 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Equivalence Queries, Revisited
Apr 06, 2026Modern machine learning systems, such as generative models and recommendation systems, often evolve through a cycle of deployment, user interaction, and periodic model updates. This differs from standard supervised learning frameworks, which focus on loss or regret minimization over a fixed sequence of prediction tasks. Motivated by this setting, we revisit the classical model of learning from equivalence queries, introduced by Angluin (1988). In this model, a learner repeatedly proposes hypotheses and, when a deployed hypothesis is inadequate, receives a counterexample. Under fully adversarial counterexample generation, however, the model can be overly pessimistic. In addition, most prior work assumes a \emph{full-information} setting, where the learner also observes the correct label of the counterexample, an assumption that is not always natural. We address these issues by restricting the environment to a broad class of less adversarial counterexample generators, which we call \emph{symmetric}. Informally, such generators choose counterexamples based only on the symmetric difference between the hypothesis and the target. This class captures natural mechanisms such as random counterexamples (Angluin and Dohrn, 2017; Bhatia, 2021; Chase, Freitag, and Reyzin, 2024), as well as generators that return the simplest counterexample according to a prescribed complexity measure. Within this framework, we study learning from equivalence queries under both full-information and bandit feedback. We obtain tight bounds on the number of learning rounds in both settings and highlight directions for future work. Our analysis combines a game-theoretic view of symmetric adversaries with adaptive weighting methods and minimax arguments.
A New Benchmark for Online Learning with Budget-Balancing Constraints
Mar 19, 2025The adversarial Bandit with Knapsack problem is a multi-armed bandits problem with budget constraints and adversarial rewards and costs. In each round, a learner selects an action to take and observes the reward and cost of the selected action. The goal is to maximize the sum of rewards while satisfying the budget constraint. The classical benchmark to compare against is the best fixed distribution over actions that satisfies the budget constraint in expectation. Unlike its stochastic counterpart, where rewards and costs are drawn from some fixed distribution (Badanidiyuru et al., 2018), the adversarial BwK problem does not admit a no-regret algorithm for every problem instance due to the "spend-or-save" dilemma (Immorlica et al., 2022). A key problem left open by existing works is whether there exists a weaker but still meaningful benchmark to compare against such that no-regret learning is still possible. In this work, we present a new benchmark to compare against, motivated both by real-world applications such as autobidding and by its underlying mathematical structure. The benchmark is based on the Earth Mover's Distance (EMD), and we show that sublinear regret is attainable against any strategy whose spending pattern is within EMD $o(T^2)$ of any sub-pacing spending pattern. As a special case, we obtain results against the "pacing over windows" benchmark, where we partition time into disjoint windows of size $w$ and allow the benchmark strategies to choose a different distribution over actions for each window while satisfying a pacing budget constraint. Against this benchmark, our algorithm obtains a regret bound of $\tilde{O}(T/\sqrt{w}+\sqrt{wT})$. We also show a matching lower bound, proving the optimality of our algorithm in this important special case. In addition, we provide further evidence of the necessity of the EMD condition for obtaining a sublinear regret.
Understanding Influence Functions and Datamodels via Harmonic Analysis
Oct 03, 2022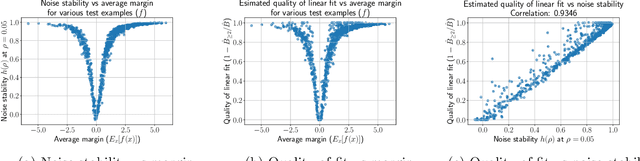
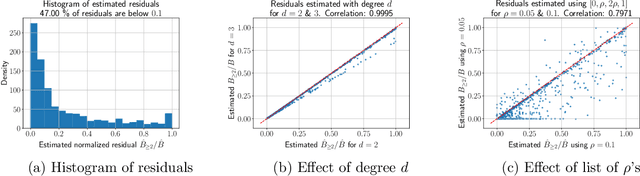
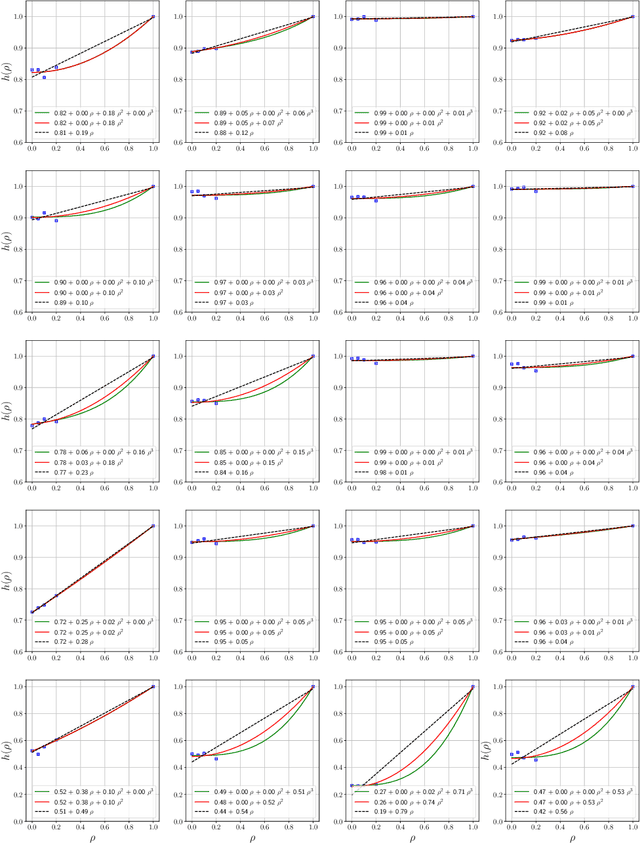
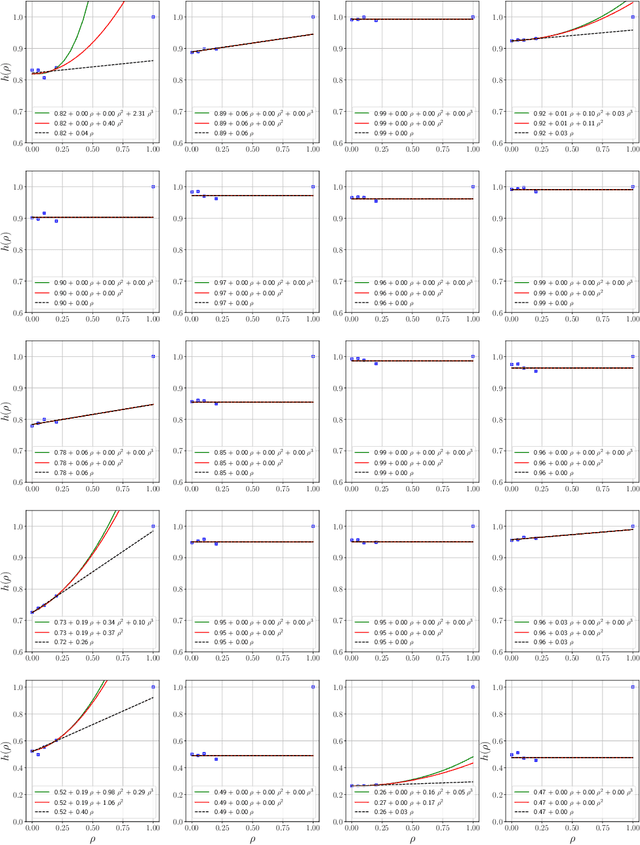
Influence functions estimate effect of individual data points on predictions of the model on test data and were adapted to deep learning in Koh and Liang [2017]. They have been used for detecting data poisoning, detecting helpful and harmful examples, influence of groups of datapoints, etc. Recently, Ilyas et al. [2022] introduced a linear regression method they termed datamodels to predict the effect of training points on outputs on test data. The current paper seeks to provide a better theoretical understanding of such interesting empirical phenomena. The primary tool is harmonic analysis and the idea of noise stability. Contributions include: (a) Exact characterization of the learnt datamodel in terms of Fourier coefficients. (b) An efficient method to estimate the residual error and quality of the optimum linear datamodel without having to train the datamodel. (c) New insights into when influences of groups of datapoints may or may not add up linearly.
Statistically Near-Optimal Hypothesis Selection
Aug 17, 2021



Hypothesis Selection is a fundamental distribution learning problem where given a comparator-class $Q=\{q_1,\ldots, q_n\}$ of distributions, and a sampling access to an unknown target distribution $p$, the goal is to output a distribution $q$ such that $\mathsf{TV}(p,q)$ is close to $opt$, where $opt = \min_i\{\mathsf{TV}(p,q_i)\}$ and $\mathsf{TV}(\cdot, \cdot)$ denotes the total-variation distance. Despite the fact that this problem has been studied since the 19th century, its complexity in terms of basic resources, such as number of samples and approximation guarantees, remains unsettled (this is discussed, e.g., in the charming book by Devroye and Lugosi `00). This is in stark contrast with other (younger) learning settings, such as PAC learning, for which these complexities are well understood. We derive an optimal $2$-approximation learning strategy for the Hypothesis Selection problem, outputting $q$ such that $\mathsf{TV}(p,q) \leq2 \cdot opt + \eps$, with a (nearly) optimal sample complexity of~$\tilde O(\log n/\epsilon^2)$. This is the first algorithm that simultaneously achieves the best approximation factor and sample complexity: previously, Bousquet, Kane, and Moran (COLT `19) gave a learner achieving the optimal $2$-approximation, but with an exponentially worse sample complexity of $\tilde O(\sqrt{n}/\epsilon^{2.5})$, and Yatracos~(Annals of Statistics `85) gave a learner with optimal sample complexity of $O(\log n /\epsilon^2)$ but with a sub-optimal approximation factor of $3$.
Optimization-friendly generic mechanisms without money
Jun 14, 2021The goal of this paper is to develop a generic framework for converting modern optimization algorithms into mechanisms where inputs come from self-interested agents. We focus on aggregating preferences from $n$ players in a context without money. Special cases of this setting include voting, allocation of items by lottery, and matching. Our key technical contribution is a new meta-algorithm we call \apex (Adaptive Pricing Equalizing Externalities). The framework is sufficiently general to be combined with any optimization algorithm that is based on local search. We outline an agenda for studying the algorithm's properties and its applications. As a special case of applying the framework to the problem of one-sided assignment with lotteries, we obtain a strengthening of the 1979 result by Hylland and Zeckhauser on allocation via a competitive equilibrium from equal incomes (CEEI). The [HZ79] result posits that there is a (fractional) allocation and a set of item prices such that the allocation is a competitive equilibrium given prices. We further show that there is always a reweighing of the players' utility values such that running unit-demand VCG with reweighed utilities leads to a HZ-equilibrium prices. Interestingly, not all HZ competitive equilibria come from VCG prices. As part of our proof, we re-prove the [HZ79] result using only Brouwer's fixed point theorem (and not the more general Kakutani's theorem). This may be of independent interest.
The Role of Randomness and Noise in Strategic Classification
May 17, 2020We investigate the problem of designing optimal classifiers in the strategic classification setting, where the classification is part of a game in which players can modify their features to attain a favorable classification outcome (while incurring some cost). Previously, the problem has been considered from a learning-theoretic perspective and from the algorithmic fairness perspective. Our main contributions include 1. Showing that if the objective is to maximize the efficiency of the classification process (defined as the accuracy of the outcome minus the sunk cost of the qualified players manipulating their features to gain a better outcome), then using randomized classifiers (that is, ones where the probability of a given feature vector to be accepted by the classifier is strictly between 0 and 1) is necessary. 2. Showing that in many natural cases, the imposed optimal solution (in terms of efficiency) has the structure where players never change their feature vectors (the randomized classifier is structured in a way, such that the gain in the probability of being classified as a 1 does not justify the expense of changing one's features). 3. Observing that the randomized classification is not a stable best-response from the classifier's viewpoint, and that the classifier doesn't benefit from randomized classifiers without creating instability in the system. 4. Showing that in some cases, a noisier signal leads to better equilibria outcomes -- improving both accuracy and fairness when more than one subpopulation with different feature adjustment costs are involved. This is interesting from a policy perspective, since it is hard to force institutions to stick to a particular randomized classification strategy (especially in a context of a market with multiple classifiers), but it is possible to alter the information environment to make the feature signals inherently noisier.
The gradient complexity of linear regression
Nov 06, 2019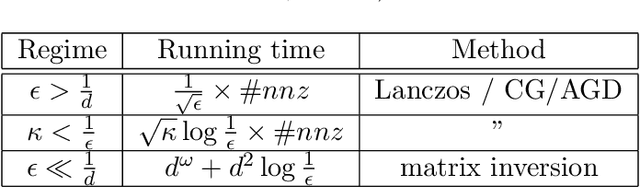
We investigate the computational complexity of several basic linear algebra primitives, including largest eigenvector computation and linear regression, in the computational model that allows access to the data via a matrix-vector product oracle. We show that for polynomial accuracy, $\Theta(d)$ calls to the oracle are necessary and sufficient even for a randomized algorithm. Our lower bound is based on a reduction to estimating the least eigenvalue of a random Wishart matrix. This simple distribution enables a concise proof, leveraging a few key properties of the random Wishart ensemble.
Convex Set Disjointness, Distributed Learning of Halfspaces, and LP Feasibility
Sep 08, 2019

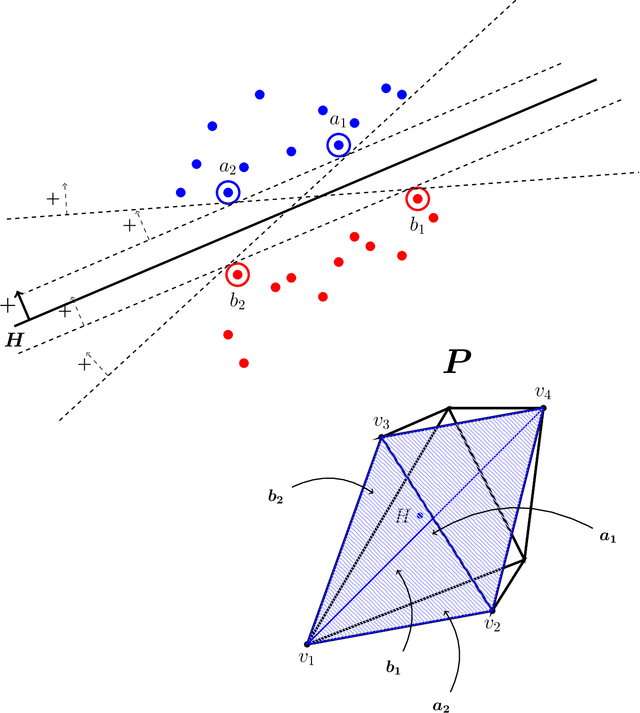

We study the Convex Set Disjointness (CSD) problem, where two players have input sets taken from an arbitrary fixed domain~$U\subseteq \mathbb{R}^d$ of size $\lvert U\rvert = n$. Their mutual goal is to decide using minimum communication whether the convex hulls of their sets intersect (equivalently, whether their sets can be separated by a hyperplane). Different forms of this problem naturally arise in distributed learning and optimization: it is equivalent to {\em Distributed Linear Program (LP) Feasibility} -- a basic task in distributed optimization, and it is tightly linked to {\it Distributed Learning of Halfdpaces in $\mathbb{R}^d$}. In {communication complexity theory}, CSD can be viewed as a geometric interpolation between the classical problems of {Set Disjointness} (when~$d\geq n-1$) and {Greater-Than} (when $d=1$). We establish a nearly tight bound of $\tilde \Theta(d\log n)$ on the communication complexity of learning halfspaces in $\mathbb{R}^d$. For Convex Set Disjointness (and the equivalent task of distributed LP feasibility) we derive upper and lower bounds of $\tilde O(d^2\log n)$ and~$\Omega(d\log n)$. These results improve upon several previous works in distributed learning and optimization. Unlike typical works in communication complexity, the main technical contribution of this work lies in the upper bounds. In particular, our protocols are based on a {\it Container Lemma for Halfspaces} and on two variants of {\it Carath\'eodory's Theorem}, which may be of independent interest. These geometric statements are used by our protocols to provide a compressed summary of the players' input.
Sorted Top-k in Rounds
Jun 12, 2019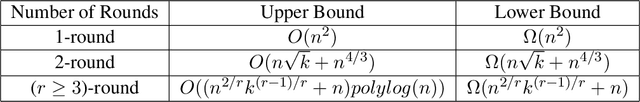

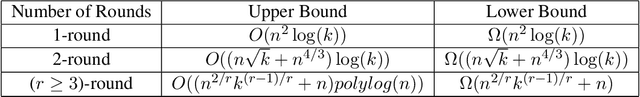

We consider the sorted top-$k$ problem whose goal is to recover the top-$k$ items with the correct order out of $n$ items using pairwise comparisons. In many applications, multiple rounds of interaction can be costly. We restrict our attention to algorithms with a constant number of rounds $r$ and try to minimize the sample complexity, i.e. the number of comparisons. When the comparisons are noiseless, we characterize how the optimal sample complexity depends on the number of rounds (up to a polylogarithmic factor for general $r$ and up to a constant factor for $r=1$ or 2). In particular, the sample complexity is $\Theta(n^2)$ for $r=1$, $\Theta(n\sqrt{k} + n^{4/3})$ for $r=2$ and $\tilde{\Theta}\left(n^{2/r} k^{(r-1)/r} + n\right)$ for $r \geq 3$. We extend our results of sorted top-$k$ to the noisy case where each comparison is correct with probability $2/3$. When $r=1$ or 2, we show that the sample complexity gets an extra $\Theta(\log(k))$ factor when we transition from the noiseless case to the noisy case. We also prove new results for top-$k$ and sorting in the noisy case. We believe our techniques can be generally useful for understanding the trade-off between round complexities and sample complexities of rank aggregation problems.
Calibration, Entropy Rates, and Memory in Language Models
Jun 11, 2019

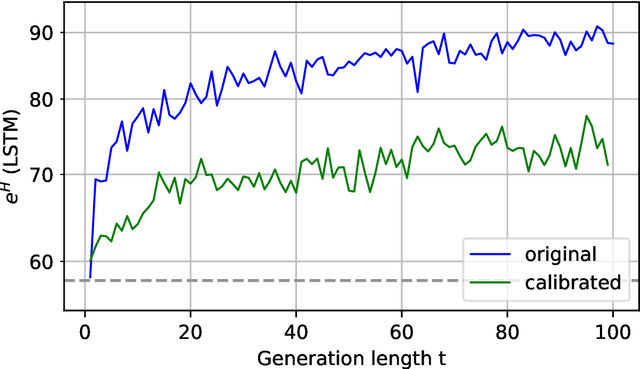
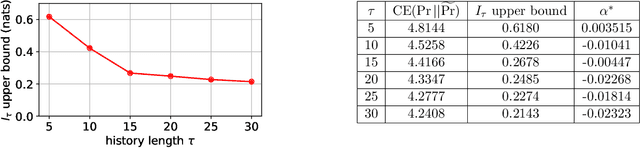
Building accurate language models that capture meaningful long-term dependencies is a core challenge in natural language processing. Towards this end, we present a calibration-based approach to measure long-term discrepancies between a generative sequence model and the true distribution, and use these discrepancies to improve the model. Empirically, we show that state-of-the-art language models, including LSTMs and Transformers, are \emph{miscalibrated}: the entropy rates of their generations drift dramatically upward over time. We then provide provable methods to mitigate this phenomenon. Furthermore, we show how this calibration-based approach can also be used to measure the amount of memory that language models use for prediction.