 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarMix: A General Data Augmentation Technique for LiDAR Point Clouds
Jul 30, 2022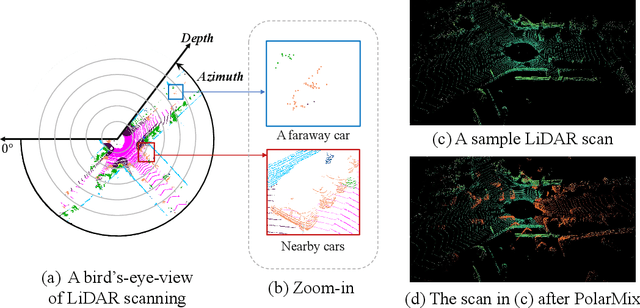
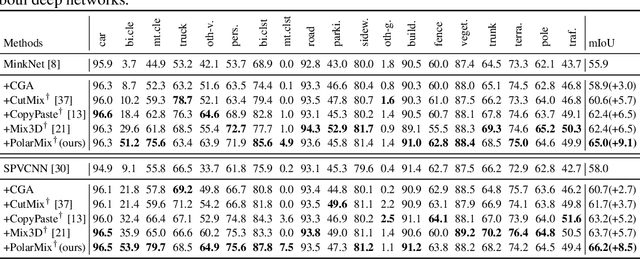
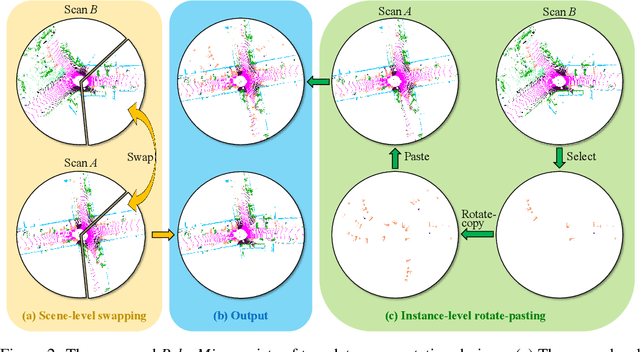
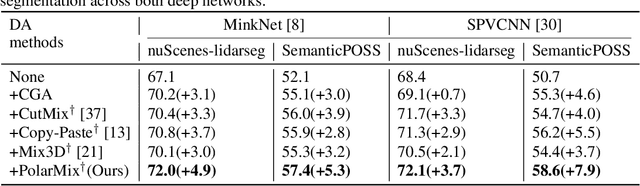
LiDAR point clouds, which are usually scanned by rotating LiDAR sensors continuously, capture precise geometry of the surrounding environment and are crucial to many autonomous detection and navigation tasks. Though many 3D deep architectures have been developed, efficient collection and annotation of large amounts of point clouds remain one major challenge in the analytic and understanding of point cloud data. This paper presents PolarMix, a point cloud augmentation technique that is simple and generic but can mitigate the data constraint effectively across different perception tasks and scenarios. PolarMix enriches point cloud distributions and preserves point cloud fidelity via two cross-scan augmentation strategies that cut, edit, and mix point clouds along the scanning direction. The first is scene-level swapping which exchanges point cloud sectors of two LiDAR scans that are cut along the azimuth axis. The second is instance-level rotation and paste which crops point instances from one LiDAR scan, rotates them by multiple angles (to create multiple copies), and paste the rotated point instances into other scans. Extensive experiments show that PolarMix achieves superior performance consistently across different perception tasks and scenarios. In addition, it can work as plug-and-play for various 3D deep architectures and also performs well for unsupervised domain adaptation.
Meta-DETR: Image-Level Few-Shot Detection with Inter-Class Correlation Exploitation
Jul 30, 2022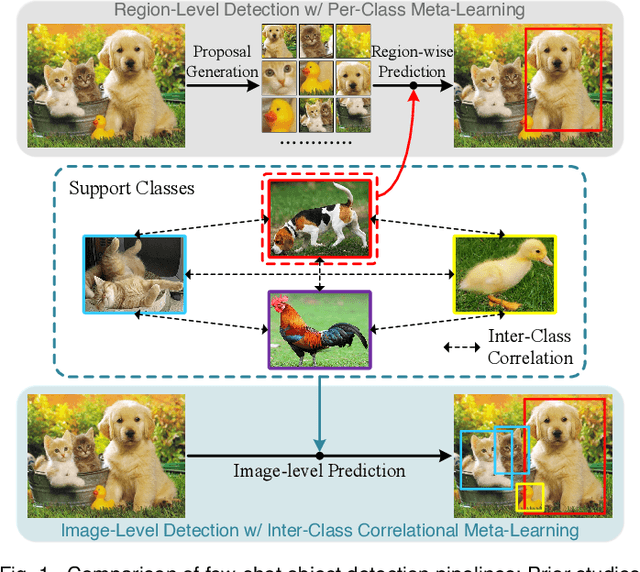
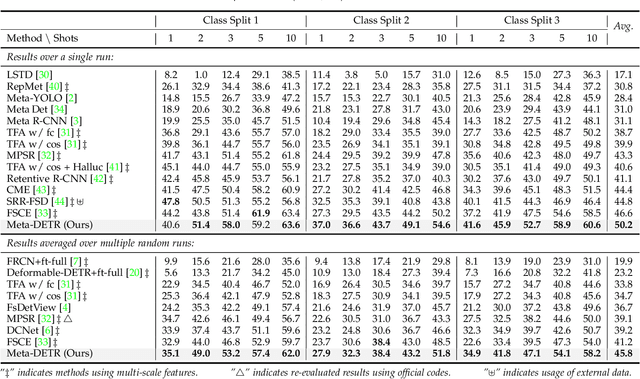
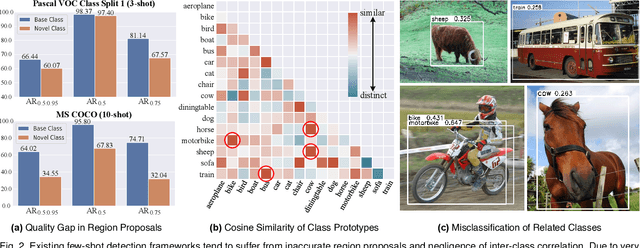
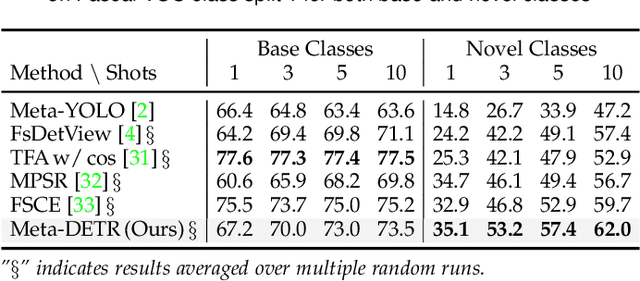
Few-shot object detection has been extensively investigated by incorporating meta-learning into region-based detection frameworks. Despite its success, the said paradigm is still constrained by several factors, such as (i) low-quality region proposals for novel classes and (ii) negligence of the inter-class correlation among different classes. Such limitations hinder the generalization of base-class knowledge for the detection of novel-class objects. In this work, we design Meta-DETR, which (i) is the first image-level few-shot detector, and (ii) introduces a novel inter-class correlational meta-learning strategy to capture and leverage the correlation among different classes for robust and accurate few-shot object detection. Meta-DETR works entirely at image level without any region proposals, which circumvents the constraint of inaccurate proposals in prevalent few-shot detection frameworks. In addition, the introduced correlational meta-learning enables Meta-DETR to simultaneously attend to multiple support classes within a single feedforward, which allows to capture the inter-class correlation among different classes, thus significantly reducing the misclassification over similar classes and enhancing knowledge generalization to novel classes. Experiments over multiple few-shot object detection benchmarks show that the proposed Meta-DETR outperforms state-of-the-art methods by large margins. The implementation codes are available at https://github.com/ZhangGongjie/Meta-DETR.
Semantic-Aligned Matching for Enhanced DETR Convergence and Multi-Scale Feature Fusion
Jul 28, 2022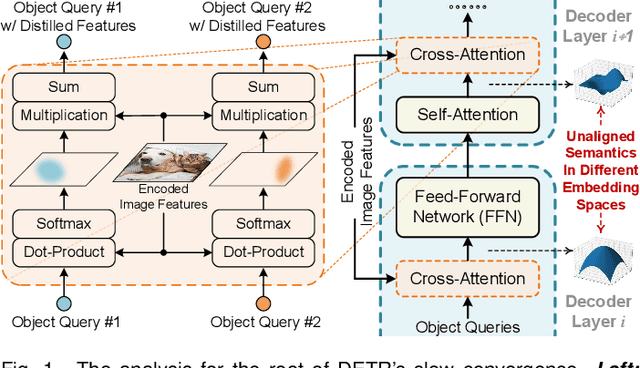
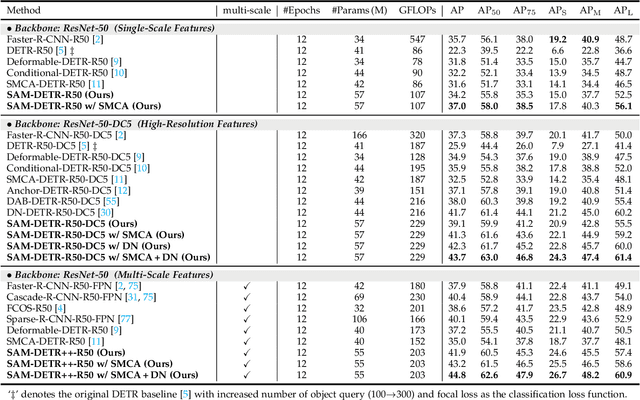
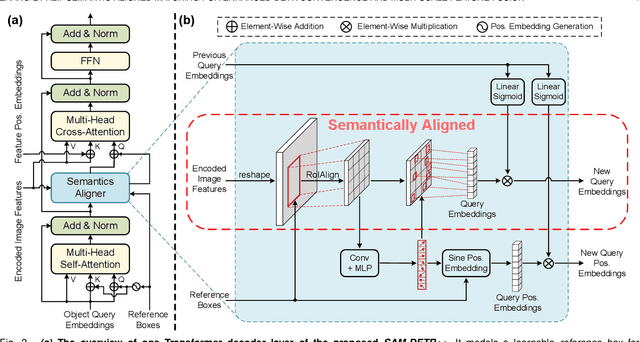
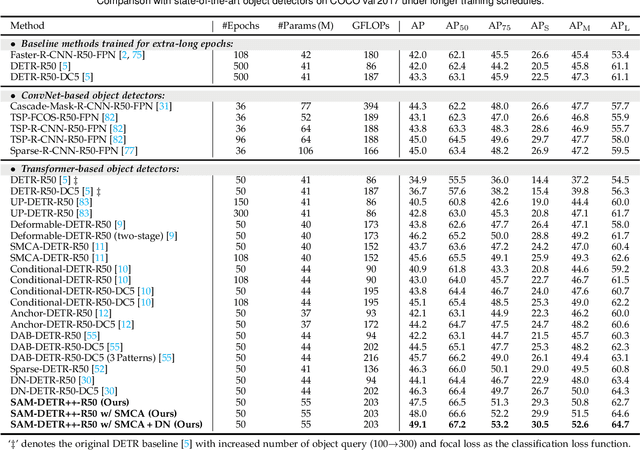
The recently proposed DEtection TRansformer (DETR) has established a fully end-to-end paradigm for object detection. However, DETR suffers from slow training convergence, which hinders its applicability to various detection tasks. We observe that DETR's slow convergence is largely attributed to the difficulty in matching object queries to relevant regions due to the unaligned semantics between object queries and encoded image features. With this observation, we design Semantic-Aligned-Matching DETR++ (SAM-DETR++) to accelerate DETR's convergence and improve detection performance. The core of SAM-DETR++ is a plug-and-play module that projects object queries and encoded image features into the same feature embedding space, where each object query can be easily matched to relevant regions with similar semantics. Besides, SAM-DETR++ searches for multiple representative keypoints and exploits their features for semantic-aligned matching with enhanced representation capacity. Furthermore, SAM-DETR++ can effectively fuse multi-scale features in a coarse-to-fine manner on the basis of the designed semantic-aligned matching. Extensive experiments show that the proposed SAM-DETR++ achieves superior convergence speed and competitive detection accuracy. Additionally, as a plug-and-play method, SAM-DETR++ can complement existing DETR convergence solutions with even better performance, achieving 44.8% AP with merely 12 training epochs and 49.1% AP with 50 training epochs on COCO val2017 with ResNet-50. Codes are available at https://github.com/ZhangGongjie/SAM-DETR .
Contextual Text Block Detection towards Scene Text Understanding
Jul 26, 2022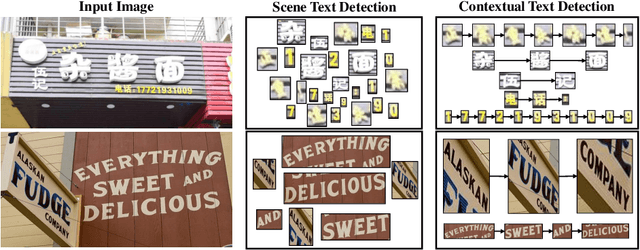

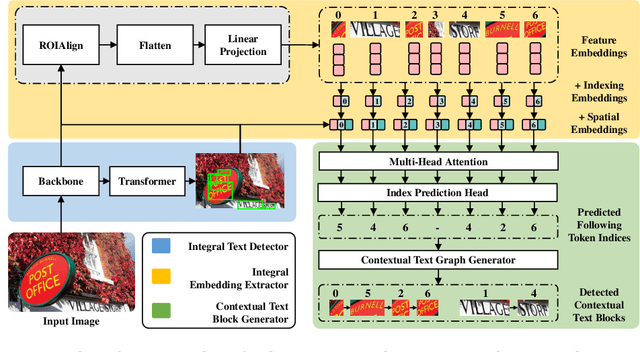
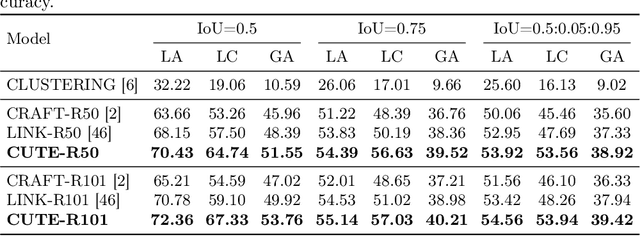
Most existing scene text detectors focus on detecting characters or words that only capture partial text messages due to missing contextual information. For a better understanding of text in scenes, it is more desired to detect contextual text blocks (CTBs) which consist of one or multiple integral text units (e.g., characters, words, or phrases) in natural reading order and transmit certain complete text messages. This paper presents contextual text detection, a new setup that detects CTBs for better understanding of texts in scenes. We formulate the new setup by a dual detection task which first detects integral text units and then groups them into a CTB. To this end, we design a novel scene text clustering technique that treats integral text units as tokens and groups them (belonging to the same CTB) into an ordered token sequence. In addition, we create two datasets SCUT-CTW-Context and ReCTS-Context to facilitate future research, where each CTB is well annotated by an ordered sequence of integral text units. Further, we introduce three metrics that measure contextual text detection in local accuracy, continuity, and global accuracy. Extensive experiments show that our method accurately detects CTBs which effectively facilitates downstream tasks such as text classification and translation. The project is available at https://sg-vilab.github.io/publication/xue2022contextual/.
Auto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022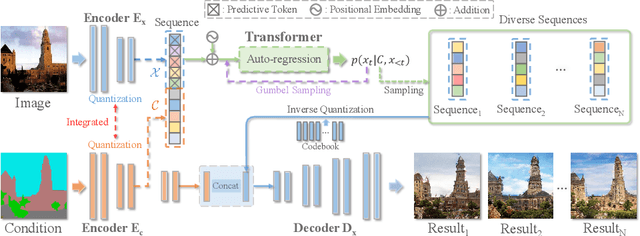
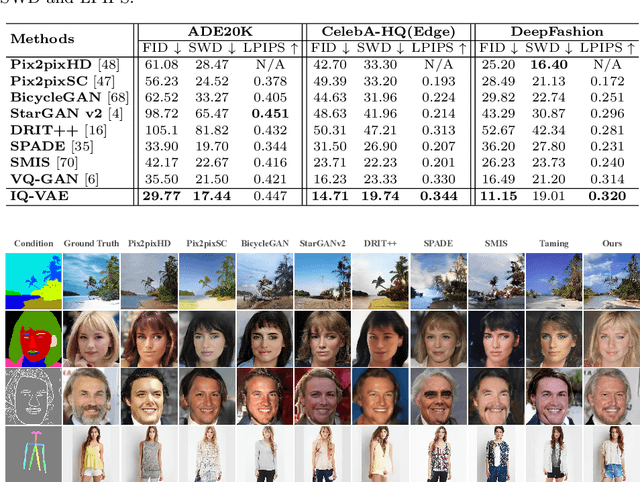
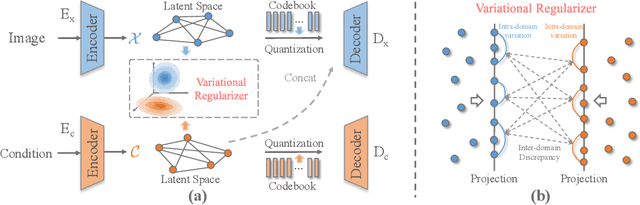
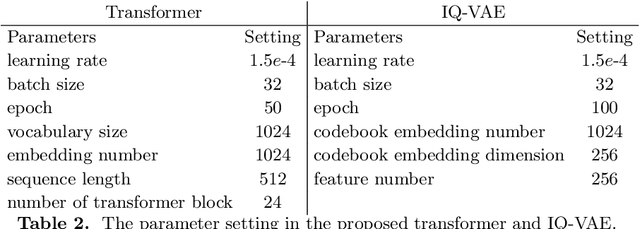
Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
Towards Counterfactual Image Manipulation via CLIP
Jul 12, 2022
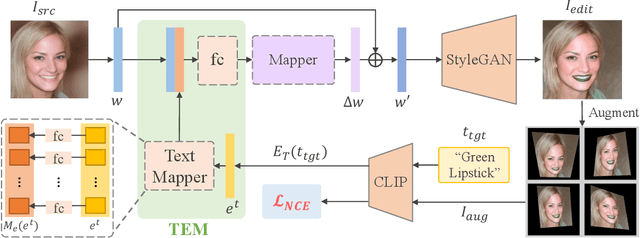
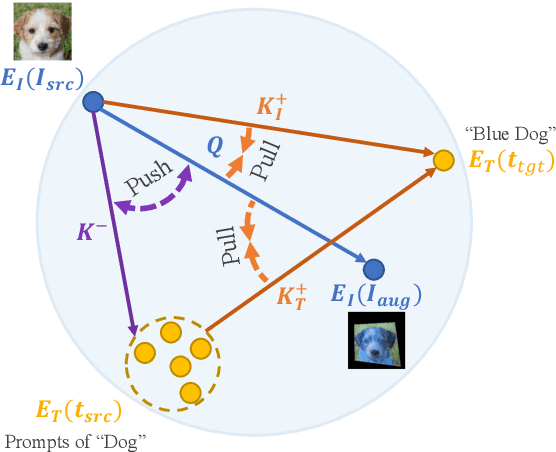

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
VMRF: View Matching Neural Radiance Fields
Jul 06, 2022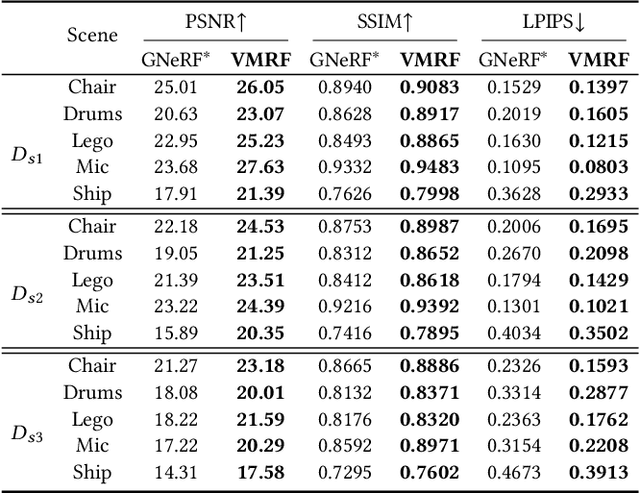
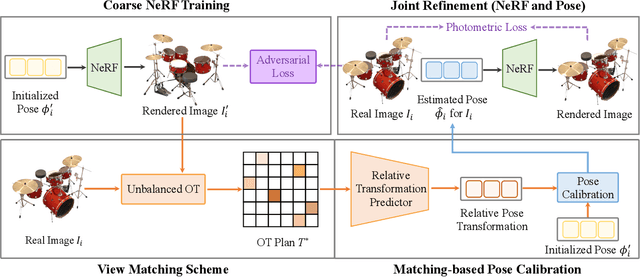
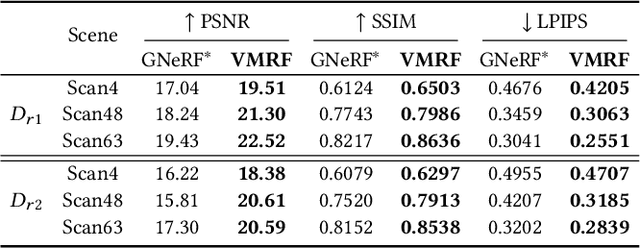
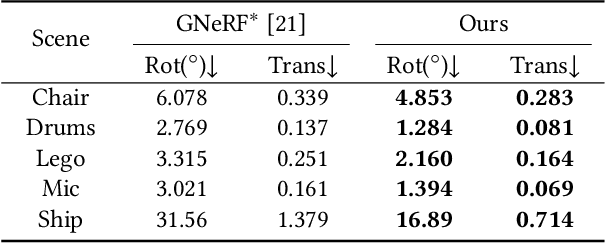
Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
Domain Adaptive Video Segmentation via Temporal Pseudo Supervision
Jul 06, 2022
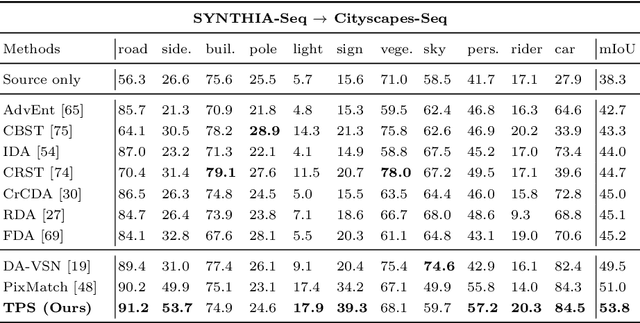
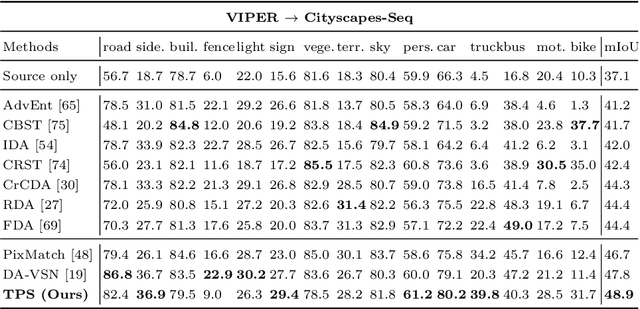

Video semantic segmentation has achieved great progress under the supervision of large amounts of labelled training data. However, domain adaptive video segmentation, which can mitigate data labelling constraints by adapting from a labelled source domain toward an unlabelled target domain, is largely neglected. We design temporal pseudo supervision (TPS), a simple and effective method that explores the idea of consistency training for learning effective representations from unlabelled target videos. Unlike traditional consistency training that builds consistency in spatial space, we explore consistency training in spatiotemporal space by enforcing model consistency across augmented video frames which helps learn from more diverse target data. Specifically, we design cross-frame pseudo labelling to provide pseudo supervision from previous video frames while learning from the augmented current video frames. The cross-frame pseudo labelling encourages the network to produce high-certainty predictions, which facilitates consistency training with cross-frame augmentation effectively. Extensive experiments over multiple public datasets show that TPS is simpler to implement, much more stable to train, and achieves superior video segmentation accuracy as compared with the state-of-the-art.
Hierarchical Mask Calibration for Unified Domain Adaptive Panoptic Segmentation
Jun 30, 2022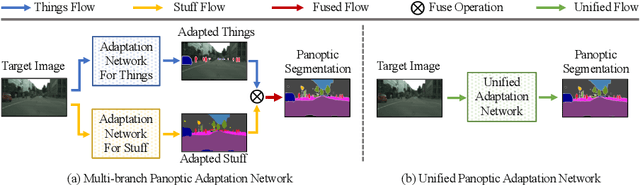

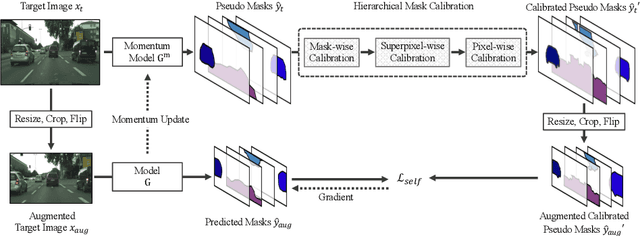

Domain adaptive panoptic segmentation aims to mitigate data annotation challenge by leveraging off-the-shelf annotated data in one or multiple related source domains. However, existing studies employ two networks for instance segmentation and semantic segmentation separately which lead to a large amount of network parameters with complicated and computationally intensive training and inference processes. We design UniDAPS, a Unified Domain Adaptive Panoptic Segmentation network that is simple but capable of achieving domain adaptive instance segmentation and semantic segmentation simultaneously within a single network. UniDAPS introduces Hierarchical Mask Calibration (HMC) that rectifies the predicted pseudo masks, pseudo superpixels and pseudo pixels and performs network re-training via an online self-training process on the fly. It has three unique features: 1) it enables unified domain adaptive panoptic adaptation; 2) it mitigates false predictions and improves domain adaptive panoptic segmentation effectively; 3) it is end-to-end trainable with much less parameters and simpler training and inference pipeline. Extensive experiments over multiple public benchmarks show that UniDAPS achieves superior domain adaptive panoptic segmentation as compared with the state-of-the-art.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022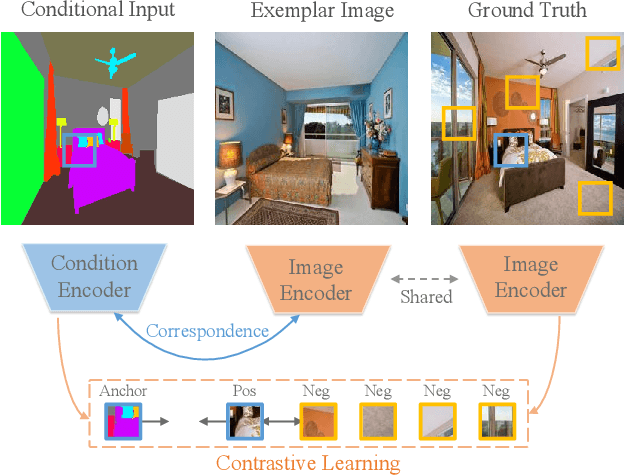
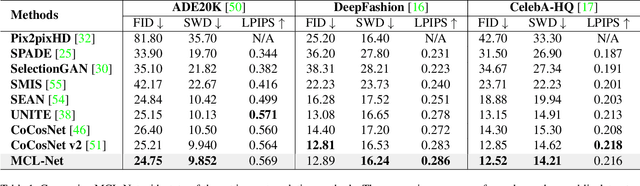
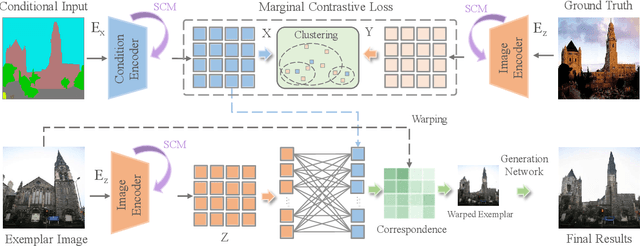
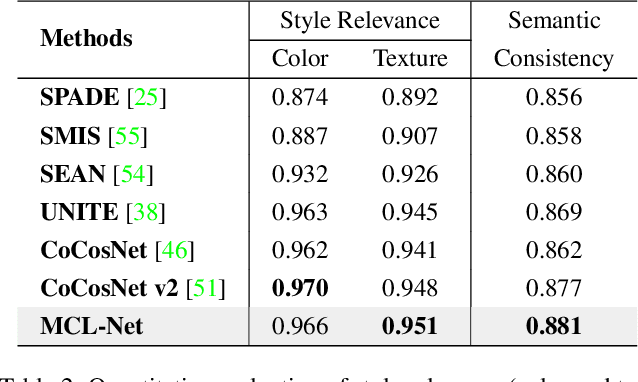
Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.