 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Broken Symmetry Phase of Solid Hydrogen: A Neural Network Variational Monte Carlo Study
Dec 19, 2025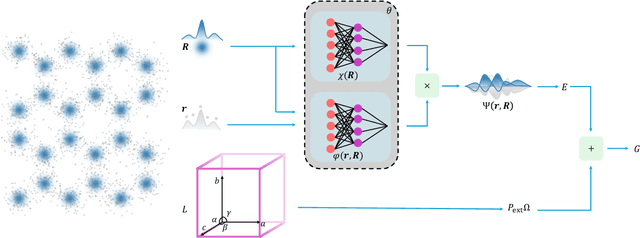
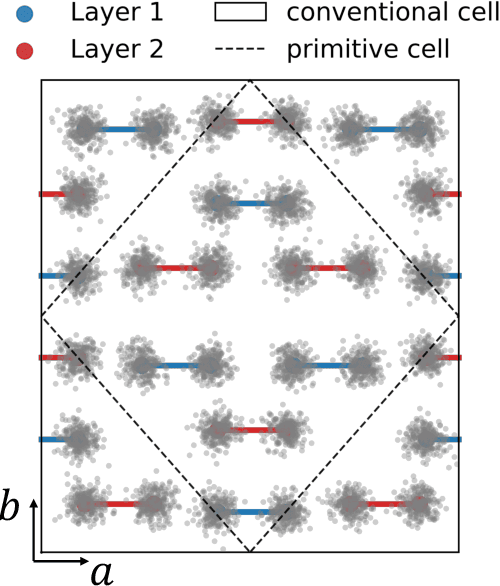
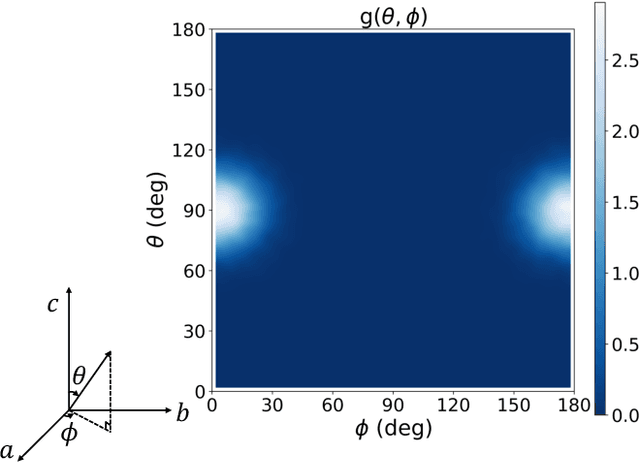
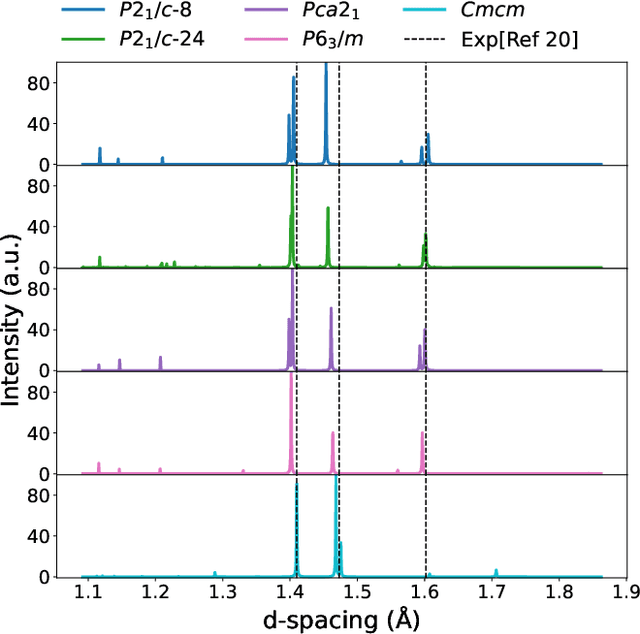
The crystal structure of high-pressure solid hydrogen remains a fundamental open problem. Although the research frontier has mostly shifted toward ultra-high pressure phases above 400 GPa, we show that even the broken symmetry phase observed around 130~GPa requires revisiting due to its intricate coupling of electronic and nuclear degrees of freedom. Here, we develop a first principle quantum Monte Carlo framework based on a deep neural network wave function that treats both electrons and nuclei quantum mechanically within the constant pressure ensemble. Our calculations reveal an unreported ground-state structure candidate for the broken symmetry phase with $Cmcm$ space group symmetry, and we test its stability up to 96 atoms. The predicted structure quantitatively matches the experimental equation of state and X-ray diffraction patterns. Furthermore, our group-theoretical analysis shows that the $Cmcm$ structure is compatible with existing Raman and infrared spectroscopic data. Crucially, static density functional theory calculation reveals the $Cmcm$ structure as a dynamically unstable saddle point on the Born-Oppenheimer potential energy surface, demonstrating that a full quantum many-body treatment of the problem is necessary. These results shed new light on the phase diagram of high-pressure hydrogen and call for further experimental verifications.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.