 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRA: Adaptive Interest-aware Representation and Alignment for Personalized Multi-interest Retrieval
Apr 24, 2025



Online community platforms require dynamic personalized retrieval and recommendation that can continuously adapt to evolving user interests and new documents. However, optimizing models to handle such changes in real-time remains a major challenge in large-scale industrial settings. To address this, we propose the Interest-aware Representation and Alignment (IRA) framework, an efficient and scalable approach that dynamically adapts to new interactions through a cumulative structure. IRA leverages two key mechanisms: (1) Interest Units that capture diverse user interests as contextual texts, while reinforcing or fading over time through cumulative updates, and (2) a retrieval process that measures the relevance between Interest Units and documents based solely on semantic relationships, eliminating dependence on click signals to mitigate temporal biases. By integrating cumulative Interest Unit updates with the retrieval process, IRA continuously adapts to evolving user preferences, ensuring robust and fine-grained personalization without being constrained by past training distributions. We validate the effectiveness of IRA through extensive experiments on real-world datasets, including its deployment in the Home Section of NAVER's CAFE, South Korea's leading community platform.
On the Overlooked Significance of Underutilized Contextual Features in Recent News Recommendation Models
Dec 29, 2021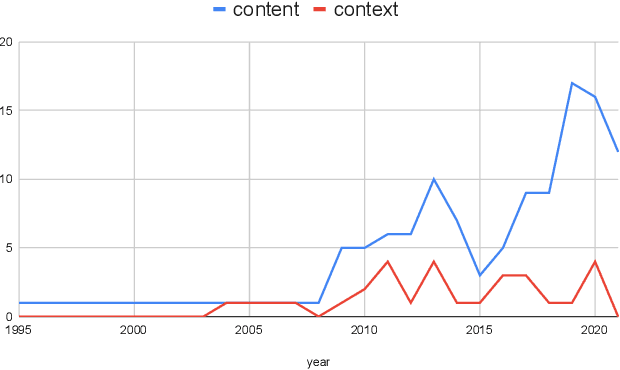
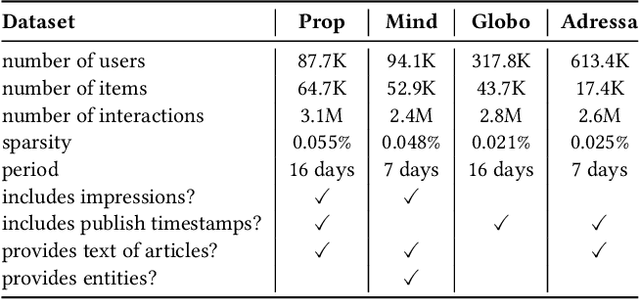
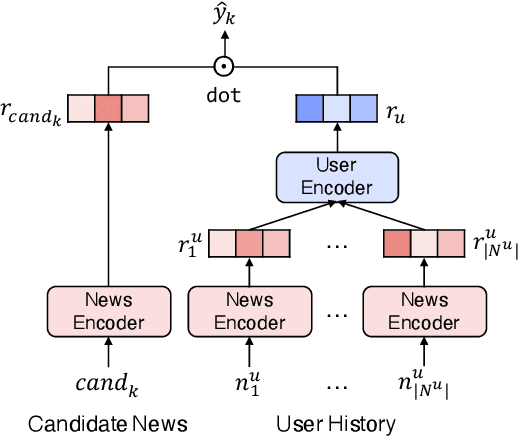
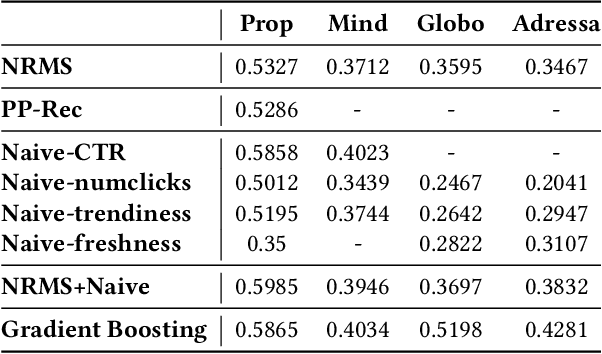
Personalized news recommendation aims to provide attractive articles for readers by predicting their likelihood of clicking on a certain article. To accurately predict this probability, plenty of studies have been proposed that actively utilize content features of articles, such as words, categories, or entities. However, we observed that the articles' contextual features, such as CTR (click-through-rate), popularity, or freshness, were either neglected or underutilized recently. To prove that this is the case, we conducted an extensive comparison between recent deep-learning models and naive contextual models that we devised and surprisingly discovered that the latter easily outperforms the former. Furthermore, our analysis showed that the recent tendency to apply overly sophisticated deep-learning operations to contextual features was actually hindering the recommendation performance. From this knowledge, we design a purposefully simple contextual module that can boost the previous news recommendation models by a large margin.
Detecting Incongruity Between News Headline and Body Text via a Deep Hierarchical Encoder
Nov 17, 2018

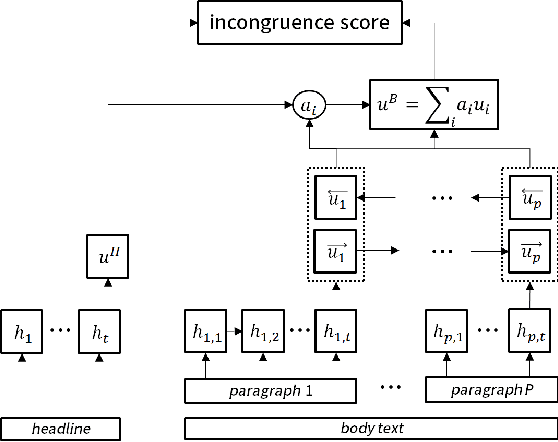
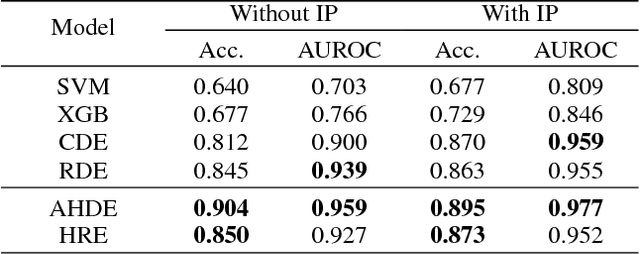
Some news headlines mislead readers with overrated or false information, and identifying them in advance will better assist readers in choosing proper news stories to consume. This research introduces million-scale pairs of news headline and body text dataset with incongruity label, which can uniquely be utilized for detecting news stories with misleading headlines. On this dataset, we develop two neural networks with hierarchical architectures that model a complex textual representation of news articles and measure the incongruity between the headline and the body text. We also present a data augmentation method that dramatically reduces the text input size a model handles by independently investigating each paragraph of news stories, which further boosts the performance. Our experiments and qualitative evaluations demonstrate that the proposed methods outperform existing approaches and efficiently detect news stories with misleading headlines in the real world.