 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Global Feature Aggregation for Real-Time Indirect Illumination
Aug 12, 2025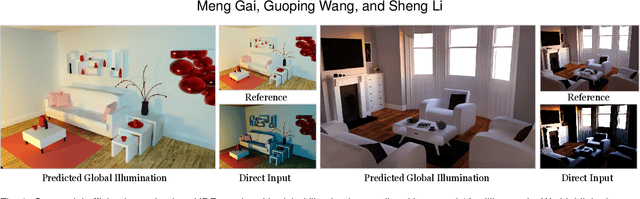
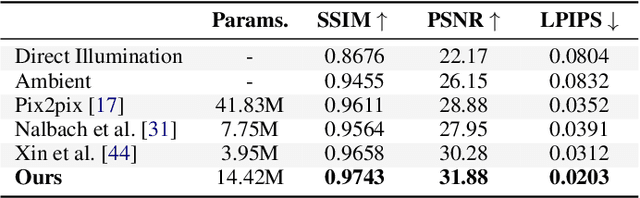
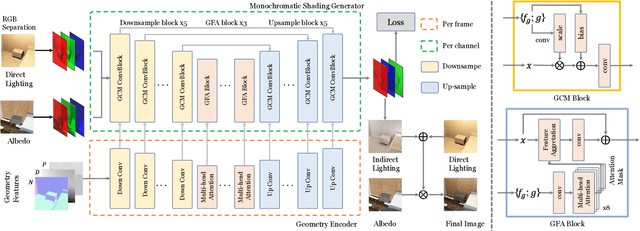

Real-time rendering with global illumination is crucial to afford the user realistic experience in virtual environments. We present a learning-based estimator to predict diffuse indirect illumination in screen space, which then is combined with direct illumination to synthesize globally-illuminated high dynamic range (HDR) results. Our approach tackles the challenges of capturing long-range/long-distance indirect illumination when employing neural networks and is generalized to handle complex lighting and scenarios. From the neural network thinking of the solver to the rendering equation, we present a novel network architecture to predict indirect illumination. Our network is equipped with a modified attention mechanism that aggregates global information guided by spacial geometry features, as well as a monochromatic design that encodes each color channel individually. We conducted extensive evaluations, and the experimental results demonstrate our superiority over previous learning-based techniques. Our approach excels at handling complex lighting such as varying-colored lighting and environment lighting. It can successfully capture distant indirect illumination and simulates the interreflections between textured surfaces well (i.e., color bleeding effects); it can also effectively handle new scenes that are not present in the training dataset.
Vertex Features for Neural Global Illumination
Aug 11, 2025Recent research on learnable neural representations has been widely adopted in the field of 3D scene reconstruction and neural rendering applications. However, traditional feature grid representations often suffer from substantial memory footprint, posing a significant bottleneck for modern parallel computing hardware. In this paper, we present neural vertex features, a generalized formulation of learnable representation for neural rendering tasks involving explicit mesh surfaces. Instead of uniformly distributing neural features throughout 3D space, our method stores learnable features directly at mesh vertices, leveraging the underlying geometry as a compact and structured representation for neural processing. This not only optimizes memory efficiency, but also improves feature representation by aligning compactly with the surface using task-specific geometric priors. We validate our neural representation across diverse neural rendering tasks, with a specific emphasis on neural radiosity. Experimental results demonstrate that our method reduces memory consumption to only one-fifth (or even less) of grid-based representations, while maintaining comparable rendering quality and lowering inference overhead.
End-to-end Acoustic-linguistic Emotion and Intent Recognition Enhanced by Semi-supervised Learning
Jul 10, 2025Emotion and intent recognition from speech is essential and has been widely investigated in human-computer interaction. The rapid development of social media platforms, chatbots, and other technologies has led to a large volume of speech data streaming from users. Nevertheless, annotating such data manually is expensive, making it challenging to train machine learning models for recognition purposes. To this end, we propose applying semi-supervised learning to incorporate a large scale of unlabelled data alongside a relatively smaller set of labelled data. We train end-to-end acoustic and linguistic models, each employing multi-task learning for emotion and intent recognition. Two semi-supervised learning approaches, including fix-match learning and full-match learning, are compared. The experimental results demonstrate that the semi-supervised learning approaches improve model performance in speech emotion and intent recognition from both acoustic and text data. The late fusion of the best models outperforms the acoustic and text baselines by joint recognition balance metrics of 12.3% and 10.4%, respectively.
Stroke-based Cyclic Amplifier: Image Super-Resolution at Arbitrary Ultra-Large Scales
Jun 12, 2025



Prior Arbitrary-Scale Image Super-Resolution (ASISR) methods often experience a significant performance decline when the upsampling factor exceeds the range covered by the training data, introducing substantial blurring. To address this issue, we propose a unified model, Stroke-based Cyclic Amplifier (SbCA), for ultra-large upsampling tasks. The key of SbCA is the stroke vector amplifier, which decomposes the image into a series of strokes represented as vector graphics for magnification. Then, the detail completion module also restores missing details, ensuring high-fidelity image reconstruction. Our cyclic strategy achieves ultra-large upsampling by iteratively refining details with this unified SbCA model, trained only once for all, while keeping sub-scales within the training range. Our approach effectively addresses the distribution drift issue and eliminates artifacts, noise and blurring, producing high-quality, high-resolution super-resolved images. Experimental validations on both synthetic and real-world datasets demonstrate that our approach significantly outperforms existing methods in ultra-large upsampling tasks (e.g. $\times100$), delivering visual quality far superior to state-of-the-art techniques.
Query Nearby: Offset-Adjusted Mask2Former enhances small-organ segmentation
Jun 06, 2025Medical segmentation plays an important role in clinical applications like radiation therapy and surgical guidance, but acquiring clinically acceptable results is difficult. In recent years, progress has been witnessed with the success of utilizing transformer-like models, such as combining the attention mechanism with CNN. In particular, transformer-based segmentation models can extract global information more effectively, compensating for the drawbacks of CNN modules that focus on local features. However, utilizing transformer architecture is not easy, because training transformer-based models can be resource-demanding. Moreover, due to the distinct characteristics in the medical field, especially when encountering mid-sized and small organs with compact regions, their results often seem unsatisfactory. For example, using ViT to segment medical images directly only gives a DSC of less than 50\%, which is far lower than the clinically acceptable score of 80\%. In this paper, we used Mask2Former with deformable attention to reduce computation and proposed offset adjustment strategies to encourage sampling points within the same organs during attention weights computation, thereby integrating compact foreground information better. Additionally, we utilized the 4th feature map in Mask2Former to provide a coarse location of organs, and employed an FCN-based auxiliary head to help train Mask2Former more quickly using Dice loss. We show that our model achieves SOTA (State-of-the-Art) performance on the HaNSeg and SegRap2023 datasets, especially on mid-sized and small organs.Our code is available at link https://github.com/earis/Offsetadjustment\_Background-location\_Decoder\_Mask2former.
NAT: Neural Acoustic Transfer for Interactive Scenes in Real Time
Jun 06, 2025



Previous acoustic transfer methods rely on extensive precomputation and storage of data to enable real-time interaction and auditory feedback. However, these methods struggle with complex scenes, especially when dynamic changes in object position, material, and size significantly alter sound effects. These continuous variations lead to fluctuating acoustic transfer distributions, making it challenging to represent with basic data structures and render efficiently in real time. To address this challenge, we present Neural Acoustic Transfer, a novel approach that utilizes an implicit neural representation to encode precomputed acoustic transfer and its variations, allowing for real-time prediction of sound fields under varying conditions. To efficiently generate the training data required for the neural acoustic field, we developed a fast Monte-Carlo-based boundary element method (BEM) approximation for general scenarios with smooth Neumann conditions. Additionally, we implemented a GPU-accelerated version of standard BEM for scenarios requiring higher precision. These methods provide the necessary training data, enabling our neural network to accurately model the sound radiation space. We demonstrate our method's numerical accuracy and runtime efficiency (within several milliseconds for 30s audio) through comprehensive validation and comparisons in diverse acoustic transfer scenarios. Our approach allows for efficient and accurate modeling of sound behavior in dynamically changing environments, which can benefit a wide range of interactive applications such as virtual reality, augmented reality, and advanced audio production.
CoTSRF: Utilize Chain of Thought as Stealthy and Robust Fingerprint of Large Language Models
May 22, 2025
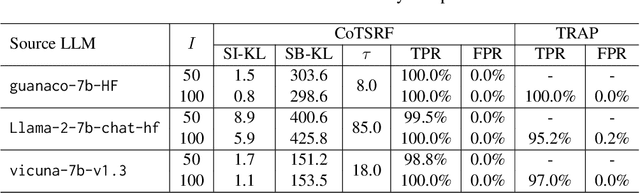
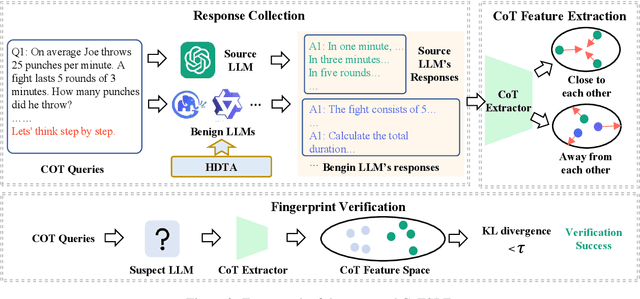
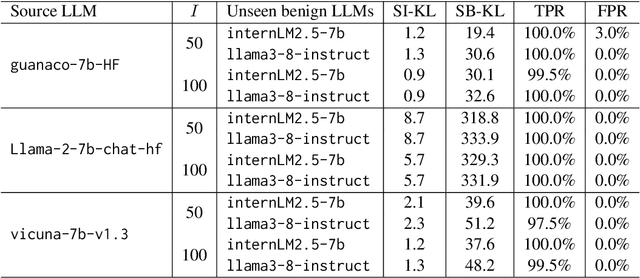
Despite providing superior performance, open-source large language models (LLMs) are vulnerable to abusive usage. To address this issue, recent works propose LLM fingerprinting methods to identify the specific source LLMs behind suspect applications. However, these methods fail to provide stealthy and robust fingerprint verification. In this paper, we propose a novel LLM fingerprinting scheme, namely CoTSRF, which utilizes the Chain of Thought (CoT) as the fingerprint of an LLM. CoTSRF first collects the responses from the source LLM by querying it with crafted CoT queries. Then, it applies contrastive learning to train a CoT extractor that extracts the CoT feature (i.e., fingerprint) from the responses. Finally, CoTSRF conducts fingerprint verification by comparing the Kullback-Leibler divergence between the CoT features of the source and suspect LLMs against an empirical threshold. Various experiments have been conducted to demonstrate the advantage of our proposed CoTSRF for fingerprinting LLMs, particularly in stealthy and robust fingerprint verification.
Benign Samples Matter! Fine-tuning On Outlier Benign Samples Severely Breaks Safety
May 11, 2025Recent studies have uncovered a troubling vulnerability in the fine-tuning stage of large language models (LLMs): even fine-tuning on entirely benign datasets can lead to a significant increase in the harmfulness of LLM outputs. Building on this finding, our red teaming study takes this threat one step further by developing a more effective attack. Specifically, we analyze and identify samples within benign datasets that contribute most to safety degradation, then fine-tune LLMs exclusively on these samples. We approach this problem from an outlier detection perspective and propose Self-Inf-N, to detect and extract outliers for fine-tuning. Our findings reveal that fine-tuning LLMs on 100 outlier samples selected by Self-Inf-N in the benign datasets severely compromises LLM safety alignment. Extensive experiments across seven mainstream LLMs demonstrate that our attack exhibits high transferability across different architectures and remains effective in practical scenarios. Alarmingly, our results indicate that most existing mitigation strategies fail to defend against this attack, underscoring the urgent need for more robust alignment safeguards. Codes are available at https://github.com/GuanZihan/Benign-Samples-Matter.
BalancEdit: Dynamically Balancing the Generality-Locality Trade-off in Multi-modal Model Editing
May 02, 2025Large multi-modal models inevitably decay over time as facts change and previously learned information becomes outdated. Traditional approaches such as fine-tuning are often impractical for updating these models due to their size and complexity. Instead, direct knowledge editing within the models presents a more viable solution. Current model editing techniques, however, typically overlook the unique influence ranges of different facts, leading to compromised model performance in terms of both generality and locality. To address this issue, we introduce the concept of the generality-locality trade-off in multi-modal model editing. We develop a new model editing dataset named OKEDIT, specifically designed to effectively evaluate this trade-off. Building on this foundation, we propose BalancEdit, a novel method for balanced model editing that dynamically achieves an optimal balance between generality and locality. BalancEdit utilizes a unique mechanism that generates both positive and negative samples for each fact to accurately determine its influence scope and incorporates these insights into the model's latent space using a discrete, localized codebook of edits, without modifying the underlying model weights. To our knowledge, this is the first approach explicitly addressing the generality-locality trade-off in multi-modal model editing. Our comprehensive results confirm the effectiveness of BalancEdit, demonstrating minimal trade-offs while maintaining robust editing capabilities. Our code and dataset will be available.
Adversarial Shallow Watermarking
Apr 28, 2025



Recent advances in digital watermarking make use of deep neural networks for message embedding and extraction. They typically follow the ``encoder-noise layer-decoder''-based architecture. By deliberately establishing a differentiable noise layer to simulate the distortion of the watermarked signal, they jointly train the deep encoder and decoder to fit the noise layer to guarantee robustness. As a result, they are usually weak against unknown distortions that are not used in their training pipeline. In this paper, we propose a novel watermarking framework to resist unknown distortions, namely Adversarial Shallow Watermarking (ASW). ASW utilizes only a shallow decoder that is randomly parameterized and designed to be insensitive to distortions for watermarking extraction. During the watermark embedding, ASW freezes the shallow decoder and adversarially optimizes a host image until its updated version (i.e., the watermarked image) stably triggers the shallow decoder to output the watermark message. During the watermark extraction, it accurately recovers the message from the watermarked image by leveraging the insensitive nature of the shallow decoder against arbitrary distortions. Our ASW is training-free, encoder-free, and noise layer-free. Experiments indicate that the watermarked images created by ASW have strong robustness against various unknown distortions. Compared to the existing ``encoder-noise layer-decoder'' approaches, ASW achieves comparable results on known distortions and better robustness on unknown distortions.