 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillful Precipitation Nowcasting using Deep Generative Models of Radar
Apr 02, 2021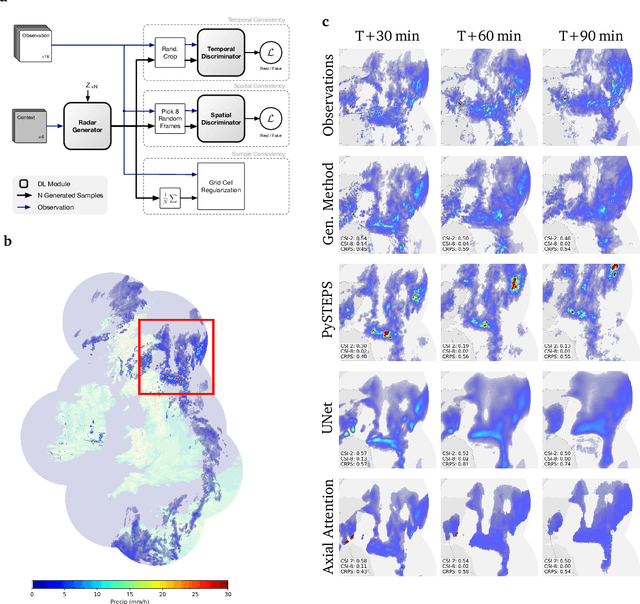
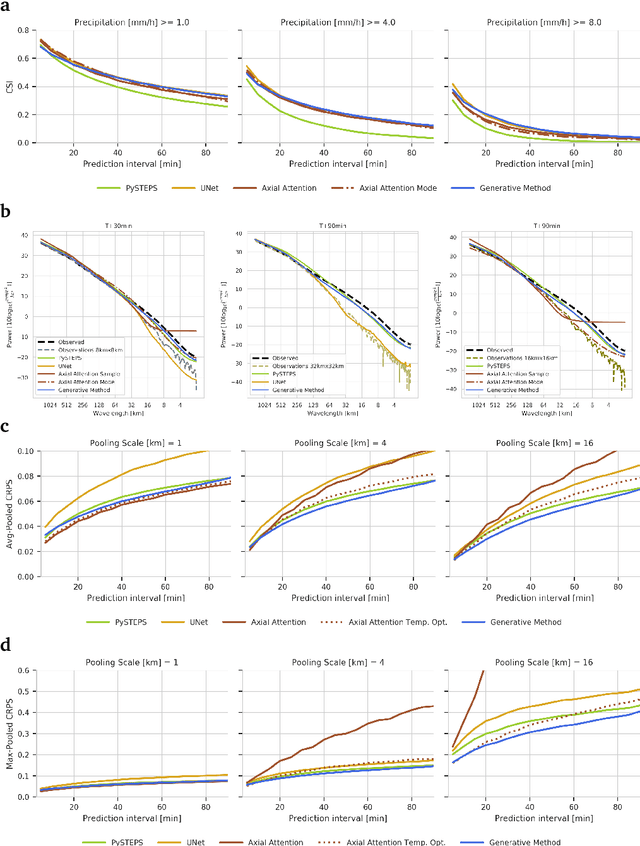
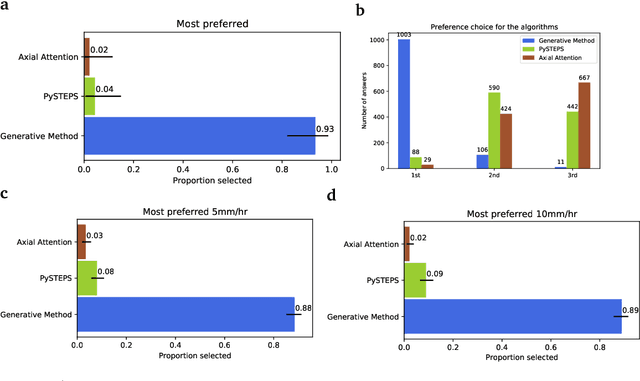
Precipitation nowcasting, the high-resolution forecasting of precipitation up to two hours ahead, supports the real-world socio-economic needs of many sectors reliant on weather-dependent decision-making. State-of-the-art operational nowcasting methods typically advect precipitation fields with radar-based wind estimates, and struggle to capture important non-linear events such as convective initiations. Recently introduced deep learning methods use radar to directly predict future rain rates, free of physical constraints. While they accurately predict low-intensity rainfall, their operational utility is limited because their lack of constraints produces blurry nowcasts at longer lead times, yielding poor performance on more rare medium-to-heavy rain events. To address these challenges, we present a Deep Generative Model for the probabilistic nowcasting of precipitation from radar. Our model produces realistic and spatio-temporally consistent predictions over regions up to 1536 km x 1280 km and with lead times from 5-90 min ahead. In a systematic evaluation by more than fifty expert forecasters from the Met Office, our generative model ranked first for its accuracy and usefulness in 88% of cases against two competitive methods, demonstrating its decision-making value and ability to provide physical insight to real-world experts. When verified quantitatively, these nowcasts are skillful without resorting to blurring. We show that generative nowcasting can provide probabilistic predictions that improve forecast value and support operational utility, and at resolutions and lead times where alternative methods struggle.
Fairness for Unobserved Characteristics: Insights from Technological Impacts on Queer Communities
Feb 09, 2021Advances in algorithmic fairness have largely omitted sexual orientation and gender identity. We explore queer concerns in privacy, censorship, language, online safety, health, and employment to study the positive and negative effects of artificial intelligence on queer communities. These issues underscore the need for new directions in fairness research that take into account a multiplicity of considerations, from privacy preservation, context sensitivity and process fairness, to an awareness of sociotechnical impact and the increasingly important role of inclusive and participatory research processes. Most current approaches for algorithmic fairness assume that the target characteristics for fairness--frequently, race and legal gender--can be observed or recorded. Sexual orientation and gender identity are prototypical instances of unobserved characteristics, which are frequently missing, unknown or fundamentally unmeasurable. This paper highlights the importance of developing new approaches for algorithmic fairness that break away from the prevailing assumption of observed characteristics.
A case for new neural network smoothness constraints
Dec 21, 2020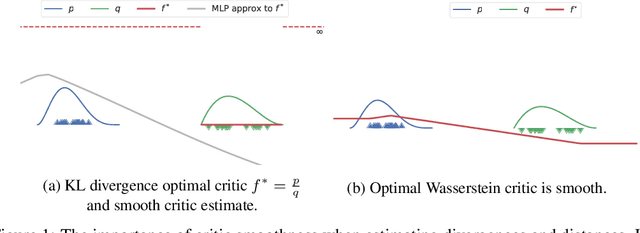
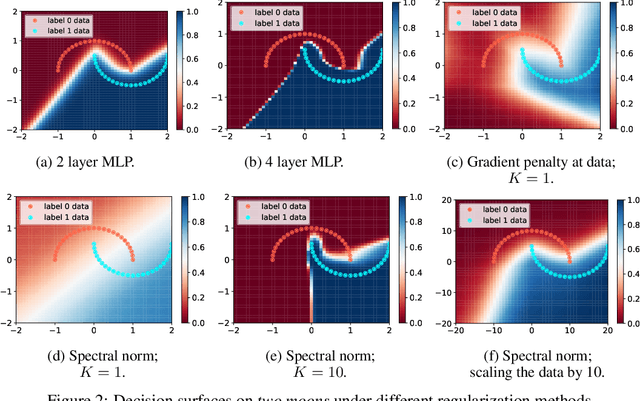
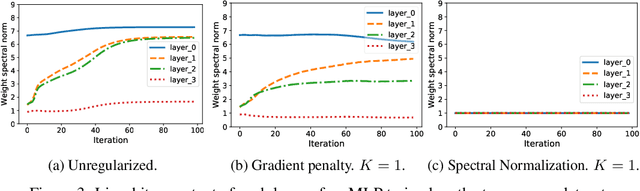
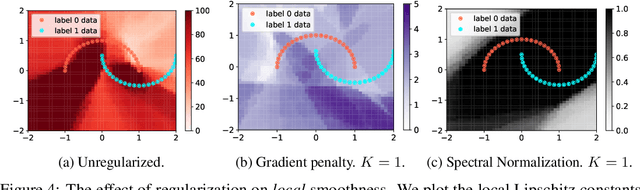
How sensitive should machine learning models be to input changes? We tackle the question of model smoothness and show that it is a useful inductive bias which aids generalization, adversarial robustness, generative modeling and reinforcement learning. We explore current methods of imposing smoothness constraints and observe they lack the flexibility to adapt to new tasks, they don't account for data modalities, they interact with losses, architectures and optimization in ways not yet fully understood. We conclude that new advances in the field are hinging on finding ways to incorporate data, tasks and learning into our definitions of smoothness.
Decolonial AI: Decolonial Theory as Sociotechnical Foresight in Artificial Intelligence
Jul 08, 2020This paper explores the important role of critical science, and in particular of post-colonial and decolonial theories, in understanding and shaping the ongoing advances in artificial intelligence. Artificial Intelligence (AI) is viewed as amongst the technological advances that will reshape modern societies and their relations. Whilst the design and deployment of systems that continually adapt holds the promise of far-reaching positive change, they simultaneously pose significant risks, especially to already vulnerable peoples. Values and power are central to this discussion. Decolonial theories use historical hindsight to explain patterns of power that shape our intellectual, political, economic, and social world. By embedding a decolonial critical approach within its technical practice, AI communities can develop foresight and tactics that can better align research and technology development with established ethical principles, centring vulnerable peoples who continue to bear the brunt of negative impacts of innovation and scientific progress. We highlight problematic applications that are instances of coloniality, and using a decolonial lens, submit three tactics that can form a decolonial field of artificial intelligence: creating a critical technical practice of AI, seeking reverse tutelage and reverse pedagogies, and the renewal of affective and political communities. The years ahead will usher in a wave of new scientific breakthroughs and technologies driven by AI research, making it incumbent upon AI communities to strengthen the social contract through ethical foresight and the multiplicity of intellectual perspectives available to us; ultimately supporting future technologies that enable greater well-being, with the goal of beneficence and justice for all.
A review of radar-based nowcasting of precipitation and applicable machine learning techniques
May 11, 2020
A 'nowcast' is a type of weather forecast which makes predictions in the very short term, typically less than two hours - a period in which traditional numerical weather prediction can be limited. This type of weather prediction has important applications for commercial aviation; public and outdoor events; and the construction industry, power utilities, and ground transportation services that conduct much of their work outdoors. Importantly, one of the key needs for nowcasting systems is in the provision of accurate warnings of adverse weather events, such as heavy rain and flooding, for the protection of life and property in such situations. Typical nowcasting approaches are based on simple extrapolation models applied to observations, primarily rainfall radar. In this paper we review existing techniques to radar-based nowcasting from environmental sciences, as well as the statistical approaches that are applicable from the field of machine learning. Nowcasting continues to be an important component of operational systems and we believe new advances are possible with new partnerships between the environmental science and machine learning communities.
Levels of Analysis for Machine Learning
Apr 06, 2020Machine learning is currently involved in some of the most vigorous debates it has ever seen. Such debates often seem to go around in circles, reaching no conclusion or resolution. This is perhaps unsurprising given that researchers in machine learning come to these discussions with very different frames of reference, making it challenging for them to align perspectives and find common ground. As a remedy for this dilemma, we advocate for the adoption of a common conceptual framework which can be used to understand, analyze, and discuss research. We present one such framework which is popular in cognitive science and neuroscience and which we believe has great utility in machine learning as well: Marr's levels of analysis. Through a series of case studies, we demonstrate how the levels facilitate an understanding and dissection of several methods from machine learning. By adopting the levels of analysis in one's own work, we argue that researchers can be better equipped to engage in the debates necessary to drive forward progress in our field.
Normalizing Flows for Probabilistic Modeling and Inference
Dec 05, 2019
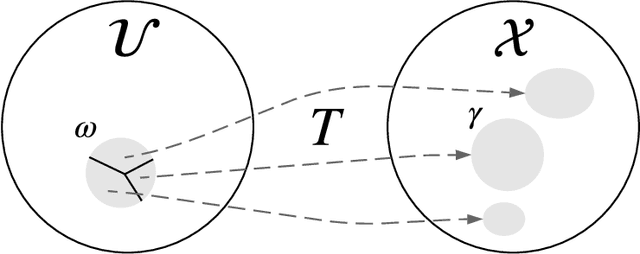
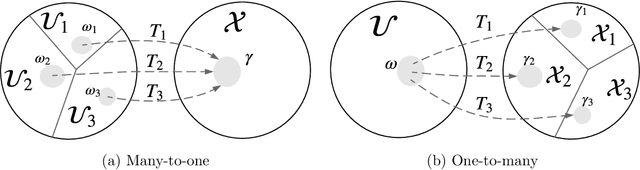
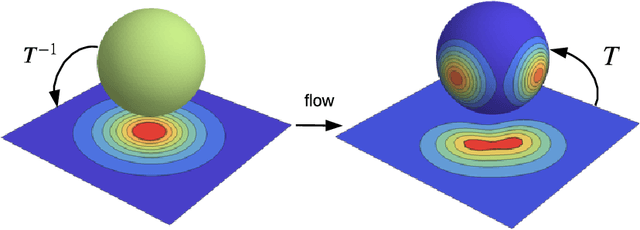
Normalizing flows provide a general mechanism for defining expressive probability distributions, only requiring the specification of a (usually simple) base distribution and a series of bijective transformations. There has been much recent work on normalizing flows, ranging from improving their expressive power to expanding their application. We believe the field has now matured and is in need of a unified perspective. In this review, we attempt to provide such a perspective by describing flows through the lens of probabilistic modeling and inference. We place special emphasis on the fundamental principles of flow design, and discuss foundational topics such as expressive power and computational trade-offs. We also broaden the conceptual framing of flows by relating them to more general probability transformations. Lastly, we summarize the use of flows for tasks such as generative modeling, approximate inference, and supervised learning.
Monte Carlo Gradient Estimation in Machine Learning
Jun 25, 2019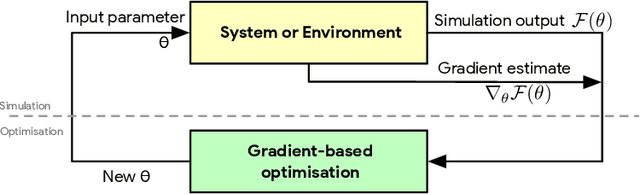

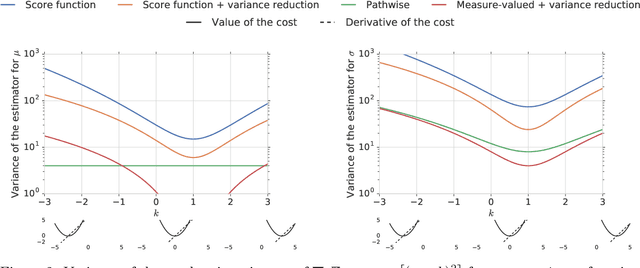
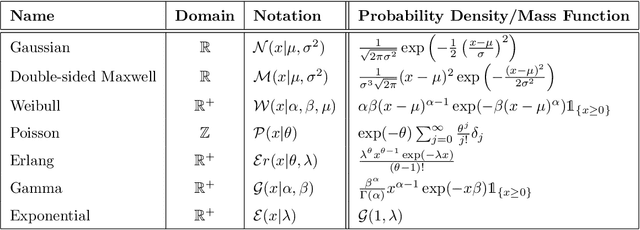
This paper is a broad and accessible survey of the methods we have at our disposal for Monte Carlo gradient estimation in machine learning and across the statistical sciences: the problem of computing the gradient of an expectation of a function with respect to parameters defining the distribution that is integrated; the problem of sensitivity analysis. In machine learning research, this gradient problem lies at the core of many learning problems, in supervised, unsupervised and reinforcement learning. We will generally seek to rewrite such gradients in a form that allows for Monte Carlo estimation, allowing them to be easily and efficiently used and analysed. We explore three strategies--the pathwise, score function, and measure-valued gradient estimators--exploring their historical developments, derivation, and underlying assumptions. We describe their use in other fields, show how they are related and can be combined, and expand on their possible generalisations. Wherever Monte Carlo gradient estimators have been derived and deployed in the past, important advances have followed. A deeper and more widely-held understanding of this problem will lead to further advances, and it is these advances that we wish to support.
Training language GANs from Scratch
May 23, 2019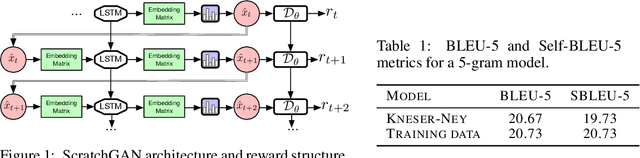
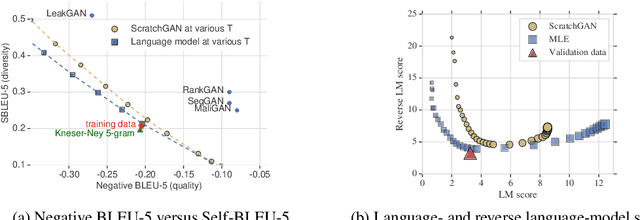
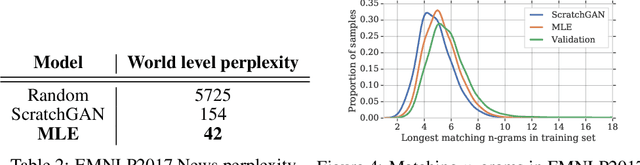
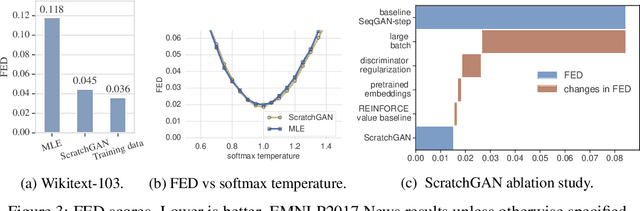
Generative Adversarial Networks (GANs) enjoy great success at image generation, but have proven difficult to train in the domain of natural language. Challenges with gradient estimation, optimization instability, and mode collapse have lead practitioners to resort to maximum likelihood pre-training, followed by small amounts of adversarial fine-tuning. The benefits of GAN fine-tuning for language generation are unclear, as the resulting models produce comparable or worse samples than traditional language models. We show it is in fact possible to train a language GAN from scratch -- without maximum likelihood pre-training. We combine existing techniques such as large batch sizes, dense rewards and discriminator regularization to stabilize and improve language GANs. The resulting model, ScratchGAN, performs comparably to maximum likelihood training on EMNLP2017 News and WikiText-103 corpora according to quality and diversity metrics.
Implicit Reparameterization Gradients
Nov 01, 2018
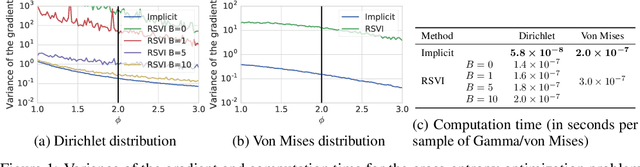
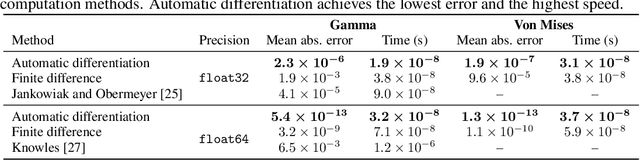
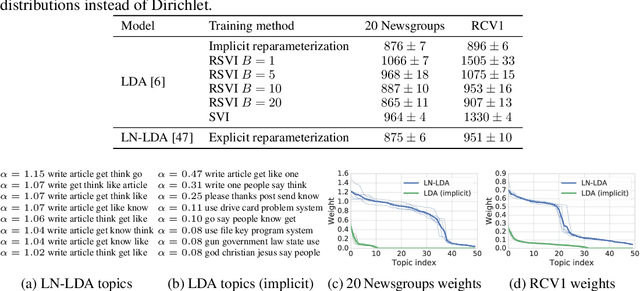
By providing a simple and efficient way of computing low-variance gradients of continuous random variables, the reparameterization trick has become the technique of choice for training a variety of latent variable models. However, it is not applicable to a number of important continuous distributions. We introduce an alternative approach to computing reparameterization gradients based on implicit differentiation and demonstrate its broader applicability by applying it to Gamma, Beta, Dirichlet, and von Mises distributions, which cannot be used with the classic reparameterization trick. Our experiments show that the proposed approach is faster and more accurate than the existing gradient estimators for these distributions.