 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublic Data-Assisted Mirror Descent for Private Model Training
Dec 01, 2021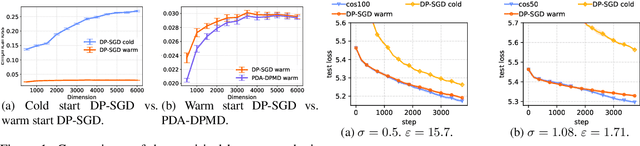
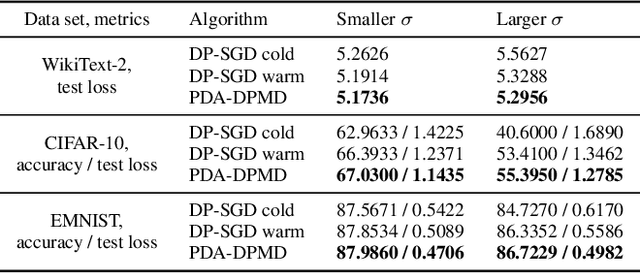

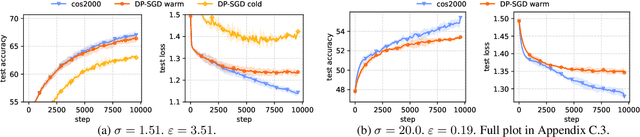
We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.
Vis2Mesh: Efficient Mesh Reconstruction from Unstructured Point Clouds of Large Scenes with Learned Virtual View Visibility
Aug 18, 2021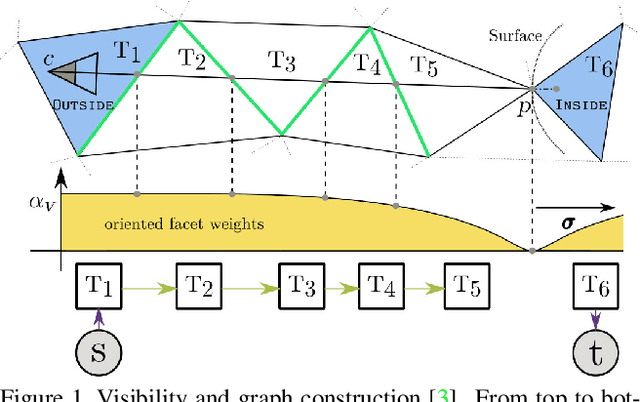
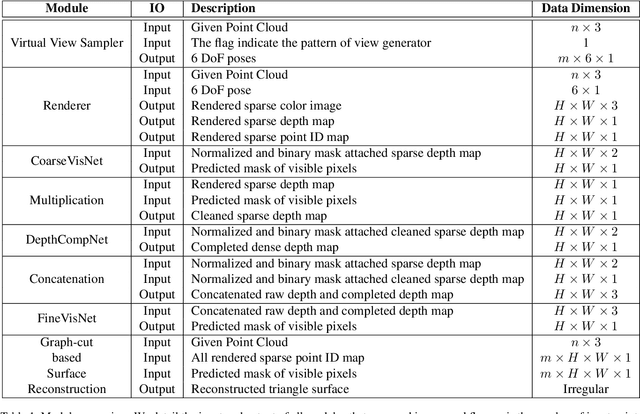
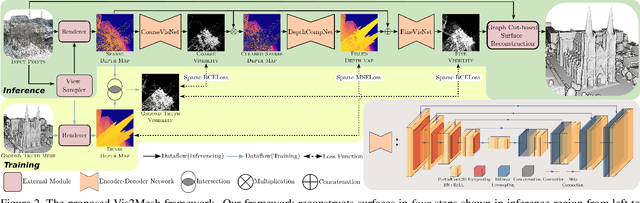
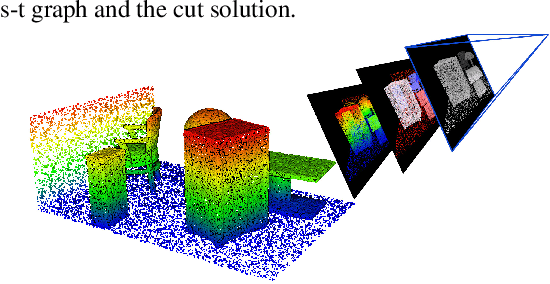
We present a novel framework for mesh reconstruction from unstructured point clouds by taking advantage of the learned visibility of the 3D points in the virtual views and traditional graph-cut based mesh generation. Specifically, we first propose a three-step network that explicitly employs depth completion for visibility prediction. Then the visibility information of multiple views is aggregated to generate a 3D mesh model by solving an optimization problem considering visibility in which a novel adaptive visibility weighting in surface determination is also introduced to suppress line of sight with a large incident angle. Compared to other learning-based approaches, our pipeline only exercises the learning on a 2D binary classification task, \ie, points visible or not in a view, which is much more generalizable and practically more efficient and capable to deal with a large number of points. Experiments demonstrate that our method with favorable transferability and robustness, and achieve competing performances \wrt state-of-the-art learning-based approaches on small complex objects and outperforms on large indoor and outdoor scenes. Code is available at https://github.com/GDAOSU/vis2mesh.
A volumetric change detection framework using UAV oblique photogrammetry - A case study of ultra-high-resolution monitoring of progressive building collapse
Aug 05, 2021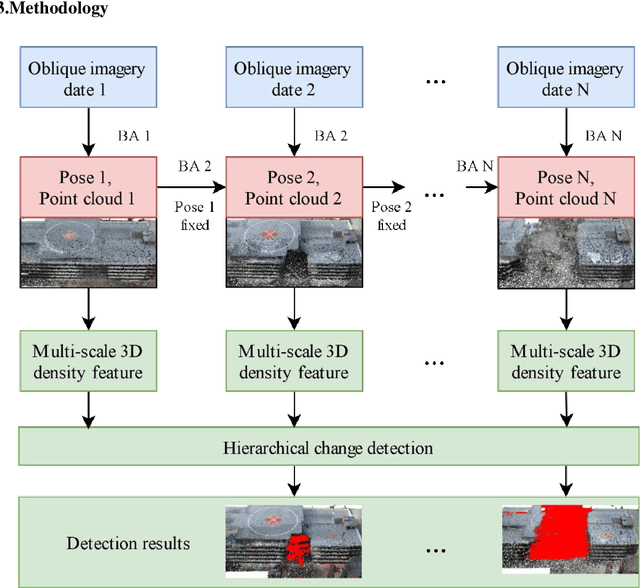

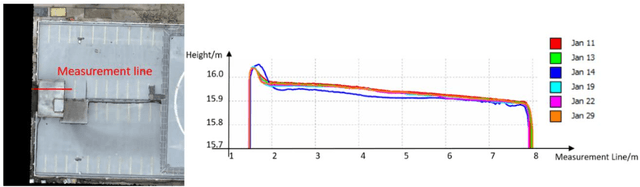
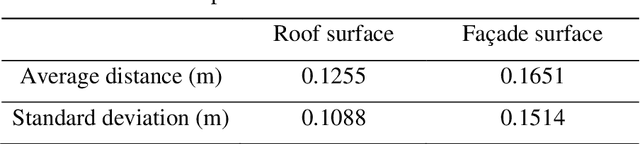
In this paper, we present a case study that performs an unmanned aerial vehicle (UAV) based fine-scale 3D change detection and monitoring of progressive collapse performance of a building during a demolition event. Multi-temporal oblique photogrammetry images are collected with 3D point clouds generated at different stages of the demolition. The geometric accuracy of the generated point clouds has been evaluated against both airborne and terrestrial LiDAR point clouds, achieving an average distance of 12 cm and 16 cm for roof and facade respectively. We propose a hierarchical volumetric change detection framework that unifies multi-temporal UAV images for pose estimation (free of ground control points), reconstruction, and a coarse-to-fine 3D density change analysis. This work has provided a solution capable of addressing change detection on full 3D time-series datasets where dramatic scene content changes are presented progressively. Our change detection results on the building demolition event have been evaluated against the manually marked ground-truth changes and have achieved an F-1 score varying from 0.78 to 0.92, with consistently high precision (0.92 - 0.99). Volumetric changes through the demolition progress are derived from change detection and have shown to favorably reflect the qualitative and quantitative building demolition progression.
Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates
Jul 20, 2021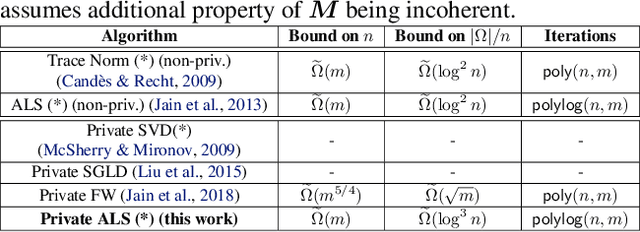
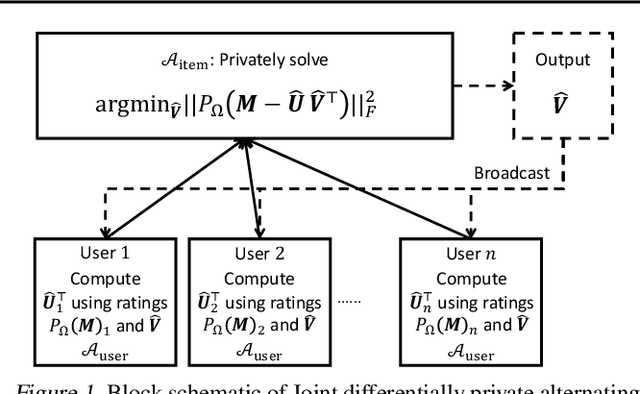
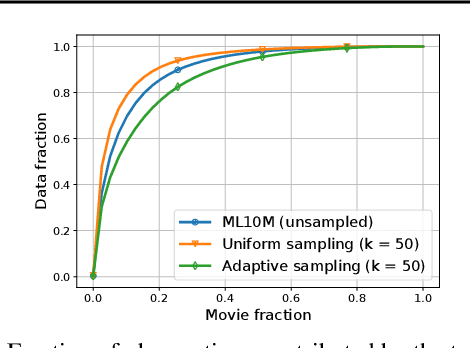
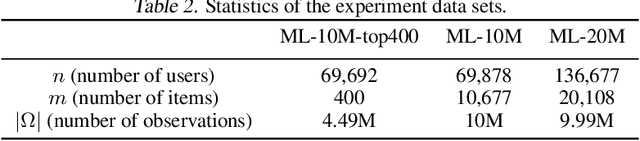
We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.
3D Reconstruction through Fusion of Cross-View Images
Jun 27, 2021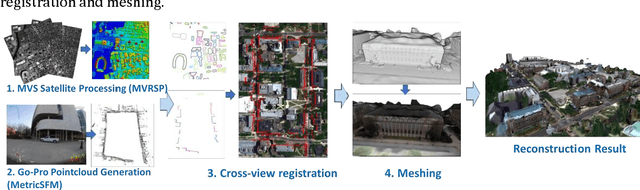
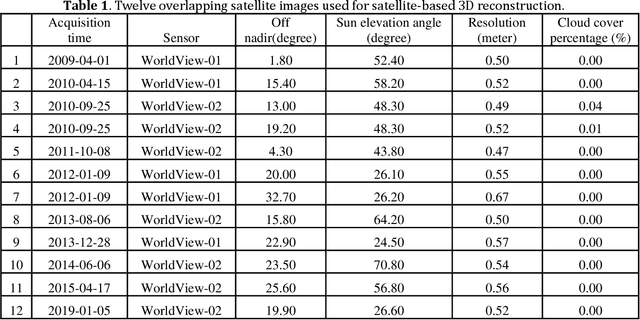

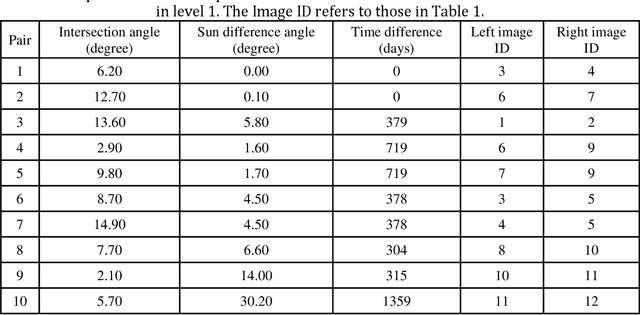
3D recovery from multi-stereo and stereo images, as an important application of the image-based perspective geometry, serves many applications in computer vision, remote sensing and Geomatics. In this chapter, the authors utilize the imaging geometry and present approaches that perform 3D reconstruction from cross-view images that are drastically different in their viewpoints. We introduce our framework that takes ground-view images and satellite images for full 3D recovery, which includes necessary methods in satellite and ground-based point cloud generation from images, 3D data co-registration, fusion and mesh generation. We demonstrate our proposed framework on a dataset consisting of twelve satellite images and 150k video frames acquired through a vehicle-mounted Go-pro camera and demonstrate the reconstruction results. We have also compared our results with results generated from an intuitive processing pipeline that involves typical geo-registration and meshing methods.
Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Jun 10, 2021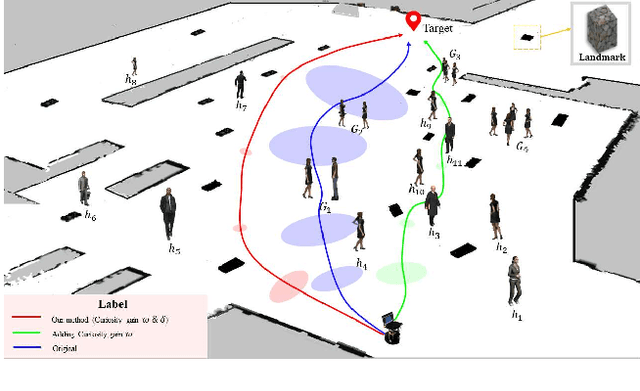
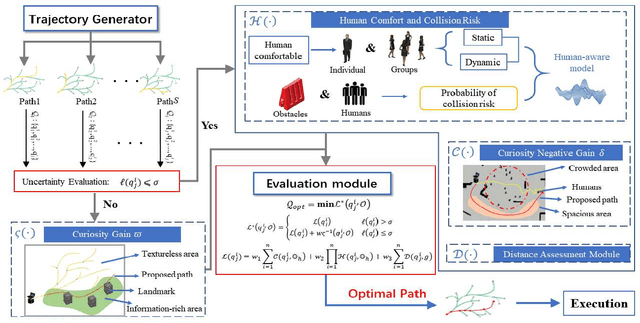
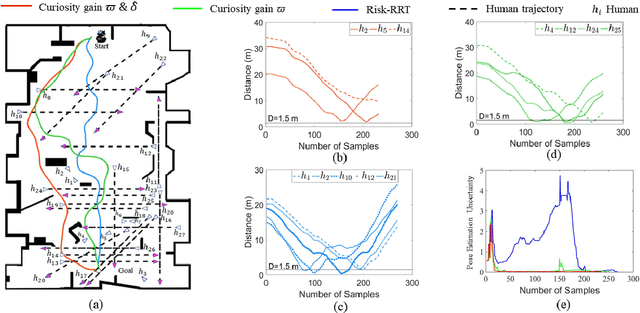

Mobile robots have become more and more popular in our daily life. In large-scale and crowded environments, how to navigate safely with localization precision is a critical problem. To solve this problem, we proposed a curiosity-based framework that can find an effective path with the consideration of human comfort, localization uncertainty, crowds, and the cost-to-go to the target. Three parts are involved in the proposed framework: the distance assessment module, the curiosity gain of the information-rich area, and the curiosity negative gain of crowded areas. The curiosity gain of the information-rich area was proposed to provoke the robot to approach localization referenced landmarks. To guarantee human comfort while coexisting with robots, we propose curiosity gain of the spacious area to bypass the crowd and maintain an appropriate distance between robots and humans. The evaluation is conducted in an unstructured environment. The results show that our method can find a feasible path, which can consider the localization uncertainty while simultaneously avoiding the crowded area. Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Practical and Private (Deep) Learning without Sampling or Shuffling
Feb 26, 2021
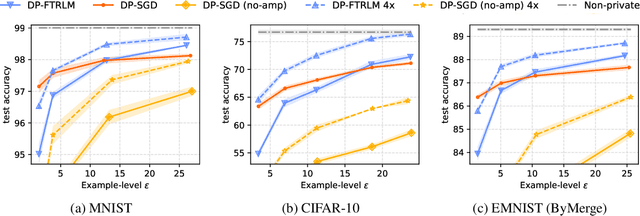
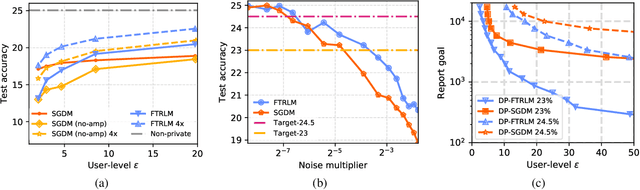
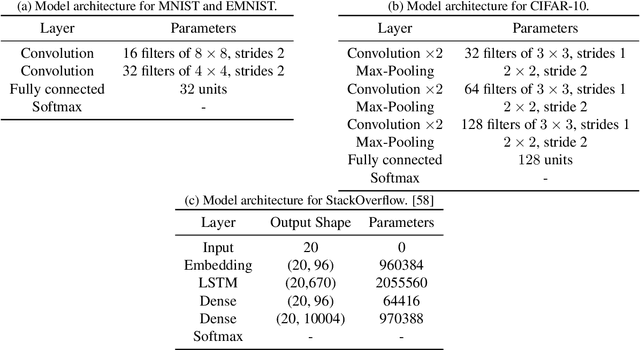
We consider training models with differential privacy (DP) using mini-batch gradients. The existing state-of-the-art, Differentially Private Stochastic Gradient Descent (DP-SGD), requires privacy amplification by sampling or shuffling to obtain the best privacy/accuracy/computation trade-offs. Unfortunately, the precise requirements on exact sampling and shuffling can be hard to obtain in important practical scenarios, particularly federated learning (FL). We design and analyze a DP variant of Follow-The-Regularized-Leader (DP-FTRL) that compares favorably (both theoretically and empirically) to amplified DP-SGD, while allowing for much more flexible data access patterns. DP-FTRL does not use any form of privacy amplification.
Adversary Instantiation: Lower Bounds for Differentially Private Machine Learning
Jan 11, 2021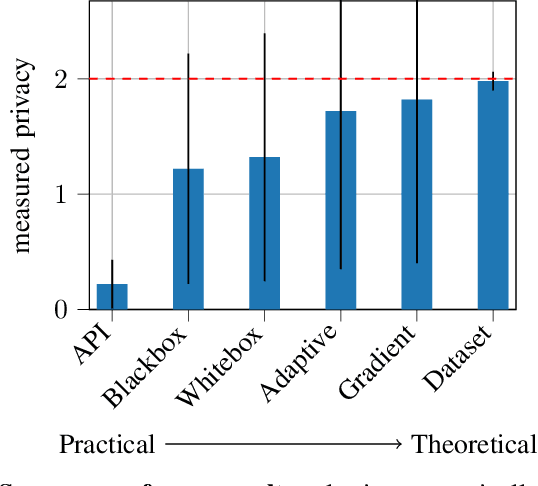
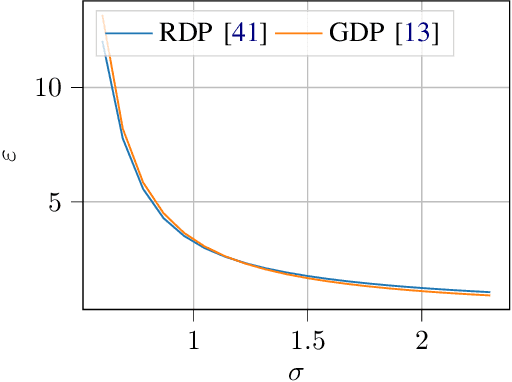
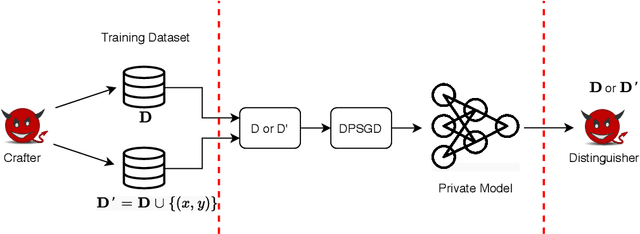
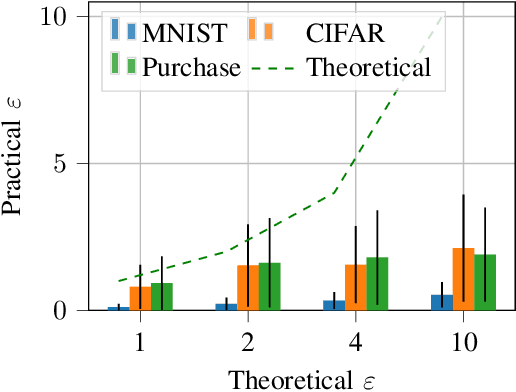
Differentially private (DP) machine learning allows us to train models on private data while limiting data leakage. DP formalizes this data leakage through a cryptographic game, where an adversary must predict if a model was trained on a dataset D, or a dataset D' that differs in just one example.If observing the training algorithm does not meaningfully increase the adversary's odds of successfully guessing which dataset the model was trained on, then the algorithm is said to be differentially private. Hence, the purpose of privacy analysis is to upper bound the probability that any adversary could successfully guess which dataset the model was trained on.In our paper, we instantiate this hypothetical adversary in order to establish lower bounds on the probability that this distinguishing game can be won. We use this adversary to evaluate the importance of the adversary capabilities allowed in the privacy analysis of DP training algorithms.For DP-SGD, the most common method for training neural networks with differential privacy, our lower bounds are tight and match the theoretical upper bound. This implies that in order to prove better upper bounds, it will be necessary to make use of additional assumptions. Fortunately, we find that our attacks are significantly weaker when additional (realistic)restrictions are put in place on the adversary's capabilities.Thus, in the practical setting common to many real-world deployments, there is a gap between our lower bounds and the upper bounds provided by the analysis: differential privacy is conservative and adversaries may not be able to leak as much information as suggested by the theoretical bound.
An Attack on InstaHide: Is Private Learning Possible with Instance Encoding?
Nov 10, 2020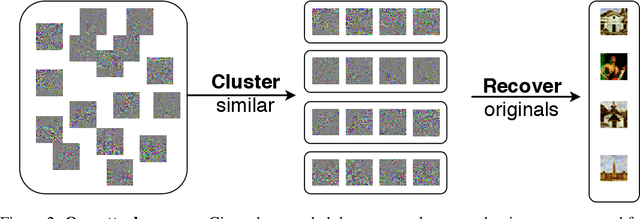



A learning algorithm is private if the produced model does not reveal (too much) about its training set. InstaHide [Huang, Song, Li, Arora, ICML'20] is a recent proposal that claims to preserve privacy by an encoding mechanism that modifies the inputs before being processed by the normal learner. We present a reconstruction attack on InstaHide that is able to use the encoded images to recover visually recognizable versions of the original images. Our attack is effective and efficient, and empirically breaks InstaHide on CIFAR-10, CIFAR-100, and the recently released InstaHide Challenge. We further formalize various privacy notions of learning through instance encoding and investigate the possibility of achieving these notions. We prove barriers against achieving (indistinguishability based notions of) privacy through any learning protocol that uses instance encoding.
Tempered Sigmoid Activations for Deep Learning with Differential Privacy
Jul 28, 2020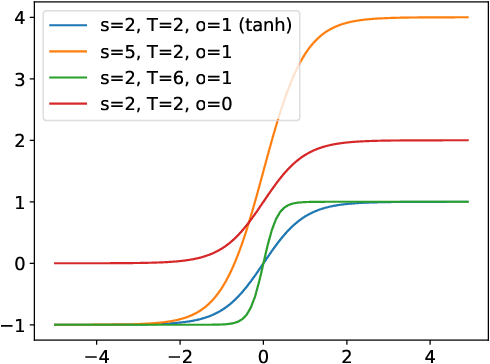
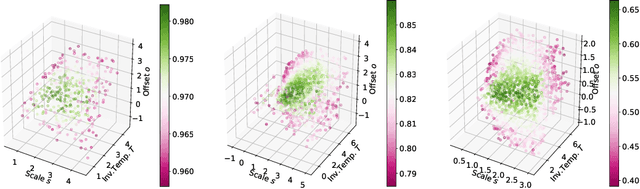
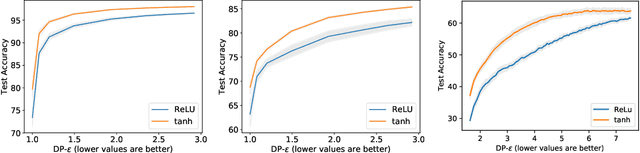

Because learning sometimes involves sensitive data, machine learning algorithms have been extended to offer privacy for training data. In practice, this has been mostly an afterthought, with privacy-preserving models obtained by re-running training with a different optimizer, but using the model architectures that already performed well in a non-privacy-preserving setting. This approach leads to less than ideal privacy/utility tradeoffs, as we show here. Instead, we propose that model architectures are chosen ab initio explicitly for privacy-preserving training. To provide guarantees under the gold standard of differential privacy, one must bound as strictly as possible how individual training points can possibly affect model updates. In this paper, we are the first to observe that the choice of activation function is central to bounding the sensitivity of privacy-preserving deep learning. We demonstrate analytically and experimentally how a general family of bounded activation functions, the tempered sigmoids, consistently outperform unbounded activation functions like ReLU. Using this paradigm, we achieve new state-of-the-art accuracy on MNIST, FashionMNIST, and CIFAR10 without any modification of the learning procedure fundamentals or differential privacy analysis.