 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Long Horizon Reinforcement Learning More Difficult Than Short Horizon Reinforcement Learning?
May 01, 2020Learning to plan for long horizons is a central challenge in episodic reinforcement learning problems. A fundamental question is to understand how the difficulty of the problem scales as the horizon increases. Here the natural measure of sample complexity is a normalized one: we are interested in the number of episodes it takes to provably discover a policy whose value is $\varepsilon$ near to that of the optimal value, where the value is measured by the normalized cumulative reward in each episode. In a COLT 2018 open problem, Jiang and Agarwal conjectured that, for tabular, episodic reinforcement learning problems, there exists a sample complexity lower bound which exhibits a polynomial dependence on the horizon -- a conjecture which is consistent with all known sample complexity upper bounds. This work refutes this conjecture, proving that tabular, episodic reinforcement learning is possible with a sample complexity that scales only logarithmically with the planning horizon. In other words, when the values are appropriately normalized (to lie in the unit interval), this results shows that long horizon RL is no more difficult than short horizon RL, at least in a minimax sense. Our analysis introduces two ideas: (i) the construction of an $\varepsilon$-net for optimal policies whose log-covering number scales only logarithmically with the planning horizon, and (ii) the Online Trajectory Synthesis algorithm, which adaptively evaluates all policies in a given policy class using sample complexity that scales with the log-covering number of the given policy class. Both may be of independent interest.
Few-Shot Learning via Learning the Representation, Provably
Feb 21, 2020This paper studies few-shot learning via representation learning, where one uses $T$ source tasks with $n_1$ data per task to learn a representation in order to reduce the sample complexity of a target task for which there is only $n_2 (\ll n_1)$ data. Specifically, we focus on the setting where there exists a good \emph{common representation} between source and target, and our goal is to understand how much of a sample size reduction is possible. First, we study the setting where this common representation is low-dimensional and provide a fast rate of $O\left(\frac{\mathcal{C}\left(\Phi\right)}{n_1T} + \frac{k}{n_2}\right)$; here, $\Phi$ is the representation function class, $\mathcal{C}\left(\Phi\right)$ is its complexity measure, and $k$ is the dimension of the representation. When specialized to linear representation functions, this rate becomes $O\left(\frac{dk}{n_1T} + \frac{k}{n_2}\right)$ where $d (\gg k)$ is the ambient input dimension, which is a substantial improvement over the rate without using representation learning, i.e. over the rate of $O\left(\frac{d}{n_2}\right)$. Second, we consider the setting where the common representation may be high-dimensional but is capacity-constrained (say in norm); here, we again demonstrate the advantage of representation learning in both high-dimensional linear regression and neural network learning. Our results demonstrate representation learning can fully utilize all $n_1T$ samples from source tasks.
The Nonstochastic Control Problem
Jan 20, 2020We consider the problem of controlling an unknown linear dynamical system in the presence of (nonstochastic) adversarial perturbations and adversarial convex loss functions. In contrast to classical control, the a priori determination of an optimal controller here is hindered by the latter's dependence on the yet unknown perturbations and costs. Instead, we measure regret against an optimal linear policy in hindsight, and give the first efficient algorithm that guarantees a sublinear regret bound, scaling as T^{2/3}, in this setting.
Robust Aggregation for Federated Learning
Dec 31, 2019

We present a robust aggregation approach to make federated learning robust to settings when a fraction of the devices may be sending corrupted updates to the server. The proposed approach relies on a robust secure aggregation oracle based on the geometric median, which returns a robust aggregate using a constant number of calls to a regular non-robust secure average oracle. The robust aggregation oracle is privacy-preserving, similar to the secure average oracle it builds upon. We provide experimental results of the proposed approach with linear models and deep networks for two tasks in computer vision and natural language processing. The robust aggregation approach is agnostic to the level of corruption; it outperforms the classical aggregation approach in terms of robustness when the level of corruption is high, while being competitive in the regime of low corruption.
Optimal Estimation of Change in a Population of Parameters
Nov 28, 2019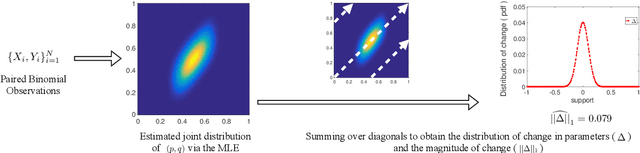
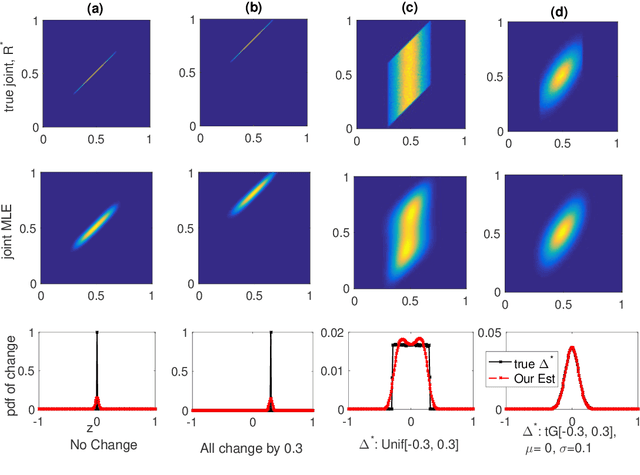
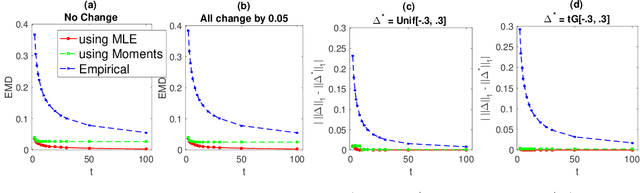

Paired estimation of change in parameters of interest over a population plays a central role in several application domains including those in the social sciences, epidemiology, medicine and biology. In these domains, the size of the population under study is often very large, however, the number of observations available per individual in the population is very small (\emph{sparse observations}) which makes the problem challenging. Consider the setting with $N$ independent individuals, each with unknown parameters $(p_i, q_i)$ drawn from some unknown distribution on $[0, 1]^2$. We observe $X_i \sim \text{Bin}(t, p_i)$ before an event and $Y_i \sim \text{Bin}(t, q_i)$ after the event. Provided these paired observations, $\{(X_i, Y_i) \}_{i=1}^N$, our goal is to accurately estimate the \emph{distribution of the change in parameters}, $\delta_i := q_i - p_i$, over the population and properties of interest like the \emph{$\ell_1$-magnitude of the change} with sparse observations ($t\ll N$). We provide \emph{information theoretic lower bounds} on the error in estimating the distribution of change and the $\ell_1$-magnitude of change. Furthermore, we show that the following two step procedure achieves the optimal error bounds: first, estimate the full joint distribution of the paired parameters using the maximum likelihood estimator (MLE) and then estimate the distribution of change and the $\ell_1$-magnitude of change using the joint MLE. Notably, and perhaps surprisingly, these error bounds are of the same order as the minimax optimal error bounds for learning the \emph{full} joint distribution itself (in Wasserstein-1 distance); in other words, estimating the magnitude of the change of parameters over the population is, in a minimax sense, as difficult as estimating the full joint distribution itself.
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
Nov 03, 2019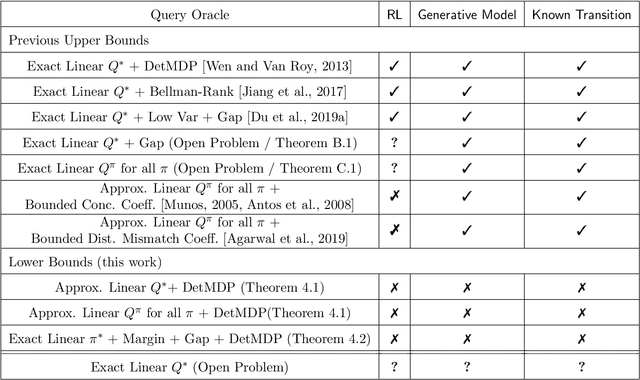
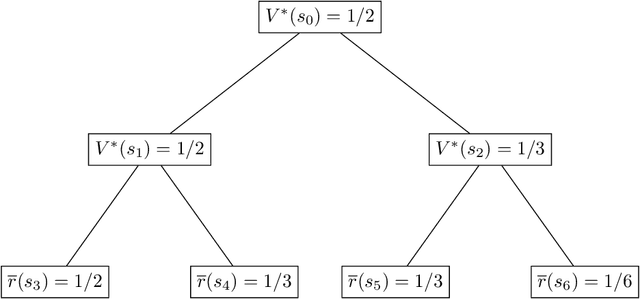
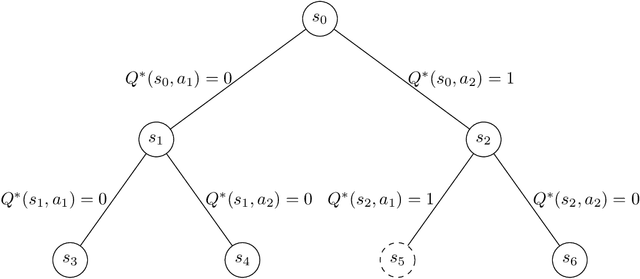
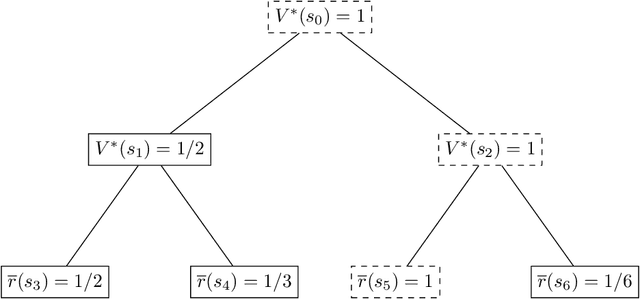
Modern deep learning methods provide an effective means to learn good representations. However, is a good representation itself sufficient for efficient reinforcement learning? This question is largely unexplored, and the extant body of literature mainly focuses on conditions which permit efficient reinforcement learning with little understanding of what are necessary conditions for efficient reinforcement learning. This work provides strong negative results for reinforcement learning methods with function approximation for which a good representation (feature extractor) is known to the agent, focusing on natural representational conditions relevant to value-based learning and policy-based learning. For value-based learning, we show that even if the agent has a highly accurate linear representation, the agent still needs to sample exponentially many trajectories in order to find a near-optimal policy. For policy-based learning, we show even if the agent's linear representation is capable of perfectly representing the optimal policy, the agent still needs to sample exponentially many trajectories in order to find a near-optimal policy. These lower bounds highlight the fact that having a good (value-based or policy-based) representation in and of itself is insufficient for efficient reinforcement learning. In particular, these results provide new insights into why the existing provably efficient reinforcement learning methods rely on further assumptions, which are often model-based in nature. Additionally, our lower bounds imply exponential separations in the sample complexity between 1) value-based learning with perfect representation and value-based learning with a good-but-not-perfect representation, 2) value-based learning and policy-based learning, 3) policy-based learning and supervised learning and 4) reinforcement learning and imitation learning.
Optimality and Approximation with Policy Gradient Methods in Markov Decision Processes
Aug 29, 2019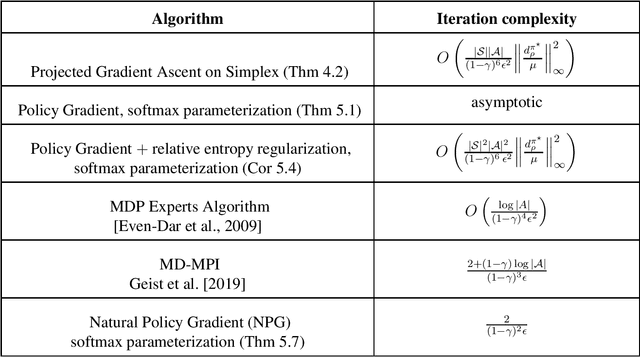
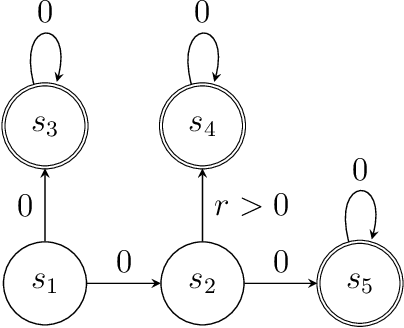
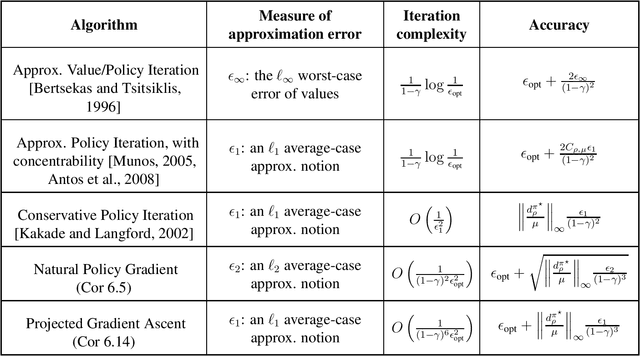
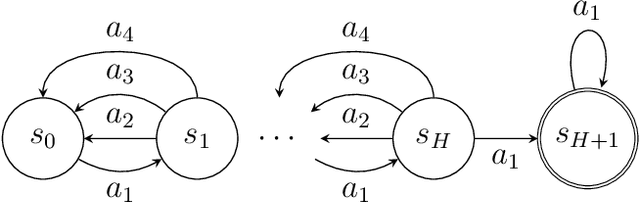
Policy gradient methods are among the most effective methods in challenging reinforcement learning problems with large state and/or action spaces. However, little is known about even their most basic theoretical convergence properties, including: if and how fast they converge to a globally optimal solution (say with a sufficiently rich policy class); how they cope with approximation error due to using a restricted class of parametric policies; or their finite sample behavior. Such characterizations are important not only to compare these methods to their approximate value function counterparts (where such issues are relatively well understood, at least in the worst case), but also to help with more principled approaches to algorithm design. This work provides provable characterizations of computational, approximation, and sample size issues with regards to policy gradient methods in the context of discounted Markov Decision Processes (MDPs). We focus on both: 1) "tabular" policy parameterizations, where the optimal policy is contained in the class and where we show global convergence to the optimal policy, and 2) restricted policy classes, which may not contain the optimal policy and where we provide agnostic learning results. One insight of this work is in formalizing the importance how a favorable initial state distribution provides a means to circumvent worst-case exploration issues. Overall, these results place policy gradient methods under a solid theoretical footing, analogous to the global convergence guarantees of iterative value function based algorithms.
Calibration, Entropy Rates, and Memory in Language Models
Jun 11, 2019

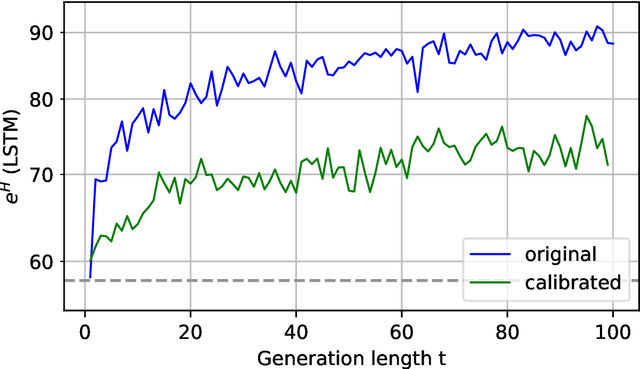
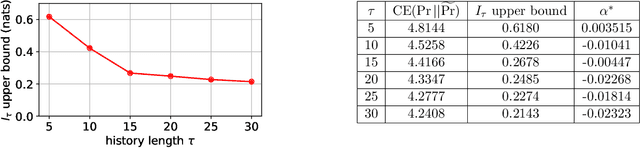
Building accurate language models that capture meaningful long-term dependencies is a core challenge in natural language processing. Towards this end, we present a calibration-based approach to measure long-term discrepancies between a generative sequence model and the true distribution, and use these discrepancies to improve the model. Empirically, we show that state-of-the-art language models, including LSTMs and Transformers, are \emph{miscalibrated}: the entropy rates of their generations drift dramatically upward over time. We then provide provable methods to mitigate this phenomenon. Furthermore, we show how this calibration-based approach can also be used to measure the amount of memory that language models use for prediction.
The Step Decay Schedule: A Near Optimal, Geometrically Decaying Learning Rate Procedure
Apr 29, 2019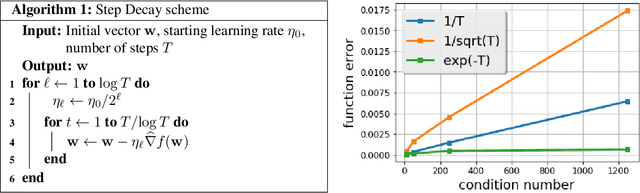
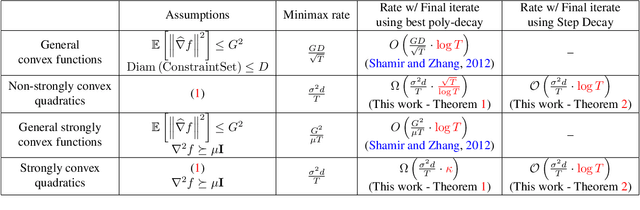

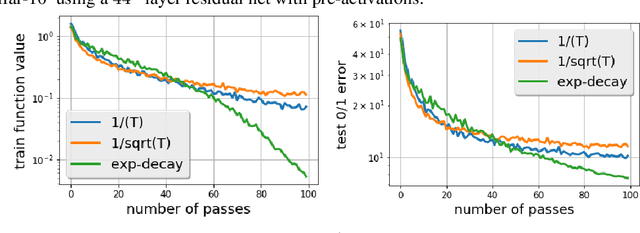
There is a stark disparity between the step size schedules used in practical large scale machine learning and those that are considered optimal by the theory of stochastic approximation. In theory, most results utilize polynomially decaying learning rate schedules, while, in practice, the "Step Decay" schedule is among the most popular schedules, where the learning rate is cut every constant number of epochs (i.e. this is a geometrically decaying schedule). This work examines the step-decay schedule for the stochastic optimization problem of streaming least squares regression (both in the non-strongly convex and strongly convex case), where we show that a sharp theoretical characterization of an optimal learning rate schedule is far more nuanced than suggested by previous work. We focus specifically on the rate that is achievable when using the final iterate of stochastic gradient descent, as is commonly done in practice. Our main result provably shows that a properly tuned geometrically decaying learning rate schedule provides an exponential improvement (in terms of the condition number) over any polynomially decaying learning rate schedule. We also provide experimental support for wider applicability of these results, including for training modern deep neural networks.
Online Control with Adversarial Disturbances
Feb 23, 2019We study the control of a linear dynamical system with adversarial disturbances (as opposed to statistical noise). The objective we consider is one of regret: we desire an online control procedure that can do nearly as well as that of a procedure that has full knowledge of the disturbances in hindsight. Our main result is an efficient algorithm that provides nearly tight regret bounds for this problem. From a technical standpoint, this work generalizes upon previous work in two main aspects: our model allows for adversarial noise in the dynamics, and allows for general convex costs.