 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanelNet: Understanding 360 Indoor Environment via Panel Representation
May 16, 2023Indoor 360 panoramas have two essential properties. (1) The panoramas are continuous and seamless in the horizontal direction. (2) Gravity plays an important role in indoor environment design. By leveraging these properties, we present PanelNet, a framework that understands indoor environments using a novel panel representation of 360 images. We represent an equirectangular projection (ERP) as consecutive vertical panels with corresponding 3D panel geometry. To reduce the negative impact of panoramic distortion, we incorporate a panel geometry embedding network that encodes both the local and global geometric features of a panel. To capture the geometric context in room design, we introduce Local2Global Transformer, which aggregates local information within a panel and panel-wise global context. It greatly improves the model performance with low training overhead. Our method outperforms existing methods on indoor 360 depth estimation and shows competitive results against state-of-the-art approaches on the task of indoor layout estimation and semantic segmentation.
A Tiny Machine Learning Model for Point Cloud Object Classification
Mar 20, 2023



The design of a tiny machine learning model, which can be deployed in mobile and edge devices, for point cloud object classification is investigated in this work. To achieve this objective, we replace the multi-scale representation of a point cloud object with a single-scale representation for complexity reduction, and exploit rich 3D geometric information of a point cloud object for performance improvement. The proposed solution is named Green-PointHop due to its low computational complexity. We evaluate the performance of Green-PointHop on ModelNet40 and ScanObjectNN two datasets. Green-PointHop has a model size of 64K parameters. It demands 2.3M floating-point operations (FLOPs) to classify a ModelNet40 object of 1024 down-sampled points. Its classification performance gaps against the state-of-the-art DGCNN method are 3% and 7% for ModelNet40 and ScanObjectNN, respectively. On the other hand, the model size and inference complexity of DGCNN are 42X and 1203X of those of Green-PointHop, respectively.
PointFlowHop: Green and Interpretable Scene Flow Estimation from Consecutive Point Clouds
Feb 27, 2023



An efficient 3D scene flow estimation method called PointFlowHop is proposed in this work. PointFlowHop takes two consecutive point clouds and determines the 3D flow vectors for every point in the first point cloud. PointFlowHop decomposes the scene flow estimation task into a set of subtasks, including ego-motion compensation, object association and object-wise motion estimation. It follows the green learning (GL) pipeline and adopts the feedforward data processing path. As a result, its underlying mechanism is more transparent than deep-learning (DL) solutions based on end-to-end optimization of network parameters. We conduct experiments on the stereoKITTI and the Argoverse LiDAR point cloud datasets and demonstrate that PointFlowHop outperforms deep-learning methods with a small model size and less training time. Furthermore, we compare the Floating Point Operations (FLOPs) required by PointFlowHop and other learning-based methods in inference, and show its big savings in computational complexity.
S3I-PointHop: SO-Invariant PointHop for 3D Point Cloud Classification
Feb 22, 2023Many point cloud classification methods are developed under the assumption that all point clouds in the dataset are well aligned with the canonical axes so that the 3D Cartesian point coordinates can be employed to learn features. When input point clouds are not aligned, the classification performance drops significantly. In this work, we focus on a mathematically transparent point cloud classification method called PointHop, analyze its reason for failure due to pose variations, and solve the problem by replacing its pose dependent modules with rotation invariant counterparts. The proposed method is named SO(3)-Invariant PointHop (or S3I-PointHop in short). We also significantly simplify the PointHop pipeline using only one single hop along with multiple spatial aggregation techniques. The idea of exploiting more spatial information is novel. Experiments on the ModelNet40 dataset demonstrate the superiority of S3I-PointHop over traditional PointHop-like methods.
gpcgc: a green point cloud geometry coding method
Feb 13, 2023



A low-complexity point cloud compression method called the Green Point Cloud Geometry Codec (GPCGC), is proposed to encode the 3D spatial coordinates of static point clouds efficiently. GPCGC consists of two modules. In the first module, point coordinates of input point clouds are hierarchically organized into an octree structure. Points at each leaf node are projected along one of three axes to yield image maps. In the second module, the occupancy map is clustered into 9 modes while the depth map is coded by a low-complexity high-efficiency image codec, called the green image codec (GIC). GIC is a multi-resolution codec based on vector quantization (VQ). Its complexity is significantly lower than HEVC-Intra. Furthermore, the rate-distortion optimization (RDO) technique is used to select the optimal coding parameters. GPCGC is a progressive codec, and it offers a coding performance competitive with MPEG's V-PCC and G-PCC standards at significantly lower complexity.
GPA-Net:No-Reference Point Cloud Quality Assessment with Multi-task Graph Convolutional Network
Nov 17, 2022



With the rapid development of 3D vision, point cloud has become an increasingly popular 3D visual media content. Due to the irregular structure, point cloud has posed novel challenges to the related research, such as compression, transmission, rendering and quality assessment. In these latest researches, point cloud quality assessment (PCQA) has attracted wide attention due to its significant role in guiding practical applications, especially in many cases where the reference point cloud is unavailable. However, current no-reference metrics which based on prevalent deep neural network have apparent disadvantages. For example, to adapt to the irregular structure of point cloud, they require preprocessing such as voxelization and projection that introduce extra distortions, and the applied grid-kernel networks, such as Convolutional Neural Networks, fail to extract effective distortion-related features. Besides, they rarely consider the various distortion patterns and the philosophy that PCQA should exhibit shifting, scaling, and rotational invariance. In this paper, we propose a novel no-reference PCQA metric named the Graph convolutional PCQA network (GPA-Net). To extract effective features for PCQA, we propose a new graph convolution kernel, i.e., GPAConv, which attentively captures the perturbation of structure and texture. Then, we propose the multi-task framework consisting of one main task (quality regression) and two auxiliary tasks (distortion type and degree predictions). Finally, we propose a coordinate normalization module to stabilize the results of GPAConv under shift, scale and rotation transformations. Experimental results on two independent databases show that GPA-Net achieves the best performance compared to the state-of-the-art no-reference PCQA metrics, even better than some full-reference metrics in some cases.
Changes from Classical Statistics to Modern Statistics and Data Science
Oct 30, 2022A coordinate system is a foundation for every quantitative science, engineering, and medicine. Classical physics and statistics are based on the Cartesian coordinate system. The classical probability and hypothesis testing theory can only be applied to Euclidean data. However, modern data in the real world are from natural language processing, mathematical formulas, social networks, transportation and sensor networks, computer visions, automations, and biomedical measurements. The Euclidean assumption is not appropriate for non Euclidean data. This perspective addresses the urgent need to overcome those fundamental limitations and encourages extensions of classical probability theory and hypothesis testing , diffusion models and stochastic differential equations from Euclidean space to non Euclidean space. Artificial intelligence such as natural language processing, computer vision, graphical neural networks, manifold regression and inference theory, manifold learning, graph neural networks, compositional diffusion models for automatically compositional generations of concepts and demystifying machine learning systems, has been rapidly developed. Differential manifold theory is the mathematic foundations of deep learning and data science as well. We urgently need to shift the paradigm for data analysis from the classical Euclidean data analysis to both Euclidean and non Euclidean data analysis and develop more and more innovative methods for describing, estimating and inferring non Euclidean geometries of modern real datasets. A general framework for integrated analysis of both Euclidean and non Euclidean data, composite AI, decision intelligence and edge AI provide powerful innovative ideas and strategies for fundamentally advancing AI. We are expected to marry statistics with AI, develop a unified theory of modern statistics and drive next generation of AI and data science.
Robust Human Matting via Semantic Guidance
Oct 11, 2022
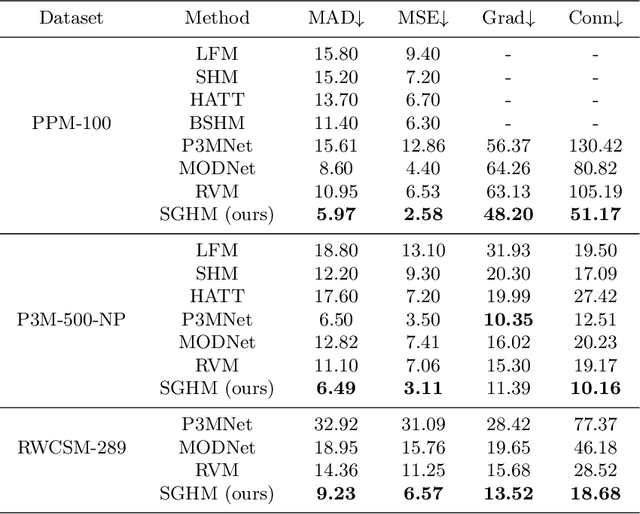
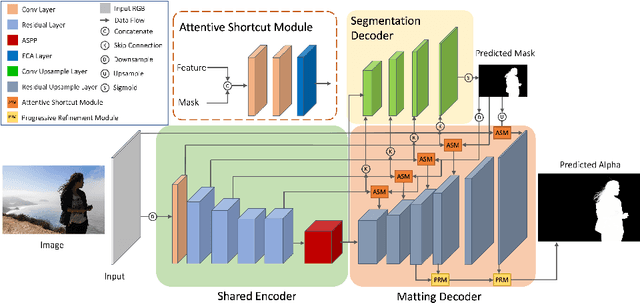
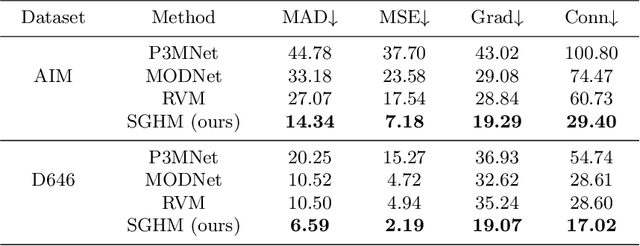
Automatic human matting is highly desired for many real applications. We investigate recent human matting methods and show that common bad cases happen when semantic human segmentation fails. This indicates that semantic understanding is crucial for robust human matting. From this, we develop a fast yet accurate human matting framework, named Semantic Guided Human Matting (SGHM). It builds on a semantic human segmentation network and introduces a light-weight matting module with only marginal computational cost. Unlike previous works, our framework is data efficient, which requires a small amount of matting ground-truth to learn to estimate high quality object mattes. Our experiments show that trained with merely 200 matting images, our method can generalize well to real-world datasets, and outperform recent methods on multiple benchmarks, while remaining efficient. Considering the unbearable labeling cost of matting data and widely available segmentation data, our method becomes a practical and effective solution for the task of human matting. Source code is available at https://github.com/cxgincsu/SemanticGuidedHumanMatting.
Point Cloud Quality Assessment using 3D Saliency Maps
Sep 30, 2022Point cloud quality assessment (PCQA) has become an appealing research field in recent days. Considering the importance of saliency detection in quality assessment, we propose an effective full-reference PCQA metric which makes the first attempt to utilize the saliency information to facilitate quality prediction, called point cloud quality assessment using 3D saliency maps (PQSM). Specifically, we first propose a projection-based point cloud saliency map generation method, in which depth information is introduced to better reflect the geometric characteristics of point clouds. Then, we construct point cloud local neighborhoods to derive three structural descriptors to indicate the geometry, color and saliency discrepancies. Finally, a saliency-based pooling strategy is proposed to generate the final quality score. Extensive experiments are performed on four independent PCQA databases. The results demonstrate that the proposed PQSM shows competitive performances compared to multiple state-of-the-art PCQA metrics.
Enhancing HDR Video Compression through CNN-based Effective Bit Depth Adaptation
Jul 18, 2022
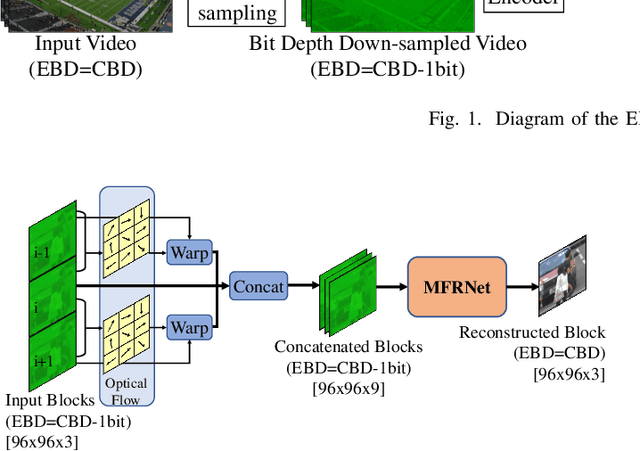

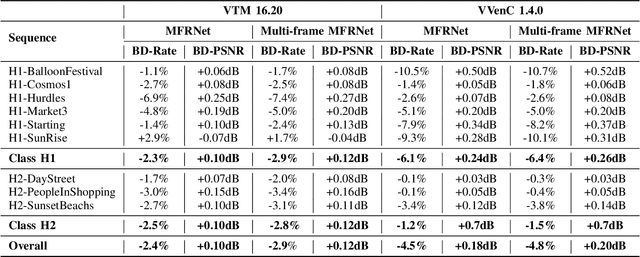
It is well known that high dynamic range (HDR) video can provide more immersive visual experiences compared to conventional standard dynamic range content. However, HDR content is typically more challenging to encode due to the increased detail associated with the wider dynamic range. In this paper, we improve HDR compression performance using the effective bit depth adaptation approach (EBDA). This method reduces the effective bit depth of the original video content before encoding and reconstructs the full bit depth using a CNN-based up-sampling method at the decoder. In this work, we modify the MFRNet network architecture to enable multiple frame processing, and the new network, multi-frame MFRNet, has been integrated into the EBDA framework using two Versatile Video Coding (VVC) host codecs: VTM 16.2 and the Fraunhofer Versatile Video Encoder (VVenC 1.4.0). The proposed approach was evaluated under the JVET HDR Common Test Conditions using the Random Access configuration. The results show coding gains over both the original VVC VTM 16.2 and VVenC 1.4.0 (w/o EBDA) on JVET HDR tested sequences, with average bitrate savings of 2.9% (over VTM) and 4.8% (against VVenC) based on the Bjontegaard Delta measurement. The source code of multi-frame MFRNet has been released at https://github.com/fan-aaron-zhang/MF-MFRNet.