 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Image Inpainting: Replacing an Image Region by Pulling Content from Another Image
Mar 22, 2018
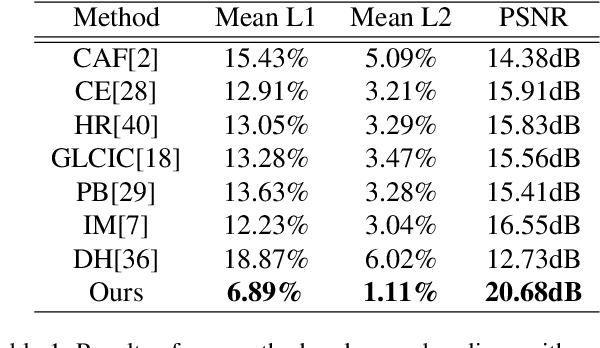
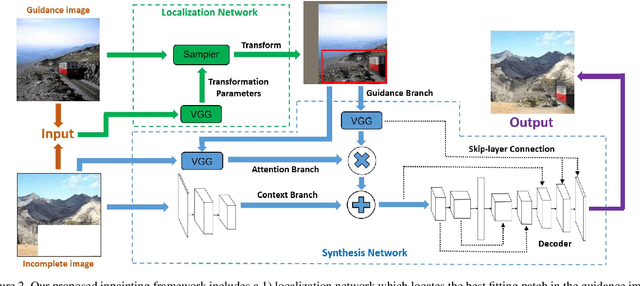

Deep generative models have shown success in automatically synthesizing missing image regions using surrounding context. However, users cannot directly decide what content to synthesize with such approaches. We propose an end-to-end network for image inpainting that uses a different image to guide the synthesis of new content to fill the hole. A key challenge addressed by our approach is synthesizing new content in regions where the guidance image and the context of the original image are inconsistent. We conduct four studies that demonstrate our results yield more realistic image inpainting results over seven baselines.
Deep GrabCut for Object Selection
Jul 14, 2017
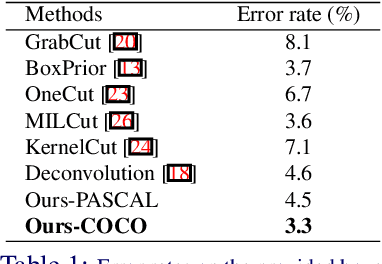
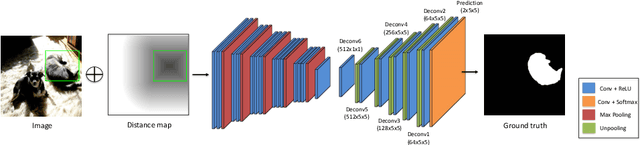
Most previous bounding-box-based segmentation methods assume the bounding box tightly covers the object of interest. However it is common that a rectangle input could be too large or too small. In this paper, we propose a novel segmentation approach that uses a rectangle as a soft constraint by transforming it into an Euclidean distance map. A convolutional encoder-decoder network is trained end-to-end by concatenating images with these distance maps as inputs and predicting the object masks as outputs. Our approach gets accurate segmentation results given sloppy rectangles while being general for both interactive segmentation and instance segmentation. We show our network extends to curve-based input without retraining. We further apply our network to instance-level semantic segmentation and resolve any overlap using a conditional random field. Experiments on benchmark datasets demonstrate the effectiveness of the proposed approaches.
Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition
Apr 23, 2017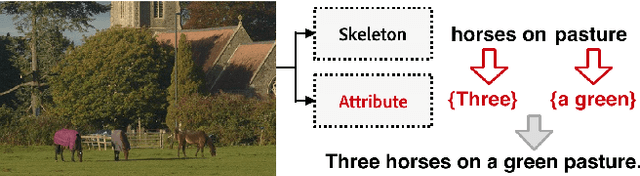

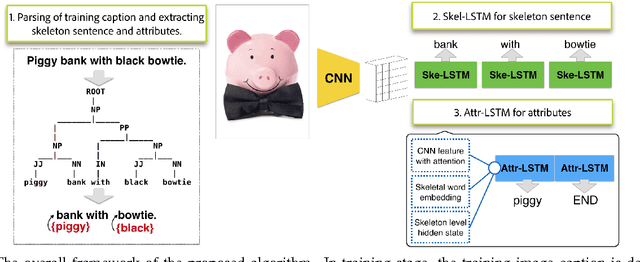
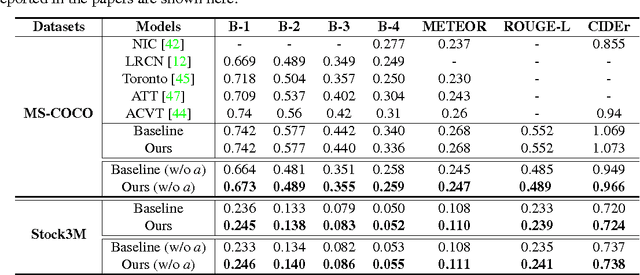
Recently, there has been a lot of interest in automatically generating descriptions for an image. Most existing language-model based approaches for this task learn to generate an image description word by word in its original word order. However, for humans, it is more natural to locate the objects and their relationships first, and then elaborate on each object, describing notable attributes. We present a coarse-to-fine method that decomposes the original image description into a skeleton sentence and its attributes, and generates the skeleton sentence and attribute phrases separately. By this decomposition, our method can generate more accurate and novel descriptions than the previous state-of-the-art. Experimental results on the MS-COCO and a larger scale Stock3M datasets show that our algorithm yields consistent improvements across different evaluation metrics, especially on the SPICE metric, which has much higher correlation with human ratings than the conventional metrics. Furthermore, our algorithm can generate descriptions with varied length, benefiting from the separate control of the skeleton and attributes. This enables image description generation that better accommodates user preferences.
Forecasting Human Dynamics from Static Images
Apr 11, 2017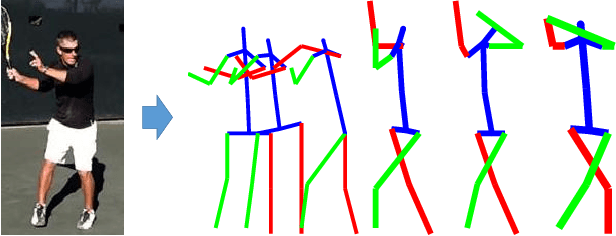

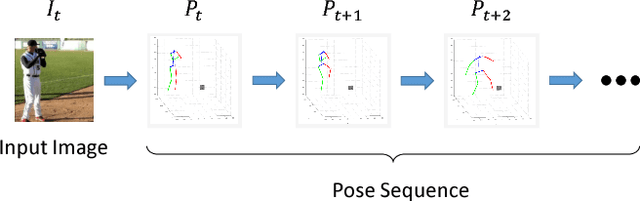

This paper presents the first study on forecasting human dynamics from static images. The problem is to input a single RGB image and generate a sequence of upcoming human body poses in 3D. To address the problem, we propose the 3D Pose Forecasting Network (3D-PFNet). Our 3D-PFNet integrates recent advances on single-image human pose estimation and sequence prediction, and converts the 2D predictions into 3D space. We train our 3D-PFNet using a three-step training strategy to leverage a diverse source of training data, including image and video based human pose datasets and 3D motion capture (MoCap) data. We demonstrate competitive performance of our 3D-PFNet on 2D pose forecasting and 3D pose recovery through quantitative and qualitative results.
Deep Image Matting
Apr 11, 2017
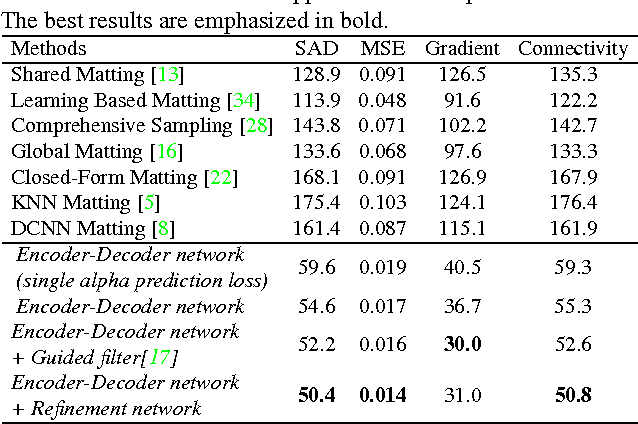

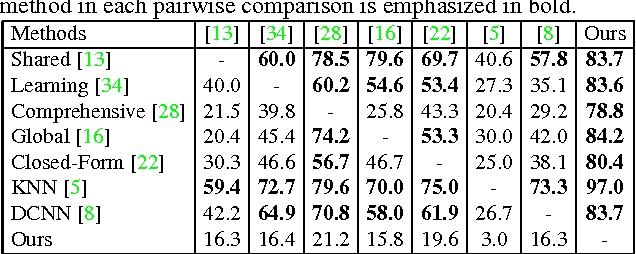
Image matting is a fundamental computer vision problem and has many applications. Previous algorithms have poor performance when an image has similar foreground and background colors or complicated textures. The main reasons are prior methods 1) only use low-level features and 2) lack high-level context. In this paper, we propose a novel deep learning based algorithm that can tackle both these problems. Our deep model has two parts. The first part is a deep convolutional encoder-decoder network that takes an image and the corresponding trimap as inputs and predict the alpha matte of the image. The second part is a small convolutional network that refines the alpha matte predictions of the first network to have more accurate alpha values and sharper edges. In addition, we also create a large-scale image matting dataset including 49300 training images and 1000 testing images. We evaluate our algorithm on the image matting benchmark, our testing set, and a wide variety of real images. Experimental results clearly demonstrate the superiority of our algorithm over previous methods.
Automatic Annotation of Structured Facts in Images
Apr 08, 2016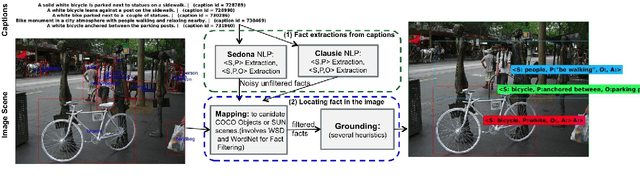

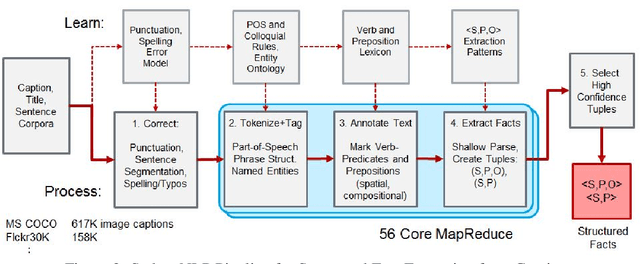

Motivated by the application of fact-level image understanding, we present an automatic method for data collection of structured visual facts from images with captions. Example structured facts include attributed objects (e.g., <flower, red>), actions (e.g., <baby, smile>), interactions (e.g., <man, walking, dog>), and positional information (e.g., <vase, on, table>). The collected annotations are in the form of fact-image pairs (e.g.,<man, walking, dog> and an image region containing this fact). With a language approach, the proposed method is able to collect hundreds of thousands of visual fact annotations with accuracy of 83% according to human judgment. Our method automatically collected more than 380,000 visual fact annotations and more than 110,000 unique visual facts from images with captions and localized them in images in less than one day of processing time on standard CPU platforms.
Sherlock: Scalable Fact Learning in Images
Apr 02, 2016
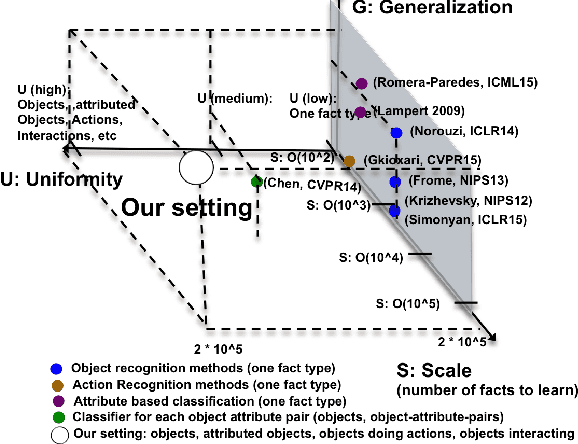
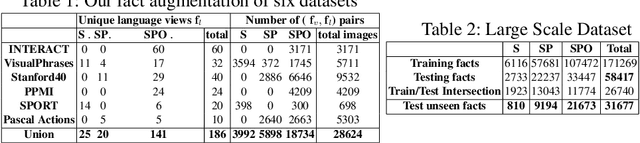
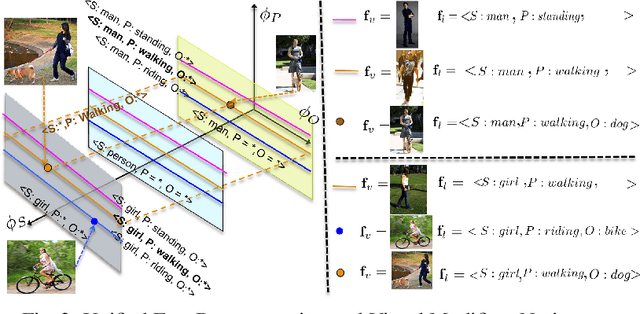
We study scalable and uniform understanding of facts in images. Existing visual recognition systems are typically modeled differently for each fact type such as objects, actions, and interactions. We propose a setting where all these facts can be modeled simultaneously with a capacity to understand unbounded number of facts in a structured way. The training data comes as structured facts in images, including (1) objects (e.g., $<$boy$>$), (2) attributes (e.g., $<$boy, tall$>$), (3) actions (e.g., $<$boy, playing$>$), and (4) interactions (e.g., $<$boy, riding, a horse $>$). Each fact has a semantic language view (e.g., $<$ boy, playing$>$) and a visual view (an image with this fact). We show that learning visual facts in a structured way enables not only a uniform but also generalizable visual understanding. We propose and investigate recent and strong approaches from the multiview learning literature and also introduce two learning representation models as potential baselines. We applied the investigated methods on several datasets that we augmented with structured facts and a large scale dataset of more than 202,000 facts and 814,000 images. Our experiments show the advantage of relating facts by the structure by the proposed models compared to the designed baselines on bidirectional fact retrieval.
Object Contour Detection with a Fully Convolutional Encoder-Decoder Network
Mar 15, 2016

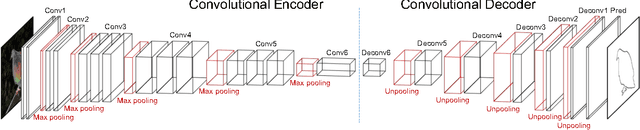

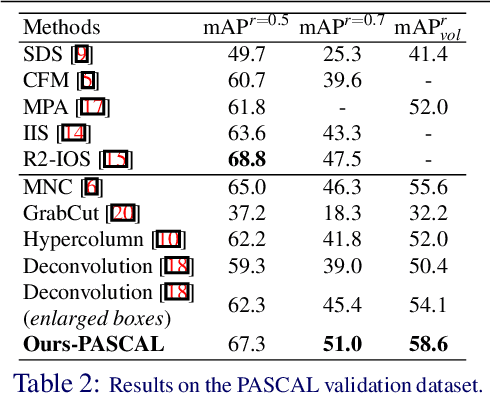
We develop a deep learning algorithm for contour detection with a fully convolutional encoder-decoder network. Different from previous low-level edge detection, our algorithm focuses on detecting higher-level object contours. Our network is trained end-to-end on PASCAL VOC with refined ground truth from inaccurate polygon annotations, yielding much higher precision in object contour detection than previous methods. We find that the learned model generalizes well to unseen object classes from the same super-categories on MS COCO and can match state-of-the-art edge detection on BSDS500 with fine-tuning. By combining with the multiscale combinatorial grouping algorithm, our method can generate high-quality segmented object proposals, which significantly advance the state-of-the-art on PASCAL VOC (improving average recall from 0.62 to 0.67) with a relatively small amount of candidates ($\sim$1660 per image).
Deep Interactive Object Selection
Mar 13, 2016
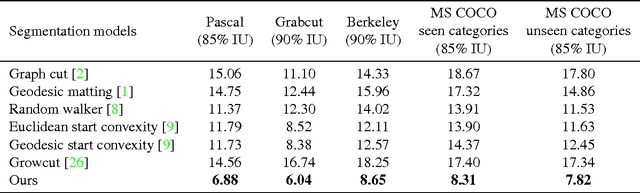

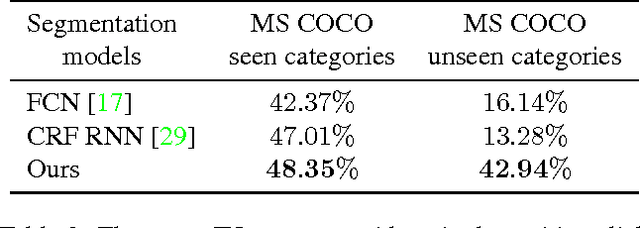
Interactive object selection is a very important research problem and has many applications. Previous algorithms require substantial user interactions to estimate the foreground and background distributions. In this paper, we present a novel deep learning based algorithm which has a much better understanding of objectness and thus can reduce user interactions to just a few clicks. Our algorithm transforms user provided positive and negative clicks into two Euclidean distance maps which are then concatenated with the RGB channels of images to compose (image, user interactions) pairs. We generate many of such pairs by combining several random sampling strategies to model user click patterns and use them to fine tune deep Fully Convolutional Networks (FCNs). Finally the output probability maps of our FCN 8s model is integrated with graph cut optimization to refine the boundary segments. Our model is trained on the PASCAL segmentation dataset and evaluated on other datasets with different object classes. Experimental results on both seen and unseen objects clearly demonstrate that our algorithm has a good generalization ability and is superior to all existing interactive object selection approaches.
Joint Object and Part Segmentation using Deep Learned Potentials
May 01, 2015
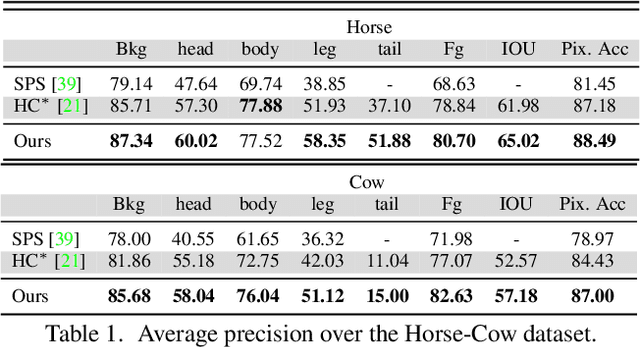
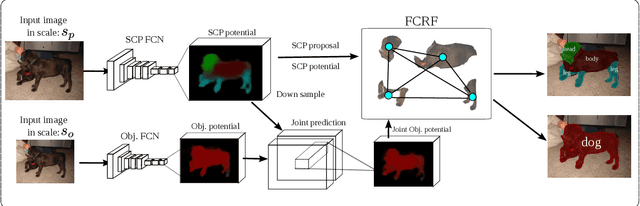
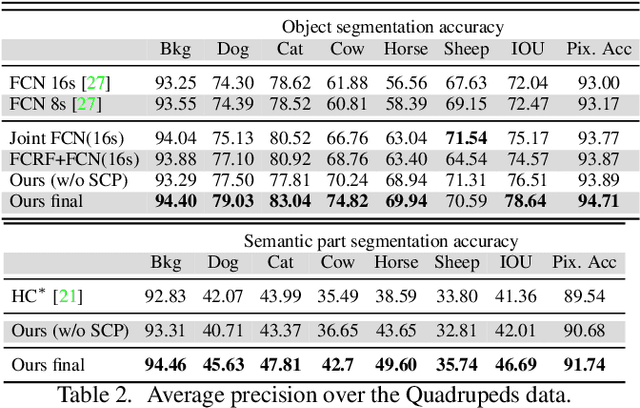
Segmenting semantic objects from images and parsing them into their respective semantic parts are fundamental steps towards detailed object understanding in computer vision. In this paper, we propose a joint solution that tackles semantic object and part segmentation simultaneously, in which higher object-level context is provided to guide part segmentation, and more detailed part-level localization is utilized to refine object segmentation. Specifically, we first introduce the concept of semantic compositional parts (SCP) in which similar semantic parts are grouped and shared among different objects. A two-channel fully convolutional network (FCN) is then trained to provide the SCP and object potentials at each pixel. At the same time, a compact set of segments can also be obtained from the SCP predictions of the network. Given the potentials and the generated segments, in order to explore long-range context, we finally construct an efficient fully connected conditional random field (FCRF) to jointly predict the final object and part labels. Extensive evaluation on three different datasets shows that our approach can mutually enhance the performance of object and part segmentation, and outperforms the current state-of-the-art on both tasks.