 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Physical Interaction with Deformable Linear Objects
May 17, 2022

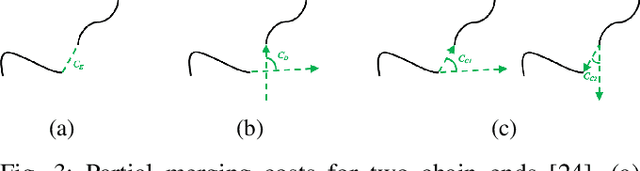
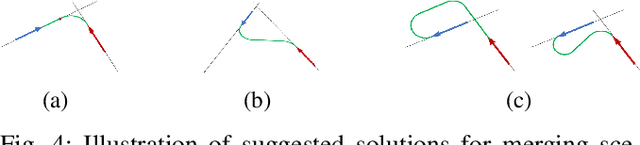
Deformable linear objects (e.g., cables, ropes, and threads) commonly appear in our everyday lives. However, perception of these objects and the study of physical interaction with them is still a growing area. There have already been successful methods to model and track deformable linear objects. However, the number of methods that can automatically extract the initial conditions in non-trivial situations for these methods has been limited, and they have been introduced to the community only recently. On the other hand, while physical interaction with these objects has been done with ground manipulators, there have not been any studies on physical interaction and manipulation of the deformable linear object with aerial robots. This workshop describes our recent work on detecting deformable linear objects, which uses the segmentation output of the existing methods to provide the initialization required by the tracking methods automatically. It works with crossings and can fill the gaps and occlusions in the segmentation and output the model desirable for physical interaction and simulation. Then we present our work on using the method for tasks such as routing and manipulation with the ground and aerial robots. We discuss our feasibility analysis on extending the physical interaction with these objects to aerial manipulation applications.
Design, Modeling and Control for a Tilt-rotor VTOL UAV in the Presence of Actuator Failure
May 11, 2022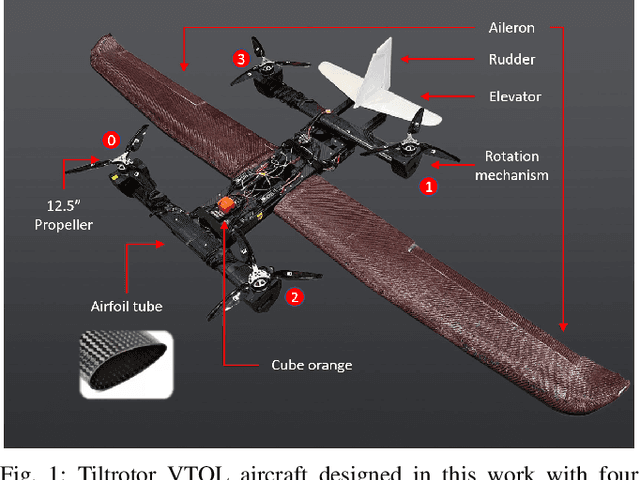
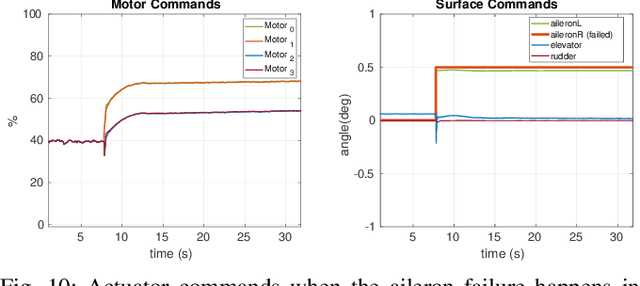

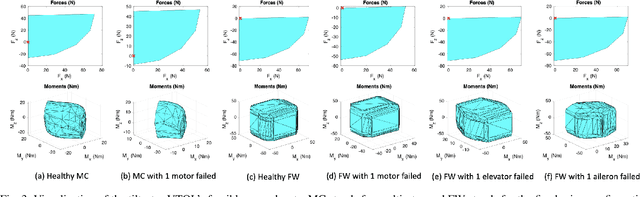
Providing both the vertical take-off and landing capabilities and the ability to fly long distances to aircraft opens the door to a wide range of new real-world aircraft applications while improving many existing applications. Tiltrotor vertical take-off and landing (VTOL) unmanned aerial vehicles (UAVs) are a better choice than fixed-wing and multirotor aircraft for such applications. Prior work on these aircraft has addressed the aerodynamic performance, design, modeling, and control. However, a less explored area is the study of their potential fault tolerance due to their inherent redundancy, which allows them to sustain some degree of actuator failure. This work introduces tolerance to several types of actuator failures in a tiltrotor VTOL aircraft. We discuss the design and model of a custom tiltrotor VTOL UAV, which is a combination of a fixed-wing aircraft and a quadrotor with tilting rotors, where the four propellers can be rotated individually. Then, we analyze the feasible wrench space the vehicle can generate and design the dynamic control allocation so that the system can adapt to actuator failure, benefiting from the configuration redundancy. The proposed approach is lightweight and is implemented as an extension to an already existing flight control stack. Extensive experiments are performed to validate that the system can maintain the controlled flight under different actuator failures. To the best of our knowledge, this work is the first study of the tiltrotor VTOL's fault-tolerance that exploits the configuration redundancy.
TartanDrive: A Large-Scale Dataset for Learning Off-Road Dynamics Models
May 03, 2022
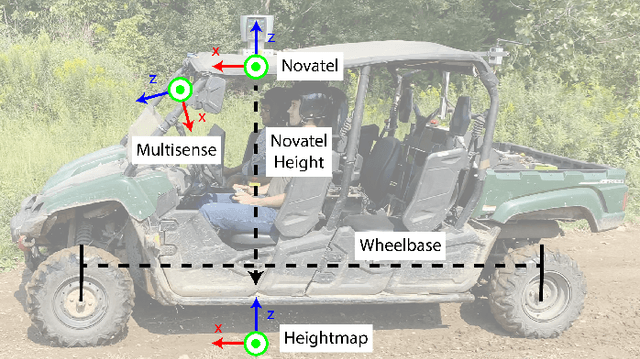
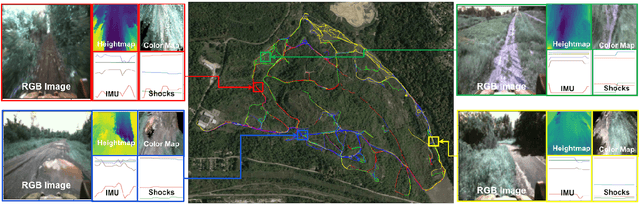
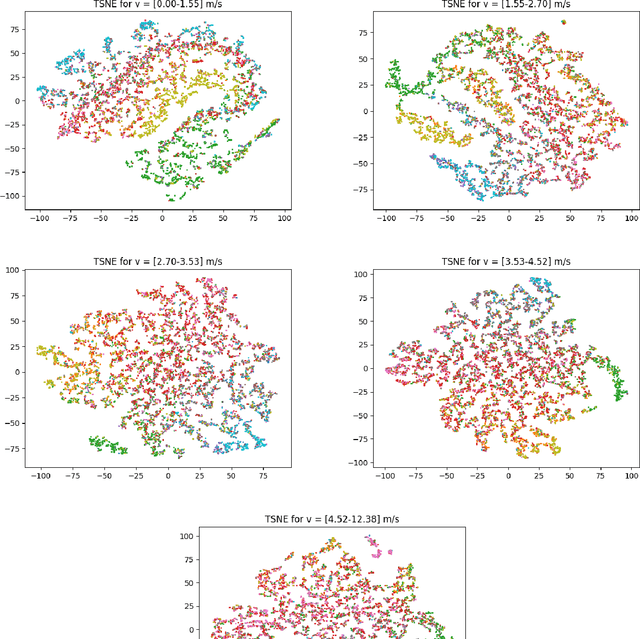
We present TartanDrive, a large scale dataset for learning dynamics models for off-road driving. We collected a dataset of roughly 200,000 off-road driving interactions on a modified Yamaha Viking ATV with seven unique sensing modalities in diverse terrains. To the authors' knowledge, this is the largest real-world multi-modal off-road driving dataset, both in terms of number of interactions and sensing modalities. We also benchmark several state-of-the-art methods for model-based reinforcement learning from high-dimensional observations on this dataset. We find that extending these models to multi-modality leads to significant performance on off-road dynamics prediction, especially in more challenging terrains. We also identify some shortcomings with current neural network architectures for the off-road driving task. Our dataset is available at https://github.com/castacks/tartan_drive.
Learning and Transferring Value Function for Robot Exploration in Subterranean Environments
Apr 07, 2022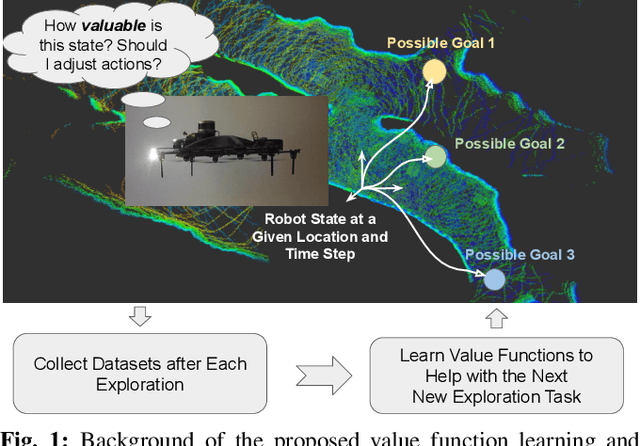
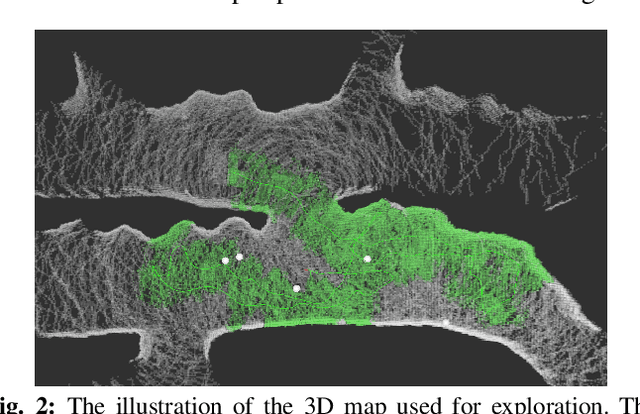

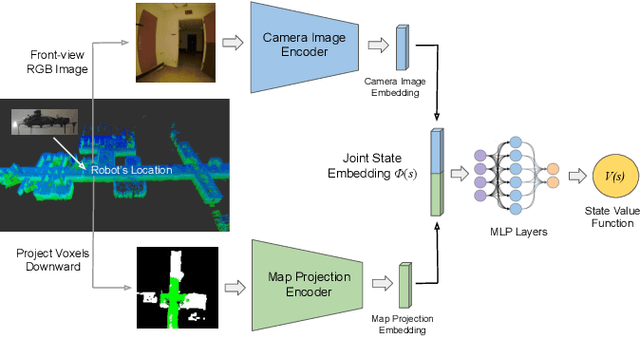
In traditional robot exploration methods, the robot usually does not have prior biases about the environment it is exploring. Thus the robot assigns equal importance to the goals which leads to insufficient exploration efficiency. Alternative, often a hand-tuned policy is used to tweak the value of goals. In this paper, we present a method to learn how "good" some states are, measured by the state value function, to provide a hint for the robot to make exploration decisions. We propose to learn state value functions from previous offline collected datasets and then transfer and improve the value function during testing in a new environment. Moreover, the environments usually have very few and even no extrinsic reward or feedback for the robot. Therefore in this work, we also tackle the problem of sparse extrinsic rewards from the environments. We design several intrinsic rewards to encourage the robot to obtain more information during exploration. These reward functions then become the building blocks of the state value functions. We test our method on challenging subterranean and urban environments. To the best of our knowledge, this work for the first time demonstrates value function prediction with previous collected datasets to help exploration in challenging subterranean environments.
TIGRIS: An Informed Sampling-based Algorithm for Informative Path Planning
Mar 24, 2022
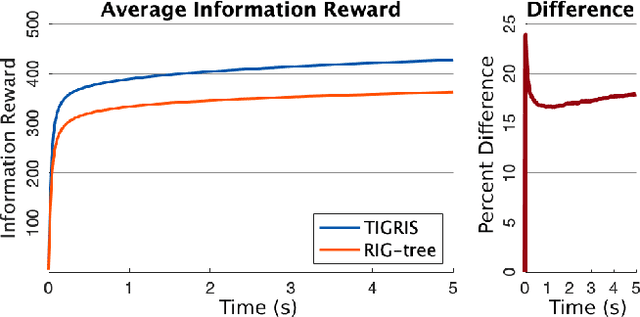
Informative path planning is an important and challenging problem in robotics that remains to be solved in a manner that allows for wide-spread implementation and real-world practical adoption. Among various reasons for this, one is the lack of approaches that allow for informative path planning in high-dimensional spaces and non-trivial sensor constraints. In this work we present a sampling-based approach that allows us to tackle the challenges of large and high-dimensional search spaces. This is done by performing informed sampling in the high-dimensional continuous space and incorporating potential information gain along edges in the reward estimation. This method rapidly generates a global path that maximizes information gain for the given path budget constraints. We discuss the details of our implementation for an example use case of searching for multiple objects of interest in a large search space using a fixed-wing UAV with a forward-facing camera. We compare our approach to a sampling-based planner baseline and demonstrate how our contributions allow our approach to consistently out-perform the baseline by $18.0\%$. With this we thus present a practical and generalizable informative path planning framework that can be used for very large environments, limited budgets, and high dimensional search spaces, such as robots with motion constraints or high-dimensional configuration spaces.
AirDet: Few-Shot Detection without Fine-tuning for Autonomous Exploration
Dec 03, 2021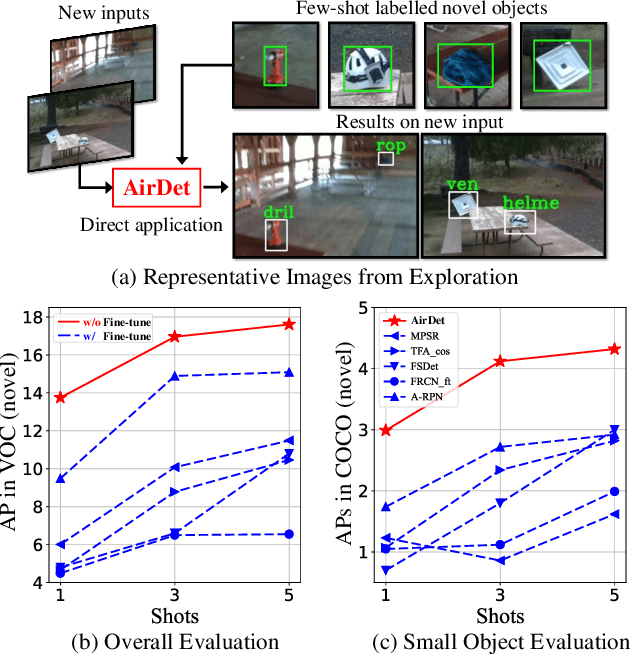
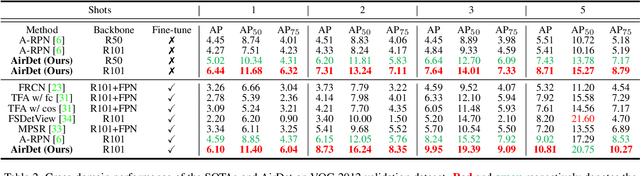
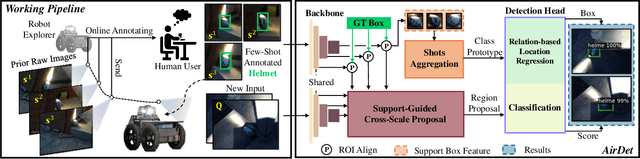
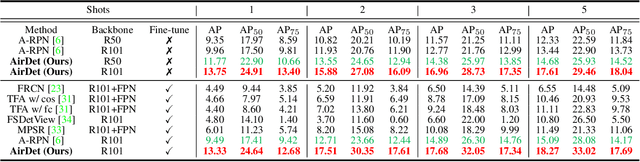
Few-shot object detection has rapidly progressed owing to the success of meta-learning strategies. However, the requirement of a fine-tuning stage in existing methods is timeconsuming and significantly hinders their usage in real-time applications such as autonomous exploration of low-power robots. To solve this problem, we present a brand new architecture, AirDet, which is free of fine-tuning by learning class agnostic relation with support images. Specifically, we propose a support-guided cross-scale (SCS) feature fusion network to generate object proposals, a global-local relation network (GLR) for shots aggregation, and a relation-based prototype embedding network (R-PEN) for precise localization. Exhaustive experiments are conducted on COCO and PASCAL VOC datasets, where surprisingly, AirDet achieves comparable or even better results than the exhaustively finetuned methods, reaching up to 40-60% improvements on the baseline. To our excitement, AirDet obtains favorable performance on multi-scale objects, especially the small ones. Furthermore, we present evaluation results on real-world exploration tests from the DARPA Subterranean Challenge, which strongly validate the feasibility of AirDet in robotics. The source code, pre-trained models, along with the real world data for exploration, will be made public.
AirObject: A Temporally Evolving Graph Embedding for Object Identification
Nov 30, 2021
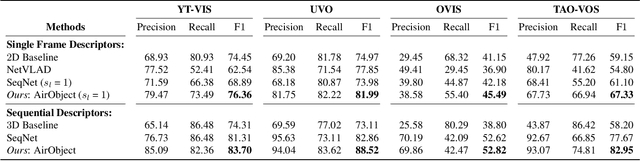
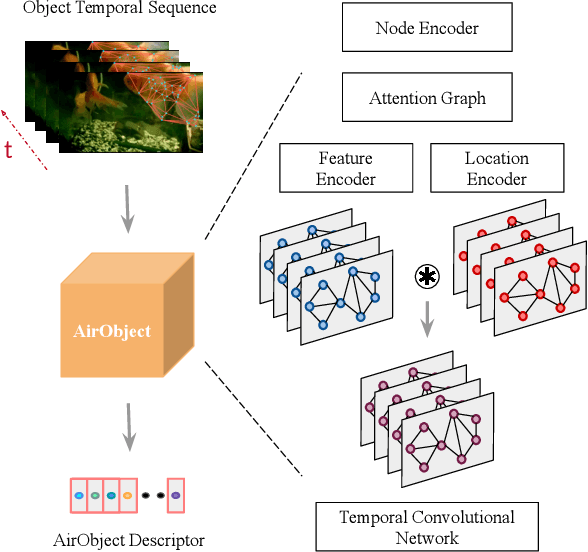
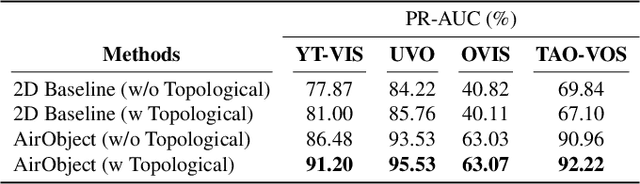
Object encoding and identification are vital for robotic tasks such as autonomous exploration, semantic scene understanding, and re-localization. Previous approaches have attempted to either track objects or generate descriptors for object identification. However, such systems are limited to a "fixed" partial object representation from a single viewpoint. In a robot exploration setup, there is a requirement for a temporally "evolving" global object representation built as the robot observes the object from multiple viewpoints. Furthermore, given the vast distribution of unknown novel objects in the real world, the object identification process must be class-agnostic. In this context, we propose a novel temporal 3D object encoding approach, dubbed AirObject, to obtain global keypoint graph-based embeddings of objects. Specifically, the global 3D object embeddings are generated using a temporal convolutional network across structural information of multiple frames obtained from a graph attention-based encoding method. We demonstrate that AirObject achieves the state-of-the-art performance for video object identification and is robust to severe occlusion, perceptual aliasing, viewpoint shift, deformation, and scale transform, outperforming the state-of-the-art single-frame and sequential descriptors. To the best of our knowledge, AirObject is one of the first temporal object encoding methods.
Semantically Consistent Image-to-Image Translation for Unsupervised Domain Adaptation
Nov 25, 2021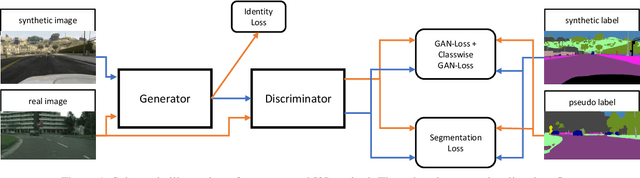
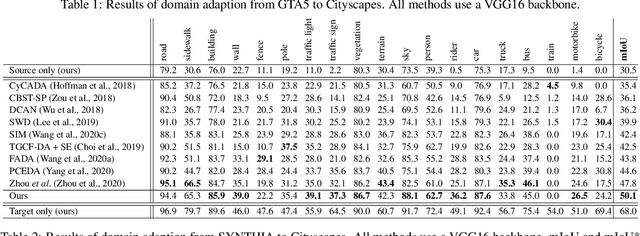
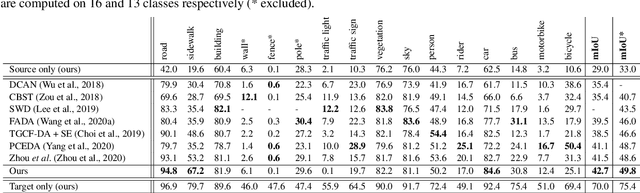

Unsupervised Domain Adaptation (UDA) aims to adapt models trained on a source domain to a new target domain where no labelled data is available. In this work, we investigate the problem of UDA from a synthetic computer-generated domain to a similar but real-world domain for learning semantic segmentation. We propose a semantically consistent image-to-image translation method in combination with a consistency regularisation method for UDA. We overcome previous limitations on transferring synthetic images to real looking images. We leverage pseudo-labels in order to learn a generative image-to-image translation model that receives additional feedback from semantic labels on both domains. Our method outperforms state-of-the-art methods that combine image-to-image translation and semi-supervised learning on relevant domain adaptation benchmarks, i.e., on GTA5 to Cityscapes and SYNTHIA to Cityscapes.
AdaFusion: Visual-LiDAR Fusion with Adaptive Weights for Place Recognition
Nov 23, 2021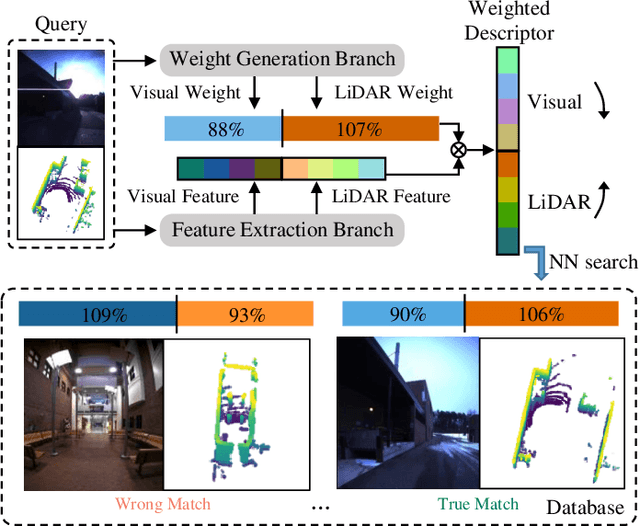
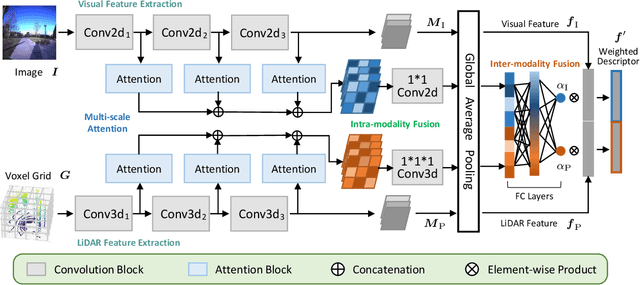
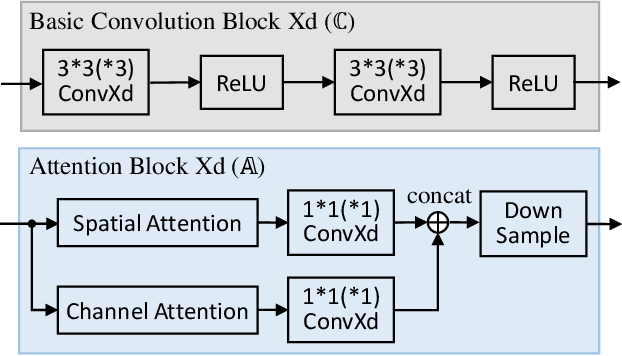

Recent years have witnessed the increasing application of place recognition in various environments, such as city roads, large buildings, and a mix of indoor and outdoor places. This task, however, still remains challenging due to the limitations of different sensors and the changing appearance of environments. Current works only consider the use of individual sensors, or simply combine different sensors, ignoring the fact that the importance of different sensors varies as the environment changes. In this paper, an adaptive weighting visual-LiDAR fusion method, named AdaFusion, is proposed to learn the weights for both images and point cloud features. Features of these two modalities are thus contributed differently according to the current environmental situation. The learning of weights is achieved by the attention branch of the network, which is then fused with the multi-modality feature extraction branch. Furthermore, to better utilize the potential relationship between images and point clouds, we design a twostage fusion approach to combine the 2D and 3D attention. Our work is tested on two public datasets, and experiments show that the adaptive weights help improve recognition accuracy and system robustness to varying environments.
Unsupervised Online Learning for Robotic Interestingness with Visual Memory
Nov 19, 2021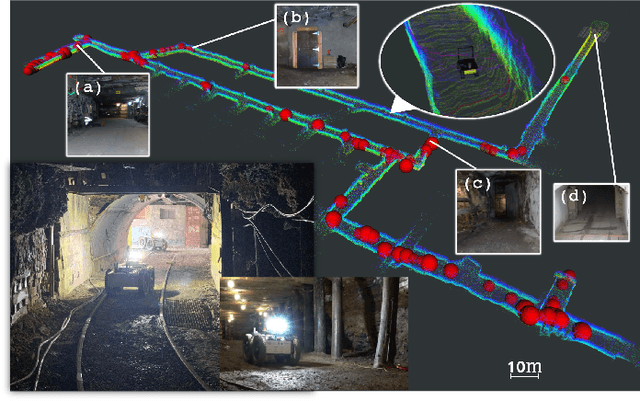

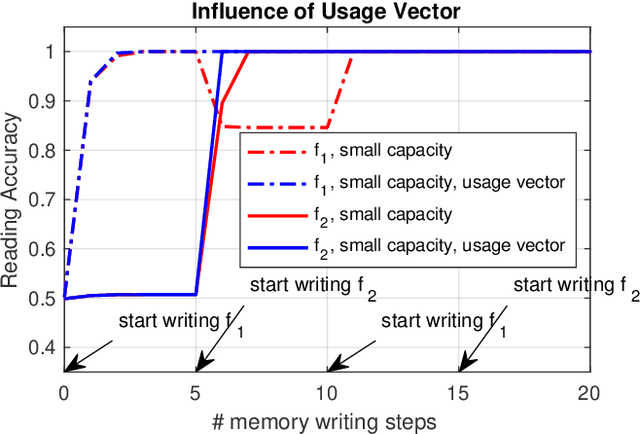

Autonomous robots frequently need to detect "interesting" scenes to decide on further exploration, or to decide which data to share for cooperation. These scenarios often require fast deployment with little or no training data. Prior work considers "interestingness" based on data from the same distribution. Instead, we propose to develop a method that automatically adapts online to the environment to report interesting scenes quickly. To address this problem, we develop a novel translation-invariant visual memory and design a three-stage architecture for long-term, short-term, and online learning, which enables the system to learn human-like experience, environmental knowledge, and online adaption, respectively. With this system, we achieve an average of 20% higher accuracy than the state-of-the-art unsupervised methods in a subterranean tunnel environment. We show comparable performance to supervised methods for robot exploration scenarios showing the efficacy of our approach. We expect that the presented method will play an important role in the robotic interestingness recognition exploration tasks.