 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolCrystalFlow: Molecular Crystal Structure Prediction via Flow Matching
Feb 17, 2026Molecular crystal structure prediction represents a grand challenge in computational chemistry due to large sizes of constituent molecules and complex intra- and intermolecular interactions. While generative modeling has revolutionized structure discovery for molecules, inorganic solids, and metal-organic frameworks, extending such approaches to fully periodic molecular crystals is still elusive. Here, we present MolCrystalFlow, a flow-based generative model for molecular crystal structure prediction. The framework disentangles intramolecular complexity from intermolecular packing by embedding molecules as rigid bodies and jointly learning the lattice matrix, molecular orientations, and centroid positions. Centroids and orientations are represented on their native Riemannian manifolds, allowing geodesic flow construction and graph neural network operations that respects geometric symmetries. We benchmark our model against state-of-the-art generative models for large-size periodic crystals and rule-based structure generation methods on two open-source molecular crystal datasets. We demonstrate an integration of MolCrystalFlow model with universal machine learning potential to accelerate molecular crystal structure prediction, paving the way for data-driven generative discovery of molecular crystals.
MolGuidance: Advanced Guidance Strategies for Conditional Molecular Generation with Flow Matching
Dec 13, 2025



Key objectives in conditional molecular generation include ensuring chemical validity, aligning generated molecules with target properties, promoting structural diversity, and enabling efficient sampling for discovery. Recent advances in computer vision introduced a range of new guidance strategies for generative models, many of which can be adapted to support these goals. In this work, we integrate state-of-the-art guidance methods -- including classifier-free guidance, autoguidance, and model guidance -- in a leading molecule generation framework built on an SE(3)-equivariant flow matching process. We propose a hybrid guidance strategy that separately guides continuous and discrete molecular modalities -- operating on velocity fields and predicted logits, respectively -- while jointly optimizing their guidance scales via Bayesian optimization. Our implementation, benchmarked on the QM9 and QMe14S datasets, achieves new state-of-the-art performance in property alignment for de novo molecular generation. The generated molecules also exhibit high structural validity. Furthermore, we systematically compare the strengths and limitations of various guidance methods, offering insights into their broader applicability.
Open Materials Generation with Stochastic Interpolants
Feb 04, 2025The discovery of new materials is essential for enabling technological advancements. Computational approaches for predicting novel materials must effectively learn the manifold of stable crystal structures within an infinite design space. We introduce Open Materials Generation (OMG), a unifying framework for the generative design and discovery of inorganic crystalline materials. OMG employs stochastic interpolants (SI) to bridge an arbitrary base distribution to the target distribution of inorganic crystals via a broad class of tunable stochastic processes, encompassing both diffusion models and flow matching as special cases. In this work, we adapt the SI framework by integrating an equivariant graph representation of crystal structures and extending it to account for periodic boundary conditions in unit cell representations. Additionally, we couple the SI flow over spatial coordinates and lattice vectors with discrete flow matching for atomic species. We benchmark OMG's performance on two tasks: Crystal Structure Prediction (CSP) for specified compositions, and 'de novo' generation (DNG) aimed at discovering stable, novel, and unique structures. In our ground-up implementation of OMG, we refine and extend both CSP and DNG metrics compared to previous works. OMG establishes a new state-of-the-art in generative modeling for materials discovery, outperforming purely flow-based and diffusion-based implementations. These results underscore the importance of designing flexible deep learning frameworks to accelerate progress in materials science.
An information-matching approach to optimal experimental design and active learning
Nov 05, 2024The efficacy of mathematical models heavily depends on the quality of the training data, yet collecting sufficient data is often expensive and challenging. Many modeling applications require inferring parameters only as a means to predict other quantities of interest (QoI). Because models often contain many unidentifiable (sloppy) parameters, QoIs often depend on a relatively small number of parameter combinations. Therefore, we introduce an information-matching criterion based on the Fisher Information Matrix to select the most informative training data from a candidate pool. This method ensures that the selected data contain sufficient information to learn only those parameters that are needed to constrain downstream QoIs. It is formulated as a convex optimization problem, making it scalable to large models and datasets. We demonstrate the effectiveness of this approach across various modeling problems in diverse scientific fields, including power systems and underwater acoustics. Finally, we use information-matching as a query function within an Active Learning loop for material science applications. In all these applications, we find that a relatively small set of optimal training data can provide the necessary information for achieving precise predictions. These results are encouraging for diverse future applications, particularly active learning in large machine learning models.
Fine-Tuning Language Models on Multiple Datasets for Citation Intention Classification
Oct 17, 2024



Citation intention Classification (CIC) tools classify citations by their intention (e.g., background, motivation) and assist readers in evaluating the contribution of scientific literature. Prior research has shown that pretrained language models (PLMs) such as SciBERT can achieve state-of-the-art performance on CIC benchmarks. PLMs are trained via self-supervision tasks on a large corpus of general text and can quickly adapt to CIC tasks via moderate fine-tuning on the corresponding dataset. Despite their advantages, PLMs can easily overfit small datasets during fine-tuning. In this paper, we propose a multi-task learning (MTL) framework that jointly fine-tunes PLMs on a dataset of primary interest together with multiple auxiliary CIC datasets to take advantage of additional supervision signals. We develop a data-driven task relation learning (TRL) method that controls the contribution of auxiliary datasets to avoid negative transfer and expensive hyper-parameter tuning. We conduct experiments on three CIC datasets and show that fine-tuning with additional datasets can improve the PLMs' generalization performance on the primary dataset. PLMs fine-tuned with our proposed framework outperform the current state-of-the-art models by 7% to 11% on small datasets while aligning with the best-performing model on a large dataset.
Active Mass Distribution Estimation from Tactile Feedback
Mar 02, 2023



In this work, we present a method to estimate the mass distribution of a rigid object through robotic interactions and tactile feedback. This is a challenging problem because of the complexity of physical dynamics modeling and the action dependencies across the model parameters. We propose a sequential estimation strategy combined with a set of robot action selection rules based on the analytical formulation of a discrete-time dynamics model. To evaluate the performance of our approach, we also manufactured re-configurable block objects that allow us to modify the object mass distribution while having access to the ground truth values. We compare our approach against multiple baselines and show that our approach can estimate the mass distribution with around 10% error, while the baselines have errors ranging from 18% to 68%.
Injecting Domain Knowledge from Empirical Interatomic Potentials to Neural Networks for Predicting Material Properties
Oct 14, 2022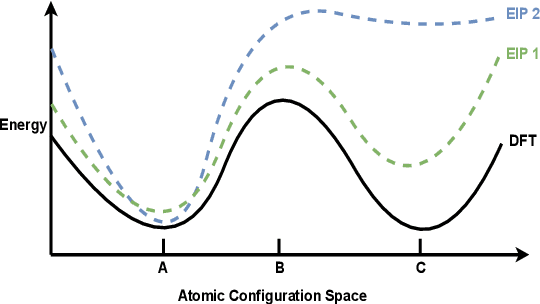
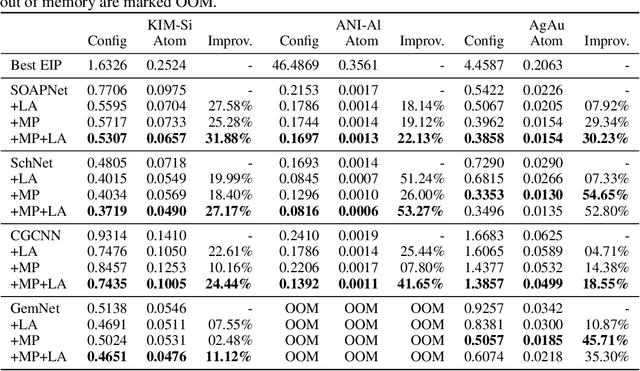
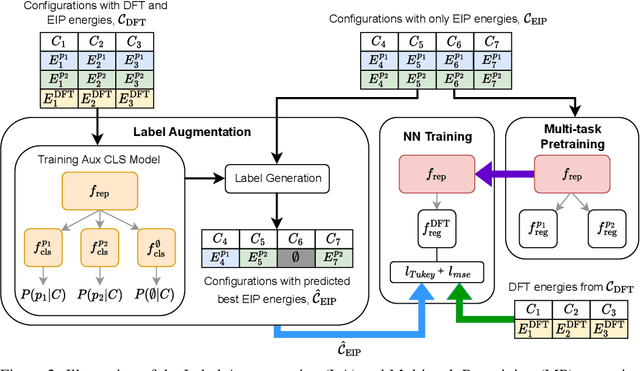
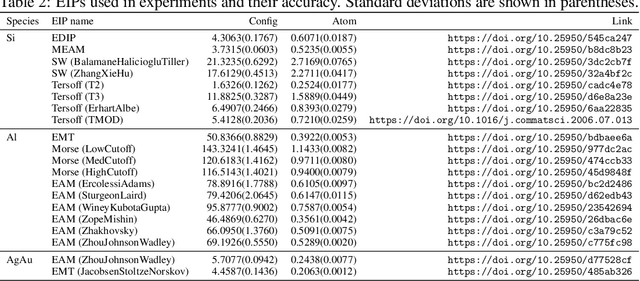
For decades, atomistic modeling has played a crucial role in predicting the behavior of materials in numerous fields ranging from nanotechnology to drug discovery. The most accurate methods in this domain are rooted in first-principles quantum mechanical calculations such as density functional theory (DFT). Because these methods have remained computationally prohibitive, practitioners have traditionally focused on defining physically motivated closed-form expressions known as empirical interatomic potentials (EIPs) that approximately model the interactions between atoms in materials. In recent years, neural network (NN)-based potentials trained on quantum mechanical (DFT-labeled) data have emerged as a more accurate alternative to conventional EIPs. However, the generalizability of these models relies heavily on the amount of labeled training data, which is often still insufficient to generate models suitable for general-purpose applications. In this paper, we propose two generic strategies that take advantage of unlabeled training instances to inject domain knowledge from conventional EIPs to NNs in order to increase their generalizability. The first strategy, based on weakly supervised learning, trains an auxiliary classifier on EIPs and selects the best-performing EIP to generate energies to supplement the ground-truth DFT energies in training the NN. The second strategy, based on transfer learning, first pretrains the NN on a large set of easily obtainable EIP energies, and then fine-tunes it on ground-truth DFT energies. Experimental results on three benchmark datasets demonstrate that the first strategy improves baseline NN performance by 5% to 51% while the second improves baseline performance by up to 55%. Combining them further boosts performance.