 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAD: Self-Supervised Pre-Training with Patchwise-Scale Adapter for Infrared Images
Dec 13, 2023Self-supervised learning (SSL) for RGB images has achieved significant success, yet there is still limited research on SSL for infrared images, primarily due to three prominent challenges: 1) the lack of a suitable large-scale infrared pre-training dataset, 2) the distinctiveness of non-iconic infrared images rendering common pre-training tasks like masked image modeling (MIM) less effective, and 3) the scarcity of fine-grained textures making it particularly challenging to learn general image features. To address these issues, we construct a Multi-Scene Infrared Pre-training (MSIP) dataset comprising 178,756 images, and introduce object-sensitive random RoI cropping, an image preprocessing method, to tackle the challenge posed by non-iconic images. To alleviate the impact of weak textures on feature learning, we propose a pre-training paradigm called Pre-training with ADapter (PAD), which uses adapters to learn domain-specific features while freezing parameters pre-trained on ImageNet to retain the general feature extraction capability. This new paradigm is applicable to any transformer-based SSL method. Furthermore, to achieve more flexible coordination between pre-trained and newly-learned features in different layers and patches, a patchwise-scale adapter with dynamically learnable scale factors is introduced. Extensive experiments on three downstream tasks show that PAD, with only 1.23M pre-trainable parameters, outperforms other baseline paradigms including continual full pre-training on MSIP. Our code and dataset are available at https://github.com/casiatao/PAD.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review
May 09, 2023



Change detection is an essential and widely utilized task in remote sensing that aims to detect and analyze changes occurring in the same geographical area over time, which has broad applications in urban development, agricultural surveys, and land cover monitoring. Detecting changes in remote sensing images is a complex challenge due to various factors, including variations in image quality, noise, registration errors, illumination changes, complex landscapes, and spatial heterogeneity. In recent years, deep learning has emerged as a powerful tool for feature extraction and addressing these challenges. Its versatility has resulted in its widespread adoption for numerous image-processing tasks. This paper presents a comprehensive survey of significant advancements in change detection for remote sensing images over the past decade. We first introduce some preliminary knowledge for the change detection task, such as problem definition, datasets, evaluation metrics, and transformer basics, as well as provide a detailed taxonomy of existing algorithms from three different perspectives: algorithm granularity, supervision modes, and learning frameworks in the methodology section. This survey enables readers to gain systematic knowledge of change detection tasks from various angles. We then summarize the state-of-the-art performance on several dominant change detection datasets, providing insights into the strengths and limitations of existing algorithms. Based on our survey, some future research directions for change detection in remote sensing are well identified. This survey paper will shed some light on the community and inspire further research efforts in the change detection task.
Free Lunch for Generating Effective Outlier Supervision
Jan 17, 2023



When deployed in practical applications, computer vision systems will encounter numerous unexpected images (\emph{{i.e.}}, out-of-distribution data). Due to the potentially raised safety risks, these aforementioned unseen data should be carefully identified and handled. Generally, existing approaches in dealing with out-of-distribution (OOD) detection mainly focus on the statistical difference between the features of OOD and in-distribution (ID) data extracted by the classifiers. Although many of these schemes have brought considerable performance improvements, reducing the false positive rate (FPR) when processing open-set images, they necessarily lack reliable theoretical analysis and generalization guarantees. Unlike the observed ways, in this paper, we investigate the OOD detection problem based on the Bayes rule and present a convincing description of the reason for failures encountered by conventional classifiers. Concretely, our analysis reveals that refining the probability distribution yielded by the vanilla neural networks is necessary for OOD detection, alleviating the issues of assigning high confidence to OOD data. To achieve this effortlessly, we propose an ultra-effective method to generate near-realistic outlier supervision. Extensive experiments on large-scale benchmarks reveal that our proposed \texttt{BayesAug} significantly reduces the FPR95 over 12.50\% compared with the previous schemes, boosting the reliability of machine learning systems. The code will be made publicly available.
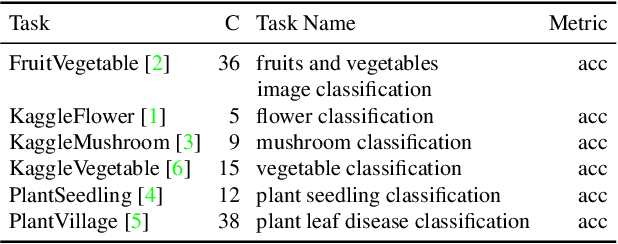
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022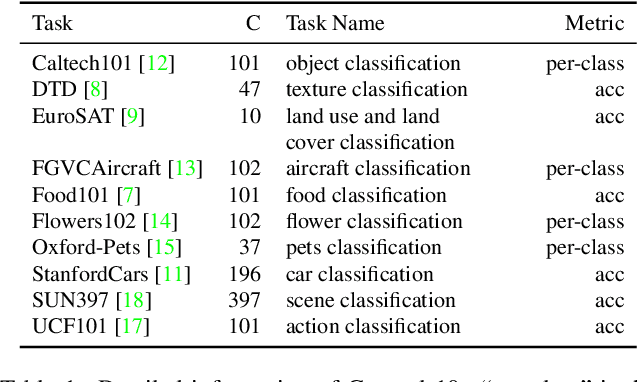

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.
Pro-tuning: Unified Prompt Tuning for Vision Tasks
Aug 14, 2022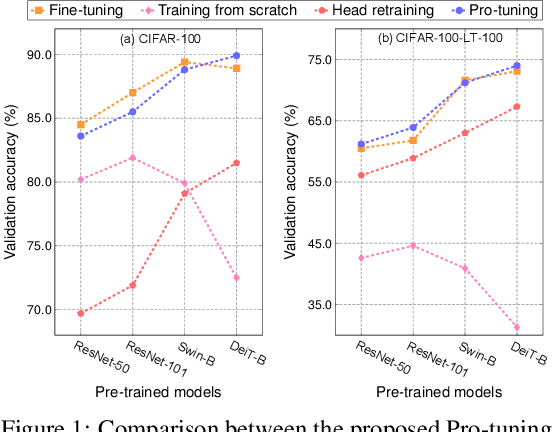
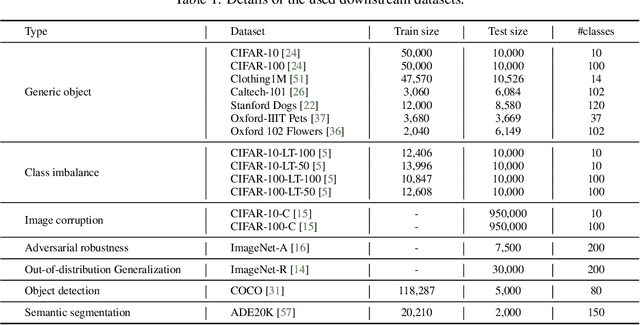
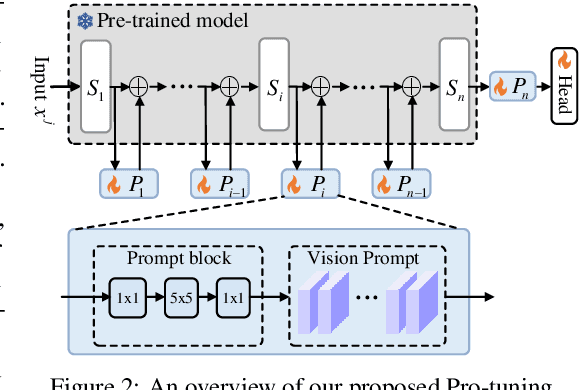
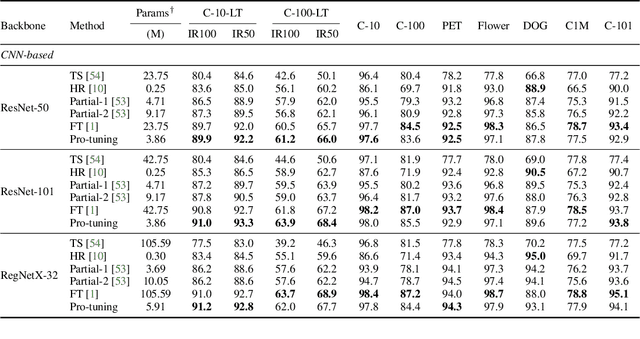
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.
Expanding Language-Image Pretrained Models for General Video Recognition
Aug 04, 2022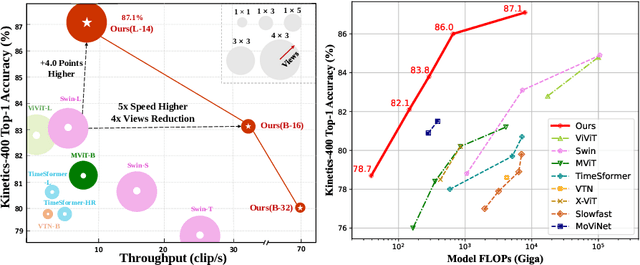
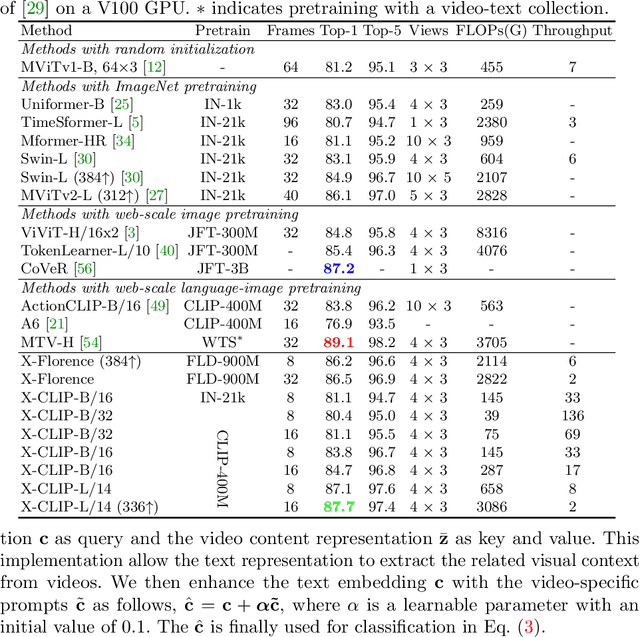
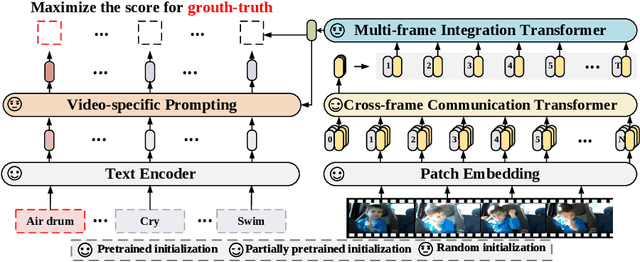
Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited. Code and models are available at https://aka.ms/X-CLIP
Domain Decorrelation with Potential Energy Ranking
Jul 26, 2022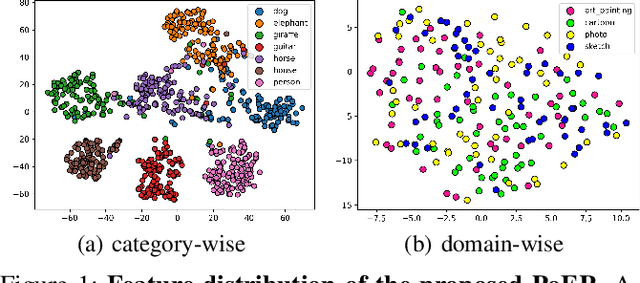
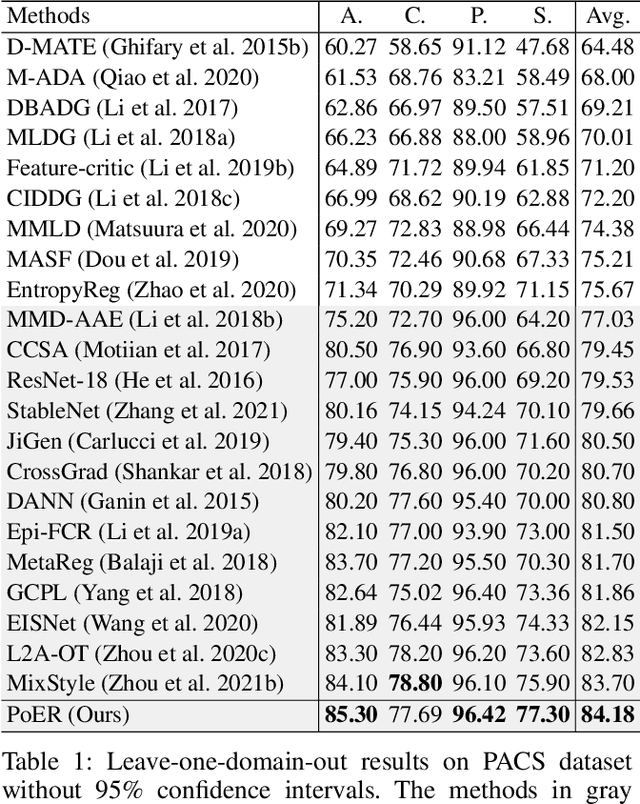

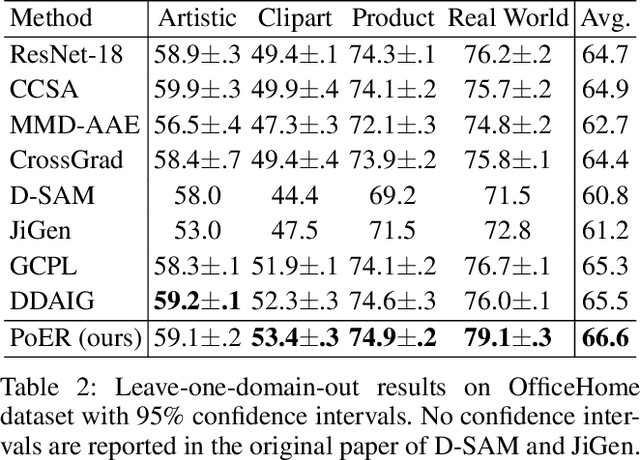
Machine learning systems, especially the methods based on deep learning, enjoy great success in modern computer vision tasks under experimental settings. Generally, these classic deep learning methods are built on the \emph{i.i.d.} assumption, supposing the training and test data are drawn from a similar distribution independently and identically. However, the aforementioned \emph{i.i.d.} assumption is in general unavailable in the real-world scenario, and as a result, leads to sharp performance decay of deep learning algorithms. Behind this, domain shift is one of the primary factors to be blamed. In order to tackle this problem, we propose using \textbf{Po}tential \textbf{E}nergy \textbf{R}anking (PoER) to decouple the object feature and the domain feature (\emph{i.e.,} appearance feature) in given images, promoting the learning of label-discriminative features while filtering out the irrelevant correlations between the objects and the background. PoER helps the neural networks to capture label-related features which contain the domain information first in shallow layers and then distills the label-discriminative representations out progressively, enforcing the neural networks to be aware of the characteristic of objects and background which is vital to the generation of domain-invariant features. PoER reports superior performance on domain generalization benchmarks, improving the average top-1 accuracy by at least 1.20\% compared to the existing methods. Moreover, we use PoER in the ECCV 2022 NICO Challenge\footnote{https://nicochallenge.com}, achieving top place with only a vanilla ResNet-18. The code has been made available at https://github.com/ForeverPs/PoER.
Adversarial Gradient Driven Exploration for Deep Click-Through Rate Prediction
Dec 21, 2021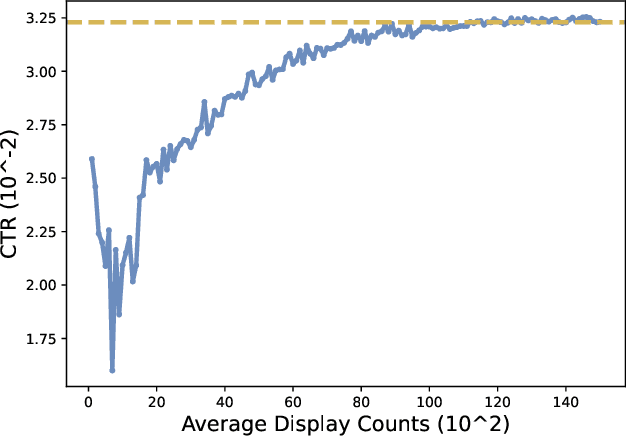
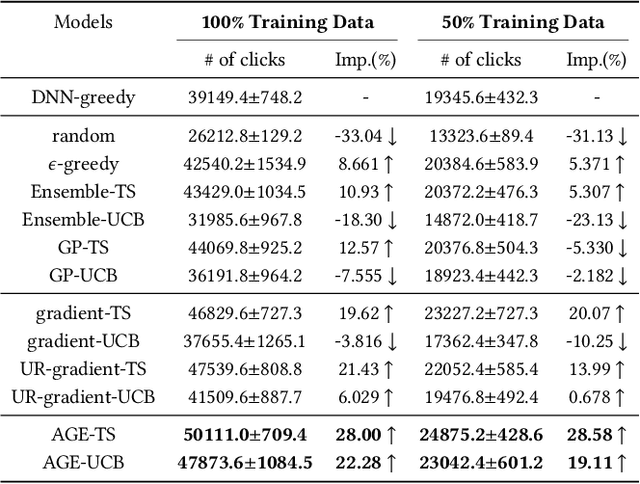
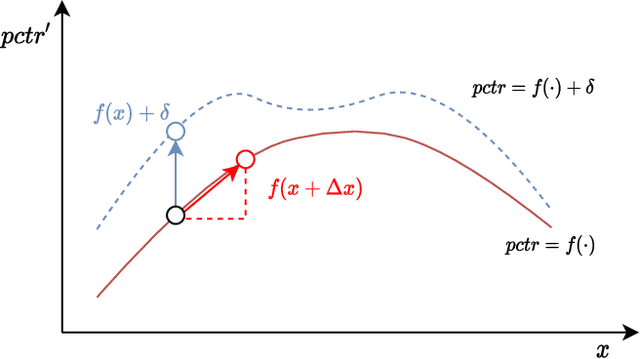
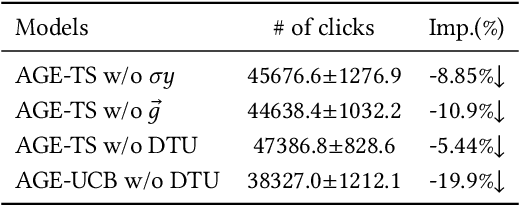
Nowadays, data-driven deep neural models have already shown remarkable progress on Click-through Rate (CTR) prediction. Unfortunately, the effectiveness of such models may fail when there are insufficient data. To handle this issue, researchers often adopt exploration strategies to examine items based on the estimated reward, e.g., UCB or Thompson Sampling. In the context of Exploitation-and-Exploration for CTR prediction, recent studies have attempted to utilize the prediction uncertainty along with model prediction as the reward score. However, we argue that such an approach may make the final ranking score deviate from the original distribution, and thereby affect model performance in the online system. In this paper, we propose a novel exploration method called \textbf{A}dversarial \textbf{G}radient Driven \textbf{E}xploration (AGE). Specifically, we propose a Pseudo-Exploration Module to simulate the gradient updating process, which can approximate the influence of the samples of to-be-explored items for the model. In addition, for better exploration efficiency, we propose an Dynamic Threshold Unit to eliminate the effects of those samples with low potential CTR. The effectiveness of our approach was demonstrated on an open-access academic dataset. Meanwhile, AGE has also been deployed in a real-world display advertising platform and all online metrics have been significantly improved.
Alleviating Mode Collapse in GAN via Diversity Penalty Module
Aug 24, 2021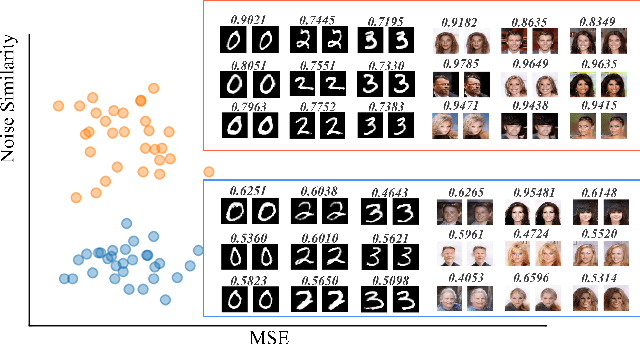
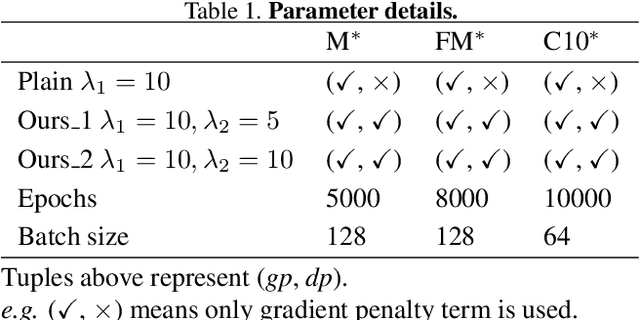
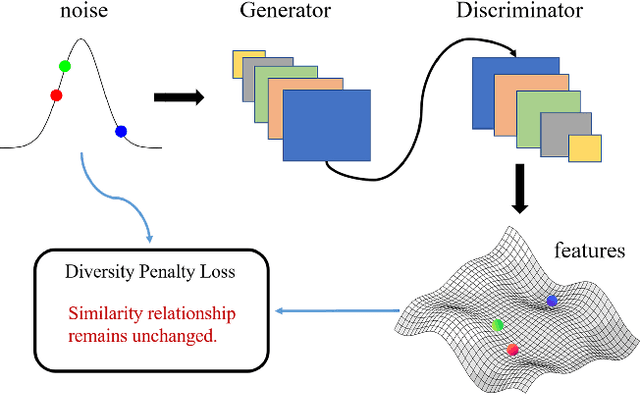
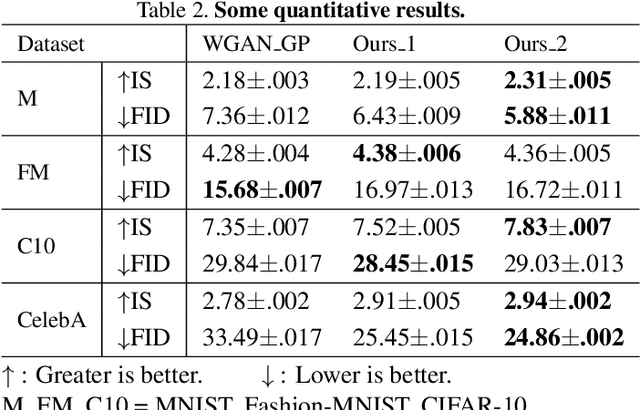
The vanilla GAN (Goodfellow et al. 2014) suffers from mode collapse deeply, which usually manifests as that the images generated by generators tend to have a high similarity amongst them, even though their corresponding latent vectors have been very different. In this paper, we introduce a pluggable diversity penalty module (DPM) to alleviate mode collapse of GANs. It reduces the similarity of image pairs in feature space, i.e., if two latent vectors are different, then we enforce the generator to generate two images with different features. The normalized Gram matrix is used to measure the similarity. We compare the proposed method with Unrolled GAN (Metz et al. 2016), BourGAN (Xiao, Zhong, and Zheng 2018), PacGAN (Lin et al. 2018), VEEGAN (Srivastava et al. 2017) and ALI (Dumoulin et al. 2016) on 2D synthetic dataset, and results show that the diversity penalty module can help GAN capture much more modes of the data distribution. Further, in classification tasks, we apply this method as image data augmentation on MNIST, Fashion- MNIST and CIFAR-10, and the classification testing accuracy is improved by 0.24%, 1.34% and 0.52% compared with WGAN GP (Gulrajani et al. 2017), respectively. In domain translation, diversity penalty module can help StarGAN (Choi et al. 2018) generate more accurate attention masks and accelarate the convergence process. Finally, we quantitatively evaluate the proposed method with IS and FID on CelebA, CIFAR-10, MNIST and Fashion-MNIST, and the results suggest GAN with diversity penalty module gets much higher IS and lower FID compared with some SOTA GAN architectures.