 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
Feb 26, 2026Uncertainty quantification is central to safe and efficient deployments of deep learning models, yet many computationally practical methods lack lacking rigorous theoretical motivation. Random network distillation (RND) is a lightweight technique that measures novelty via prediction errors against a fixed random target. While empirically effective, it has remained unclear what uncertainties RND measures and how its estimates relate to other approaches, e.g. Bayesian inference or deep ensembles. This paper establishes these missing theoretical connections by analyzing RND within the neural tangent kernel framework in the limit of infinite network width. Our analysis reveals two central findings in this limit: (1) The uncertainty signal from RND -- its squared self-predictive error -- is equivalent to the predictive variance of a deep ensemble. (2) By constructing a specific RND target function, we show that the RND error distribution can be made to mirror the centered posterior predictive distribution of Bayesian inference with wide neural networks. Based on this equivalence, we moreover devise a posterior sampling algorithm that generates i.i.d. samples from an exact Bayesian posterior predictive distribution using this modified \textit{Bayesian RND} model. Collectively, our findings provide a unified theoretical perspective that places RND within the principled frameworks of deep ensembles and Bayesian inference, and offer new avenues for efficient yet theoretically grounded uncertainty quantification methods.
Sparse Masked Attention Policies for Reliable Generalization
Feb 23, 2026In reinforcement learning, abstraction methods that remove unnecessary information from the observation are commonly used to learn policies which generalize better to unseen tasks. However, these methods often overlook a crucial weakness: the function which extracts the reduced-information representation has unknown generalization ability in unseen observations. In this paper, we address this problem by presenting an information removal method which more reliably generalizes to new states. We accomplish this by using a learned masking function which operates on, and is integrated with, the attention weights within an attention-based policy network. We demonstrate that our method significantly improves policy generalization to unseen tasks in the Procgen benchmark compared to standard PPO and masking approaches.
Parallelizing Tree Search with Twice Sequential Monte Carlo
Nov 18, 2025Model-based reinforcement learning (RL) methods that leverage search are responsible for many milestone breakthroughs in RL. Sequential Monte Carlo (SMC) recently emerged as an alternative to the Monte Carlo Tree Search (MCTS) algorithm which drove these breakthroughs. SMC is easier to parallelize and more suitable to GPU acceleration. However, it also suffers from large variance and path degeneracy which prevent it from scaling well with increased search depth, i.e., increased sequential compute. To address these problems, we introduce Twice Sequential Monte Carlo Tree Search (TSMCTS). Across discrete and continuous environments TSMCTS outperforms the SMC baseline as well as a popular modern version of MCTS. Through variance reduction and mitigation of path degeneracy, TSMCTS scales favorably with sequential compute while retaining the properties that make SMC natural to parallelize.
Improving Robustness of AlphaZero Algorithms to Test-Time Environment Changes
Sep 04, 2025The AlphaZero framework provides a standard way of combining Monte Carlo planning with prior knowledge provided by a previously trained policy-value neural network. AlphaZero usually assumes that the environment on which the neural network was trained will not change at test time, which constrains its applicability. In this paper, we analyze the problem of deploying AlphaZero agents in potentially changed test environments and demonstrate how the combination of simple modifications to the standard framework can significantly boost performance, even in settings with a low planning budget available. The code is publicly available on GitHub.
Modular Recurrence in Contextual MDPs for Universal Morphology Control
Jun 10, 2025A universal controller for any robot morphology would greatly improve computational and data efficiency. By utilizing contextual information about the properties of individual robots and exploiting their modular structure in the architecture of deep reinforcement learning agents, steps have been made towards multi-robot control. Generalization to new, unseen robots, however, remains a challenge. In this paper we hypothesize that the relevant contextual information is partially observable, but that it can be inferred through interactions for better generalization to contexts that are not seen during training. To this extent, we implement a modular recurrent architecture and evaluate its generalization performance on a large set of MuJoCo robots. The results show a substantial improved performance on robots with unseen dynamics, kinematics, and topologies, in four different environments.
Universal Value-Function Uncertainties
May 27, 2025


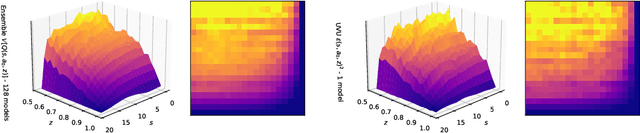
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
How Ensembles of Distilled Policies Improve Generalisation in Reinforcement Learning
May 22, 2025



In the zero-shot policy transfer setting in reinforcement learning, the goal is to train an agent on a fixed set of training environments so that it can generalise to similar, but unseen, testing environments. Previous work has shown that policy distillation after training can sometimes produce a policy that outperforms the original in the testing environments. However, it is not yet entirely clear why that is, or what data should be used to distil the policy. In this paper, we prove, under certain assumptions, a generalisation bound for policy distillation after training. The theory provides two practical insights: for improved generalisation, you should 1) train an ensemble of distilled policies, and 2) distil it on as much data from the training environments as possible. We empirically verify that these insights hold in more general settings, when the assumptions required for the theory no longer hold. Finally, we demonstrate that an ensemble of policies distilled on a diverse dataset can generalise significantly better than the original agent.
Contextual Similarity Distillation: Ensemble Uncertainties with a Single Model
Mar 14, 2025



Uncertainty quantification is a critical aspect of reinforcement learning and deep learning, with numerous applications ranging from efficient exploration and stable offline reinforcement learning to outlier detection in medical diagnostics. The scale of modern neural networks, however, complicates the use of many theoretically well-motivated approaches such as full Bayesian inference. Approximate methods like deep ensembles can provide reliable uncertainty estimates but still remain computationally expensive. In this work, we propose contextual similarity distillation, a novel approach that explicitly estimates the variance of an ensemble of deep neural networks with a single model, without ever learning or evaluating such an ensemble in the first place. Our method builds on the predictable learning dynamics of wide neural networks, governed by the neural tangent kernel, to derive an efficient approximation of the predictive variance of an infinite ensemble. Specifically, we reinterpret the computation of ensemble variance as a supervised regression problem with kernel similarities as regression targets. The resulting model can estimate predictive variance at inference time with a single forward pass, and can make use of unlabeled target-domain data or data augmentations to refine its uncertainty estimates. We empirically validate our method across a variety of out-of-distribution detection benchmarks and sparse-reward reinforcement learning environments. We find that our single-model method performs competitively and sometimes superior to ensemble-based baselines and serves as a reliable signal for efficient exploration. These results, we believe, position contextual similarity distillation as a principled and scalable alternative for uncertainty quantification in reinforcement learning and general deep learning.
Training on more Reachable Tasks for Generalisation in Reinforcement Learning
Oct 04, 2024



In multi-task reinforcement learning, agents train on a fixed set of tasks and have to generalise to new ones. Recent work has shown that increased exploration improves this generalisation, but it remains unclear why exactly that is. In this paper, we introduce the concept of reachability in multi-task reinforcement learning and show that an initial exploration phase increases the number of reachable tasks the agent is trained on. This, and not the increased exploration, is responsible for the improved generalisation, even to unreachable tasks. Inspired by this, we propose a novel method Explore-Go that implements such an exploration phase at the beginning of each episode. Explore-Go only modifies the way experience is collected and can be used with most existing on-policy or off-policy reinforcement learning algorithms. We demonstrate the effectiveness of our method when combined with some popular algorithms and show an increase in generalisation performance across several environments.
Explore-Go: Leveraging Exploration for Generalisation in Deep Reinforcement Learning
Jun 12, 2024



One of the remaining challenges in reinforcement learning is to develop agents that can generalise to novel scenarios they might encounter once deployed. This challenge is often framed in a multi-task setting where agents train on a fixed set of tasks and have to generalise to new tasks. Recent work has shown that in this setting increased exploration during training can be leveraged to increase the generalisation performance of the agent. This makes sense when the states encountered during testing can actually be explored during training. In this paper, we provide intuition why exploration can also benefit generalisation to states that cannot be explicitly encountered during training. Additionally, we propose a novel method Explore-Go that exploits this intuition by increasing the number of states on which the agent trains. Explore-Go effectively increases the starting state distribution of the agent and as a result can be used in conjunction with most existing on-policy or off-policy reinforcement learning algorithms. We show empirically that our method can increase generalisation performance in an illustrative environment and on the Procgen benchmark.