 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Predict Sentence by Sentence
May 28, 2025



Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
The Coverage Principle: A Framework for Understanding Compositional Generalization
May 26, 2025Large language models excel at pattern matching, yet often fall short in systematic compositional generalization. We propose the coverage principle: a data-centric framework showing that models relying primarily on pattern matching for compositional tasks cannot reliably generalize beyond substituting fragments that yield identical results when used in the same contexts. We demonstrate that this framework has a strong predictive power for the generalization capabilities of Transformers. First, we derive and empirically confirm that the training data required for two-hop generalization grows at least quadratically with the token set size, and the training data efficiency does not improve with 20x parameter scaling. Second, for compositional tasks with path ambiguity where one variable affects the output through multiple computational paths, we show that Transformers learn context-dependent state representations that undermine both performance and interoperability. Third, Chain-of-Thought supervision improves training data efficiency for multi-hop tasks but still struggles with path ambiguity. Finally, we outline a \emph{mechanism-based} taxonomy that distinguishes three ways neural networks can generalize: structure-based (bounded by coverage), property-based (leveraging algebraic invariances), and shared-operator (through function reuse). This conceptual lens contextualizes our results and highlights where new architectural ideas are needed to achieve systematic compositionally. Overall, the coverage principle provides a unified lens for understanding compositional reasoning, and underscores the need for fundamental architectural or training innovations to achieve truly systematic compositionality.
Knowledge Entropy Decay during Language Model Pretraining Hinders New Knowledge Acquisition
Oct 02, 2024



In this work, we investigate how a model's tendency to broadly integrate its parametric knowledge evolves throughout pretraining, and how this behavior affects overall performance, particularly in terms of knowledge acquisition and forgetting. We introduce the concept of knowledge entropy, which quantifies the range of memory sources the model engages with; high knowledge entropy indicates that the model utilizes a wide range of memory sources, while low knowledge entropy suggests reliance on specific sources with greater certainty. Our analysis reveals a consistent decline in knowledge entropy as pretraining advances. We also find that the decline is closely associated with a reduction in the model's ability to acquire and retain knowledge, leading us to conclude that diminishing knowledge entropy (smaller number of active memory sources) impairs the model's knowledge acquisition and retention capabilities. We find further support for this by demonstrating that increasing the activity of inactive memory sources enhances the model's capacity for knowledge acquisition and retention.
IterCQR: Iterative Conversational Query Reformulation without Human Supervision
Nov 16, 2023



In conversational search, which aims to retrieve passages containing essential information, queries suffer from high dependency on the preceding dialogue context. Therefore, reformulating conversational queries into standalone forms is essential for the effective utilization of off-the-shelf retrievers. Previous methodologies for conversational query search frequently depend on human-annotated gold labels. However, these manually crafted queries often result in sub-optimal retrieval performance and require high collection costs. In response to these challenges, we propose Iterative Conversational Query Reformulation (IterCQR), a methodology that conducts query reformulation without relying on human oracles. IterCQR iteratively trains the QR model by directly leveraging signal from information retrieval (IR) as a reward. Our proposed IterCQR method shows state-of-the-art performance on two datasets, demonstrating its effectiveness on both sparse and dense retrievers. Notably, IterCQR exhibits robustness in domain-shift, low-resource, and topic-shift scenarios.
CrossAug: A Contrastive Data Augmentation Method for Debiasing Fact Verification Models
Sep 30, 2021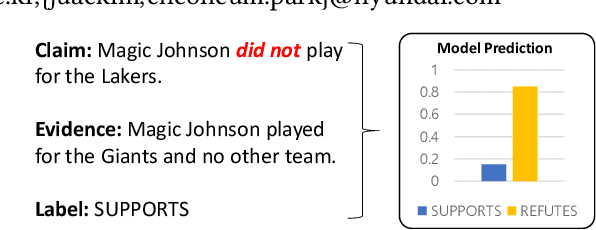
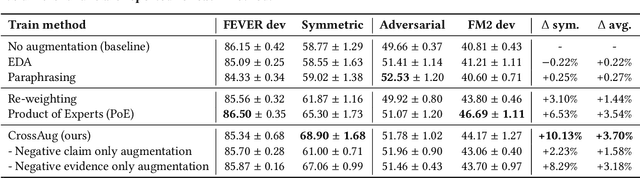
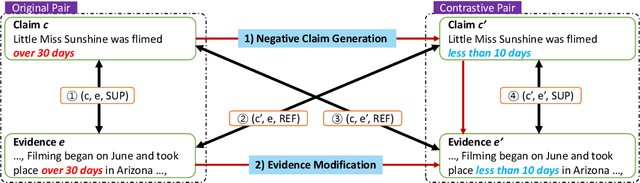
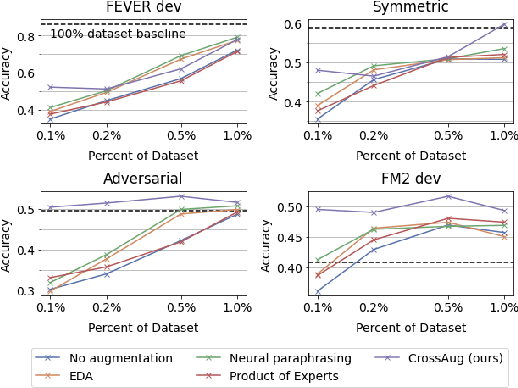
Fact verification datasets are typically constructed using crowdsourcing techniques due to the lack of text sources with veracity labels. However, the crowdsourcing process often produces undesired biases in data that cause models to learn spurious patterns. In this paper, we propose CrossAug, a contrastive data augmentation method for debiasing fact verification models. Specifically, we employ a two-stage augmentation pipeline to generate new claims and evidences from existing samples. The generated samples are then paired cross-wise with the original pair, forming contrastive samples that facilitate the model to rely less on spurious patterns and learn more robust representations. Experimental results show that our method outperforms the previous state-of-the-art debiasing technique by 3.6% on the debiased extension of the FEVER dataset, with a total performance boost of 10.13% from the baseline. Furthermore, we evaluate our approach in data-scarce settings, where models can be more susceptible to biases due to the lack of training data. Experimental results demonstrate that our approach is also effective at debiasing in these low-resource conditions, exceeding the baseline performance on the Symmetric dataset with just 1% of the original data.
Collaborative Training of GANs in Continuous and Discrete Spaces for Text Generation
Nov 04, 2020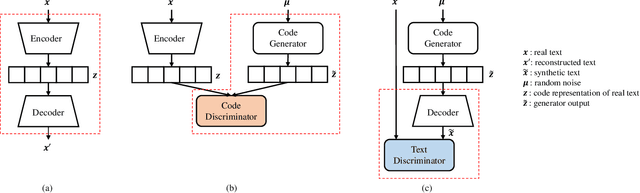

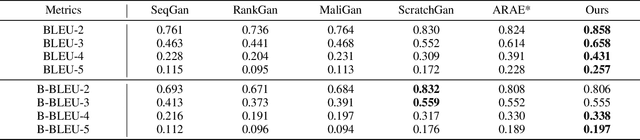
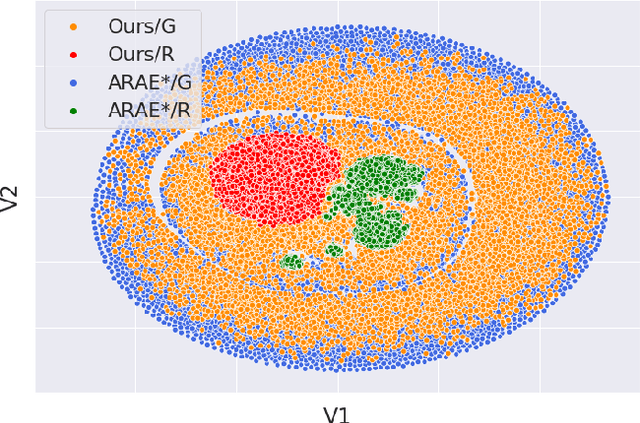
Applying generative adversarial networks (GANs) to text-related tasks is challenging due to the discrete nature of language. One line of research resolves this issue by employing reinforcement learning (RL) and optimizing the next-word sampling policy directly in a discrete action space. Such methods compute the rewards from complete sentences and avoid error accumulation due to exposure bias. Other approaches employ approximation techniques that map the text to continuous representation in order to circumvent the non-differentiable discrete process. Particularly, autoencoder-based methods effectively produce robust representations that can model complex discrete structures. In this paper, we propose a novel text GAN architecture that promotes the collaborative training of the continuous-space and discrete-space methods. Our method employs an autoencoder to learn an implicit data manifold, providing a learning objective for adversarial training in a continuous space. Furthermore, the complete textual output is directly evaluated and updated via RL in a discrete space. The collaborative interplay between the two adversarial trainings effectively regularize the text representations in different spaces. The experimental results on three standard benchmark datasets show that our model substantially outperforms state-of-the-art text GANs with respect to quality, diversity, and global consistency.
Detecting Incongruity Between News Headline and Body Text via a Deep Hierarchical Encoder
Nov 17, 2018

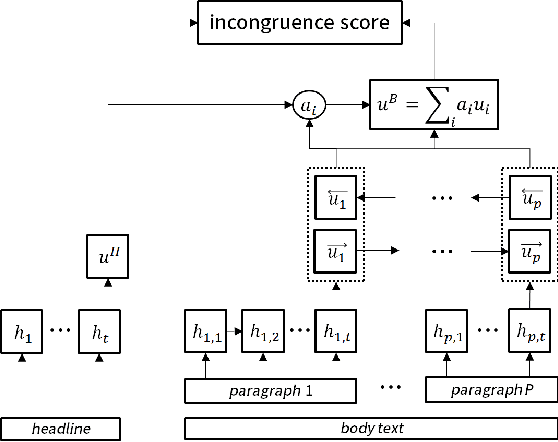
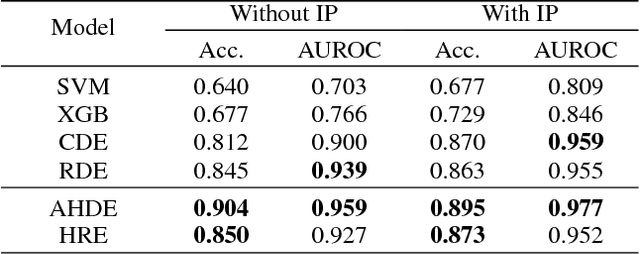
Some news headlines mislead readers with overrated or false information, and identifying them in advance will better assist readers in choosing proper news stories to consume. This research introduces million-scale pairs of news headline and body text dataset with incongruity label, which can uniquely be utilized for detecting news stories with misleading headlines. On this dataset, we develop two neural networks with hierarchical architectures that model a complex textual representation of news articles and measure the incongruity between the headline and the body text. We also present a data augmentation method that dramatically reduces the text input size a model handles by independently investigating each paragraph of news stories, which further boosts the performance. Our experiments and qualitative evaluations demonstrate that the proposed methods outperform existing approaches and efficiently detect news stories with misleading headlines in the real world.