 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Large-Scale Evolution of Image Classifiers
Jun 11, 2017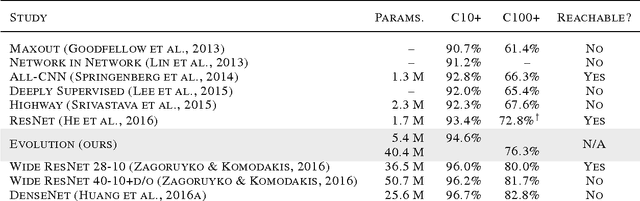
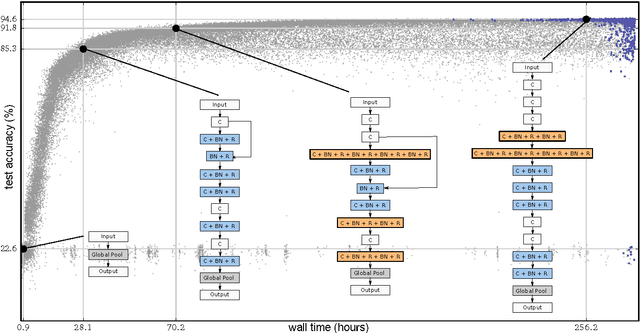
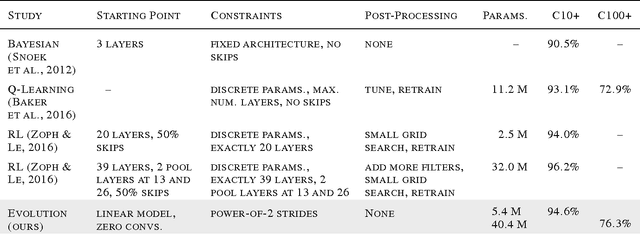
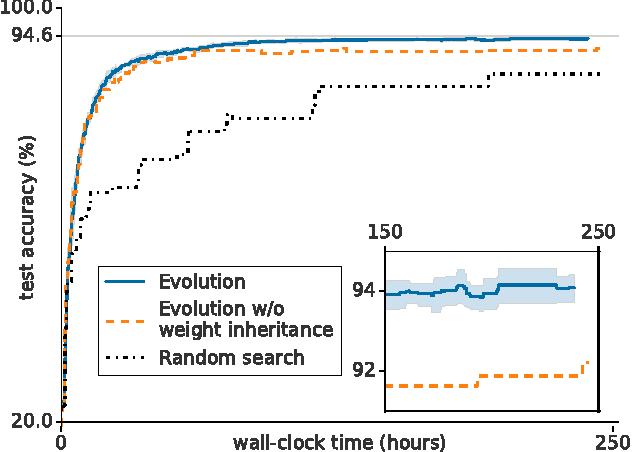
Neural networks have proven effective at solving difficult problems but designing their architectures can be challenging, even for image classification problems alone. Our goal is to minimize human participation, so we employ evolutionary algorithms to discover such networks automatically. Despite significant computational requirements, we show that it is now possible to evolve models with accuracies within the range of those published in the last year. Specifically, we employ simple evolutionary techniques at unprecedented scales to discover models for the CIFAR-10 and CIFAR-100 datasets, starting from trivial initial conditions and reaching accuracies of 94.6% (95.6% for ensemble) and 77.0%, respectively. To do this, we use novel and intuitive mutation operators that navigate large search spaces; we stress that no human participation is required once evolution starts and that the output is a fully-trained model. Throughout this work, we place special emphasis on the repeatability of results, the variability in the outcomes and the computational requirements.
TensorFlow: A system for large-scale machine learning
May 31, 2016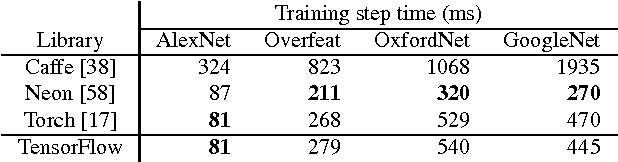

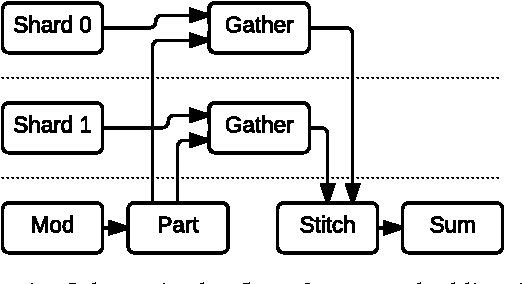
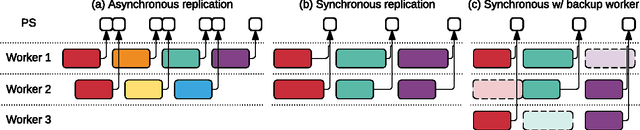
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016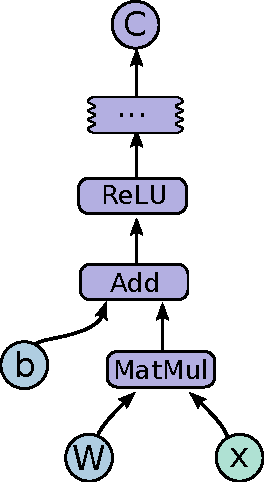

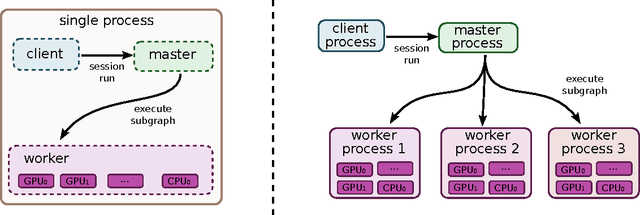
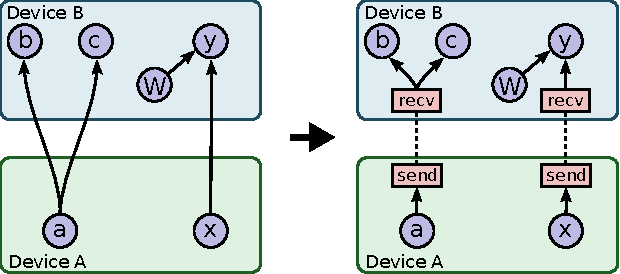
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.