 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Black Hole Properties from Astronomical Multivariate Time Series with Bayesian Attentive Neural Processes
Jun 18, 2021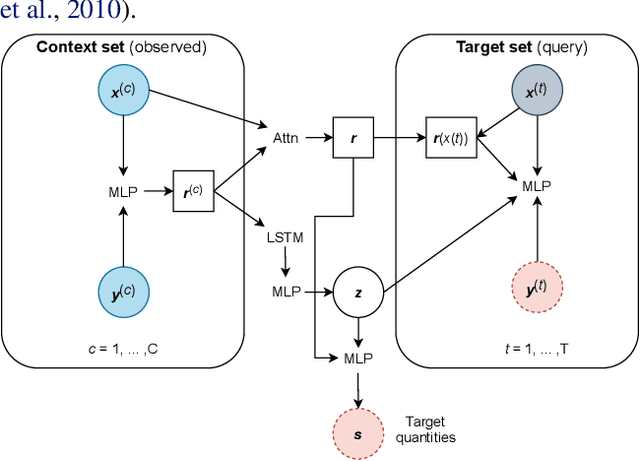
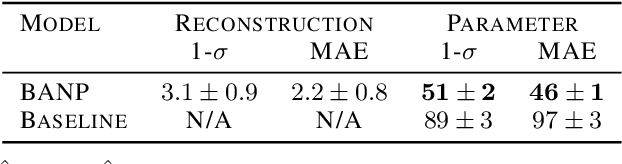
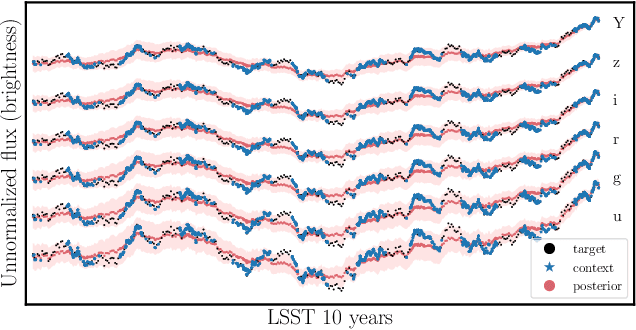
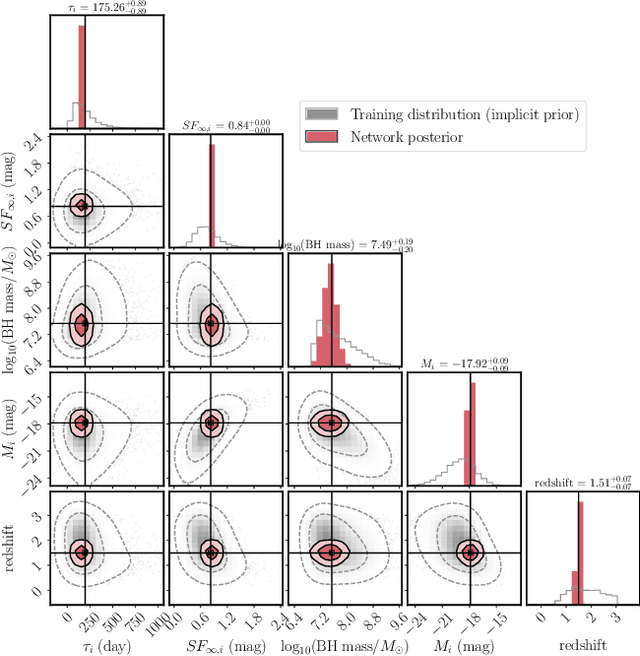
Among the most extreme objects in the Universe, active galactic nuclei (AGN) are luminous centers of galaxies where a black hole feeds on surrounding matter. The variability patterns of the light emitted by an AGN contain information about the physical properties of the underlying black hole. Upcoming telescopes will observe over 100 million AGN in multiple broadband wavelengths, yielding a large sample of multivariate time series with long gaps and irregular sampling. We present a method that reconstructs the AGN time series and simultaneously infers the posterior probability density distribution (PDF) over the physical quantities of the black hole, including its mass and luminosity. We apply this method to a simulated dataset of 11,000 AGN and report precision and accuracy of 0.4 dex and 0.3 dex in the inferred black hole mass. This work is the first to address probabilistic time series reconstruction and parameter inference for AGN in an end-to-end fashion.
A Deep Learning Approach for Active Anomaly Detection of Extragalactic Transients
Mar 22, 2021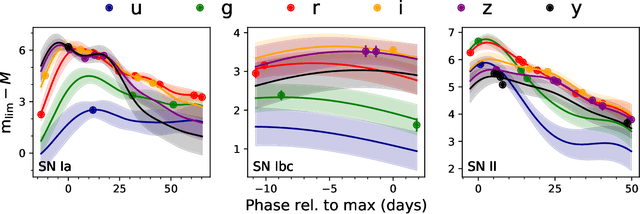
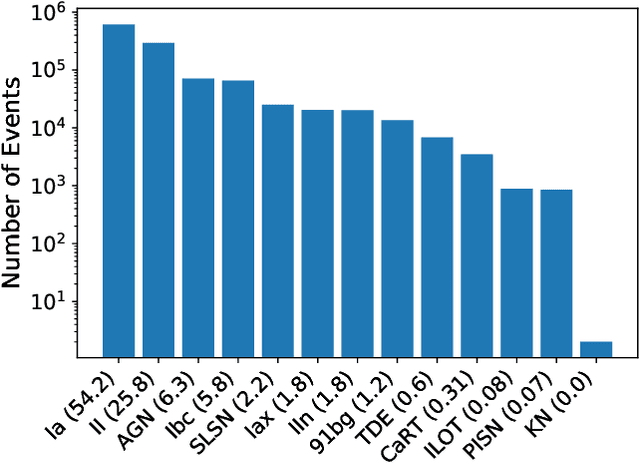
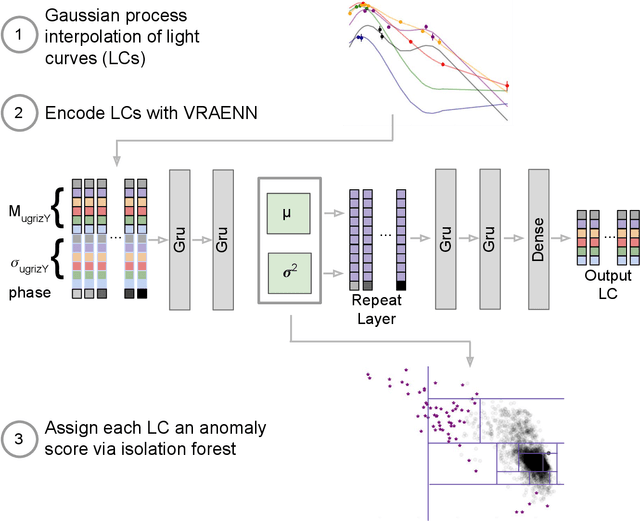
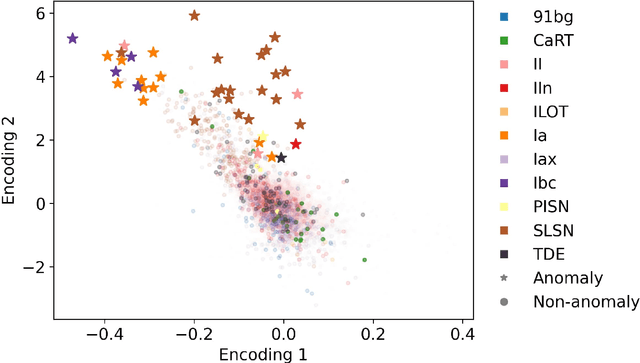
There is a shortage of multi-wavelength and spectroscopic followup capabilities given the number of transient and variable astrophysical events discovered through wide-field, optical surveys such as the upcoming Vera C. Rubin Observatory. From the haystack of potential science targets, astronomers must allocate scarce resources to study a selection of needles in real time. Here we present a variational recurrent autoencoder neural network to encode simulated Rubin Observatory extragalactic transient events using 1% of the PLAsTiCC dataset to train the autoencoder. Our unsupervised method uniquely works with unlabeled, real time, multivariate and aperiodic data. We rank 1,129,184 events based on an anomaly score estimated using an isolation forest. We find that our pipeline successfully ranks rarer classes of transients as more anomalous. Using simple cuts in anomaly score and uncertainty, we identify a pure (~95% pure) sample of rare transients (i.e., transients other than Type Ia, Type II and Type Ibc supernovae) including superluminous and pair-instability supernovae. Finally, our algorithm is able to identify these transients as anomalous well before peak, enabling real-time follow up studies in the era of the Rubin Observatory.
A Bayesian neural network predicts the dissolution of compact planetary systems
Jan 11, 2021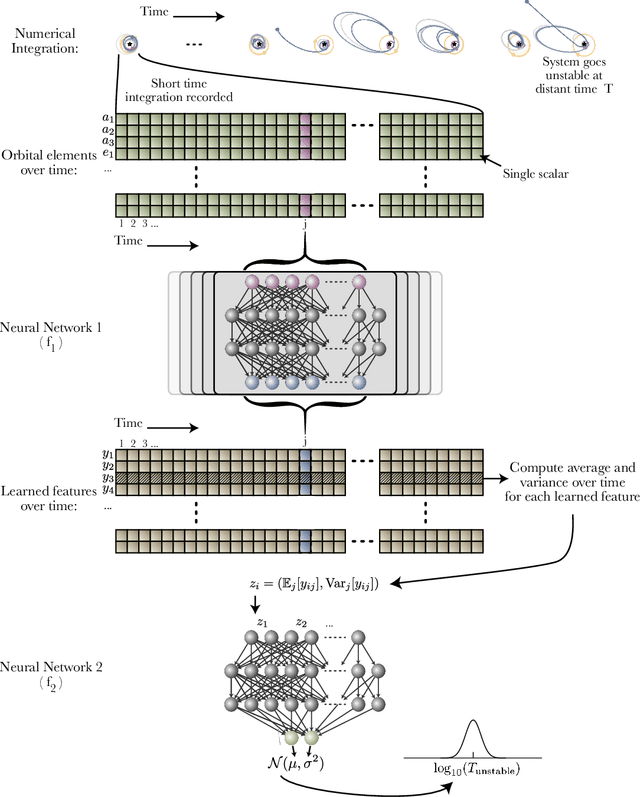
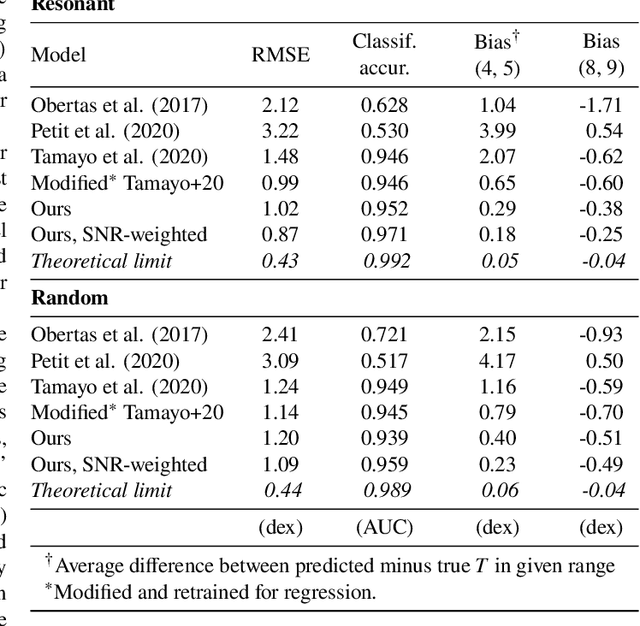
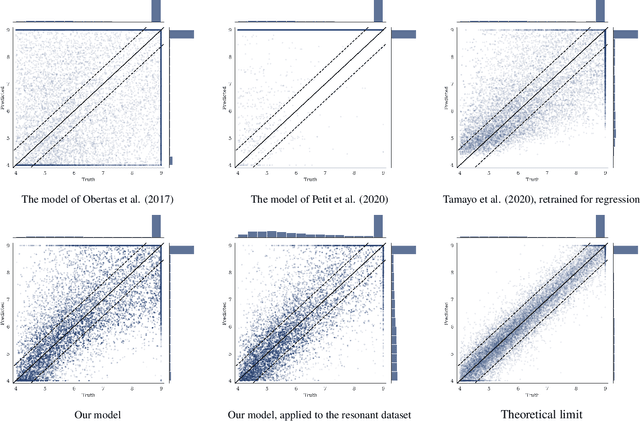
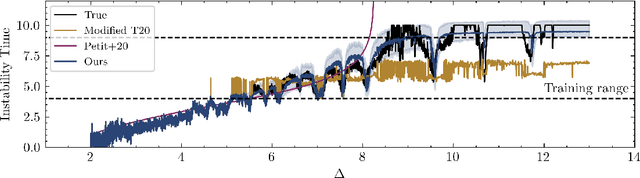
Despite over three hundred years of effort, no solutions exist for predicting when a general planetary configuration will become unstable. We introduce a deep learning architecture to push forward this problem for compact systems. While current machine learning algorithms in this area rely on scientist-derived instability metrics, our new technique learns its own metrics from scratch, enabled by a novel internal structure inspired from dynamics theory. Our Bayesian neural network model can accurately predict not only if, but also when a compact planetary system with three or more planets will go unstable. Our model, trained directly from short N-body time series of raw orbital elements, is more than two orders of magnitude more accurate at predicting instability times than analytical estimators, while also reducing the bias of existing machine learning algorithms by nearly a factor of three. Despite being trained on compact resonant and near-resonant three-planet configurations, the model demonstrates robust generalization to both non-resonant and higher multiplicity configurations, in the latter case outperforming models fit to that specific set of integrations. The model computes instability estimates up to five orders of magnitude faster than a numerical integrator, and unlike previous efforts provides confidence intervals on its predictions. Our inference model is publicly available in the SPOCK package, with training code open-sourced.
$\texttt{deep21}$: a Deep Learning Method for 21cm Foreground Removal
Oct 29, 2020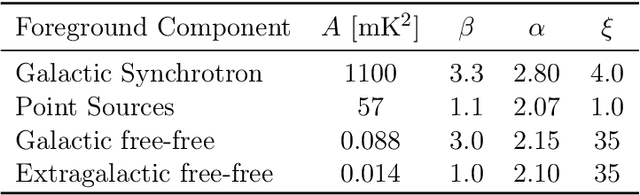
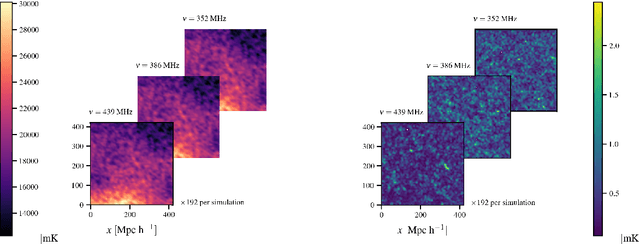
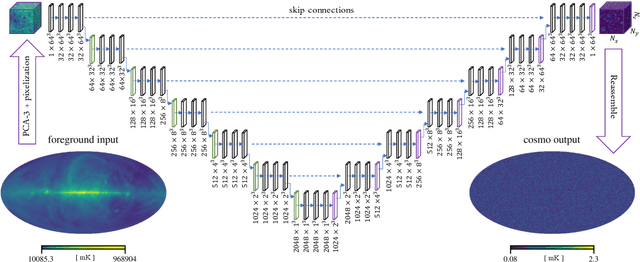
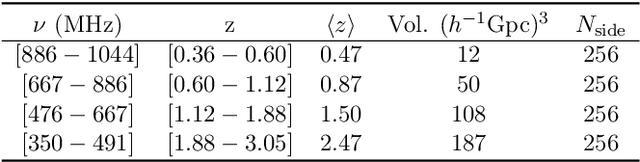
We seek to remove foreground contaminants from 21cm intensity mapping observations. We demonstrate that a deep convolutional neural network (CNN) with a UNet architecture and three-dimensional convolutions, trained on simulated observations, can effectively separate frequency and spatial patterns of the cosmic neutral hydrogen (HI) signal from foregrounds in the presence of noise. Cleaned maps recover cosmological clustering statistics within 10% at all relevant angular scales and frequencies. This amounts to a reduction in prediction variance of over an order of magnitude on small angular scales ($\ell > 300$), and improved accuracy for small radial scales ($k_{\parallel} > 0.17\ \rm h\ Mpc^{-1})$ compared to standard Principal Component Analysis (PCA) methods. We estimate posterior confidence intervals for the network's prediction by training an ensemble of UNets. Our approach demonstrates the feasibility of analyzing 21cm intensity maps, as opposed to derived summary statistics, for upcoming radio experiments, as long as the simulated foreground model is sufficiently realistic. We provide the code used for this analysis on $\href{https://github.com/tlmakinen/deep21}{\rm GitHub}$, as well as a browser-based tutorial for the experiment and UNet model via the accompanying $\href{http://bit.ly/deep21-colab}{\rm Colab\ notebook}$.
Anomaly Detection for Multivariate Time Series of Exotic Supernovae
Oct 21, 2020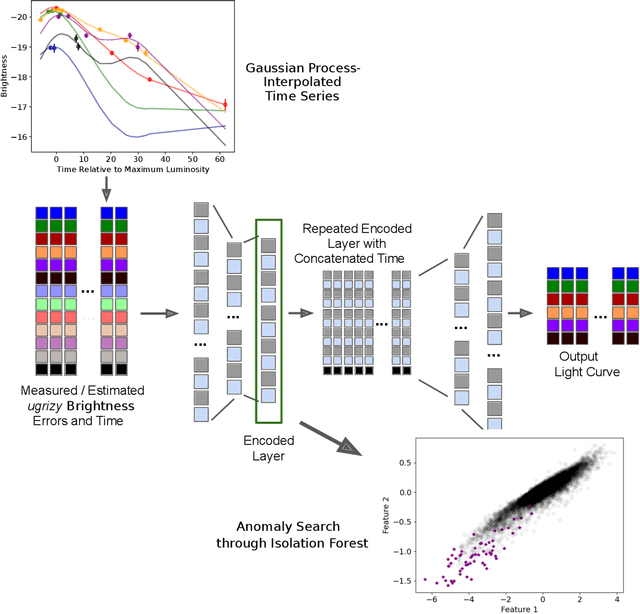
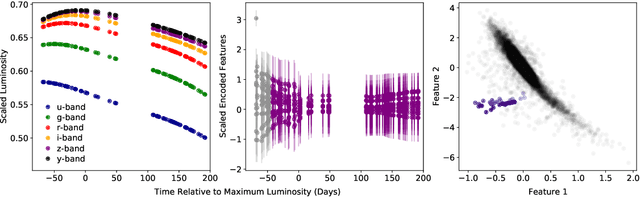
Supernovae mark the explosive deaths of stars and enrich the cosmos with heavy elements. Future telescopes will discover thousands of new supernovae nightly, creating a need to flag astrophysically interesting events rapidly for followup study. Ideally, such an anomaly detection pipeline would be independent of our current knowledge and be sensitive to unexpected phenomena. Here we present an unsupervised method to search for anomalous time series in real time for transient, multivariate, and aperiodic signals. We use a RNN-based variational autoencoder to encode supernova time series and an isolation forest to search for anomalous events in the learned encoded space. We apply this method to a simulated dataset of 12,159 supernovae, successfully discovering anomalous supernovae and objects with catastrophically incorrect redshift measurements. This work is the first anomaly detection pipeline for supernovae which works with online datastreams.
Meta-Learning One-Class Classification with DeepSets: Application in the Milky Way
Jul 08, 2020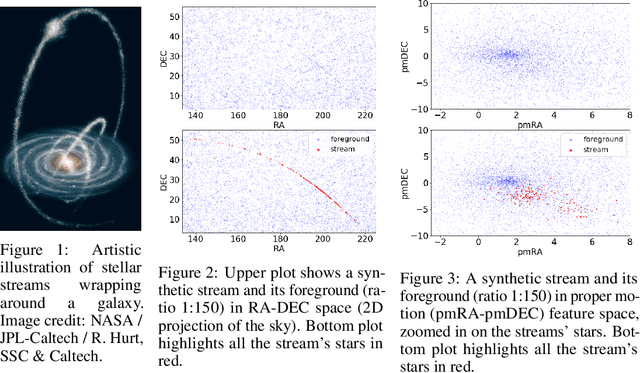
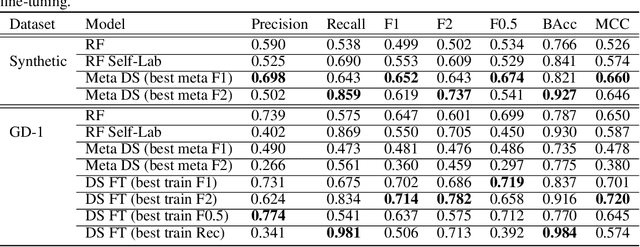

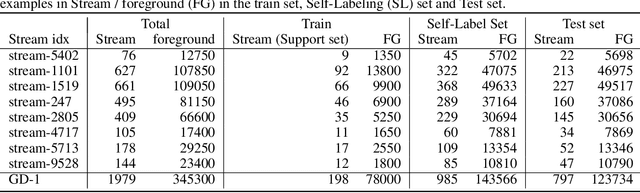
We explore in this paper the use of neural networks designed for point-clouds and sets on a new meta-learning task. We present experiments on the astronomical challenge of characterizing the stellar population of stellar streams. Stellar streams are elongated structures of stars in the outskirts of the Milky Way that form when a (small) galaxy breaks up under the Milky Way's gravitational force. We consider that we obtain, for each stream, a small 'support set' of stars that belongs to this stream. We aim to predict if the other stars in that region of the sky are from that stream or not, similar to one-class classification. Each "stream task" could also be transformed into a binary classification problem in a highly imbalanced regime (or supervised anomaly detection) by using the much bigger set of "other" stars and considering them as noisy negative examples. We propose to study the problem in the meta-learning regime: we expect that we can learn general information on characterizing a stream's stellar population by meta-learning across several streams in a fully supervised regime, and transfer it to new streams using only positive supervision. We present a novel use of Deep Sets, a model developed for point-cloud and sets, trained in a meta-learning fully supervised regime, and evaluated in a one-class classification setting. We compare it against Random Forests (with and without self-labeling) in the classic setting of binary classification, retrained for each task. We show that our method outperforms the Random-Forests even though the Deep Sets is not retrained on the new tasks, and accesses only a small part of the data compared to the Random Forest. We also show that the model performs well on a real-life stream when including additional fine-tuning.
Discovering Symbolic Models from Deep Learning with Inductive Biases
Jun 19, 2020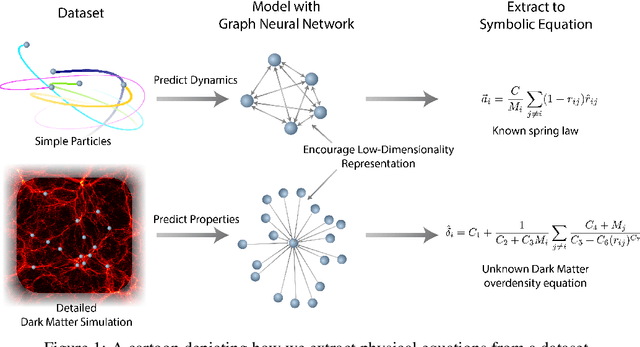

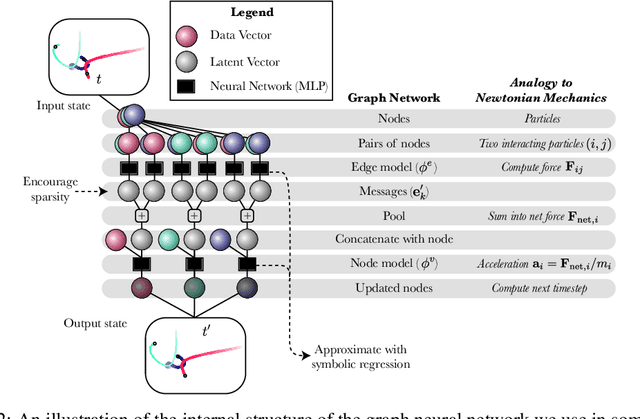

We develop a general approach to distill symbolic representations of a learned deep model by introducing strong inductive biases. We focus on Graph Neural Networks (GNNs). The technique works as follows: we first encourage sparse latent representations when we train a GNN in a supervised setting, then we apply symbolic regression to components of the learned model to extract explicit physical relations. We find the correct known equations, including force laws and Hamiltonians, can be extracted from the neural network. We then apply our method to a non-trivial cosmology example-a detailed dark matter simulation-and discover a new analytic formula which can predict the concentration of dark matter from the mass distribution of nearby cosmic structures. The symbolic expressions extracted from the GNN using our technique also generalized to out-of-distribution data better than the GNN itself. Our approach offers alternative directions for interpreting neural networks and discovering novel physical principles from the representations they learn.
Lagrangian Neural Networks
Mar 10, 2020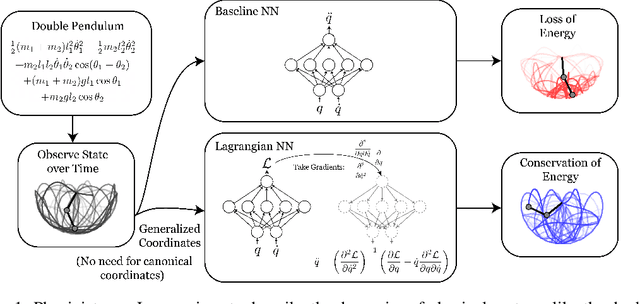
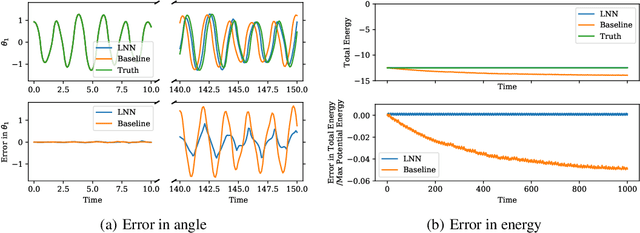
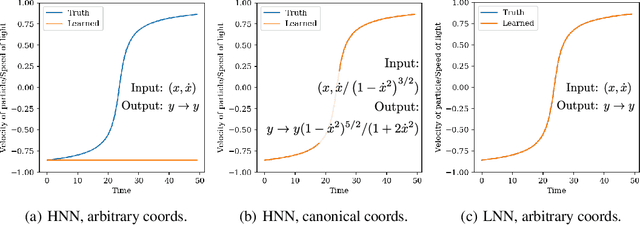
Accurate models of the world are built upon notions of its underlying symmetries. In physics, these symmetries correspond to conservation laws, such as for energy and momentum. Yet even though neural network models see increasing use in the physical sciences, they struggle to learn these symmetries. In this paper, we propose Lagrangian Neural Networks (LNNs), which can parameterize arbitrary Lagrangians using neural networks. In contrast to models that learn Hamiltonians, LNNs do not require canonical coordinates, and thus perform well in situations where canonical momenta are unknown or difficult to compute. Unlike previous approaches, our method does not restrict the functional form of learned energies and will produce energy-conserving models for a variety of tasks. We test our approach on a double pendulum and a relativistic particle, demonstrating energy conservation where a baseline approach incurs dissipation and modeling relativity without canonical coordinates where a Hamiltonian approach fails. Finally, we show how this model can be applied to graphs and continuous systems using a Lagrangian Graph Network, and demonstrate it on the 1D wave equation.
From Dark Matter to Galaxies with Convolutional Neural Networks
Oct 17, 2019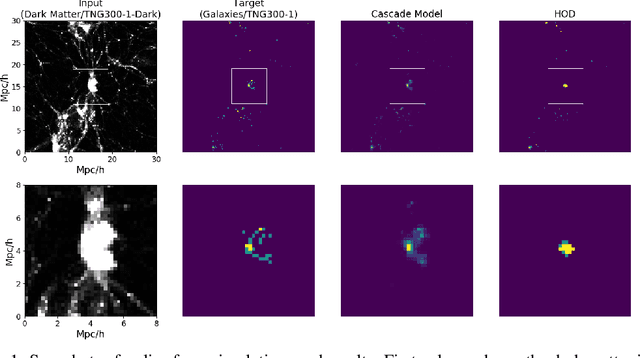
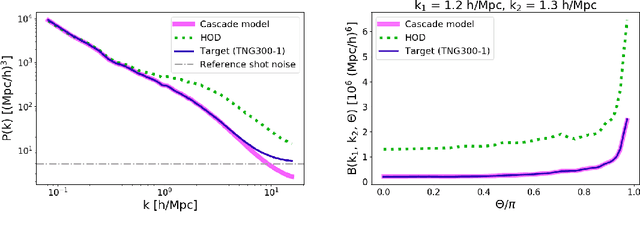
Cosmological simulations play an important role in the interpretation of astronomical data, in particular in comparing observed data to our theoretical expectations. However, to compare data with these simulations, the simulations in principle need to include gravity, magneto-hydrodyanmics, radiative transfer, etc. These ideal large-volume simulations (gravo-magneto-hydrodynamical) are incredibly computationally expensive which can cost tens of millions of CPU hours to run. In this paper, we propose a deep learning approach to map from the dark-matter-only simulation (computationally cheaper) to the galaxy distribution (from the much costlier cosmological simulation). The main challenge of this task is the high sparsity in the target galaxy distribution: space is mainly empty. We propose a cascade architecture composed of a classification filter followed by a regression procedure. We show that our result outperforms a state-of-the-art model used in the astronomical community, and provides a good trade-off between computational cost and prediction accuracy.
Learning neutrino effects in Cosmology with Convolutional Neural Networks
Oct 09, 2019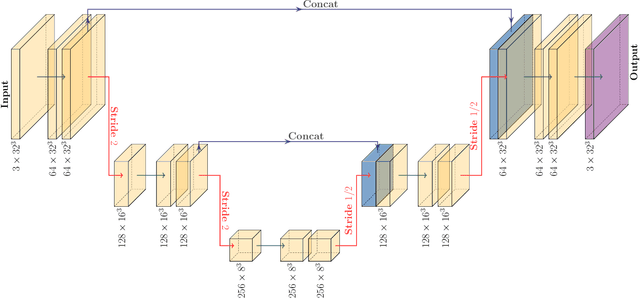

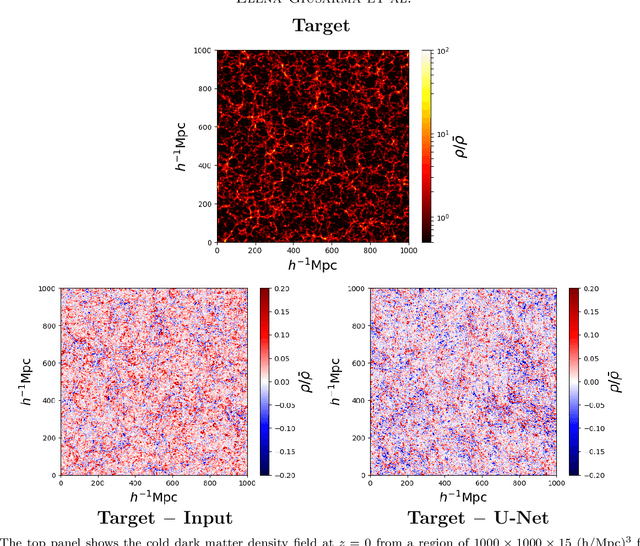
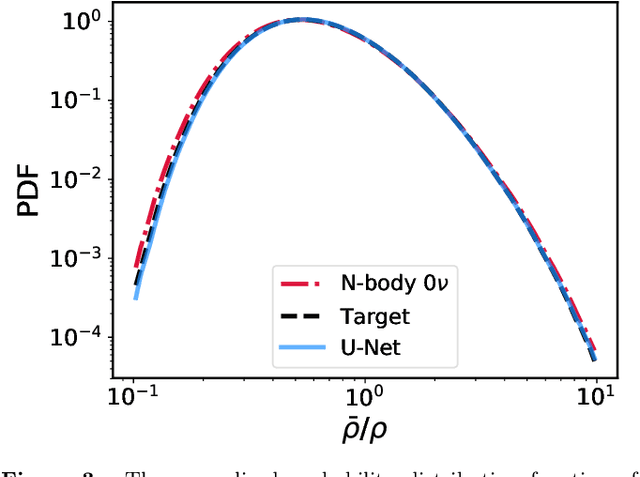
Measuring the sum of the three active neutrino masses, $M_\nu$, is one of the most important challenges in modern cosmology. Massive neutrinos imprint characteristic signatures on several cosmological observables in particular on the large-scale structure of the Universe. In order to maximize the information that can be retrieved from galaxy surveys, accurate theoretical predictions in the non-linear regime are needed. Currently, one way to achieve those predictions is by running cosmological numerical simulations. Unfortunately, producing those simulations requires high computational resources -- seven hundred CPU hours for each neutrino mass case. In this work, we propose a new method, based on a deep learning network (U-Net), to quickly generate simulations with massive neutrinos from standard $\Lambda$CDM simulations without neutrinos. We computed multiple relevant statistical measures of deep-learning generated simulations, and conclude that our method accurately reproduces the 3-dimensional spatial distribution of matter down to non-linear scales: $k < 0.7$ h/Mpc. Finally, our method allows us to generate massive neutrino simulations 10,000 times faster than the traditional methods.