 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe StarCraft Multi-Agent Challenge
Feb 26, 2019
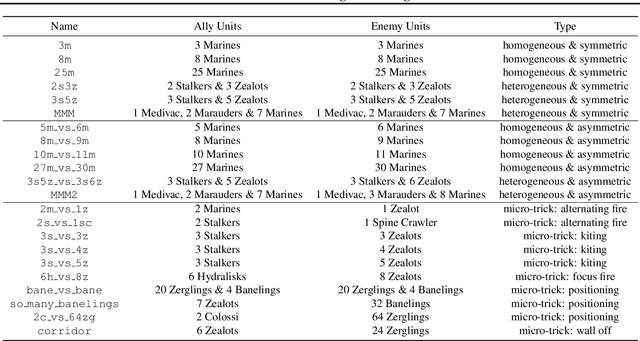

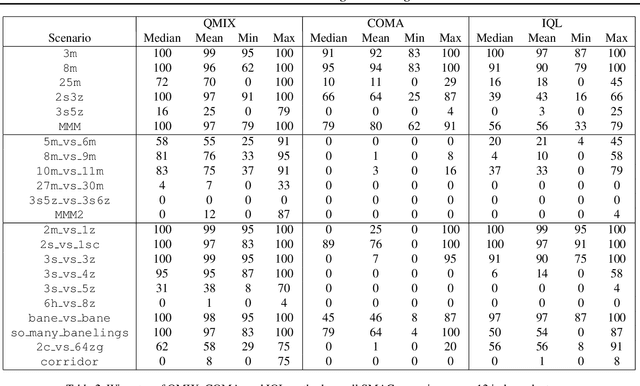
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: https://youtu.be/VZ7zmQ_obZ0.
Fast Efficient Hyperparameter Tuning for Policy Gradients
Feb 18, 2019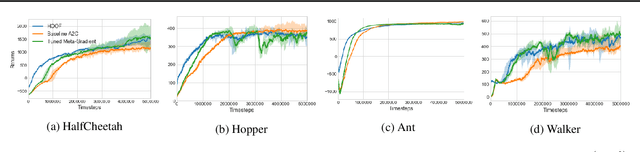
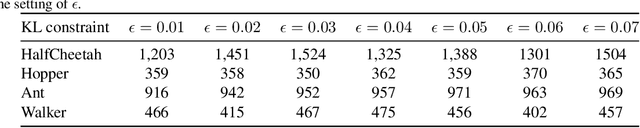
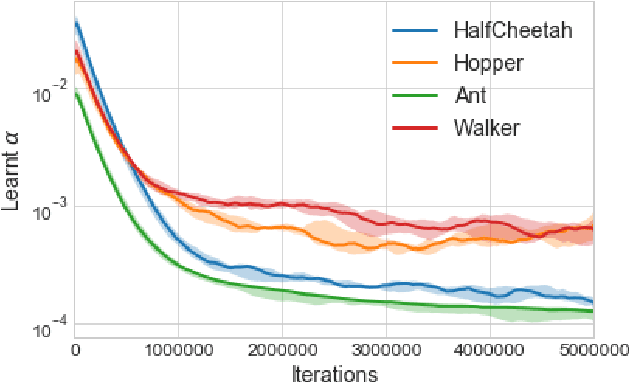
The performance of policy gradient methods is sensitive to hyperparameter settings that must be tuned for any new application. Widely used grid search methods for tuning hyperparameters are sample inefficient and computationally expensive. More advanced methods like Population Based Training that learn optimal schedules for hyperparameters instead of fixed settings can yield better results, but are also sample inefficient and computationally expensive. In this paper, we propose Hyperparameter Optimisation on the Fly (HOOF), a gradient-free meta-learning algorithm that can automatically learn an optimal schedule for hyperparameters that affect the policy update directly through the gradient. The main idea is to use existing trajectories sampled by the policy gradient method to optimise a one-step improvement objective, yielding a sample and computationally efficient algorithm that is easy to implement. Our experimental results across multiple domains and algorithms show that using HOOF to learn these hyperparameter schedules leads to faster learning with improved performance.
Stable Opponent Shaping in Differentiable Games
Nov 20, 2018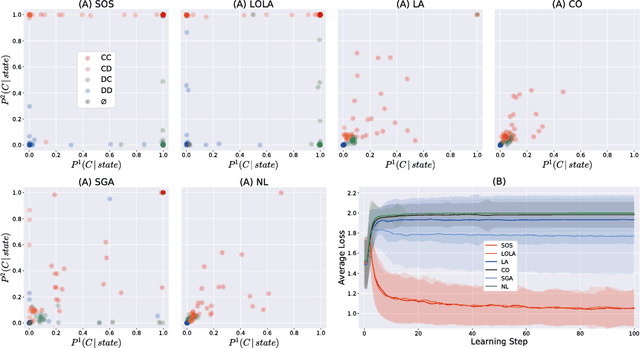
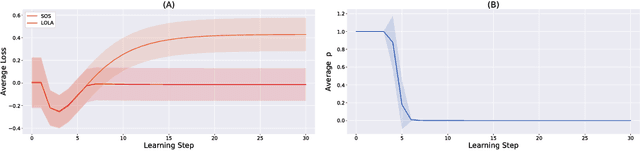
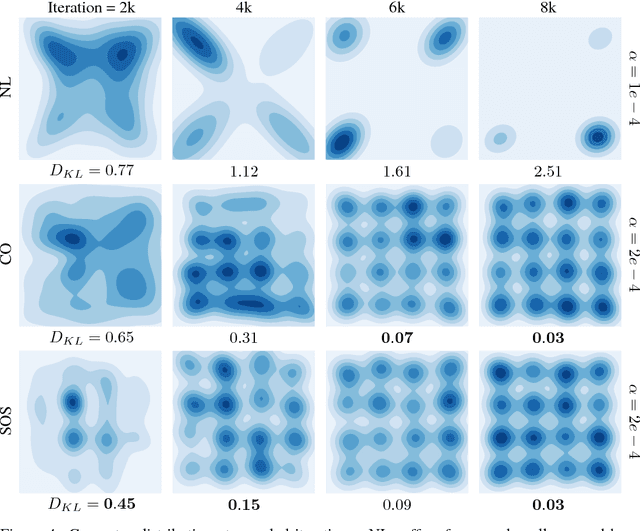

A growing number of learning methods are actually \emph{games} which optimise multiple, interdependent objectives in parallel -- from GANs and intrinsic curiosity to multi-agent RL. Opponent shaping is a powerful approach to improve learning dynamics in such games, accounting for the fact that the 'environment' includes agents adapting to one another's updates. Learning with Opponent-Learning Awareness (LOLA) is a recent algorithm which exploits this dynamic response and encourages cooperation in settings like the Iterated Prisoner's Dilemma. Although experimentally successful, we show that LOLA can exhibit 'arrogant' behaviour directly at odds with convergence. In fact, remarkably few algorithms have theoretical guarantees applying across all differentiable games. In this paper we present Stable Opponent Shaping (SOS), a new method that interpolates between LOLA and a stable variant named LookAhead. We prove that LookAhead locally converges and avoids strict saddles in \emph{all differentiable games}, the strongest results in the field so far. SOS inherits these desirable guarantees, while also shaping the learning of opponents and consistently either matching or outperforming LOLA experimentally.
Learning from Demonstration in the Wild
Nov 08, 2018
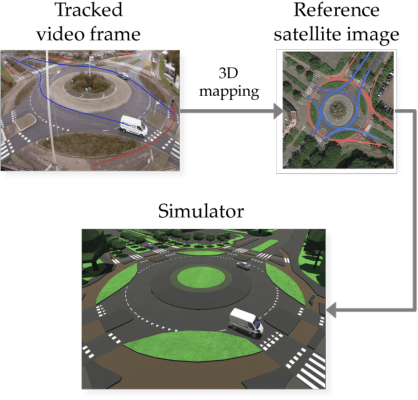
Learning from demonstration (LfD) is useful in settings where hand-coding behaviour or a reward function is impractical. It has succeeded in a wide range of problems but typically relies on artificially generated demonstrations or specially deployed sensors and has not generally been able to leverage the copious demonstrations available in the wild: those that capture behaviour that was occurring anyway using sensors that were already deployed for another purpose, e.g., traffic camera footage capturing demonstrations of natural behaviour of vehicles, cyclists, and pedestrians. We propose video to behaviour (ViBe), a new approach to learning models of road user behaviour that requires as input only unlabelled raw video data of a traffic scene collected from a single, monocular, uncalibrated camera with ordinary resolution. Our approach calibrates the camera, detects relevant objects, tracks them through time, and uses the resulting trajectories to perform LfD, yielding models of naturalistic behaviour. We apply ViBe to raw videos of a traffic intersection and show that it can learn purely from videos, without additional expert knowledge.
Multi-Agent Common Knowledge Reinforcement Learning
Nov 05, 2018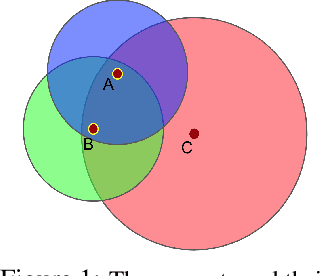

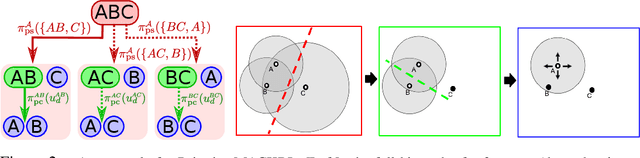
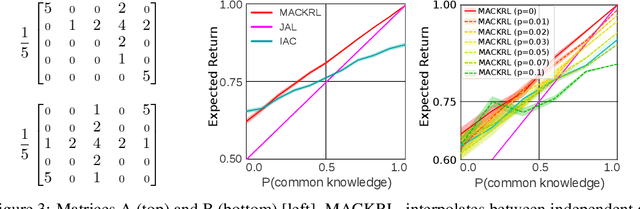
In multi-agent reinforcement learning, centralised policies can only be executed if agents have access to either the global state or an instantaneous communication channel. An alternative approach that circumvents this limitation is to use centralised training of a set of decentralised policies. However, such policies severely limit the agents' ability to coordinate. We propose multi-agent common knowledge reinforcement learning (MACKRL), which strikes a middle ground between these two extremes. Our approach is based on the insight that, even in partially observable settings, subsets of agents often have some common knowledge that they can exploit to coordinate their behaviour. Common knowledge can arise, e.g., if all agents can reliably observe things in their own field of view and know the field of view of other agents. Using this additional information, it is possible to find a centralised policy that conditions only on agents' common knowledge and that can be executed in a decentralised fashion. A resulting challenge is then to determine at what level agents should coordinate. While the common knowledge shared among all agents may not contain much valuable information, there may be subgroups of agents that share common knowledge useful for coordination. MACKRL addresses this challenge using a hierarchical approach: at each level, a controller can either select a joint action for the agents in a given subgroup, or propose a partition of the agents into smaller subgroups whose actions are then selected by controllers at the next level. While action selection involves sampling hierarchically, learning updates are based on the probability of the joint action, calculated by marginalising across the possible decisions of the hierarchy. We show promising results on both a proof-of-concept matrix game and a multi-agent version of StarCraft II Micromanagement.
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
Nov 04, 2018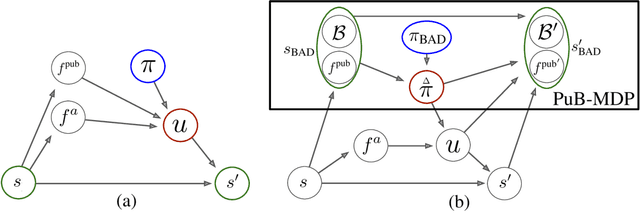
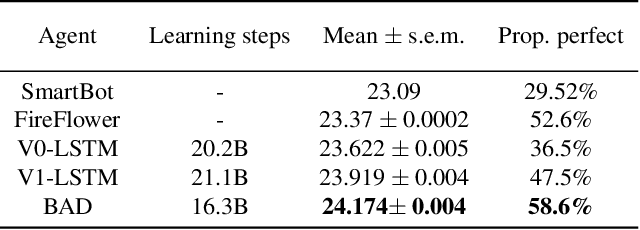
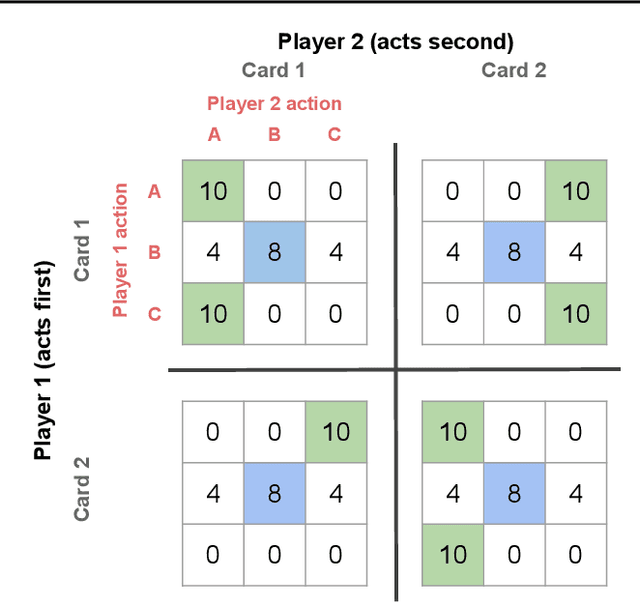
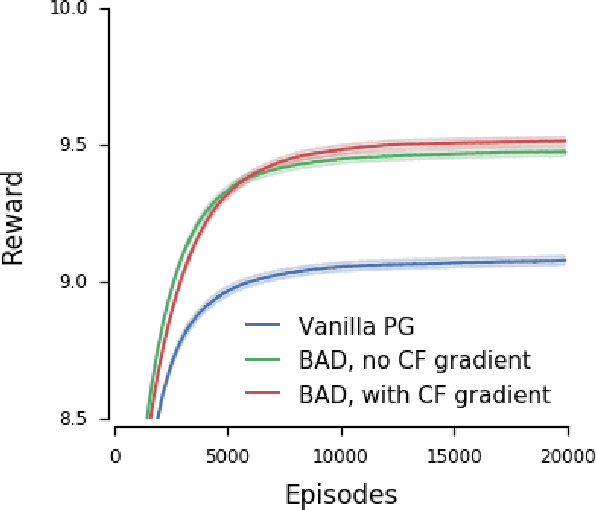
When observing the actions of others, humans carry out inferences about why the others acted as they did, and what this implies about their view of the world. Humans also use the fact that their actions will be interpreted in this manner when observed by others, allowing them to act informatively and thereby communicate efficiently with others. Although learning algorithms have recently achieved superhuman performance in a number of two-player, zero-sum games, scalable multi-agent reinforcement learning algorithms that can discover effective strategies and conventions in complex, partially observable settings have proven elusive. We present the Bayesian action decoder (BAD), a new multi-agent learning method that uses an approximate Bayesian update to obtain a public belief that conditions on the actions taken by all agents in the environment. Together with the public belief, this Bayesian update effectively defines a new Markov decision process, the public belief MDP, in which the action space consists of deterministic partial policies, parameterised by deep neural networks, that can be sampled for a given public state. It exploits the fact that an agent acting only on this public belief state can still learn to use its private information if the action space is augmented to be over partial policies mapping private information into environment actions. The Bayesian update is also closely related to the theory of mind reasoning that humans carry out when observing others' actions. We first validate BAD on a proof-of-principle two-step matrix game, where it outperforms traditional policy gradient methods. We then evaluate BAD on the challenging, cooperative partial-information card game Hanabi, where in the two-player setting the method surpasses all previously published learning and hand-coded approaches.
VIREL: A Variational Inference Framework for Reinforcement Learning
Nov 03, 2018
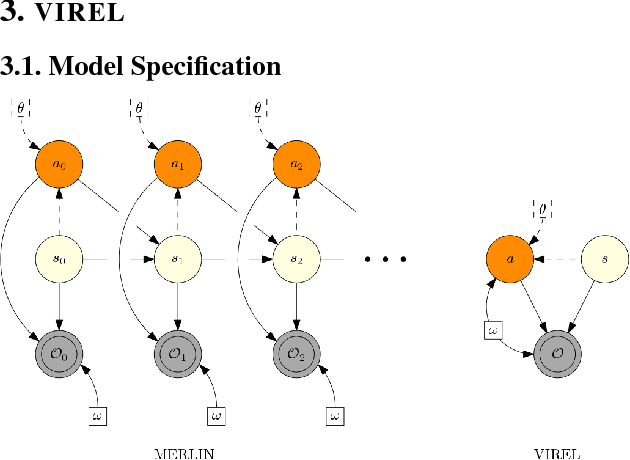

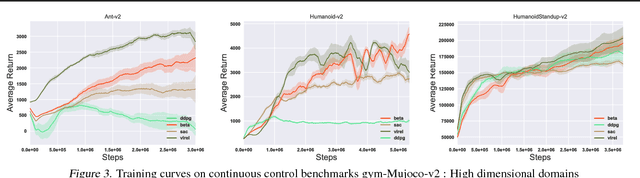
Applying probabilistic models to reinforcement learning (RL) has become an exciting direction of research owing to powerful optimisation tools such as variational inference becoming applicable to RL. However, due to their formulation, existing inference frameworks and their algorithms pose significant challenges for learning optimal policies, for example, the absence of mode capturing behaviour in pseudo-likelihood methods and difficulties in optimisation of learning objective in maximum entropy RL based approaches. We propose VIREL, a novel, theoretically grounded probabilistic inference framework for RL that utilises the action-value function in a parametrised form to capture future dynamics of the underlying Markov decision process. Owing to it's generality, our framework lends itself to current advances in variational inference. Applying the variational expectation-maximisation algorithm to our framework, we show that actor-critic algorithm can be reduced to expectation-maximization. We derive a family of methods from our framework, including state-of-the-art methods based on soft value functions. We evaluate two actor-critic algorithms derived from this family, which perform on par with soft actor critic, demonstrating that our framework offers a promising perspective on RL as inference.
CAML: Fast Context Adaptation via Meta-Learning
Oct 12, 2018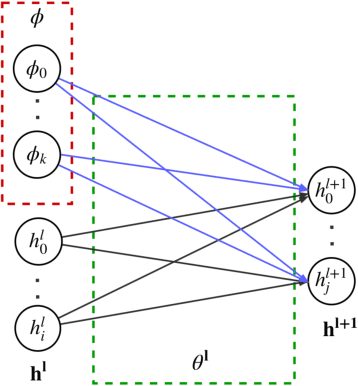

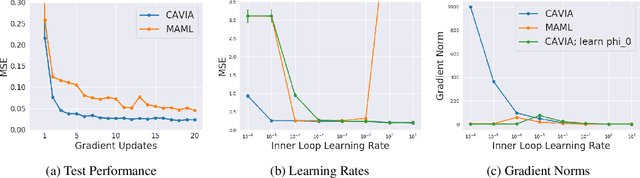
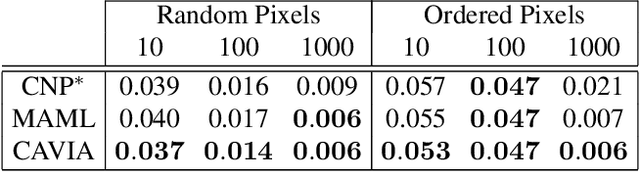
We propose CAML, a meta-learning method for fast adaptation that partitions the model parameters into two parts: context parameters that serve as additional input to the model and are adapted on individual tasks, and shared parameters that are meta-trained and shared across tasks. At test time, the context parameters are updated with one or several gradient steps on a task-specific loss that is backpropagated through the shared part of the network. Compared to approaches that adjust all parameters on a new task (e.g., MAML), our method can be scaled up to larger networks without overfitting on a single task, is easier to implement, and saves memory writes during training and network communication at test time for distributed machine learning systems. We show empirically that this approach outperforms MAML, is less sensitive to the task-specific learning rate, can capture meaningful task embeddings with the context parameters, and outperforms alternative partitionings of the parameter vectors.
Learning with Opponent-Learning Awareness
Sep 19, 2018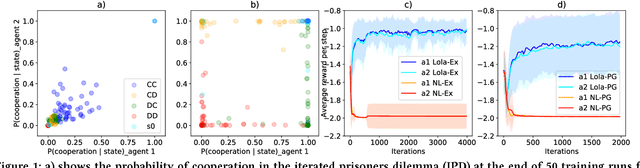
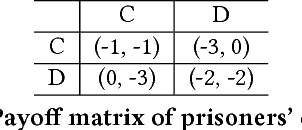
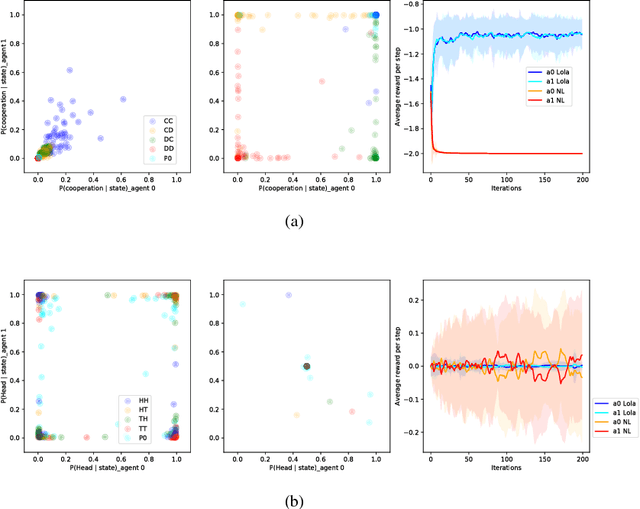
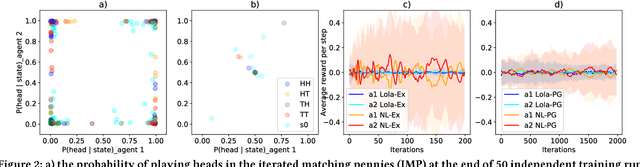
Multi-agent settings are quickly gathering importance in machine learning. This includes a plethora of recent work on deep multi-agent reinforcement learning, but also can be extended to hierarchical RL, generative adversarial networks and decentralised optimisation. In all these settings the presence of multiple learning agents renders the training problem non-stationary and often leads to unstable training or undesired final results. We present Learning with Opponent-Learning Awareness (LOLA), a method in which each agent shapes the anticipated learning of the other agents in the environment. The LOLA learning rule includes a term that accounts for the impact of one agent's policy on the anticipated parameter update of the other agents. Results show that the encounter of two LOLA agents leads to the emergence of tit-for-tat and therefore cooperation in the iterated prisoners' dilemma, while independent learning does not. In this domain, LOLA also receives higher payouts compared to a naive learner, and is robust against exploitation by higher order gradient-based methods. Applied to repeated matching pennies, LOLA agents converge to the Nash equilibrium. In a round robin tournament we show that LOLA agents successfully shape the learning of a range of multi-agent learning algorithms from literature, resulting in the highest average returns on the IPD. We also show that the LOLA update rule can be efficiently calculated using an extension of the policy gradient estimator, making the method suitable for model-free RL. The method thus scales to large parameter and input spaces and nonlinear function approximators. We apply LOLA to a grid world task with an embedded social dilemma using recurrent policies and opponent modelling. By explicitly considering the learning of the other agent, LOLA agents learn to cooperate out of self-interest. The code is at github.com/alshedivat/lola.
DiCE: The Infinitely Differentiable Monte-Carlo Estimator
Sep 19, 2018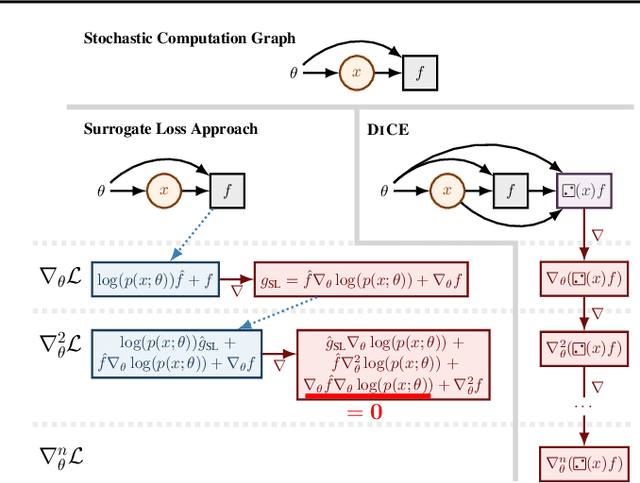
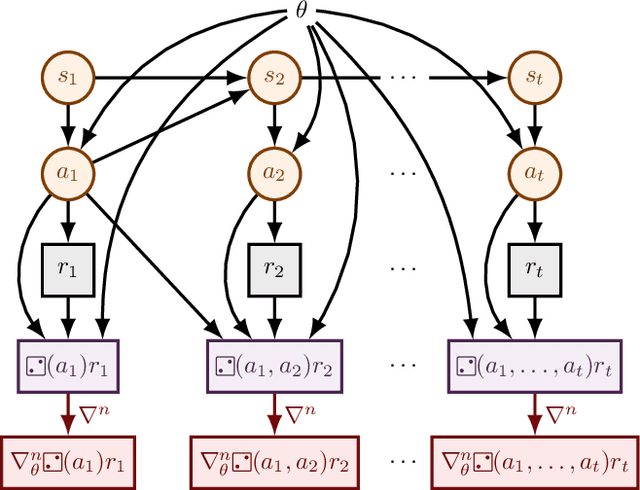
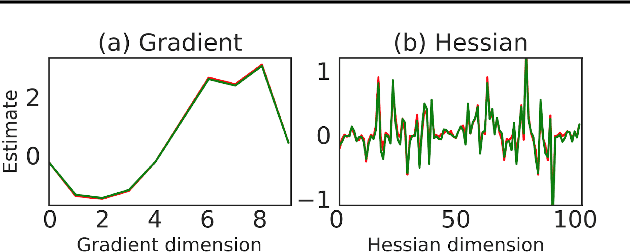
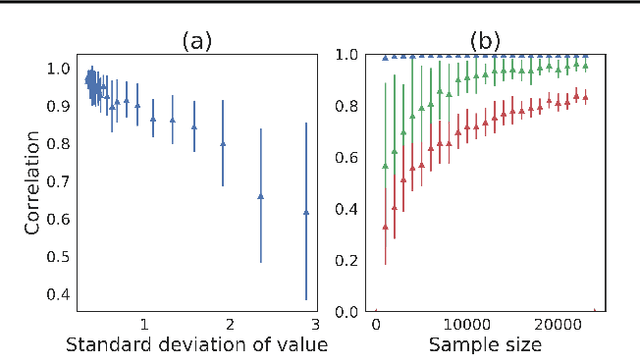
The score function estimator is widely used for estimating gradients of stochastic objectives in stochastic computation graphs (SCG), eg, in reinforcement learning and meta-learning. While deriving the first-order gradient estimators by differentiating a surrogate loss (SL) objective is computationally and conceptually simple, using the same approach for higher-order derivatives is more challenging. Firstly, analytically deriving and implementing such estimators is laborious and not compliant with automatic differentiation. Secondly, repeatedly applying SL to construct new objectives for each order derivative involves increasingly cumbersome graph manipulations. Lastly, to match the first-order gradient under differentiation, SL treats part of the cost as a fixed sample, which we show leads to missing and wrong terms for estimators of higher-order derivatives. To address all these shortcomings in a unified way, we introduce DiCE, which provides a single objective that can be differentiated repeatedly, generating correct estimators of derivatives of any order in SCGs. Unlike SL, DiCE relies on automatic differentiation for performing the requisite graph manipulations. We verify the correctness of DiCE both through a proof and numerical evaluation of the DiCE derivative estimates. We also use DiCE to propose and evaluate a novel approach for multi-agent learning. Our code is available at https://www.github.com/alshedivat/lola.