 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Ability-Aware Adaptive Control for Multi-robot Collaborative Manipulation
Feb 07, 2021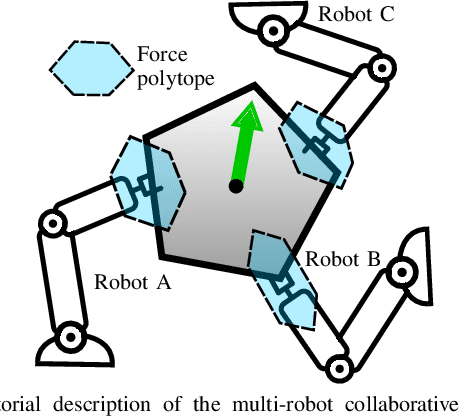
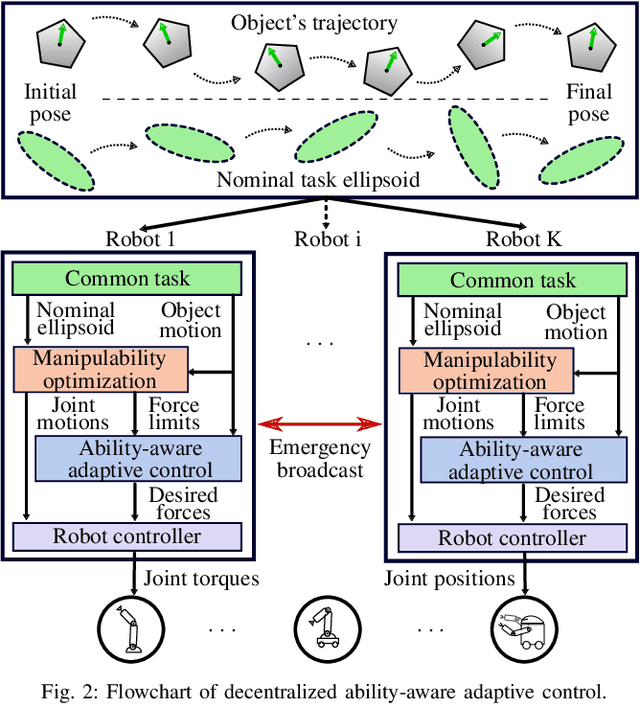
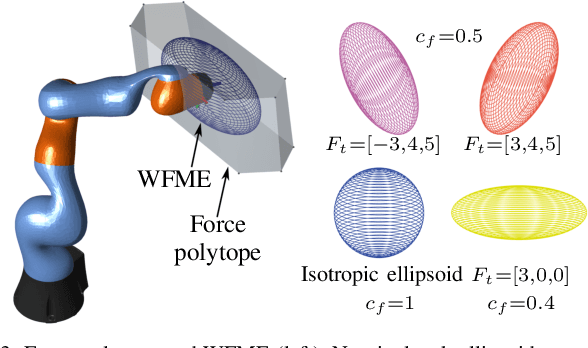
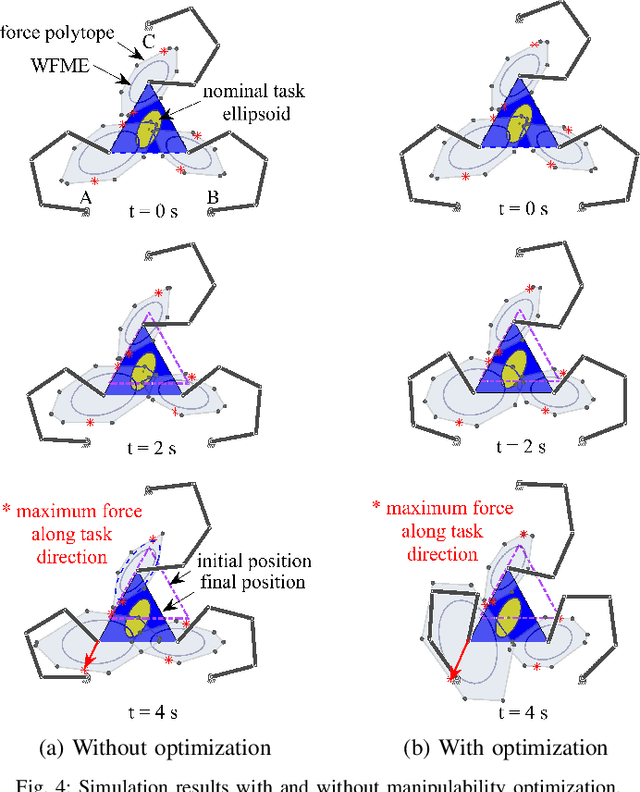
Multi-robot teams can achieve more dexterous, complex and heavier payload tasks than a single robot, yet effective collaboration is required. Multi-robot collaboration is extremely challenging due to the different kinematic and dynamics capabilities of the robots, the limited communication between them, and the uncertainty of the system parameters. In this paper, a Decentralized Ability-Aware Adaptive Control is proposed to address these challenges based on two key features. Firstly, the common manipulation task is represented by the proposed nominal task ellipsoid, which is used to maximize each robot force capability online via optimizing its configuration. Secondly, a decentralized adaptive controller is designed to be Lyapunov stable in spite of heterogeneous actuation constraints of the robots and uncertain physical parameters of the object and environment. In the proposed framework, decentralized coordination and load distribution between the robots is achieved without communication, while only the control deficiency is broadcast if any of the robots reaches its force limits. In this case, the object reference trajectory is modified in a decentralized manner to guarantee stable interaction. Finally, we perform several numerical and physical simulations to analyse and verify the proposed method with heterogeneous multi-robot teams in collaborative manipulation tasks.
Sparsity-Inducing Optimal Control via Differential Dynamic Programming
Nov 14, 2020
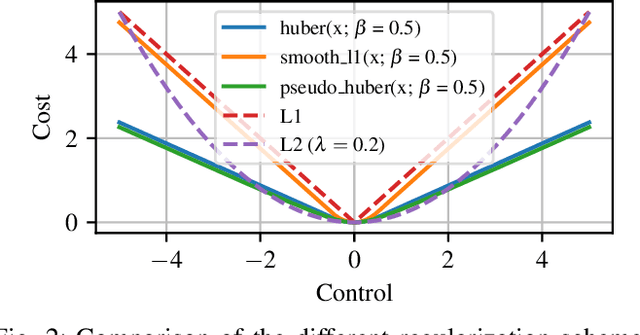

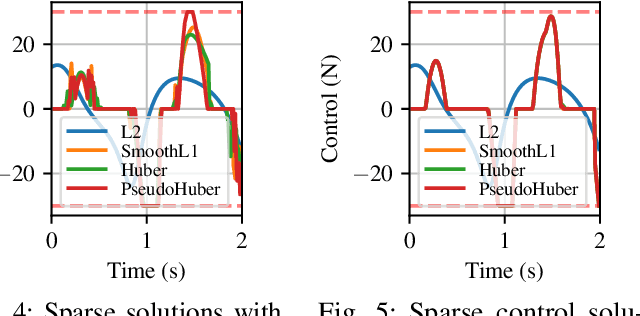
Optimal control is a popular approach to synthesize highly dynamic motion. Commonly, L2 regularization is used on the control inputs in order to minimize energy used and to ensure smoothness of the control inputs. However, for some systems, such as satellites, the control needs to be applied in sparse bursts due to how the propulsion system operates. In this paper, we study approaches to induce sparsity in optimal control solutions---namely via smooth L1 and Huber regularization penalties. We apply these loss terms to state-of-the-art Differential Dynamic Programming (DDP)-based solvers to create a family of sparsity-inducing optimal control methods. We analyze and compare the effect of the different losses on inducing sparsity, their numerical conditioning, their impact on convergence, and discuss hyperparameter settings. We demonstrate our method in simulation and hardware experiments on canonical dynamics systems, control of satellites, and the NASA Valkyrie humanoid robot. We provide an implementation of our method and all examples for reproducibility on GitHub.
A Passive Navigation Planning Algorithm for Collision-free Control of Mobile Robots
Nov 01, 2020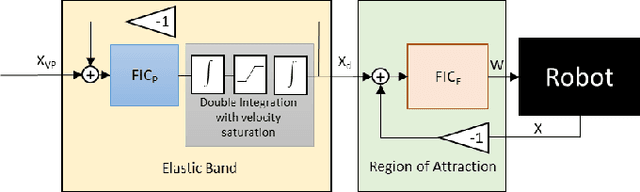
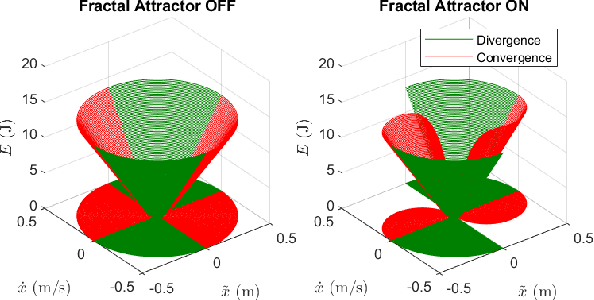
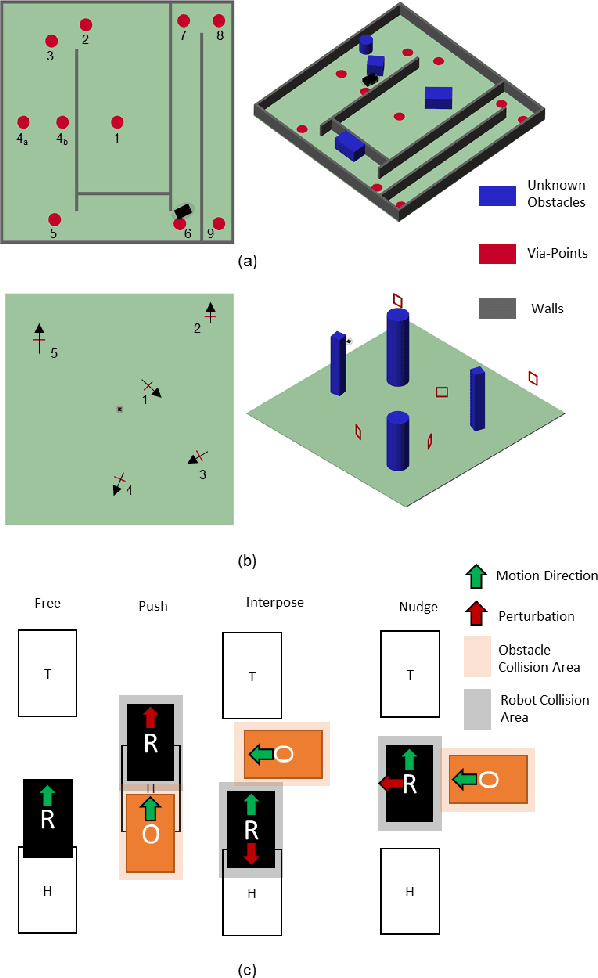
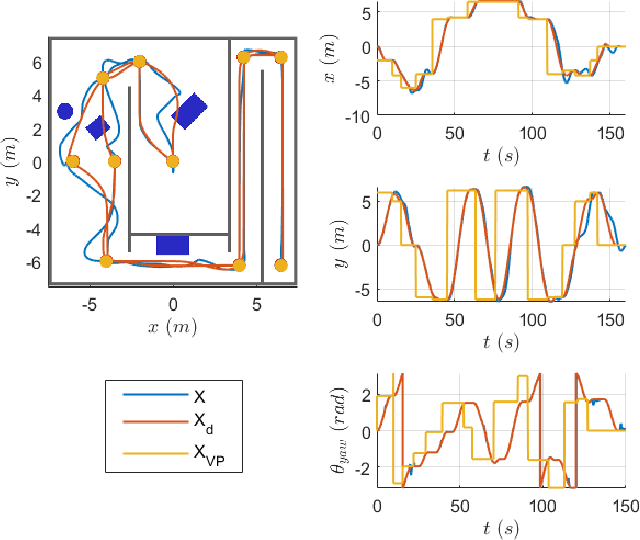
Path planning and collision avoidance are challenging in complex and highly variable environments due to the limited horizon of events. In literature, there are multiple model- and learning-based approaches that require significant computational resources to be effectively deployed and they may have limited generality. We propose a planning algorithm based on a globally stable passive controller that can plan smooth trajectories using limited computational resources in challenging environmental conditions. The architecture combines the recently proposed fractal impedance controller with elastic bands and regions of finite time invariance. As the method is based on an impedance controller, it can also be used directly as a force/torque controller. We validated our method in simulation to analyse the ability of interactive navigation in challenging concave domains via the issuing of via-points, and its robustness to low bandwidth feedback. A swarm simulation using 11 agents validated the scalability of the proposed method. We have performed hardware experiments on a holonomic wheeled platform validating smoothness and robustness of interaction with dynamic agents (i.e., humans and robots). The computational complexity of the proposed local planner enables deployment with low-power micro-controllers lowering the energy consumption compared to other methods that rely upon numeric optimisation.
Robust Planning and Control for Dynamic Quadrupedal Locomotion with Adaptive Feet
Oct 23, 2020

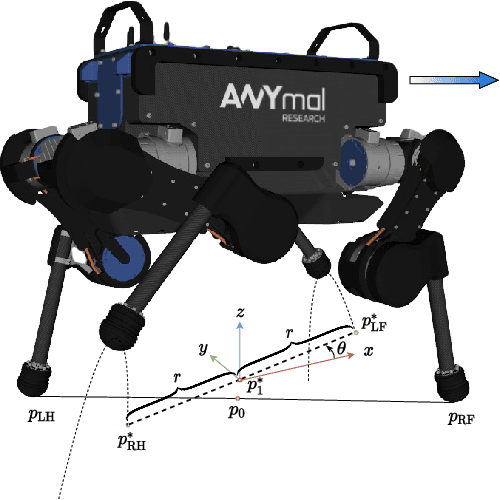
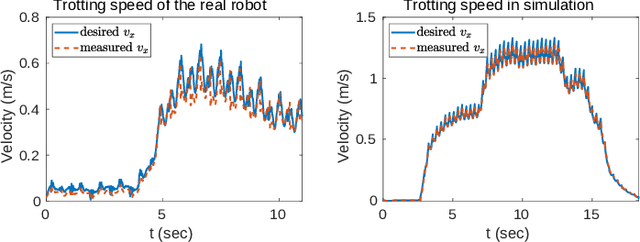
In this paper, we aim to improve the robustness of dynamic quadrupedal locomotion through three aspects: 1) fast model predictive foothold planning, 2) LQR control for robust motion tracking and 3) adaptive feet for terrain adaptation. In our proposed planning and control framework, foothold plans are updated at 400 Hz considering the current robot state and an LQR controller generates optimal feedback gains for motion tracking. The LQR optimal gain matrix with non-zero off-diagonal elements leverages the coupling of dynamics to compensate for system underactuation, such as a quadruped robot with passive ankles. The specially designed foot with adaptive sole aims at improving the traversability of rough terrains with rocks, loose gravel and rubble by enlarging the contact surfaces with ground. Experiments on the quadruped ANYmal demonstrate the effectiveness of the proposed method for robust dynamic locomotion given external disturbances and environmental uncertainties.
RigidFusion: Robot Localisation and Mapping in Environments with Large Dynamic Rigid Objects
Oct 21, 2020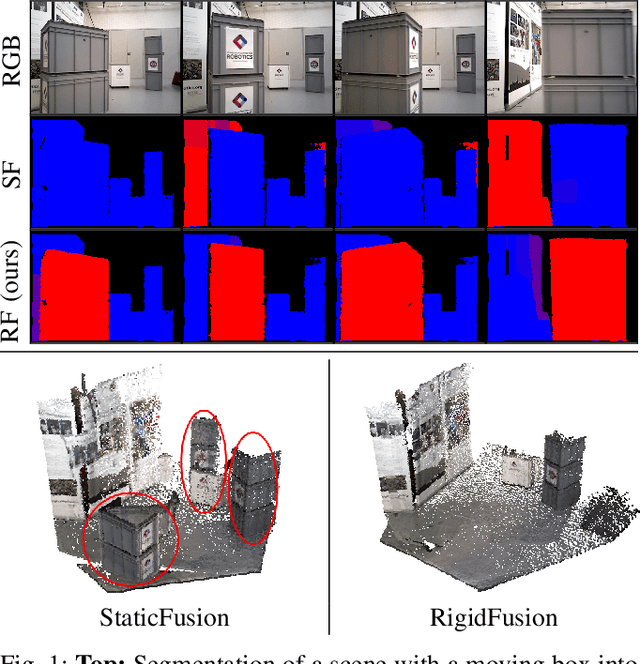

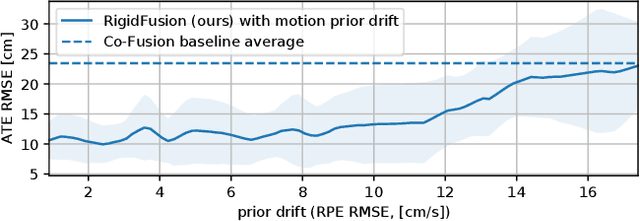
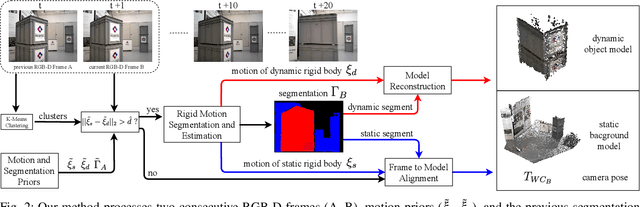
This work presents a novel approach to simultaneously track a robot with respect to multiple rigid entities, including the environment and additional dynamic objects in a scene. Previous approaches treat dynamic parts of a scene as outliers and are thus limited to small amount of dynamics, or rely on prior information for all objects in the scene to enable robust camera tracking. Here, we propose to formulate localisation and object tracking as the same underlying problem and simultaneously track multiple rigid transformations, therefore enabling simultaneous localisation and object tracking for mobile manipulators in dynamic scenes. We evaluate our approach on multiple challenging dynamic scenes with large occlusions. The evaluation demonstrates that our approach achieves better scene segmentation and camera pose tracking in highly dynamic scenes without requiring knowledge of the dynamic object's appearance.
Inverse Dynamics vs. Forward Dynamics in Direct Transcription Formulations for Trajectory Optimization
Oct 11, 2020

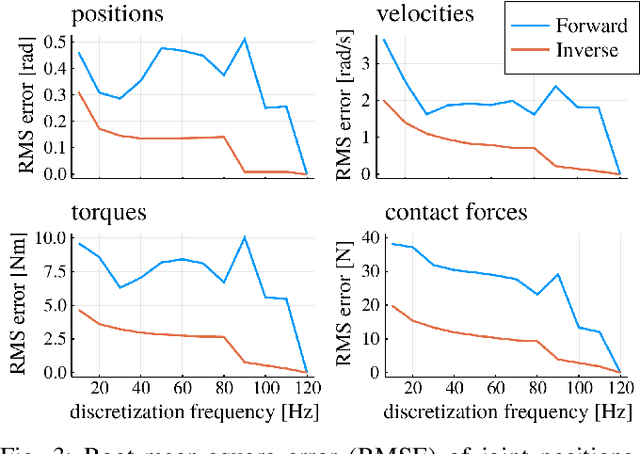

Benchmarks of state-of-the-art rigid-body dynamics libraries have reported better performance for solving the inverse dynamics problem than the forward alternative. Those benchmarks encouraged us to question whether this computational advantage translates to direct transcription formulations, where calculating the rigid-body dynamics and their derivatives often accounts for a significant share of computation time. In this work, we implement an optimization framework where both approaches for enforcing the system dynamics are available. We evaluate the performance of each approach for systems of varying complexity, and for domains with rigid contacts. Our tests revealed that formulations employing inverse dynamics converge faster, require less iterations, and are more robust to coarse problem discretization. These results suggest that inverse dynamics should be the preferred approach to enforce nonlinear system dynamics in simultaneous methods, such as direct transcription.
Memory Clustering using Persistent Homology for Multimodality- and Discontinuity-Sensitive Learning of Optimal Control Warm-starts
Oct 02, 2020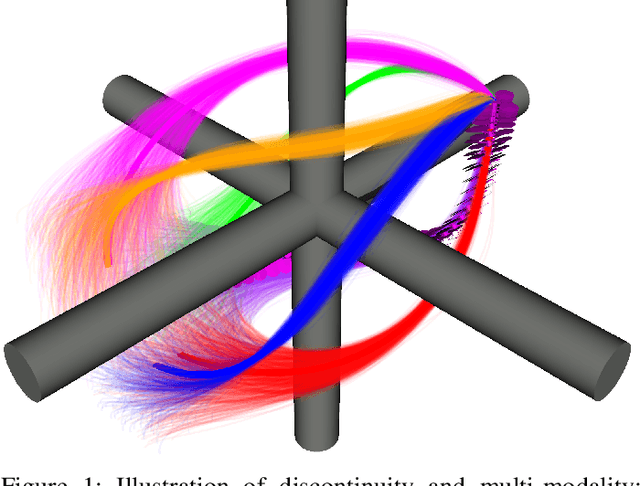
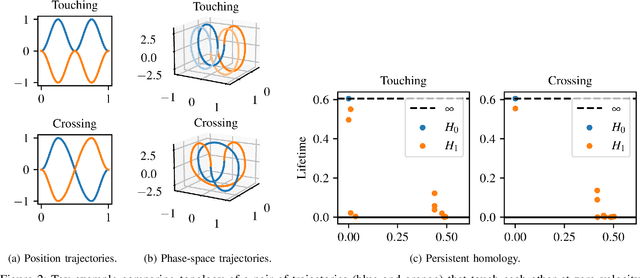
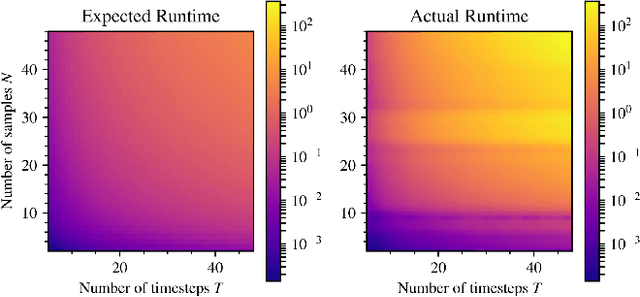

Shooting methods are an efficient approach to solving nonlinear optimal control problems. As they use local optimization, they exhibit favorable convergence when initialized with a good warm-start but may not converge at all if provided with a poor initial guess. Recent work has focused on providing an initial guess from a learned model trained on samples generated during an offline exploration of the problem space. However, in practice the solutions contain discontinuities introduced by system dynamics or the environment. Additionally, in many cases multiple equally suitable, i.e., multi-modal, solutions exist to solve a problem. Classic learning approaches smooth across the boundary of these discontinuities and thus generalize poorly. In this work, we apply tools from algebraic topology to extract information on the underlying structure of the solution space. In particular, we introduce a method based on persistent homology to automatically cluster the dataset of precomputed solutions to obtain different candidate initial guesses. We then train a Mixture-of-Experts within each cluster to predict initial guesses and provide a comparison with modality-agnostic learning. We demonstrate our method on a cart-pole toy problem and a quadrotor avoiding obstacles, and show that clustering samples based on inherent structure improves the warm-start quality.
A Direct-Indirect Hybridization Approach to Control-Limited DDP
Oct 01, 2020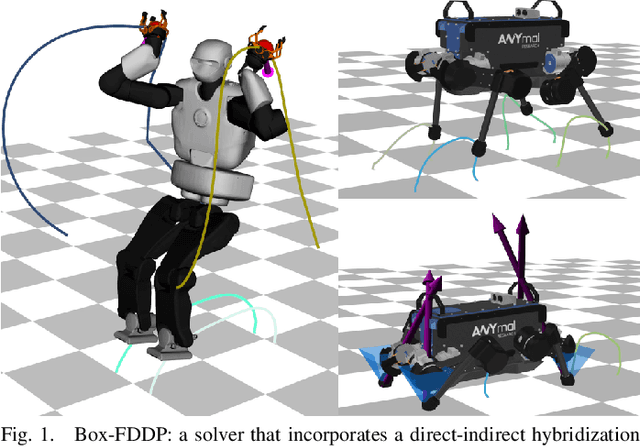

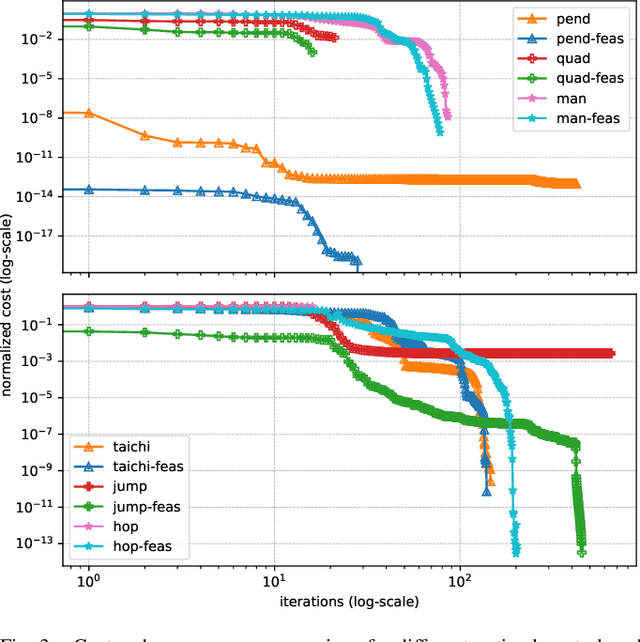
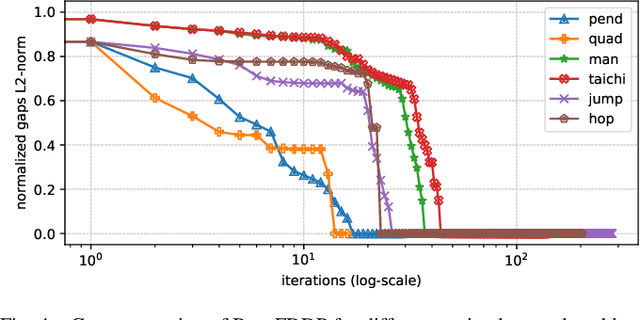
Optimal control is a widely used tool for synthesizing motions and controls for user-defined tasks under physical constraints. A common approach is to formulate it using direct multiple-shooting and then to use off-the-shelf nonlinear programming solvers that can easily handle arbitrary constraints on the controls and states. However, these methods are not fast enough for many robotics applications such as real-time humanoid motor control. Exploiting the sparse structure of optimal control problem, such as in Differential DynamicProgramming (DDP), has proven to significantly boost the computational efficiency, and recent works have been focused on handling arbitrary constraints. Despite that, DDP has been associated with poor numerical convergence, particularly when considering long time horizons. One of the main reasons is due to system instabilities and poor warm-starting (only controls). This paper presents control-limited Feasibility-driven DDP (Box-FDDP), a solver that incorporates a direct-indirect hybridization of the control-limited DDP algorithm. Concretely, the forward and backward passes handle feasibility and control limits. We showcase the impact and importance of our method on a set of challenging optimal control problems against the Box-DDP and squashing-function approach.
Multi-modal Trajectory Optimization for Impact-aware Manipulation
Jun 23, 2020
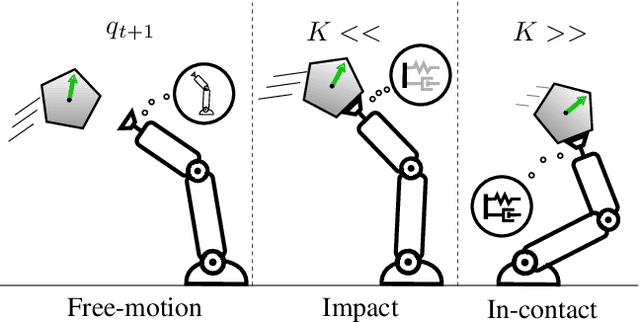
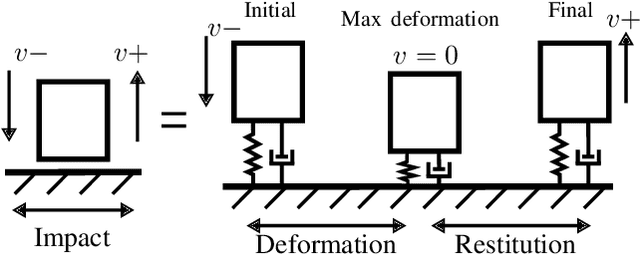

The transition from free motion to contact is a challenging problem in robotics, in part due to its hybrid nature. Yet, disregarding the effects of impacts at the motion planning level might result in intractable impulsive contact forces. In this paper, we introduce an impact-aware multi-modal trajectory optimization (TO) method that comprises both hybrid dynamics and hybrid control in a coherent fashion. A key concept is the incorporation of an explicit contact force transmission model in the TO method. This allows the simultaneous optimization of the contact forces, contact timings, continuous motion trajectories and compliance, while satisfying task constraints. We compare our method against standard compliance control and an impact-agnostic TO method in physical simulations. Further, we experimentally validate the proposed method with a robot manipulator on the task of halting a large-momentum object.
Variable Autonomy of Whole-body Control for Inspection and Intervention in Industrial Environments using Legged Robots
Apr 06, 2020
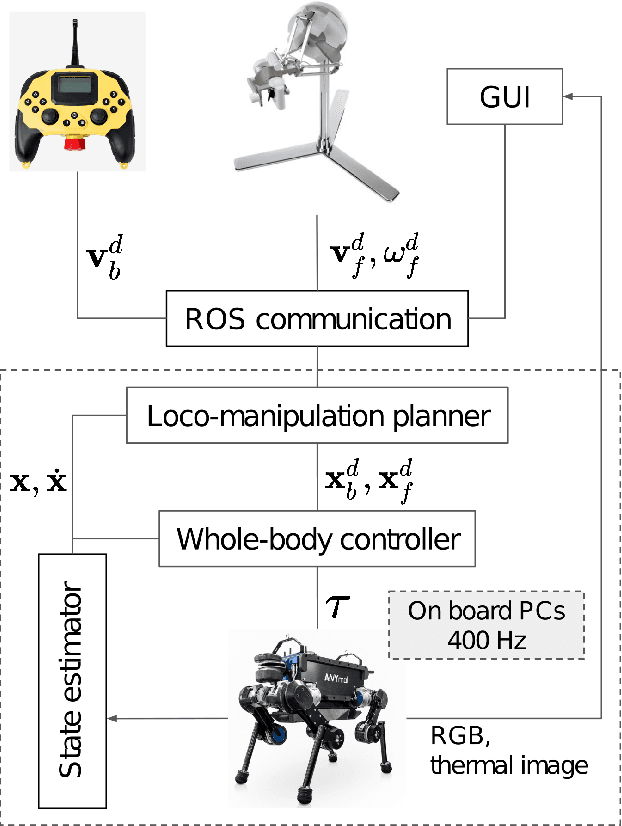
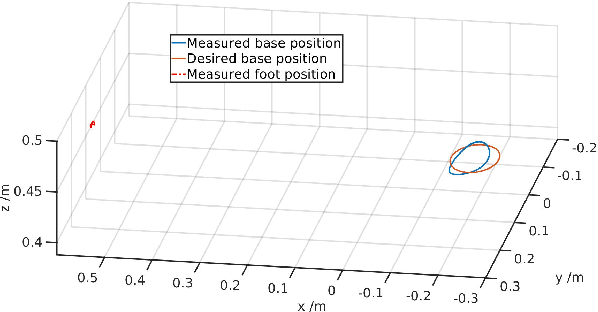
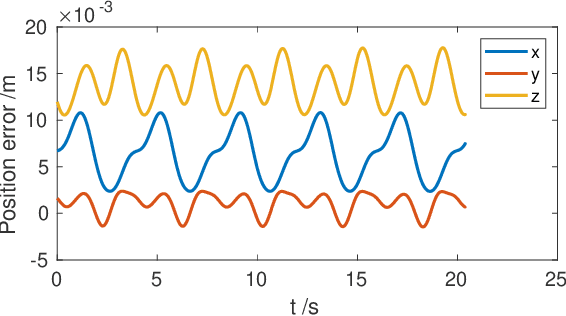
The deployment of robots in industrial and civil scenarios is a viable solution to protect operators from danger and hazards. Shared autonomy is paramount to enable remote control of complex systems such as legged robots, allowing the operator to focus on the essential tasks instead of overly detailed execution. To realize this, we proposed a comprehensive control framework for inspection and intervention using a legged robot and validated the integration of multiple loco-manipulation algorithms optimised for improving the remote operation. The proposed control offers 3 operation modes: fully automated, semi-autonomous, and the haptic interface receiving onsite physical interaction for assisting teleoperation. Our contribution is the design of a QP-based semi-analytical whole-body control, which is the key to the various task completion subject to internal and external constraints. We demonstrated the versatility of the whole-body control in terms of decoupling tasks, singularity toleration and constraint satisfaction. We deployed our solution in field trials and evaluated in an emergency setting by an E-stop while the robot was clearing road barrier and traversing difficult terrains.