 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Good Enough Embedding for Easy Few-Shot Learning
May 13, 2026The field of deep visual recognition is undergoing a paradigm shift toward universal representations. The Platonic Representation Hypothesis suggests that diverse architectures trained on massive datasets are converging toward a shared, "ideal" latent space. This again raises a critical question: is a "Good Embedding All You Need?" In this paper, we leverage this convergence to demonstrate that off-the-shelf embeddings are inherently "good enough" for complex tasks, rendering intensive task-specific fine-tuning unnecessary. We explore this hypothesis within the few-shot learning framework, proposing a straightforward, non-parametric pipeline that entirely bypasses backpropagation. By utilizing a k-Nearest Neighbor classifier on frozen DINOv2-L features, we conduct a layer-wise characterization to identify an optimal feature extraction. We further demonstrate that manifold refinement via PCA and ICA provides a beneficial regularizing effect. Our results across four major benchmarks demonstrate that our approach consistently surpasses sophisticated meta-learning algorithms, achieving state-of-the-art performance.
Toward Aristotelian Medical Representations: Backpropagation-Free Layer-wise Analysis for Interpretable Generalized Metric Learning on MedMNIST
Apr 07, 2026While deep learning has achieved remarkable success in medical imaging, the "black-box" nature of backpropagation-based models remains a significant barrier to clinical adoption. To bridge this gap, we propose Aristotelian Rapid Object Modeling (A-ROM), a framework built upon the Platonic Representation Hypothesis (PRH). This hypothesis posits that models trained on vast, diverse datasets converge toward a universal and objective representation of reality. By leveraging the generalizable metric space of pretrained Vision Transformers (ViTs), A-ROM enables the rapid modeling of novel medical concepts without the computational burden or opacity of further gradient-based fine-tuning. We replace traditional, opaque decision layers with a human-readable concept dictionary and a k-Nearest Neighbors (kNN) classifier to ensure the model's logic remains interpretable. Experiments on the MedMNIST v2 suite demonstrate that A-ROM delivers performance competitive with standard benchmarks while providing a simple and scalable, "few-shot" solution that meets the rigorous transparency demands of modern clinical environments.
Enhancing Policy Learning with World-Action Model
Mar 30, 2026This paper presents the World-Action Model (WAM), an action-regularized world model that jointly reasons over future visual observations and the actions that drive state transitions. Unlike conventional world models trained solely via image prediction, WAM incorporates an inverse dynamics objective into DreamerV2 that predicts actions from latent state transitions, encouraging the learned representations to capture action-relevant structure critical for downstream control. We evaluate WAM on enhancing policy learning across eight manipulation tasks from the CALVIN benchmark. We first pretrain a diffusion policy via behavioral cloning on world model latents, then refine it with model-based PPO inside the frozen world model. Without modifying the policy architecture or training procedure, WAM improves average behavioral cloning success from 59.4% to 71.2% over DreamerV2 and DiWA baselines. After PPO fine-tuning, WAM achieves 92.8% average success versus 79.8% for the baseline, with two tasks reaching 100%, using 8.7x fewer training steps.
Zero-shot Vision-Language Reranking for Cross-View Geolocalization
Mar 28, 2026Cross-view geolocalization (CVGL) systems, while effective at retrieving a list of relevant candidates (high Recall@k), often fail to identify the single best match (low Top-1 accuracy). This work investigates the use of zero-shot Vision-Language Models (VLMs) as rerankers to address this gap. We propose a two-stage framework: state-of-the-art (SOTA) retrieval followed by VLM reranking. We systematically compare two strategies: (1) Pointwise (scoring candidates individually) and (2) Pairwise (comparing candidates relatively). Experiments on the VIGOR dataset show a clear divergence: all pointwise methods cause a catastrophic drop in performance or no change at all. In contrast, a pairwise comparison strategy using LLaVA improves Top-1 accuracy over the strong retrieval baseline. Our analysis concludes that, these VLMs are poorly calibrated for absolute relevance scoring but are effective at fine-grained relative visual judgment, making pairwise reranking a promising direction for enhancing CVGL precision.
Just Zoom In: Cross-View Geo-Localization via Autoregressive Zooming
Mar 26, 2026Cross-view geo-localization (CVGL) estimates a camera's location by matching a street-view image to geo-referenced overhead imagery, enabling GPS-denied localization and navigation. Existing methods almost universally formulate CVGL as an image-retrieval problem in a contrastively trained embedding space. This ties performance to large batches and hard negative mining, and it ignores both the geometric structure of maps and the coverage mismatch between street-view and overhead imagery. In particular, salient landmarks visible from the street view can fall outside a fixed satellite crop, making retrieval targets ambiguous and limiting explicit spatial inference over the map. We propose Just Zoom In, an alternative formulation that performs CVGL via autoregressive zooming over a city-scale overhead map. Starting from a coarse satellite view, the model takes a short sequence of zoom-in decisions to select a terminal satellite cell at a target resolution, without contrastive losses or hard negative mining. We further introduce a realistic benchmark with crowd-sourced street views and high-resolution satellite imagery that reflects real capture conditions. On this benchmark, Just Zoom In achieves state-of-the-art performance, improving Recall@1 within 50 m by 5.5% and Recall@1 within 100 m by 9.6% over the strongest contrastive-retrieval baseline. These results demonstrate the effectiveness of sequential coarse-to-fine spatial reasoning for cross-view geo-localization.
LLaVA-LE: Large Language-and-Vision Assistant for Lunar Exploration
Mar 25, 2026Recent advances in multimodal vision-language models (VLMs) have enabled joint reasoning over visual and textual information, yet their application to planetary science remains largely unexplored. A key hindrance is the absence of large-scale datasets that pair real planetary imagery with detailed scientific descriptions. In this work, we introduce LLaVA-LE (Large Language-and-Vision Assistant for Lunar Exploration), a vision-language model specialized for lunar surface and subsurface characterization. To enable this capability, we curate a new large-scale multimodal lunar dataset, LUCID (LUnar Caption Image Dataset) consisting of 96k high-resolution panchromatic images paired with detailed captions describing lunar terrain characteristics, and 81k question-answer (QA) pairs derived from approximately 20k images in the LUCID dataset. Leveraging this dataset, we fine-tune LLaVA using a two-stage training curriculum: (1) concept alignment for domain-specific terrain description, and (2) instruction-tuned visual question answering. We further design evaluation benchmarks spanning multiple levels of reasoning complexity relevant to lunar terrain analysis. Evaluated against GPT and Gemini judges, LLaVA-LE achieves a 3.3x overall performance gain over Base LLaVA and 2.1x over our Stage 1 model, with a reasoning score of 1.070, exceeding the judge's own reference score, highlighting the effectiveness of domain-specific multimodal data and instruction tuning to advance VLMs in planetary exploration. Code is available at https://github.com/OSUPCVLab/LLaVA-LE.
BetterScene: 3D Scene Synthesis with Representation-Aligned Generative Model
Feb 26, 2026We present BetterScene, an approach to enhance novel view synthesis (NVS) quality for diverse real-world scenes using extremely sparse, unconstrained photos. BetterScene leverages the production-ready Stable Video Diffusion (SVD) model pretrained on billions of frames as a strong backbone, aiming to mitigate artifacts and recover view-consistent details at inference time. Conventional methods have developed similar diffusion-based solutions to address these challenges of novel view synthesis. Despite significant improvements, these methods typically rely on off-the-shelf pretrained diffusion priors and fine-tune only the UNet module while keeping other components frozen, which still leads to inconsistent details and artifacts even when incorporating geometry-aware regularizations like depth or semantic conditions. To address this, we investigate the latent space of the diffusion model and introduce two components: (1) temporal equivariance regularization and (2) vision foundation model-aligned representation, both applied to the variational autoencoder (VAE) module within the SVD pipeline. BetterScene integrates a feed-forward 3D Gaussian Splatting (3DGS) model to render features as inputs for the SVD enhancer and generate continuous, artifact-free, consistent novel views. We evaluate on the challenging DL3DV-10K dataset and demonstrate superior performance compared to state-of-the-art methods.
MotivNet: Evolving Meta-Sapiens into an Emotionally Intelligent Foundation Model
Dec 30, 2025In this paper, we introduce MotivNet, a generalizable facial emotion recognition model for robust real-world application. Current state-of-the-art FER models tend to have weak generalization when tested on diverse data, leading to deteriorated performance in the real world and hindering FER as a research domain. Though researchers have proposed complex architectures to address this generalization issue, they require training cross-domain to obtain generalizable results, which is inherently contradictory for real-world application. Our model, MotivNet, achieves competitive performance across datasets without cross-domain training by using Meta-Sapiens as a backbone. Sapiens is a human vision foundational model with state-of-the-art generalization in the real world through large-scale pretraining of a Masked Autoencoder. We propose MotivNet as an additional downstream task for Sapiens and define three criteria to evaluate MotivNet's viability as a Sapiens task: benchmark performance, model similarity, and data similarity. Throughout this paper, we describe the components of MotivNet, our training approach, and our results showing MotivNet is generalizable across domains. We demonstrate that MotivNet can be benchmarked against existing SOTA models and meets the listed criteria, validating MotivNet as a Sapiens downstream task, and making FER more incentivizing for in-the-wild application. The code is available at https://github.com/OSUPCVLab/EmotionFromFaceImages.
Multivariate Gaussian Representation Learning for Medical Action Evaluation
Nov 13, 2025



Fine-grained action evaluation in medical vision faces unique challenges due to the unavailability of comprehensive datasets, stringent precision requirements, and insufficient spatiotemporal dynamic modeling of very rapid actions. To support development and evaluation, we introduce CPREval-6k, a multi-view, multi-label medical action benchmark containing 6,372 expert-annotated videos with 22 clinical labels. Using this dataset, we present GaussMedAct, a multivariate Gaussian encoding framework, to advance medical motion analysis through adaptive spatiotemporal representation learning. Multivariate Gaussian Representation projects the joint motions to a temporally scaled multi-dimensional space, and decomposes actions into adaptive 3D Gaussians that serve as tokens. These tokens preserve motion semantics through anisotropic covariance modeling while maintaining robustness to spatiotemporal noise. Hybrid Spatial Encoding, employing a Cartesian and Vector dual-stream strategy, effectively utilizes skeletal information in the form of joint and bone features. The proposed method achieves 92.1% Top-1 accuracy with real-time inference on the benchmark, outperforming the ST-GCN baseline by +5.9% accuracy with only 10% FLOPs. Cross-dataset experiments confirm the superiority of our method in robustness.
Lightweight Road Environment Segmentation using Vector Quantization
Apr 19, 2025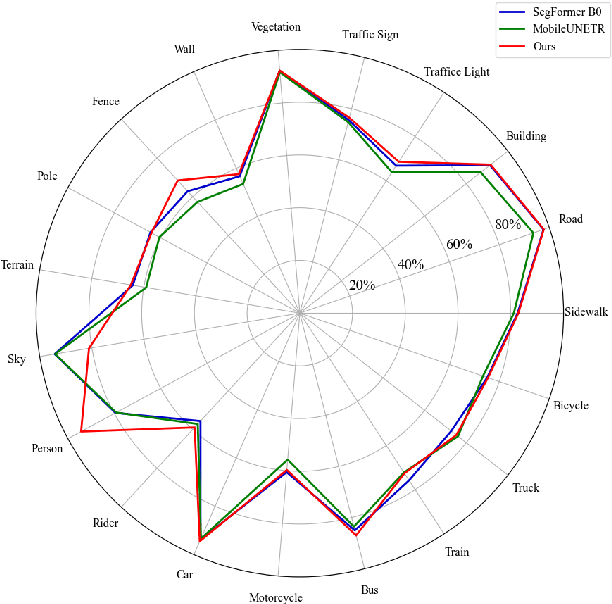

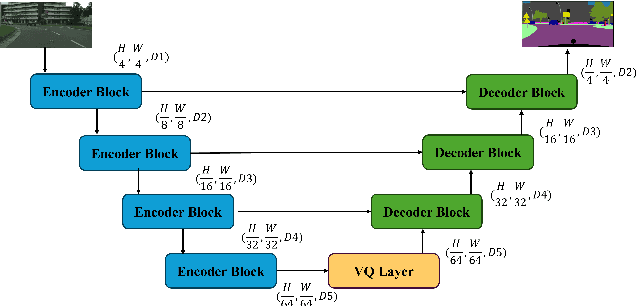
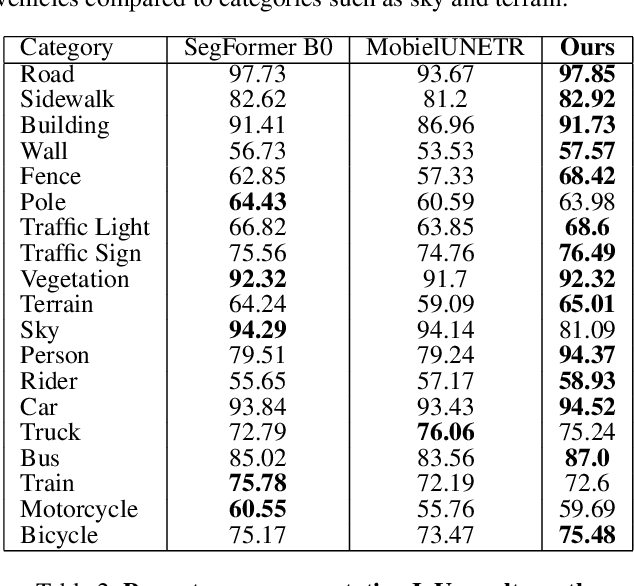
Road environment segmentation plays a significant role in autonomous driving. Numerous works based on Fully Convolutional Networks (FCNs) and Transformer architectures have been proposed to leverage local and global contextual learning for efficient and accurate semantic segmentation. In both architectures, the encoder often relies heavily on extracting continuous representations from the image, which limits the ability to represent meaningful discrete information. To address this limitation, we propose segmentation of the autonomous driving environment using vector quantization. Vector quantization offers three primary advantages for road environment segmentation. (1) Each continuous feature from the encoder is mapped to a discrete vector from the codebook, helping the model discover distinct features more easily than with complex continuous features. (2) Since a discrete feature acts as compressed versions of the encoder's continuous features, they also compress noise or outliers, enhancing the image segmentation task. (3) Vector quantization encourages the latent space to form coarse clusters of continuous features, forcing the model to group similar features, making the learned representations more structured for the decoding process. In this work, we combined vector quantization with the lightweight image segmentation model MobileUNETR and used it as a baseline model for comparison to demonstrate its efficiency. Through experiments, we achieved 77.0 % mIoU on Cityscapes, outperforming the baseline by 2.9 % without increasing the model's initial size or complexity.