 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning
Apr 22, 2025Recent work shows that reinforcement learning(RL) can markedly sharpen the reasoning ability of large language models (LLMs) by prompting them to "think before answering." Yet whether and how these gains transfer to audio-language reasoning remains largely unexplored. We extend the Group-Relative Policy Optimization (GRPO) framework from DeepSeek-R1 to a Large Audio-Language Model (LALM), and construct a 32k sample multiple-choice corpus. Using a two-stage regimen supervised fine-tuning on structured and unstructured chains-of-thought, followed by curriculum-guided GRPO, we systematically compare implicit vs. explicit, and structured vs. free form reasoning under identical architectures. Our structured audio reasoning model, SARI (Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning), achieves a 16.35% improvement in average accuracy over the base model Qwen2-Audio-7B-Instruct. Furthermore, the variant built upon Qwen2.5-Omni reaches state-of-the-art performance of 67.08% on the MMAU test-mini benchmark. Ablation experiments show that on the base model we use: (i) SFT warm-up is important for stable RL training, (ii) structured chains yield more robust generalization than unstructured ones, and (iii) easy-to-hard curricula accelerate convergence and improve final performance. These findings demonstrate that explicit, structured reasoning and curriculum learning substantially enhances audio-language understanding.
Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
Dec 03, 2024



The GPT-4o represents a significant milestone in enabling real-time interaction with large language models (LLMs) through speech, its remarkable low latency and high fluency not only capture attention but also stimulate research interest in the field. This real-time speech interaction is particularly valuable in scenarios requiring rapid feedback and immediate responses, dramatically enhancing user experience. However, there is a notable lack of research focused on real-time large speech language models, particularly for Chinese. In this work, we present KE-Omni, a seamless large speech language model built upon Ke-SpeechChat, a large-scale high-quality synthetic speech interaction dataset consisting of 7 million Chinese and English conversations, featuring 42,002 speakers, and totaling over 60,000 hours, This contributes significantly to the advancement of research and development in this field. The demos can be accessed at \url{https://huggingface.co/spaces/KE-Team/KE-Omni}.
Technical Report: Competition Solution For BetterMixture
Mar 20, 2024In the era of flourishing large-scale models, the challenge of selecting and optimizing datasets from the vast and complex sea of data, to enhance the performance of large language models within the constraints of limited computational resources, has become paramount. This paper details our solution for the BetterMixture challenge, which focuses on the fine-tuning data mixing for large language models. Our approach, which secured third place, incorporates data deduplication, low-level and high-level quality filtering, and diversity selection. The foundation of our solution is Ke-Data-Juicer, an extension of Data-Juicer, demonstrating its robust capabilities in handling and optimizing data for large language models.
ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
Jul 28, 2023



This paper presents the development and evaluation of ChatHome, a domain-specific language model (DSLM) designed for the intricate field of home renovation. Considering the proven competencies of large language models (LLMs) like GPT-4 and the escalating fascination with home renovation, this study endeavors to reconcile these aspects by generating a dedicated model that can yield high-fidelity, precise outputs relevant to the home renovation arena. ChatHome's novelty rests on its methodology, fusing domain-adaptive pretraining and instruction-tuning over an extensive dataset. This dataset includes professional articles, standard documents, and web content pertinent to home renovation. This dual-pronged strategy is designed to ensure that our model can assimilate comprehensive domain knowledge and effectively address user inquiries. Via thorough experimentation on diverse datasets, both universal and domain-specific, including the freshly introduced "EvalHome" domain dataset, we substantiate that ChatHome not only amplifies domain-specific functionalities but also preserves its versatility.
Audio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022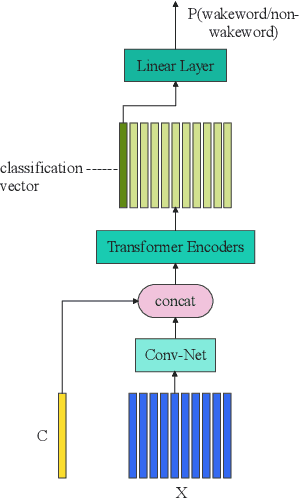
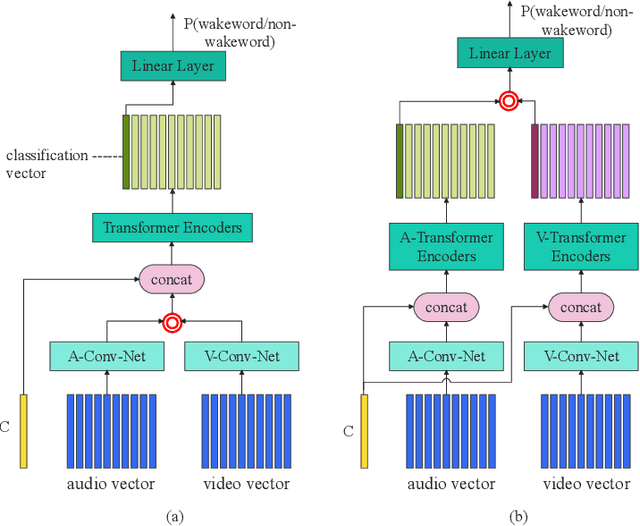

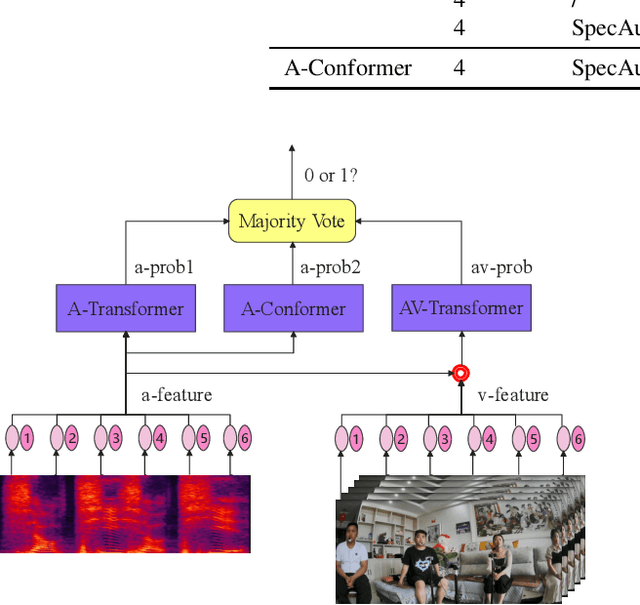
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021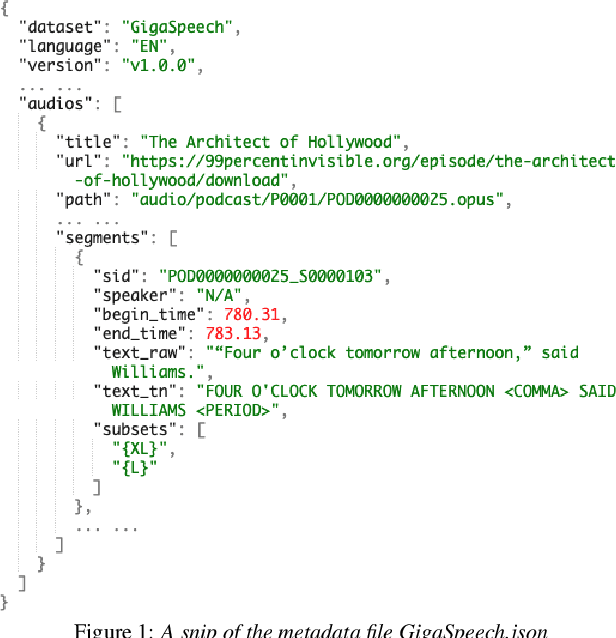
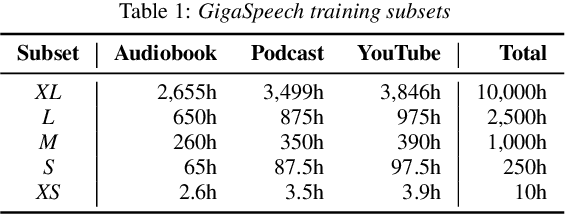
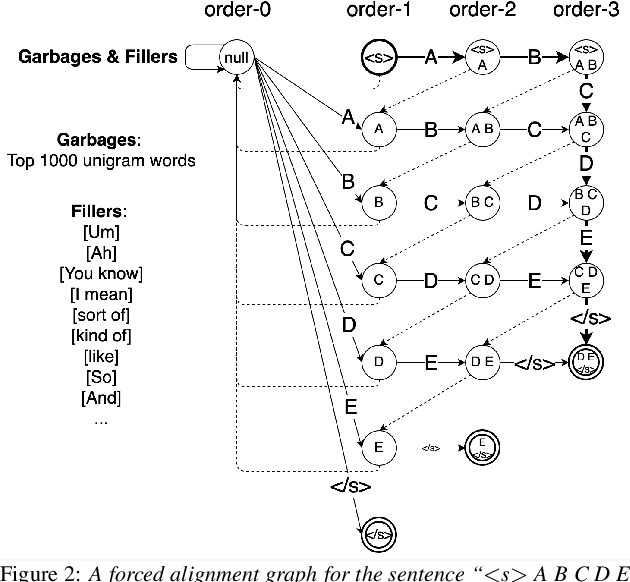
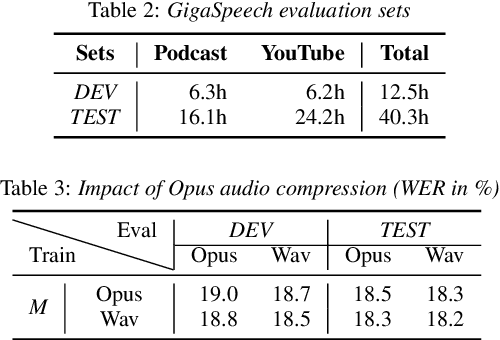
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021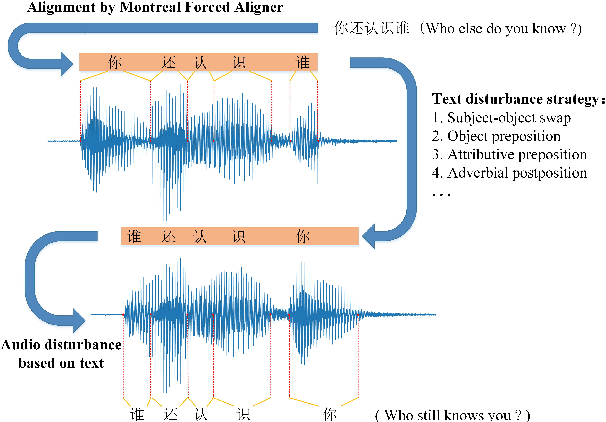


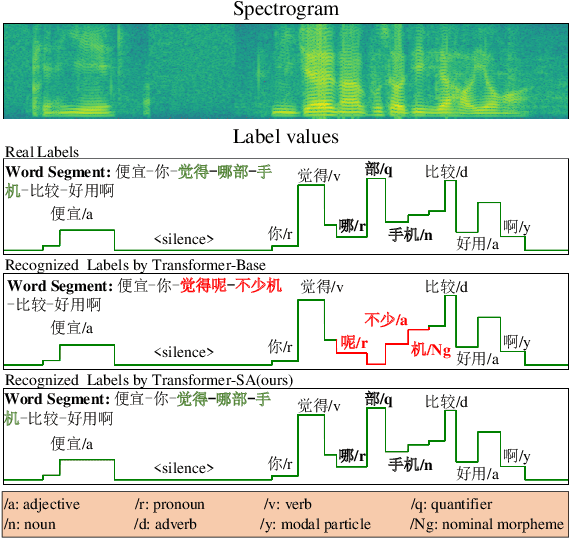
End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.
Towards End-to-End Code-Switching Speech Recognition
Nov 01, 2018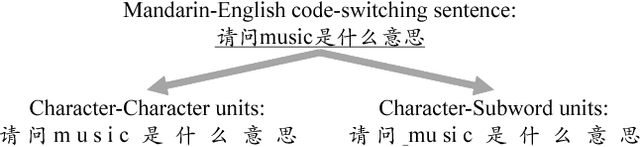
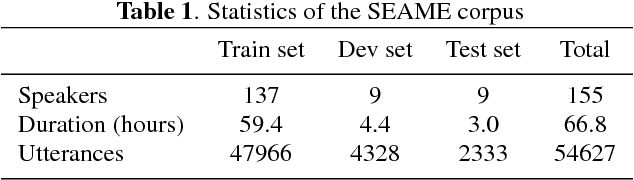
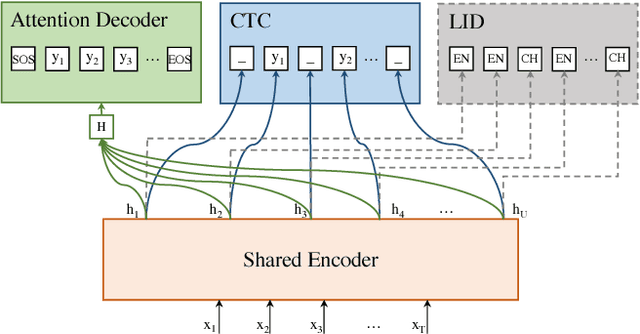
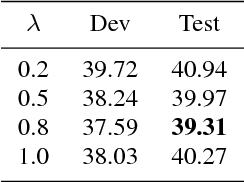
Code-switching speech recognition has attracted an increasing interest recently, but the need for expert linguistic knowledge has always been a big issue. End-to-end automatic speech recognition (ASR) simplifies the building of ASR systems considerably by predicting graphemes or characters directly from acoustic input. In the mean time, the need of expert linguistic knowledge is also eliminated, which makes it an attractive choice for code-switching ASR. This paper presents a hybrid CTC-Attention based end-to-end Mandarin-English code-switching (CS) speech recognition system and studies the effect of hybrid CTC-Attention based models, different modeling units, the inclusion of language identification and different decoding strategies on the task of code-switching ASR. On the SEAME corpus, our system achieves a mixed error rate (MER) of 34.24%.
A comparable study of modeling units for end-to-end Mandarin speech recognition
May 14, 2018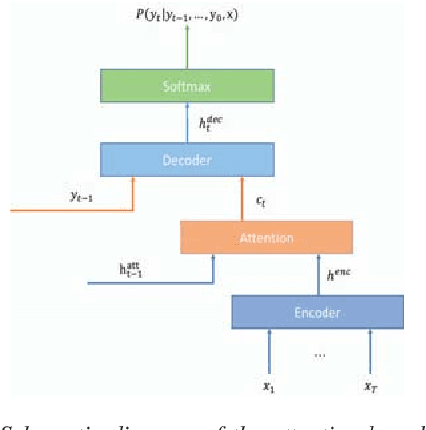
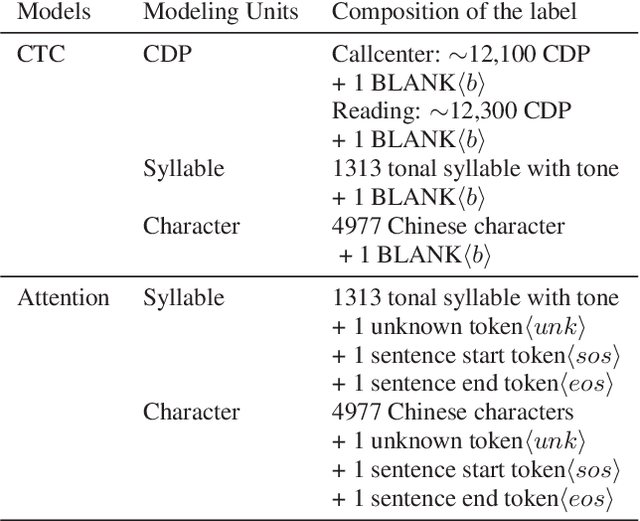
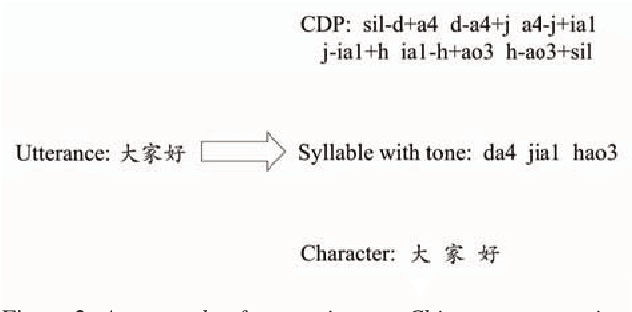
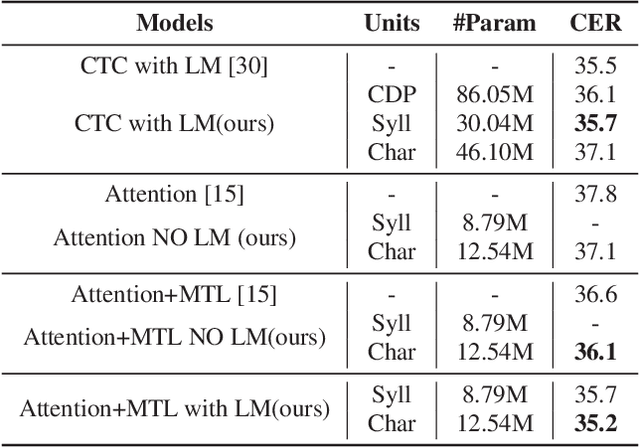
End-To-End speech recognition have become increasingly popular in mandarin speech recognition and achieved delightful performance. Mandarin is a tonal language which is different from English and requires special treatment for the acoustic modeling units. There have been several different kinds of modeling units for mandarin such as phoneme, syllable and Chinese character. In this work, we explore two major end-to-end models: connectionist temporal classification (CTC) model and attention based encoder-decoder model for mandarin speech recognition. We compare the performance of three different scaled modeling units: context dependent phoneme(CDP), syllable with tone and Chinese character. We find that all types of modeling units can achieve approximate character error rate (CER) in CTC model and the performance of Chinese character attention model is better than syllable attention model. Furthermore, we find that Chinese character is a reasonable unit for mandarin speech recognition. On DidiCallcenter task, Chinese character attention model achieves a CER of 5.68% and CTC model gets a CER of 7.29%, on the other DidiReading task, CER are 4.89% and 5.79%, respectively. Moreover, attention model achieves a better performance than CTC model on both datasets.