 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenUS: A Fully Open-Source Foundation Model for Ultrasound Image Analysis via Self-Adaptive Masked Contrastive Learning
Nov 14, 2025Ultrasound (US) is one of the most widely used medical imaging modalities, thanks to its low cost, portability, real-time feedback, and absence of ionizing radiation. However, US image interpretation remains highly operator-dependent and varies significantly across anatomical regions, acquisition protocols, and device types. These variations, along with unique challenges such as speckle, low contrast, and limited standardized annotations, hinder the development of generalizable, label-efficient ultrasound AI models. In this paper, we propose OpenUS, the first reproducible, open-source ultrasound foundation model built on a large collection of public data. OpenUS employs a vision Mamba backbone, capturing both local and global long-range dependencies across the image. To extract rich features during pre-training, we introduce a novel self-adaptive masking framework that combines contrastive learning with masked image modeling. This strategy integrates the teacher's attention map with student reconstruction loss, adaptively refining clinically-relevant masking to enhance pre-training effectiveness. OpenUS also applies a dynamic learning schedule to progressively adjust the difficulty of the pre-training process. To develop the foundation model, we compile the largest to-date public ultrasound dataset comprising over 308K images from 42 publicly available datasets, covering diverse anatomical regions, institutions, imaging devices, and disease types. Our pre-trained OpenUS model can be easily adapted to specific downstream tasks by serving as a backbone for label-efficient fine-tuning. Code is available at https://github.com/XZheng0427/OpenUS.
Uncertainty-quantified Rollout Policy Adaptation for Unlabelled Cross-domain Temporal Grounding
Aug 08, 2025Video Temporal Grounding (TG) aims to temporally locate video segments matching a natural language description (a query) in a long video. While Vision-Language Models (VLMs) are effective at holistic semantic matching, they often struggle with fine-grained temporal localisation. Recently, Group Relative Policy Optimisation (GRPO) reformulates the inference process as a reinforcement learning task, enabling fine-grained grounding and achieving strong in-domain performance. However, GRPO relies on labelled data, making it unsuitable in unlabelled domains. Moreover, because videos are large and expensive to store and process, performing full-scale adaptation introduces prohibitive latency and computational overhead, making it impractical for real-time deployment. To overcome both problems, we introduce a Data-Efficient Unlabelled Cross-domain Temporal Grounding method, from which a model is first trained on a labelled source domain, then adapted to a target domain using only a small number of unlabelled videos from the target domain. This approach eliminates the need for target annotation and keeps both computational and storage overhead low enough to run in real time. Specifically, we introduce. Uncertainty-quantified Rollout Policy Adaptation (URPA) for cross-domain knowledge transfer in learning video temporal grounding without target labels. URPA generates multiple candidate predictions using GRPO rollouts, averages them to form a pseudo label, and estimates confidence from the variance across these rollouts. This confidence then weights the training rewards, guiding the model to focus on reliable supervision. Experiments on three datasets across six cross-domain settings show that URPA generalises well using only a few unlabelled target videos. Codes will be released once published.
ViSMaP: Unsupervised Hour-long Video Summarisation by Meta-Prompting
Apr 22, 2025We introduce ViSMap: Unsupervised Video Summarisation by Meta Prompting, a system to summarise hour long videos with no-supervision. Most existing video understanding models work well on short videos of pre-segmented events, yet they struggle to summarise longer videos where relevant events are sparsely distributed and not pre-segmented. Moreover, long-form video understanding often relies on supervised hierarchical training that needs extensive annotations which are costly, slow and prone to inconsistency. With ViSMaP we bridge the gap between short videos (where annotated data is plentiful) and long ones (where it's not). We rely on LLMs to create optimised pseudo-summaries of long videos using segment descriptions from short ones. These pseudo-summaries are used as training data for a model that generates long-form video summaries, bypassing the need for expensive annotations of long videos. Specifically, we adopt a meta-prompting strategy to iteratively generate and refine creating pseudo-summaries of long videos. The strategy leverages short clip descriptions obtained from a supervised short video model to guide the summary. Each iteration uses three LLMs working in sequence: one to generate the pseudo-summary from clip descriptions, another to evaluate it, and a third to optimise the prompt of the generator. This iteration is necessary because the quality of the pseudo-summaries is highly dependent on the generator prompt, and varies widely among videos. We evaluate our summaries extensively on multiple datasets; our results show that ViSMaP achieves performance comparable to fully supervised state-of-the-art models while generalising across domains without sacrificing performance. Code will be released upon publication.
ViMo: A Generative Visual GUI World Model for App Agent
Apr 15, 2025App agents, which autonomously operate mobile Apps through Graphical User Interfaces (GUIs), have gained significant interest in real-world applications. Yet, they often struggle with long-horizon planning, failing to find the optimal actions for complex tasks with longer steps. To address this, world models are used to predict the next GUI observation based on user actions, enabling more effective agent planning. However, existing world models primarily focus on generating only textual descriptions, lacking essential visual details. To fill this gap, we propose ViMo, the first visual world model designed to generate future App observations as images. For the challenge of generating text in image patches, where even minor pixel errors can distort readability, we decompose GUI generation into graphic and text content generation. We propose a novel data representation, the Symbolic Text Representation~(STR) to overlay text content with symbolic placeholders while preserving graphics. With this design, ViMo employs a STR Predictor to predict future GUIs' graphics and a GUI-text Predictor for generating the corresponding text. Moreover, we deploy ViMo to enhance agent-focused tasks by predicting the outcome of different action options. Experiments show ViMo's ability to generate visually plausible and functionally effective GUIs that enable App agents to make more informed decisions.
Multi-modal Multi-platform Person Re-Identification: Benchmark and Method
Mar 21, 2025



Conventional person re-identification (ReID) research is often limited to single-modality sensor data from static cameras, which fails to address the complexities of real-world scenarios where multi-modal signals are increasingly prevalent. For instance, consider an urban ReID system integrating stationary RGB cameras, nighttime infrared sensors, and UAVs equipped with dynamic tracking capabilities. Such systems face significant challenges due to variations in camera perspectives, lighting conditions, and sensor modalities, hindering effective person ReID. To address these challenges, we introduce the MP-ReID benchmark, a novel dataset designed specifically for multi-modality and multi-platform ReID. This benchmark uniquely compiles data from 1,930 identities across diverse modalities, including RGB, infrared, and thermal imaging, captured by both UAVs and ground-based cameras in indoor and outdoor environments. Building on this benchmark, we introduce Uni-Prompt ReID, a framework with specific-designed prompts, tailored for cross-modality and cross-platform scenarios. Our method consistently outperforms state-of-the-art approaches, establishing a robust foundation for future research in complex and dynamic ReID environments. Our dataset are available at:https://mp-reid.github.io/.
Temporal Score Analysis for Understanding and Correcting Diffusion Artifacts
Mar 20, 2025



Visual artifacts remain a persistent challenge in diffusion models, even with training on massive datasets. Current solutions primarily rely on supervised detectors, yet lack understanding of why these artifacts occur in the first place. In our analysis, we identify three distinct phases in the diffusion generative process: Profiling, Mutation, and Refinement. Artifacts typically emerge during the Mutation phase, where certain regions exhibit anomalous score dynamics over time, causing abrupt disruptions in the normal evolution pattern. This temporal nature explains why existing methods focusing only on spatial uncertainty of the final output fail at effective artifact localization. Based on these insights, we propose ASCED (Abnormal Score Correction for Enhancing Diffusion), that detects artifacts by monitoring abnormal score dynamics during the diffusion process, with a trajectory-aware on-the-fly mitigation strategy that appropriate generation of noise in the detected areas. Unlike most existing methods that apply post hoc corrections, \eg, by applying a noising-denoising scheme after generation, our mitigation strategy operates seamlessly within the existing diffusion process. Extensive experiments demonstrate that our proposed approach effectively reduces artifacts across diverse domains, matching or surpassing existing supervised methods without additional training.
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025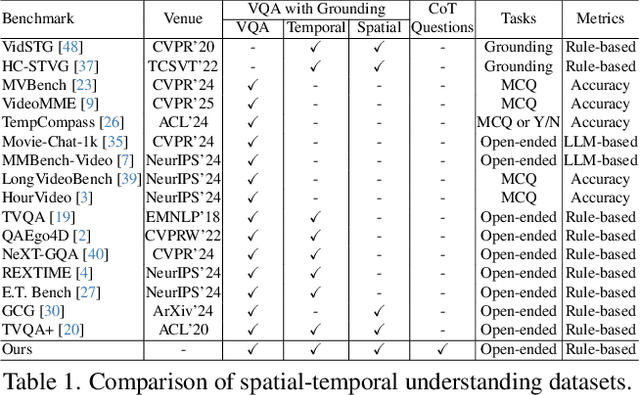
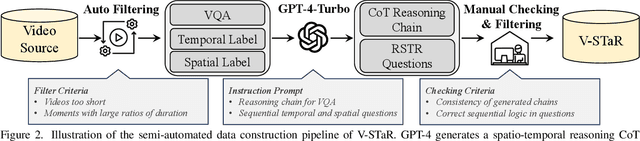

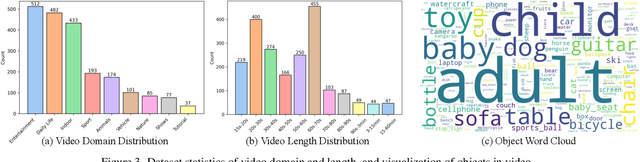
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
AIM-Fair: Advancing Algorithmic Fairness via Selectively Fine-Tuning Biased Models with Contextual Synthetic Data
Mar 07, 2025



Recent advances in generative models have sparked research on improving model fairness with AI-generated data. However, existing methods often face limitations in the diversity and quality of synthetic data, leading to compromised fairness and overall model accuracy. Moreover, many approaches rely on the availability of demographic group labels, which are often costly to annotate. This paper proposes AIM-Fair, aiming to overcome these limitations and harness the potential of cutting-edge generative models in promoting algorithmic fairness. We investigate a fine-tuning paradigm starting from a biased model initially trained on real-world data without demographic annotations. This model is then fine-tuned using unbiased synthetic data generated by a state-of-the-art diffusion model to improve its fairness. Two key challenges are identified in this fine-tuning paradigm, 1) the low quality of synthetic data, which can still happen even with advanced generative models, and 2) the domain and bias gap between real and synthetic data. To address the limitation of synthetic data quality, we propose Contextual Synthetic Data Generation (CSDG) to generate data using a text-to-image diffusion model (T2I) with prompts generated by a context-aware LLM, ensuring both data diversity and control of bias in synthetic data. To resolve domain and bias shifts, we introduce a novel selective fine-tuning scheme in which only model parameters more sensitive to bias and less sensitive to domain shift are updated. Experiments on CelebA and UTKFace datasets show that our AIM-Fair improves model fairness while maintaining utility, outperforming both fully and partially fine-tuned approaches to model fairness.
XFMamba: Cross-Fusion Mamba for Multi-View Medical Image Classification
Mar 04, 2025Compared to single view medical image classification, using multiple views can significantly enhance predictive accuracy as it can account for the complementarity of each view while leveraging correlations between views. Existing multi-view approaches typically employ separate convolutional or transformer branches combined with simplistic feature fusion strategies. However, these approaches inadvertently disregard essential cross-view correlations, leading to suboptimal classification performance, and suffer from challenges with limited receptive field (CNNs) or quadratic computational complexity (transformers). Inspired by state space sequence models, we propose XFMamba, a pure Mamba-based cross-fusion architecture to address the challenge of multi-view medical image classification. XFMamba introduces a novel two-stage fusion strategy, facilitating the learning of single-view features and their cross-view disparity. This mechanism captures spatially long-range dependencies in each view while enhancing seamless information transfer between views. Results on three public datasets, MURA, CheXpert and DDSM, illustrate the effectiveness of our approach across diverse multi-view medical image classification tasks, showing that it outperforms existing convolution-based and transformer-based multi-view methods. Code is available at https://github.com/XZheng0427/XFMamba.
CoS: Chain-of-Shot Prompting for Long Video Understanding
Feb 10, 2025



Multi-modal Large Language Models (MLLMs) struggle with long videos due to the need for excessive visual tokens. These tokens exceed massively the context length of MLLMs, resulting in filled by redundant task-irrelevant shots. How to select shots is an unsolved critical problem: sparse sampling risks missing key details, while exhaustive sampling overwhelms the model with irrelevant content, leading to video misunderstanding. To solve this problem, we propose Chain-of-Shot prompting (CoS). The key idea is to frame shot selection as test-time visual prompt optimisation, choosing shots adaptive to video understanding semantic task by optimising shots-task alignment. CoS has two key parts: (1) a binary video summary mechanism that performs pseudo temporal grounding, discovering a binary coding to identify task-relevant shots, and (2) a video co-reasoning module that deploys the binary coding to pair (learning to align) task-relevant positive shots with irrelevant negative shots. It embeds the optimised shot selections into the original video, facilitating a focus on relevant context to optimize long video understanding. Experiments across three baselines and five datasets demonstrate the effectiveness and adaptability of CoS. Code given in https://lwpyh.github.io/CoS.