 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models
Dec 12, 2020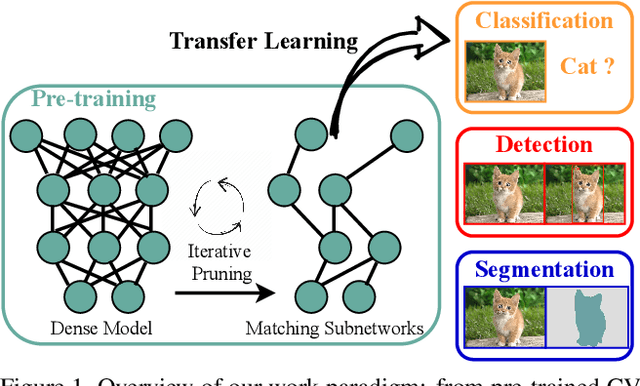

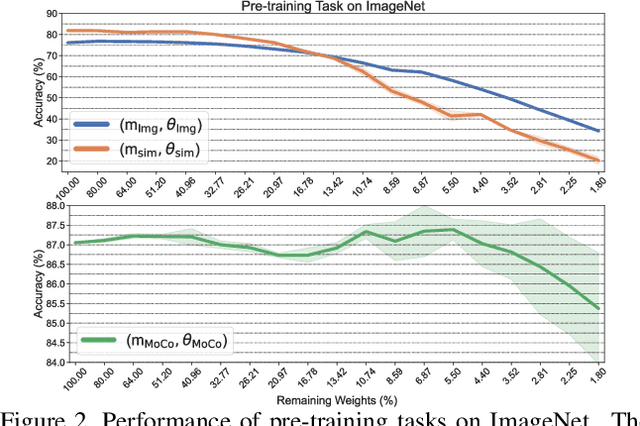
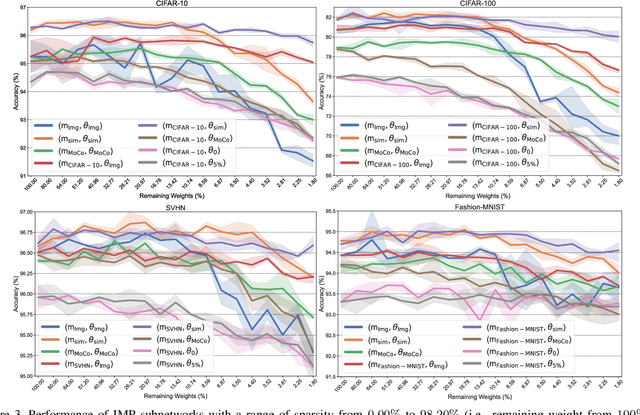
The computer vision world has been re-gaining enthusiasm in various pre-trained models, including both classical ImageNet supervised pre-training and recently emerged self-supervised pre-training such as simCLR and MoCo. Pre-trained weights often boost a wide range of downstream tasks including classification, detection, and segmentation. Latest studies suggest that the pre-training benefits from gigantic model capacity. We are hereby curious and ask: after pre-training, does a pre-trained model indeed have to stay large for its universal downstream transferability? In this paper, we examine the supervised and self-supervised pre-trained models through the lens of lottery ticket hypothesis (LTH). LTH identifies highly sparse matching subnetworks that can be trained in isolation from (nearly) scratch, to reach the full models' performance. We extend the scope of LTH to questioning whether matching subnetworks still exist in the pre-training models, that enjoy the same downstream transfer performance. Our extensive experiments convey an overall positive message: from all pre-trained weights obtained by ImageNet classification, simCLR and MoCo, we are consistently able to locate such matching subnetworks at 59.04% to 96.48% sparsity that transfer universally to multiple downstream tasks, whose performance see no degradation compared to using full pre-trained weights. Further analyses reveal that subnetworks found from different pre-training tend to yield diverse mask structures and perturbation sensitivities. We conclude that the core LTH observations remain generally relevant in the pre-training paradigm of computer vision, but more delicate discussions are needed in some cases. Codes and pre-trained models will be made available at: https://github.com/VITA-Group/CV_LTH_Pre-training.
Training Stronger Baselines for Learning to Optimize
Oct 18, 2020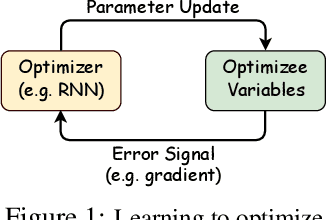
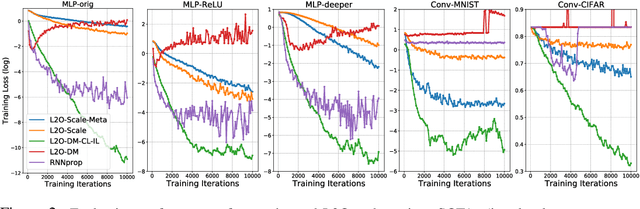
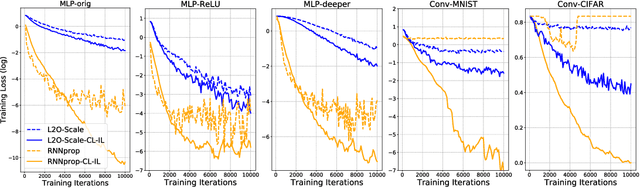
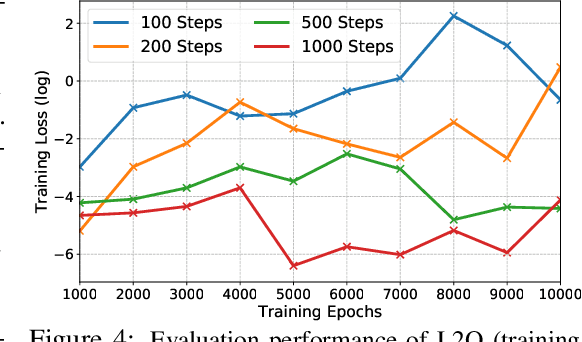
Learning to optimize (L2O) has gained increasing attention since classical optimizers require laborious problem-specific design and hyperparameter tuning. However, there is a gap between the practical demand and the achievable performance of existing L2O models. Specifically, those learned optimizers are applicable to only a limited class of problems, and often exhibit instability. With many efforts devoted to designing more sophisticated L2O models, we argue for another orthogonal, under-explored theme: the training techniques for those L2O models. We show that even the simplest L2O model could have been trained much better. We first present a progressive training scheme to gradually increase the optimizer unroll length, to mitigate a well-known L2O dilemma of truncation bias (shorter unrolling) versus gradient explosion (longer unrolling). We further leverage off-policy imitation learning to guide the L2O learning, by taking reference to the behavior of analytical optimizers. Our improved training techniques are plugged into a variety of state-of-the-art L2O models, and immediately boost their performance, without making any change to their model structures. Especially, by our proposed techniques, an earliest and simplest L2O model can be trained to outperform the latest complicated L2O models on a number of tasks. Our results demonstrate a greater potential of L2O yet to be unleashed, and urge to rethink the recent progress. Our codes are publicly available at: https://github.com/VITA-Group/L2O-Training-Techniques.
Interactive Fiction Game Playing as Multi-Paragraph Reading Comprehension with Reinforcement Learning
Oct 05, 2020
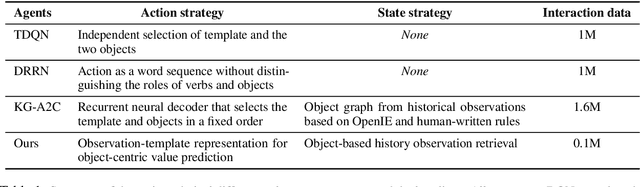
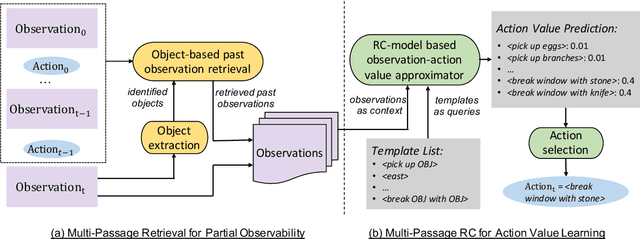
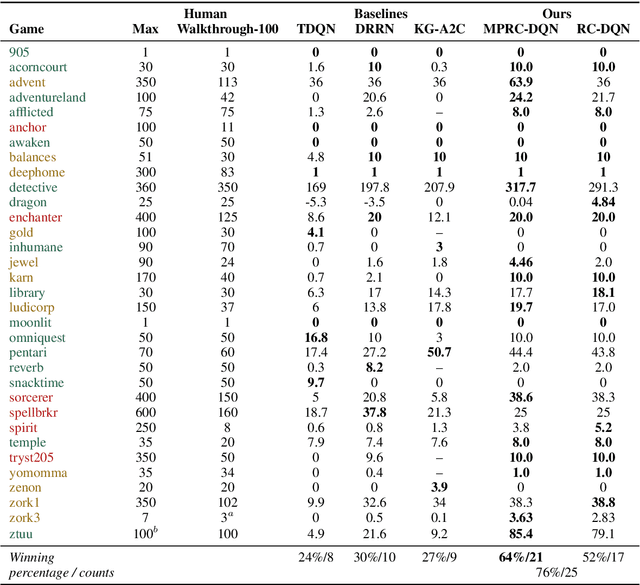
Interactive Fiction (IF) games with real human-written natural language texts provide a new natural evaluation for language understanding techniques. In contrast to previous text games with mostly synthetic texts, IF games pose language understanding challenges on the human-written textual descriptions of diverse and sophisticated game worlds and language generation challenges on the action command generation from less restricted combinatorial space. We take a novel perspective of IF game solving and re-formulate it as Multi-Passage Reading Comprehension (MPRC) tasks. Our approaches utilize the context-query attention mechanisms and the structured prediction in MPRC to efficiently generate and evaluate action outputs and apply an object-centric historical observation retrieval strategy to mitigate the partial observability of the textual observations. Extensive experiments on the recent IF benchmark (Jericho) demonstrate clear advantages of our approaches achieving high winning rates and low data requirements compared to all previous approaches. Our source code is available at: https://github.com/XiaoxiaoGuo/rcdqn.
Lifelong Object Detection
Sep 02, 2020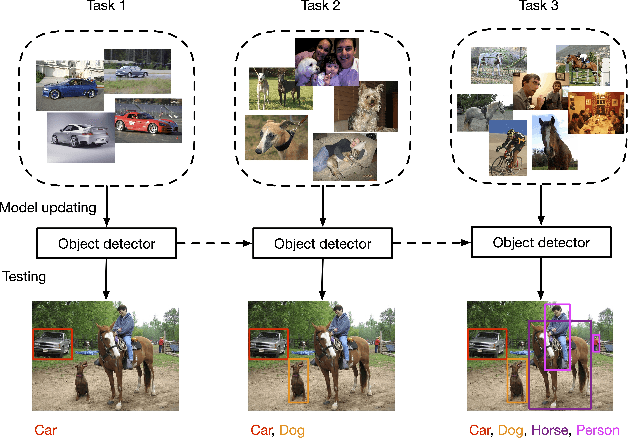
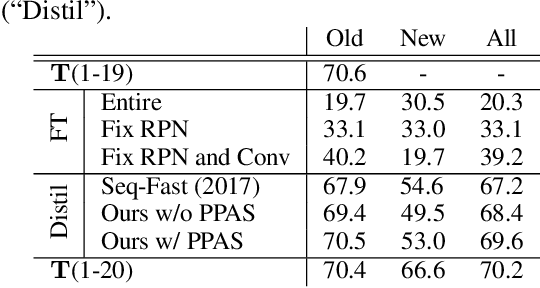
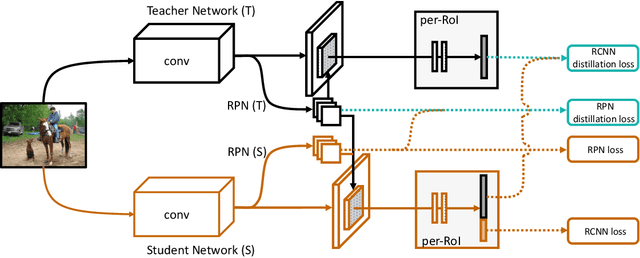

Recent advances in object detection have benefited significantly from rapid developments in deep neural networks. However, neural networks suffer from the well-known issue of catastrophic forgetting, which makes continual or lifelong learning problematic. In this paper, we leverage the fact that new training classes arrive in a sequential manner and incrementally refine the model so that it additionally detects new object classes in the absence of previous training data. Specifically, we consider the representative object detector, Faster R-CNN, for both accurate and efficient prediction. To prevent abrupt performance degradation due to catastrophic forgetting, we propose to apply knowledge distillation on both the region proposal network and the region classification network, to retain the detection of previously trained classes. A pseudo-positive-aware sampling strategy is also introduced for distillation sample selection. We evaluate the proposed method on PASCAL VOC 2007 and MS COCO benchmarks and show competitive mAP and 6x inference speed improvement, which makes the approach more suitable for real-time applications. Our implementation will be publicly available.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks
Jul 23, 2020In natural language processing (NLP), enormous pre-trained models like BERT have become the standard starting point for training on a range of downstream tasks, and similar trends are emerging in other areas of deep learning. In parallel, work on the lottery ticket hypothesis has shown that models for NLP and computer vision contain smaller matching subnetworks capable of training in isolation to full accuracy and transferring to other tasks. In this work, we combine these observations to assess whether such trainable, transferrable subnetworks exist in pre-trained BERT models. For a range of downstream tasks, we indeed find matching subnetworks at 40% to 90% sparsity. We find these subnetworks at (pre-trained) initialization, a deviation from prior NLP research where they emerge only after some amount of training. Subnetworks found on the masked language modeling task (the same task used to pre-train the model) transfer universally; those found on other tasks transfer in a limited fashion if at all. As large-scale pre-training becomes an increasingly central paradigm in deep learning, our results demonstrate that the main lottery ticket observations remain relevant in this context. Codes available at https://github.com/TAMU-VITA/BERT-Tickets.
Proper Network Interpretability Helps Adversarial Robustness in Classification
Jun 26, 2020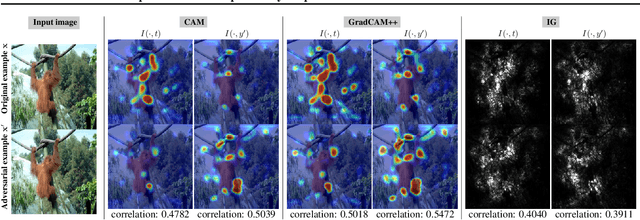
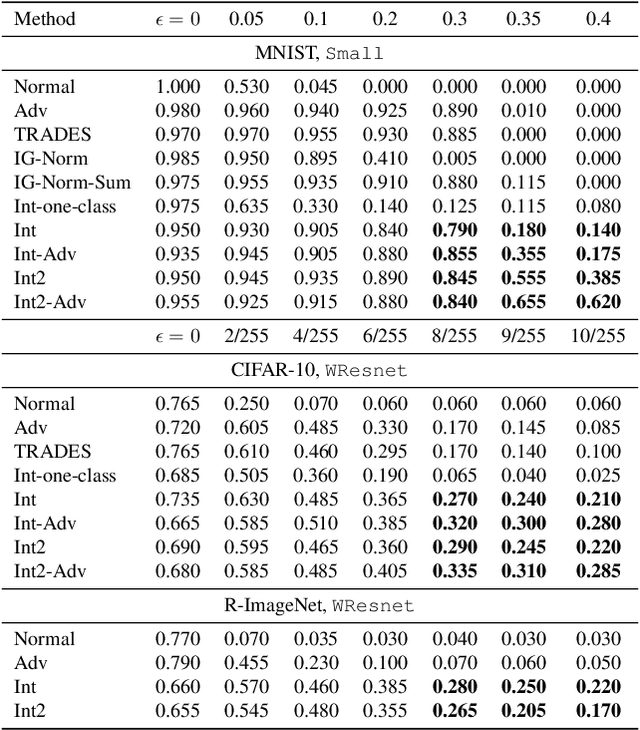
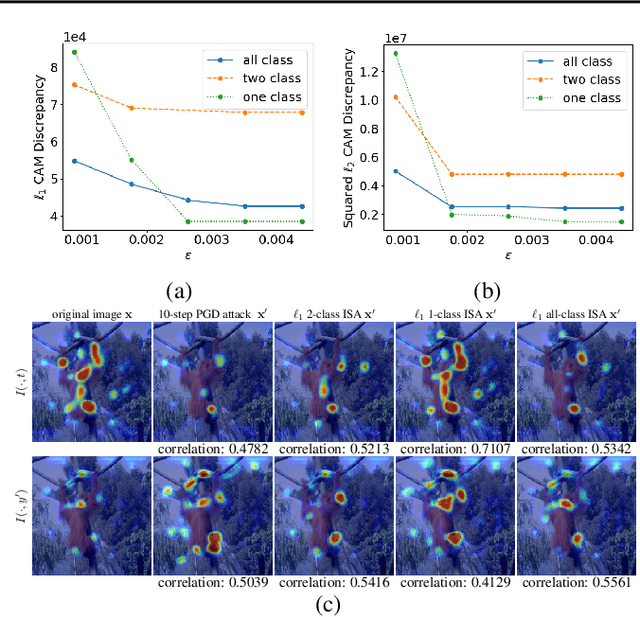
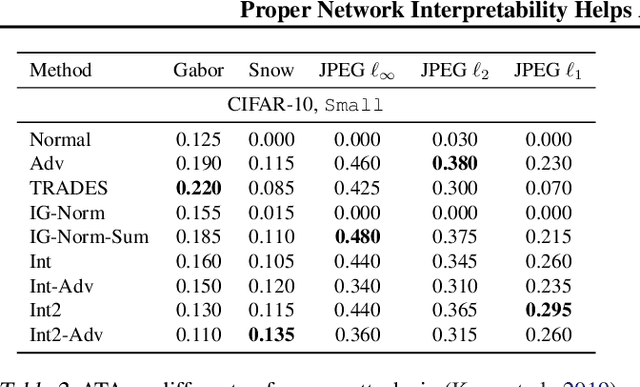
Recent works have empirically shown that there exist adversarial examples that can be hidden from neural network interpretability (namely, making network interpretation maps visually similar), or interpretability is itself susceptible to adversarial attacks. In this paper, we theoretically show that with a proper measurement of interpretation, it is actually difficult to prevent prediction-evasion adversarial attacks from causing interpretation discrepancy, as confirmed by experiments on MNIST, CIFAR-10 and Restricted ImageNet. Spurred by that, we develop an interpretability-aware defensive scheme built only on promoting robust interpretation (without the need for resorting to adversarial loss minimization). We show that our defense achieves both robust classification and robust interpretation, outperforming state-of-the-art adversarial training methods against attacks of large perturbation in particular.
Can 3D Adversarial Logos Cloak Humans?
Jun 25, 2020

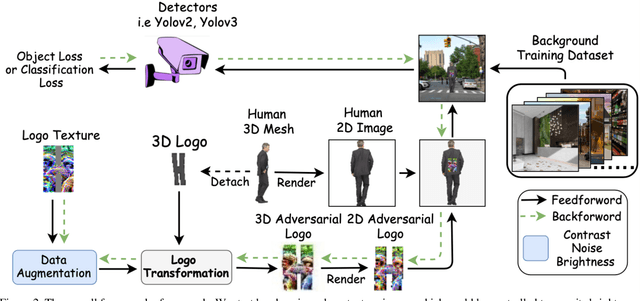
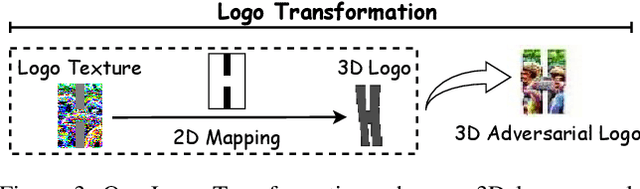
With the trend of adversarial attacks, researchers attempt to fool trained object detectors in 2D scenes. Among many of them, an intriguing new form of attack with potential real-world usage is to append adversarial patches (e.g. logos) to images. Nevertheless, much less have we known about adversarial attacks from 3D rendering views, which is essential for the attack to be persistently strong in the physical world. This paper presents a new 3D adversarial logo attack: we construct an arbitrary shape logo from a 2D texture image and map this image into a 3D adversarial logo via a texture mapping called logo transformation. The resulting 3D adversarial logo is then viewed as an adversarial texture enabling easy manipulation of its shape and position. This greatly extends the versatility of adversarial training for computer graphics synthesized imagery. Contrary to the traditional adversarial patch, this new form of attack is mapped into the 3D object world and back-propagates to the 2D image domain through differentiable rendering. In addition, and unlike existing adversarial patches, our new 3D adversarial logo is shown to fool state-of-the-art deep object detectors robustly under model rotations, leading to one step further for realistic attacks in the physical world. Our codes are available at https://github.com/TAMU-VITA/3D_Adversarial_Logo.
Unsupervised Speech Decomposition via Triple Information Bottleneck
May 04, 2020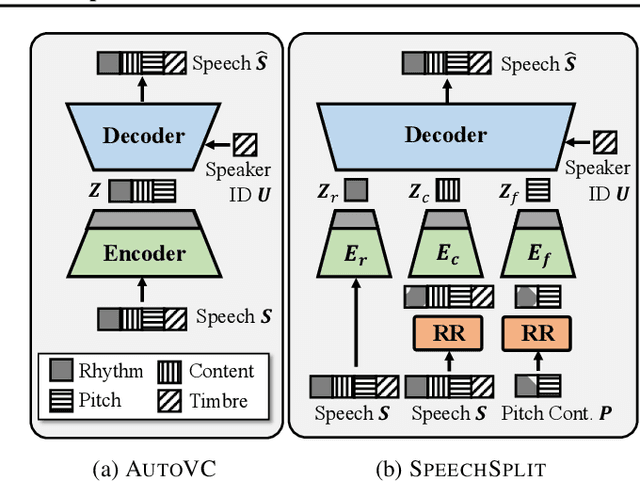
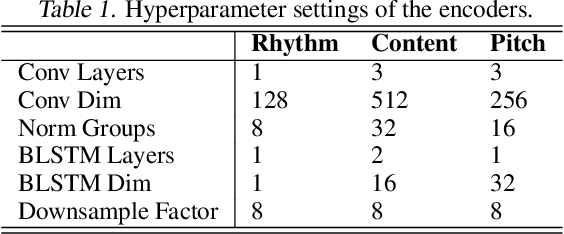
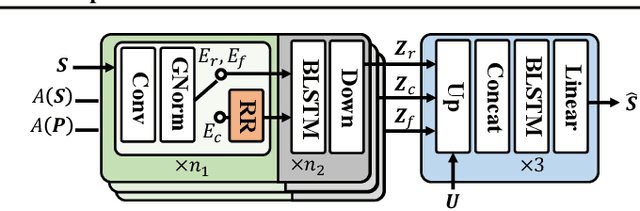

Speech information can be roughly decomposed into four components: language content, timbre, pitch, and rhythm. Obtaining disentangled representations of these components is useful in many speech analysis and generation applications. Recently, state-of-the-art voice conversion systems have led to speech representations that can disentangle speaker-dependent and independent information. However, these systems can only disentangle timbre, while information about pitch, rhythm and content is still mixed together. Further disentangling the remaining speech components is an under-determined problem in the absence of explicit annotations for each component, which are difficult and expensive to obtain. In this paper, we propose SpeechSplit, which can blindly decompose speech into its four components by introducing three carefully designed information bottlenecks. SpeechSplit is among the first algorithms that can separately perform style transfer on timbre, pitch and rhythm without text labels.
Learning to Recover Reasoning Chains for Multi-Hop Question Answering via Cooperative Games
Apr 06, 2020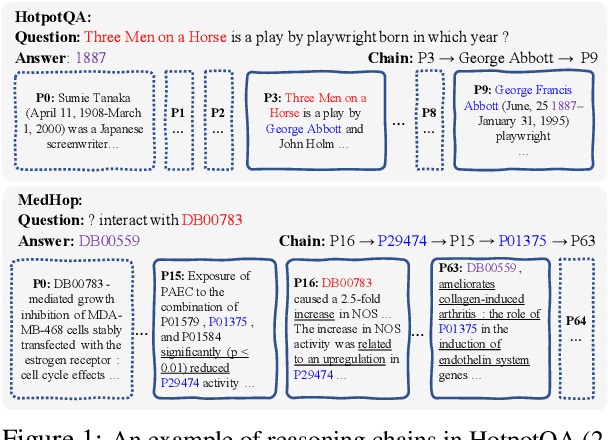
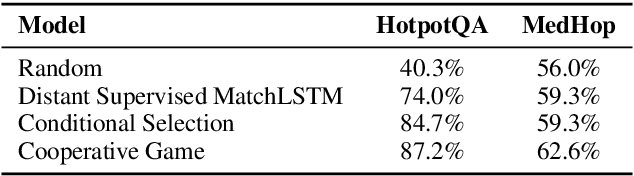
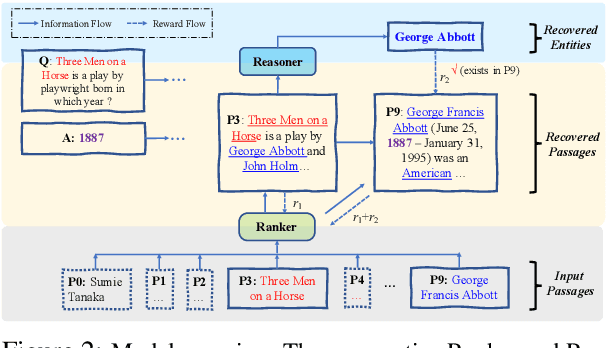

We propose the new problem of learning to recover reasoning chains from weakly supervised signals, i.e., the question-answer pairs. We propose a cooperative game approach to deal with this problem, in which how the evidence passages are selected and how the selected passages are connected are handled by two models that cooperate to select the most confident chains from a large set of candidates (from distant supervision). For evaluation, we created benchmarks based on two multi-hop QA datasets, HotpotQA and MedHop; and hand-labeled reasoning chains for the latter. The experimental results demonstrate the effectiveness of our proposed approach.
Adversarial Robustness: From Self-Supervised Pre-Training to Fine-Tuning
Mar 28, 2020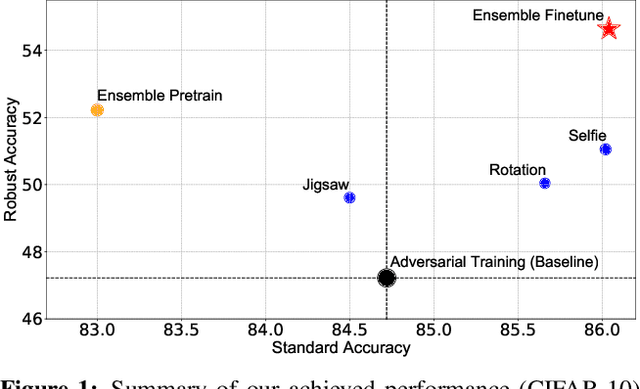


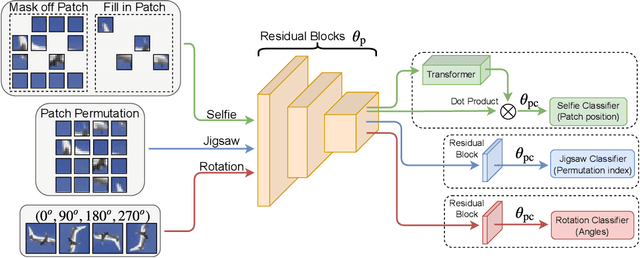
Pretrained models from self-supervision are prevalently used in fine-tuning downstream tasks faster or for better accuracy. However, gaining robustness from pretraining is left unexplored. We introduce adversarial training into self-supervision, to provide general-purpose robust pre-trained models for the first time. We find these robust pre-trained models can benefit the subsequent fine-tuning in two ways: i) boosting final model robustness; ii) saving the computation cost, if proceeding towards adversarial fine-tuning. We conduct extensive experiments to demonstrate that the proposed framework achieves large performance margins (eg, 3.83% on robust accuracy and 1.3% on standard accuracy, on the CIFAR-10 dataset), compared with the conventional end-to-end adversarial training baseline. Moreover, we find that different self-supervised pre-trained models have a diverse adversarial vulnerability. It inspires us to ensemble several pretraining tasks, which boosts robustness more. Our ensemble strategy contributes to a further improvement of 3.59% on robust accuracy, while maintaining a slightly higher standard accuracy on CIFAR-10. Our codes are available at https://github.com/TAMU-VITA/Adv-SS-Pretraining.