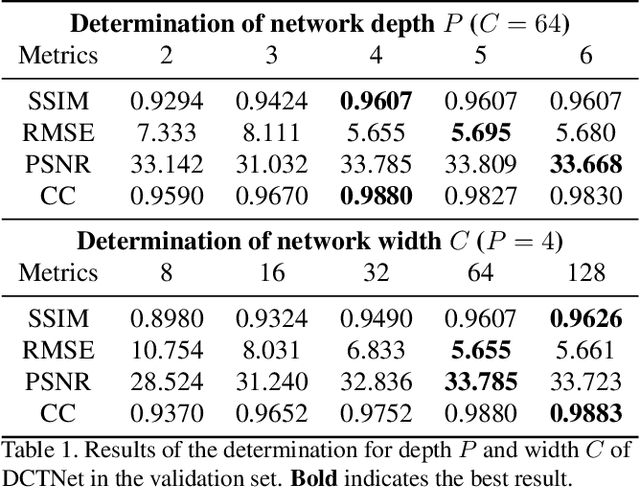
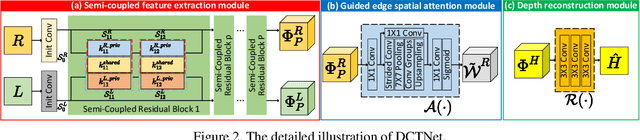
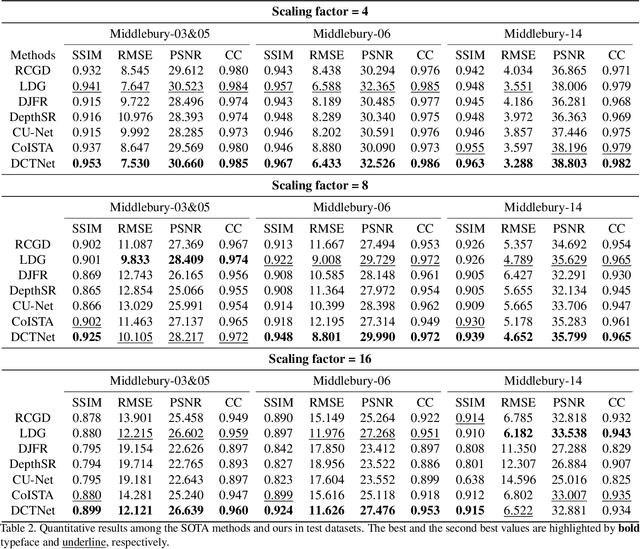
Guided depth super-resolution (GDSR) is a hot topic in multi-modal image processing. The goal is to use high-resolution (HR) RGB images to provide extra information on edges and object contours, so that low-resolution depth maps can be upsampled to HR ones. To solve the issues of RGB texture over-transferred, cross-modal feature extraction difficulty and unclear working mechanism of modules in existing methods, we propose an advanced Discrete Cosine Transform Network (DCTNet), which is composed of four components. Firstly, the paired RGB/depth images are input into the semi-coupled feature extraction module. The shared convolution kernels extract the cross-modal common features, and the private kernels extract their unique features, respectively. Then the RGB features are input into the edge attention mechanism to highlight the edges useful for upsampling. Subsequently, in the Discrete Cosine Transform (DCT) module, where DCT is employed to solve the optimization problem designed for image domain GDSR. The solution is then extended to implement the multi-channel RGB/depth features upsampling, which increases the rationality of DCTNet, and is more flexible and effective than conventional methods. The final depth prediction is output by the reconstruction module. Numerous qualitative and quantitative experiments demonstrate the effectiveness of our method, which can generate accurate and HR depth maps, surpassing state-of-the-art methods. Meanwhile, the rationality of modules is also proved by ablation experiments.