 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent Escapes Saddle Points Efficiently
Feb 13, 2019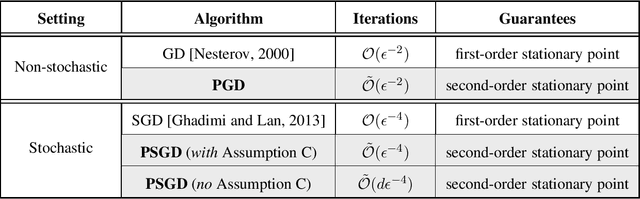
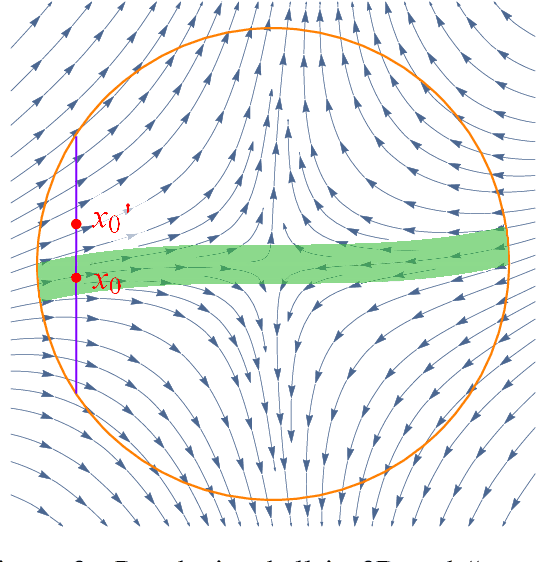
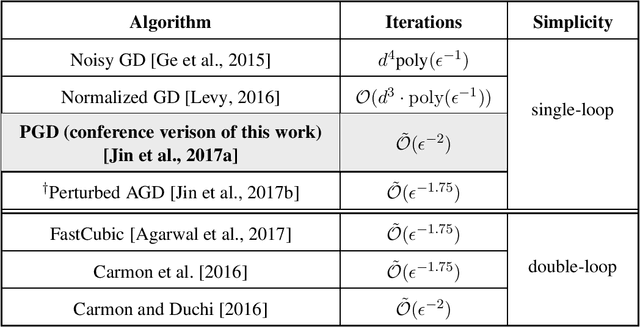
This paper considers the perturbed stochastic gradient descent algorithm and shows that it finds $\epsilon$-second order stationary points ($\left\|\nabla f(x)\right\|\leq \epsilon$ and $\nabla^2 f(x) \succeq -\sqrt{\epsilon} \mathbf{I}$) in $\tilde{O}(d/\epsilon^4)$ iterations, giving the first result that has linear dependence on dimension for this setting. For the special case, where stochastic gradients are Lipschitz, the dependence on dimension reduces to polylogarithmic. In addition to giving new results, this paper also presents a simplified proof strategy that gives a shorter and more elegant proof of previously known results (Jin et al. 2017) on perturbed gradient descent algorithm.
Maximum Likelihood Estimation for Learning Populations of Parameters
Feb 12, 2019
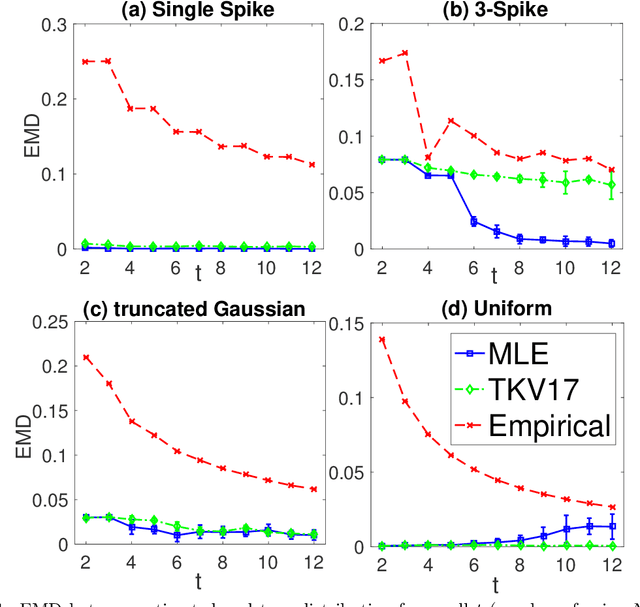
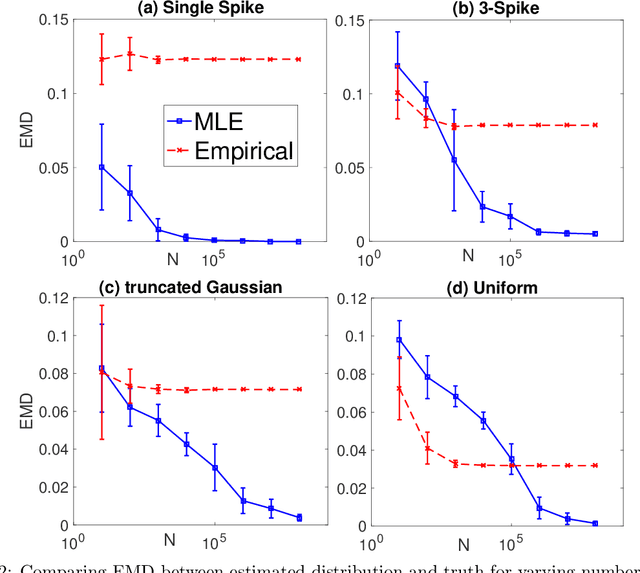
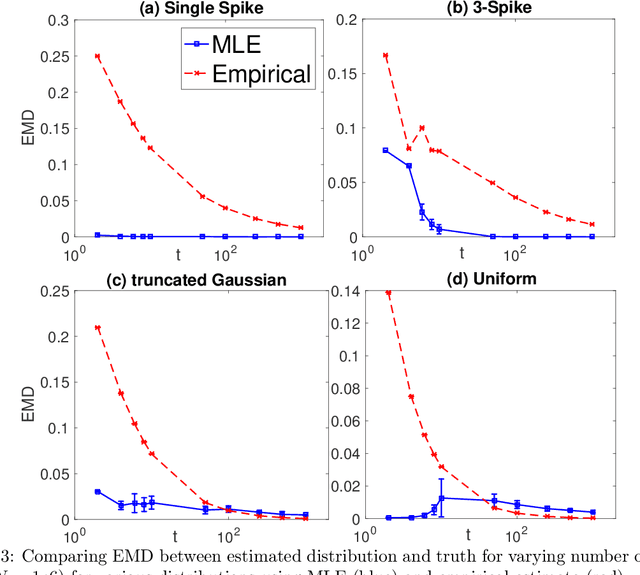
Consider a setting with $N$ independent individuals, each with an unknown parameter, $p_i \in [0, 1]$ drawn from some unknown distribution $P^\star$. After observing the outcomes of $t$ independent Bernoulli trials, i.e., $X_i \sim \text{Binomial}(t, p_i)$ per individual, our objective is to accurately estimate $P^\star$. This problem arises in numerous domains, including the social sciences, psychology, health-care, and biology, where the size of the population under study is usually large while the number of observations per individual is often limited. Our main result shows that, in the regime where $t \ll N$, the maximum likelihood estimator (MLE) is both statistically minimax optimal and efficiently computable. Precisely, for sufficiently large $N$, the MLE achieves the information theoretic optimal error bound of $\mathcal{O}(\frac{1}{t})$ for $t < c\log{N}$, with regards to the earth mover's distance (between the estimated and true distributions). More generally, in an exponentially large interval of $t$ beyond $c \log{N}$, the MLE achieves the minimax error bound of $\mathcal{O}(\frac{1}{\sqrt{t\log N}})$. In contrast, regardless of how large $N$ is, the naive "plug-in" estimator for this problem only achieves the sub-optimal error of $\Theta(\frac{1}{\sqrt{t}})$.
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
Feb 11, 2019In this note, we derive concentration inequalities for random vectors with subGaussian norm (a generalization of both subGaussian random vectors and norm bounded random vectors), which are tight up to logarithmic factors.
A Smoother Way to Train Structured Prediction Models
Feb 08, 2019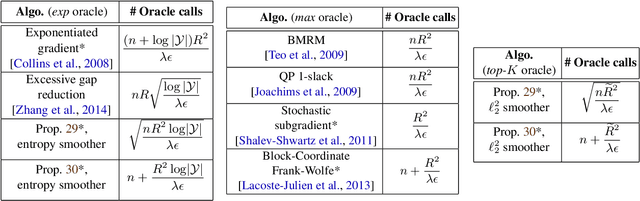
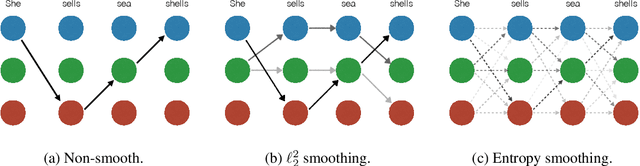

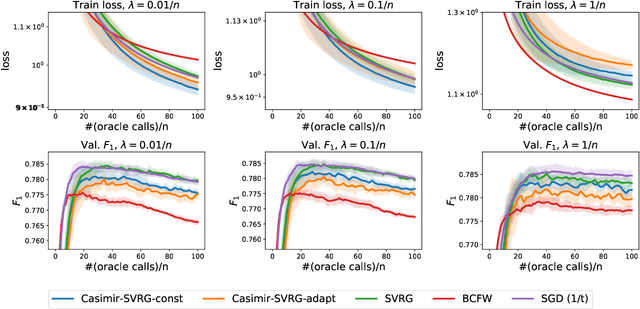
We present a framework to train a structured prediction model by performing smoothing on the inference algorithm it builds upon. Smoothing overcomes the non-smoothness inherent to the maximum margin structured prediction objective, and paves the way for the use of fast primal gradient-based optimization algorithms. We illustrate the proposed framework by developing a novel primal incremental optimization algorithm for the structural support vector machine. The proposed algorithm blends an extrapolation scheme for acceleration and an adaptive smoothing scheme and builds upon the stochastic variance-reduced gradient algorithm. We establish its worst-case global complexity bound and study several practical variants, including extensions to deep structured prediction. We present experimental results on two real-world problems, namely named entity recognition and visual object localization. The experimental results show that the proposed framework allows us to build upon efficient inference algorithms to develop large-scale optimization algorithms for structured prediction which can achieve competitive performance on the two real-world problems.
Provably Efficient Maximum Entropy Exploration
Dec 06, 2018
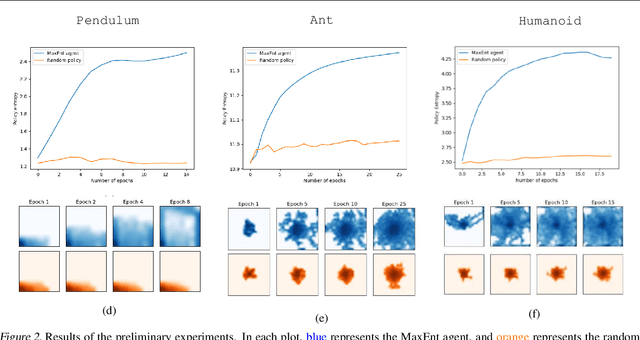
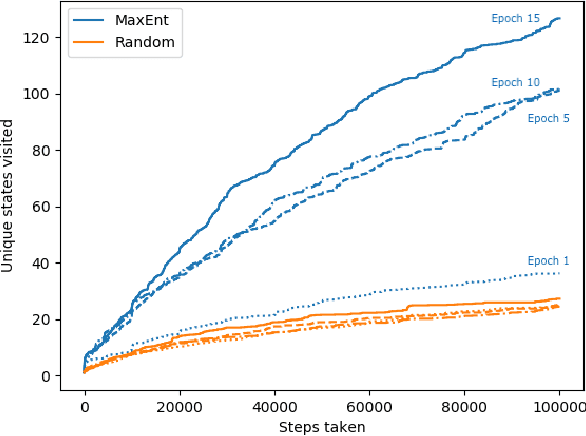
Suppose an agent is in a (possibly unknown) Markov decision process (MDP) in the absence of a reward signal, what might we hope that an agent can efficiently learn to do? One natural, intrinsically defined, objective problem is for the agent to learn a policy which induces a distribution over state space that is as uniform as possible, which can be measured in an entropic sense. Despite the corresponding mathematical program being non-convex, our main result provides a provably efficient method (both in terms of sample size and computational complexity) to construct such a maximum-entropy exploratory policy. Key to our algorithmic methodology is utilizing the conditional gradient method (a.k.a. the Frank-Wolfe algorithm) which utilizes an approximate MDP solver.
Coupled Recurrent Models for Polyphonic Music Composition
Nov 20, 2018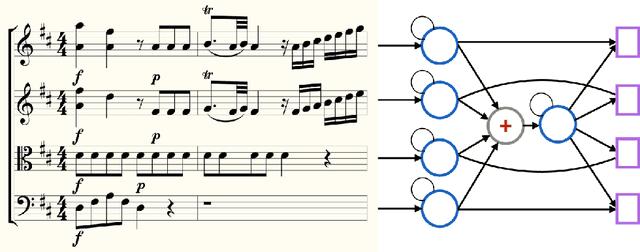



This work describes a novel recurrent model for music composition, which accounts for the rich statistical structure of polyphonic music. There are many ways to factor the probability distribution over musical scores; we consider the merits of various approaches and propose a new factorization that decomposes a score into a collection of concurrent, coupled time series: 'parts.' The model we propose borrows ideas from both convolutional neural models and recurrent neural models; we argue that these ideas are natural for capturing music's pitch invariances, temporal structure, and polyphony. We train generative models for homophonic and polyphonic composition on the KernScores dataset (Sapp, 2005) a collection of 2,300 musical scores comprised of around 2.8 million notes spanning time from the Renaissance to the early 20th century. While evaluation of generative models is known to be hard (Theis et al., 2016), we present careful quantitative results using a unit-adjusted cross entropy metric that is independent of how we factor the distribution over scores. We also present qualitative results using a blind discrimination test.
Global Convergence of Policy Gradient Methods for the Linear Quadratic Regulator
Oct 21, 2018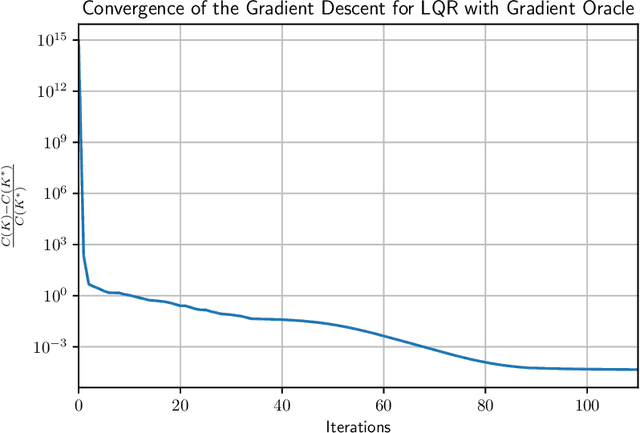
Direct policy gradient methods for reinforcement learning and continuous control problems are a popular approach for a variety of reasons: 1) they are easy to implement without explicit knowledge of the underlying model 2) they are an "end-to-end" approach, directly optimizing the performance metric of interest 3) they inherently allow for richly parameterized policies. A notable drawback is that even in the most basic continuous control problem (that of linear quadratic regulators), these methods must solve a non-convex optimization problem, where little is understood about their efficiency from both computational and statistical perspectives. In contrast, system identification and model based planning in optimal control theory have a much more solid theoretical footing, where much is known with regards to their computational and statistical properties. This work bridges this gap showing that (model free) policy gradient methods globally converge to the optimal solution and are efficient (polynomially so in relevant problem dependent quantities) with regards to their sample and computational complexities.
On the insufficiency of existing momentum schemes for Stochastic Optimization
Jul 31, 2018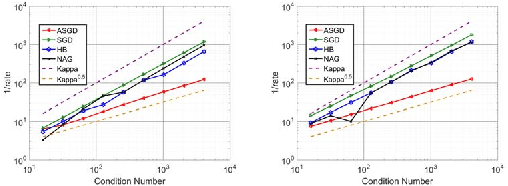
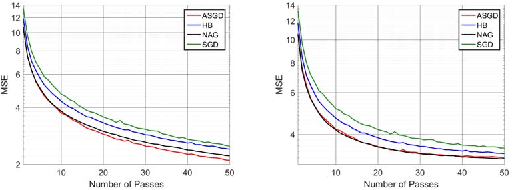
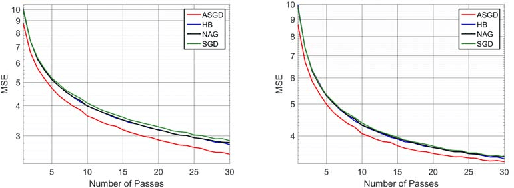
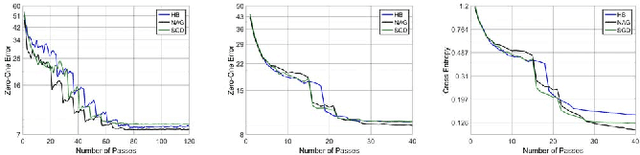
Momentum based stochastic gradient methods such as heavy ball (HB) and Nesterov's accelerated gradient descent (NAG) method are widely used in practice for training deep networks and other supervised learning models, as they often provide significant improvements over stochastic gradient descent (SGD). Rigorously speaking, "fast gradient" methods have provable improvements over gradient descent only for the deterministic case, where the gradients are exact. In the stochastic case, the popular explanations for their wide applicability is that when these fast gradient methods are applied in the stochastic case, they partially mimic their exact gradient counterparts, resulting in some practical gain. This work provides a counterpoint to this belief by proving that there exist simple problem instances where these methods cannot outperform SGD despite the best setting of its parameters. These negative problem instances are, in an informal sense, generic; they do not look like carefully constructed pathological instances. These results suggest (along with empirical evidence) that HB or NAG's practical performance gains are a by-product of mini-batching. Furthermore, this work provides a viable (and provable) alternative, which, on the same set of problem instances, significantly improves over HB, NAG, and SGD's performance. This algorithm, referred to as Accelerated Stochastic Gradient Descent (ASGD), is a simple to implement stochastic algorithm, based on a relatively less popular variant of Nesterov's Acceleration. Extensive empirical results in this paper show that ASGD has performance gains over HB, NAG, and SGD.
Accelerating Stochastic Gradient Descent For Least Squares Regression
Jul 31, 2018
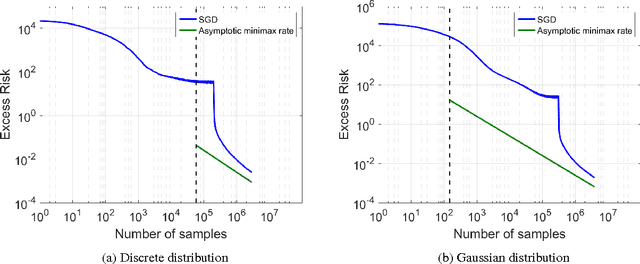
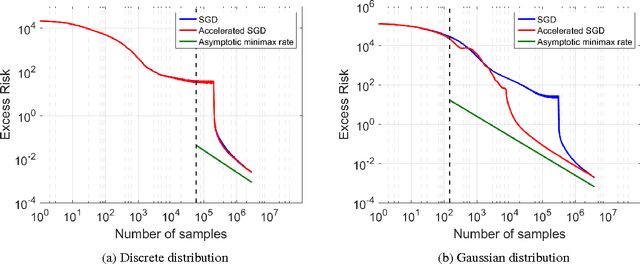
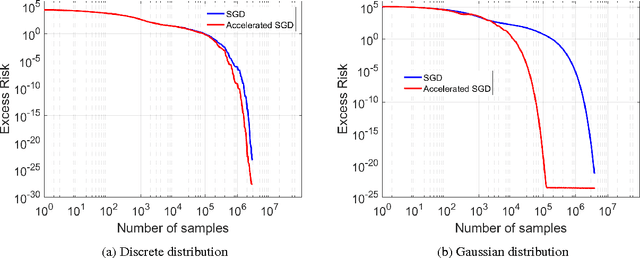
There is widespread sentiment that it is not possible to effectively utilize fast gradient methods (e.g. Nesterov's acceleration, conjugate gradient, heavy ball) for the purposes of stochastic optimization due to their instability and error accumulation, a notion made precise in d'Aspremont 2008 and Devolder, Glineur, and Nesterov 2014. This work considers these issues for the special case of stochastic approximation for the least squares regression problem, and our main result refutes the conventional wisdom by showing that acceleration can be made robust to statistical errors. In particular, this work introduces an accelerated stochastic gradient method that provably achieves the minimax optimal statistical risk faster than stochastic gradient descent. Critical to the analysis is a sharp characterization of accelerated stochastic gradient descent as a stochastic process. We hope this characterization gives insights towards the broader question of designing simple and effective accelerated stochastic methods for more general convex and non-convex optimization problems.
Parallelizing Stochastic Gradient Descent for Least Squares Regression: mini-batching, averaging, and model misspecification
Jul 31, 2018
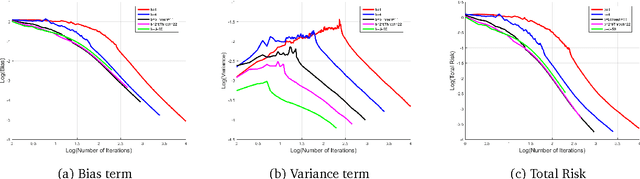

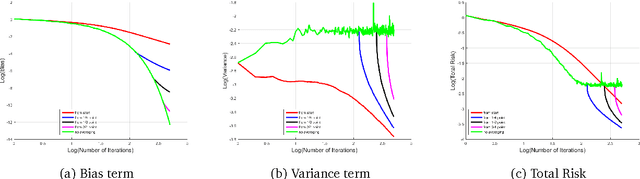
This work characterizes the benefits of averaging schemes widely used in conjunction with stochastic gradient descent (SGD). In particular, this work provides a sharp analysis of: (1) mini-batching, a method of averaging many samples of a stochastic gradient to both reduce the variance of the stochastic gradient estimate and for parallelizing SGD and (2) tail-averaging, a method involving averaging the final few iterates of SGD to decrease the variance in SGD's final iterate. This work presents non-asymptotic excess risk bounds for these schemes for the stochastic approximation problem of least squares regression. Furthermore, this work establishes a precise problem-dependent extent to which mini-batch SGD yields provable near-linear parallelization speedups over SGD with batch size one. This allows for understanding learning rate versus batch size tradeoffs for the final iterate of an SGD method. These results are then utilized in providing a highly parallelizable SGD method that obtains the minimax risk with nearly the same number of serial updates as batch gradient descent, improving significantly over existing SGD methods. A non-asymptotic analysis of communication efficient parallelization schemes such as model-averaging/parameter mixing methods is then provided. Finally, this work sheds light on some fundamental differences in SGD's behavior when dealing with agnostic noise in the (non-realizable) least squares regression problem. In particular, the work shows that the stepsizes that ensure minimax risk for the agnostic case must be a function of the noise properties. This paper builds on the operator view of analyzing SGD methods, introduced by Defossez and Bach (2015), followed by developing a novel analysis in bounding these operators to characterize the excess risk. These techniques are of broader interest in analyzing computational aspects of stochastic approximation.