 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Where Visual Understanding Meets Text-to-Image Generation
Mar 03, 2026Unifying visual representation learning and text-to-image (T2I) generation within a single model remains a central challenge in multimodal learning. We introduce DREAM, a unified framework that jointly optimizes discriminative and generative objectives, while learning strong visual representations. DREAM is built on two key techniques: During training, Masking Warmup, a progressive masking schedule, begins with minimal masking to establish the contrastive alignment necessary for representation learning, then gradually transitions to full masking for stable generative training. At inference, DREAM employs Semantically Aligned Decoding to align partially masked image candidates with the target text and select the best one for further decoding, improving text-image fidelity (+6.3%) without external rerankers. Trained solely on CC12M, DREAM achieves 72.7% ImageNet linear-probing accuracy (+1.1% over CLIP) and an FID of 4.25 (+6.2% over FLUID), with consistent gains in few-shot classification, semantic segmentation, and depth estimation. These results demonstrate that discriminative and generative objectives can be synergistic, allowing unified multimodal models that excel at both visual understanding and generation.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
Using Deep Learning-based Features Extracted from CT scans to Predict Outcomes in COVID-19 Patients
May 10, 2022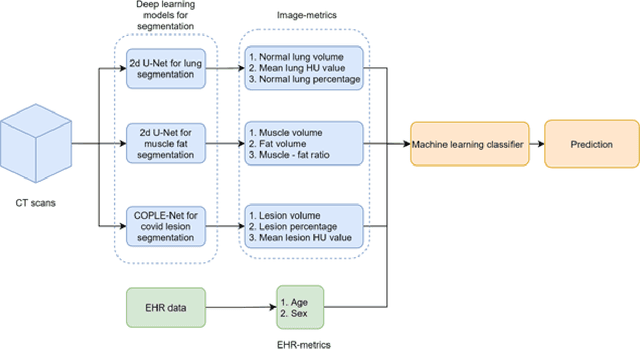

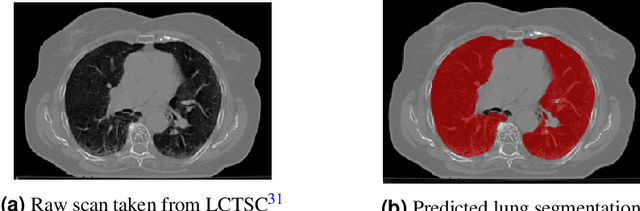
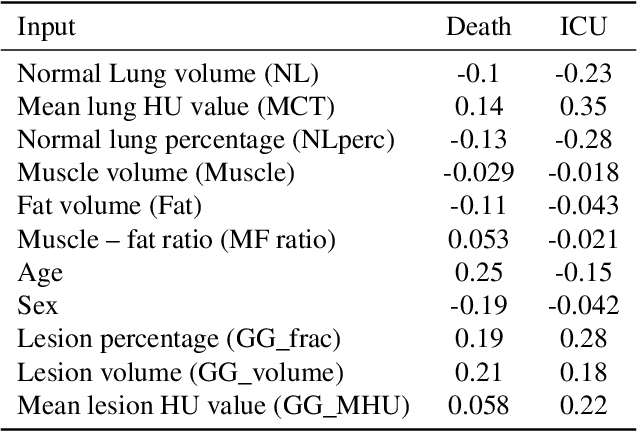
The COVID-19 pandemic has had a considerable impact on day-to-day life. Tackling the disease by providing the necessary resources to the affected is of paramount importance. However, estimation of the required resources is not a trivial task given the number of factors which determine the requirement. This issue can be addressed by predicting the probability that an infected patient requires Intensive Care Unit (ICU) support and the importance of each of the factors that influence it. Moreover, to assist the doctors in determining the patients at high risk of fatality, the probability of death is also calculated. For determining both the patient outcomes (ICU admission and death), a novel methodology is proposed by combining multi-modal features, extracted from Computed Tomography (CT) scans and Electronic Health Record (EHR) data. Deep learning models are leveraged to extract quantitative features from CT scans. These features combined with those directly read from the EHR database are fed into machine learning models to eventually output the probabilities of patient outcomes. This work demonstrates both the ability to apply a broad set of deep learning methods for general quantification of Chest CT scans and the ability to link these quantitative metrics to patient outcomes. The effectiveness of the proposed method is shown by testing it on an internally curated dataset, achieving a mean area under Receiver operating characteristic curve (AUC) of 0.77 on ICU admission prediction and a mean AUC of 0.73 on death prediction using the best performing classifiers.
Multi-Domain Few-Shot Learning and Dataset for Agricultural Applications
Sep 21, 2021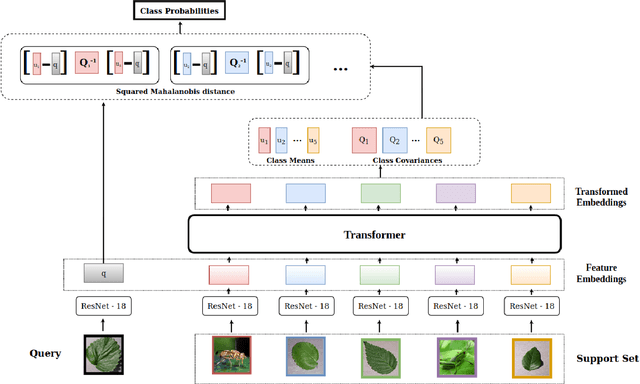
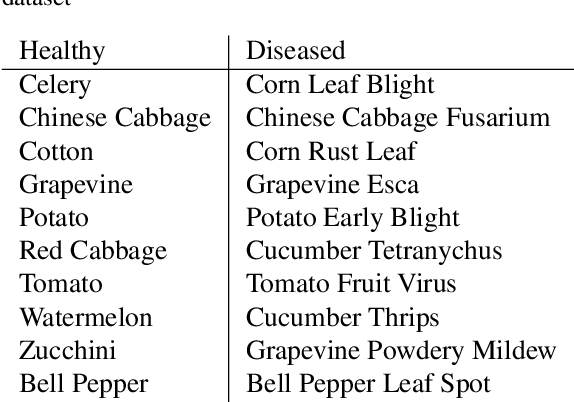

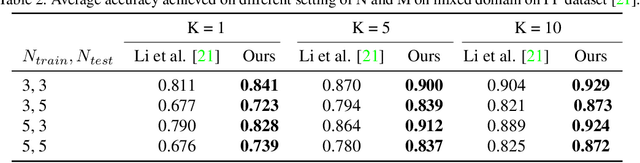
Automatic classification of pests and plants (both healthy and diseased) is of paramount importance in agriculture to improve yield. Conventional deep learning models based on convolutional neural networks require thousands of labeled examples per category. In this work we propose a method to learn from a few samples to automatically classify different pests, plants, and their diseases, using Few-Shot Learning (FSL). We learn a feature extractor to generate embeddings and then update the embeddings using Transformers. Using Mahalanobis distance, a class-covariance-based metric, we then calculate the similarity of the transformed embeddings with the embedding of the image to be classified. Using our proposed architecture, we conduct extensive experiments on multiple datasets showing the effectiveness of our proposed model. We conduct 42 experiments in total to comprehensively analyze the model and it achieves up to 14% and 24% performance gains on few-shot image classification benchmarks on two datasets. We also compile a new FSL dataset containing images of healthy and diseased plants taken in real-world settings. Using our proposed architecture which has been shown to outperform several existing FSL architectures in agriculture, we provide strong baselines on our newly proposed dataset.
Pose-based Sign Language Recognition using GCN and BERT
Dec 01, 2020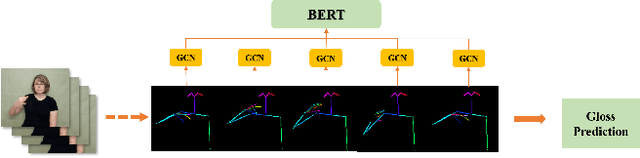
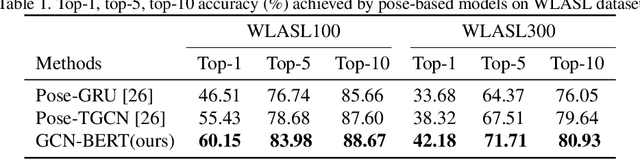
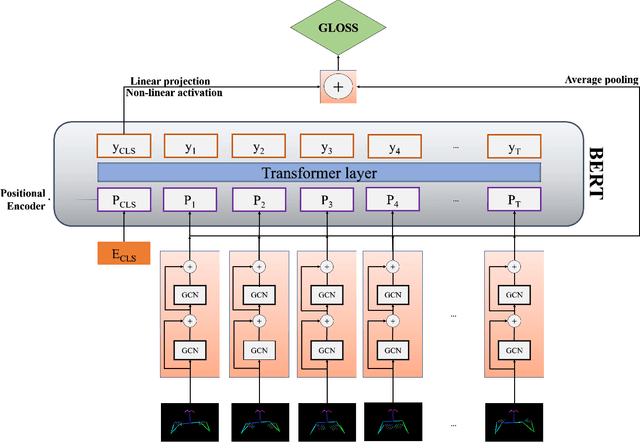

Sign language recognition (SLR) plays a crucial role in bridging the communication gap between the hearing and vocally impaired community and the rest of the society. Word-level sign language recognition (WSLR) is the first important step towards understanding and interpreting sign language. However, recognizing signs from videos is a challenging task as the meaning of a word depends on a combination of subtle body motions, hand configurations, and other movements. Recent pose-based architectures for WSLR either model both the spatial and temporal dependencies among the poses in different frames simultaneously or only model the temporal information without fully utilizing the spatial information. We tackle the problem of WSLR using a novel pose-based approach, which captures spatial and temporal information separately and performs late fusion. Our proposed architecture explicitly captures the spatial interactions in the video using a Graph Convolutional Network (GCN). The temporal dependencies between the frames are captured using Bidirectional Encoder Representations from Transformers (BERT). Experimental results on WLASL, a standard word-level sign language recognition dataset show that our model significantly outperforms the state-of-the-art on pose-based methods by achieving an improvement in the prediction accuracy by up to 5%.