 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Matrix Approximation and Geometry of Unitary Orbits
Jul 06, 2022Consider the following optimization problem: Given $n \times n$ matrices $A$ and $\Lambda$, maximize $\langle A, U\Lambda U^*\rangle$ where $U$ varies over the unitary group $\mathrm{U}(n)$. This problem seeks to approximate $A$ by a matrix whose spectrum is the same as $\Lambda$ and, by setting $\Lambda$ to be appropriate diagonal matrices, one can recover matrix approximation problems such as PCA and rank-$k$ approximation. We study the problem of designing differentially private algorithms for this optimization problem in settings where the matrix $A$ is constructed using users' private data. We give efficient and private algorithms that come with upper and lower bounds on the approximation error. Our results unify and improve upon several prior works on private matrix approximation problems. They rely on extensions of packing/covering number bounds for Grassmannians to unitary orbits which should be of independent interest.
Beyond Uniform Lipschitz Condition in Differentially Private Optimization
Jun 21, 2022
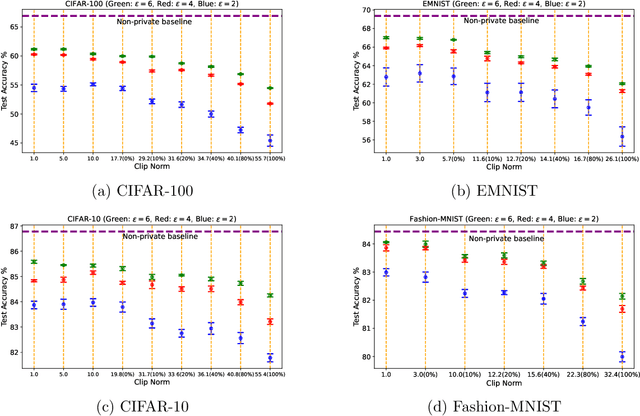
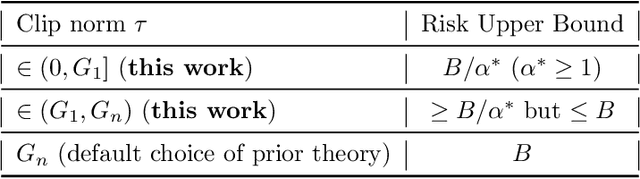
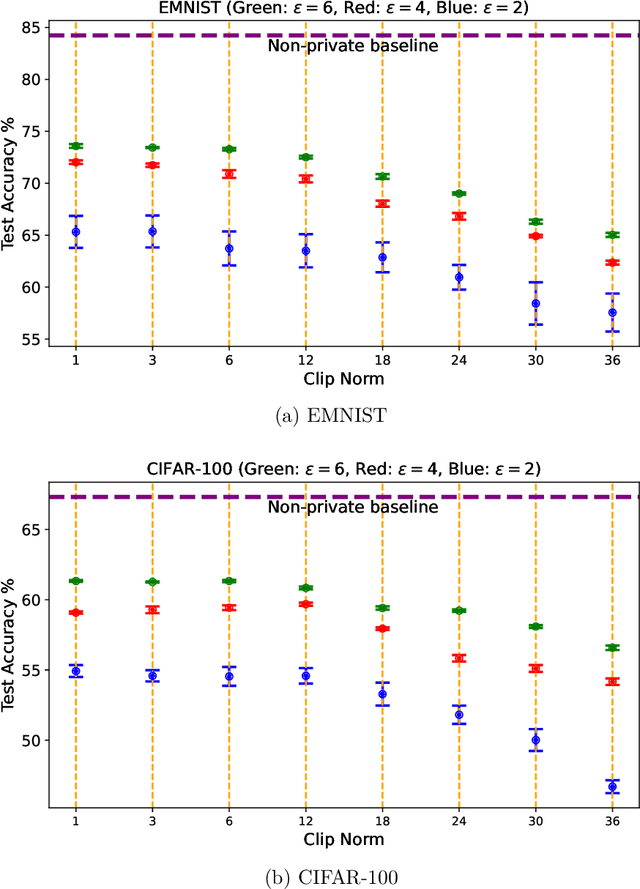
Most prior convergence results on differentially private stochastic gradient descent (DP-SGD) are derived under the simplistic assumption of uniform Lipschitzness, i.e., the per-sample gradients are uniformly bounded. This assumption is unrealistic in many problems, e.g., linear regression with Gaussian data. We relax uniform Lipschitzness by instead assuming that the per-sample gradients have \textit{sample-dependent} upper bounds, i.e., per-sample Lipschitz constants, which themselves may be unbounded. We derive new convergence results for DP-SGD on both convex and nonconvex functions when the per-sample Lipschitz constants have bounded moments. Furthermore, we provide principled guidance on choosing the clip norm in DP-SGD for convex settings satisfying our relaxed version of Lipschitzness, without making distributional assumptions on the Lipschitz constants. We verify the effectiveness of our recommendation via experiments on benchmarking datasets.
On the Unreasonable Effectiveness of Federated Averaging with Heterogeneous Data
Jun 09, 2022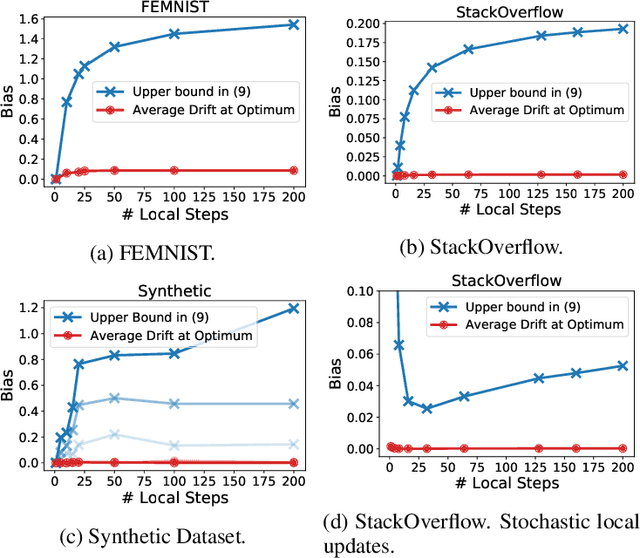
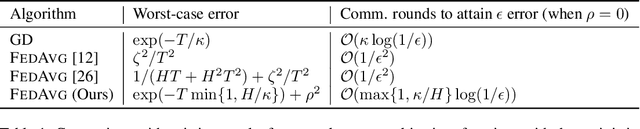
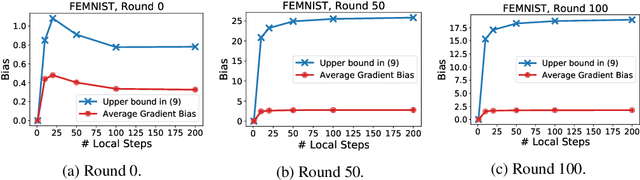
Existing theory predicts that data heterogeneity will degrade the performance of the Federated Averaging (FedAvg) algorithm in federated learning. However, in practice, the simple FedAvg algorithm converges very well. This paper explains the seemingly unreasonable effectiveness of FedAvg that contradicts the previous theoretical predictions. We find that the key assumption of bounded gradient dissimilarity in previous theoretical analyses is too pessimistic to characterize data heterogeneity in practical applications. For a simple quadratic problem, we demonstrate there exist regimes where large gradient dissimilarity does not have any negative impact on the convergence of FedAvg. Motivated by this observation, we propose a new quantity, average drift at optimum, to measure the effects of data heterogeneity, and explicitly use it to present a new theoretical analysis of FedAvg. We show that the average drift at optimum is nearly zero across many real-world federated training tasks, whereas the gradient dissimilarity can be large. And our new analysis suggests FedAvg can have identical convergence rates in homogeneous and heterogeneous data settings, and hence, leads to better understanding of its empirical success.
Self-Consistency of the Fokker-Planck Equation
Jun 02, 2022

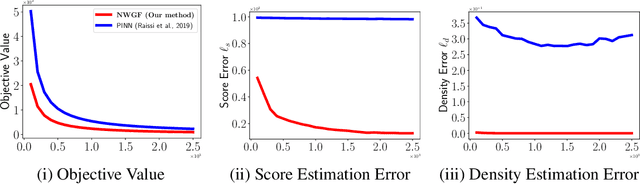
The Fokker-Planck equation (FPE) is the partial differential equation that governs the density evolution of the It\^o process and is of great importance to the literature of statistical physics and machine learning. The FPE can be regarded as a continuity equation where the change of the density is completely determined by a time varying velocity field. Importantly, this velocity field also depends on the current density function. As a result, the ground-truth velocity field can be shown to be the solution of a fixed-point equation, a property that we call self-consistency. In this paper, we exploit this concept to design a potential function of the hypothesis velocity fields, and prove that, if such a function diminishes to zero during the training procedure, the trajectory of the densities generated by the hypothesis velocity fields converges to the solution of the FPE in the Wasserstein-2 sense. The proposed potential function is amenable to neural-network based parameterization as the stochastic gradient with respect to the parameter can be efficiently computed. Once a parameterized model, such as Neural Ordinary Differential Equation is trained, we can generate the entire trajectory to the FPE.
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022
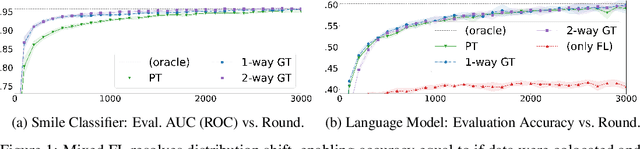
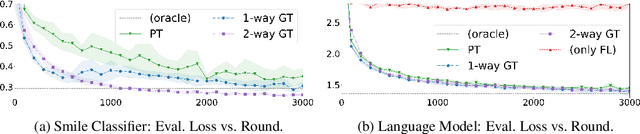
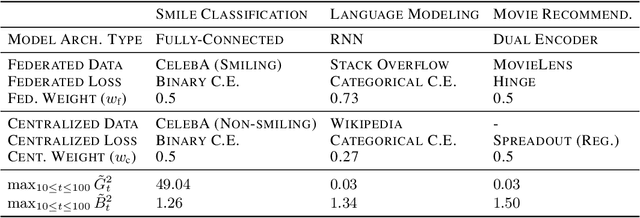
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
Reproducibility in Optimization: Theoretical Framework and Limits
Feb 09, 2022
We initiate a formal study of reproducibility in optimization. We define a quantitative measure of reproducibility of optimization procedures in the face of noisy or error-prone operations such as inexact or stochastic gradient computations or inexact initialization. We then analyze several convex optimization settings of interest such as smooth, non-smooth, and strongly-convex objective functions and establish tight bounds on the limits of reproducibility in each setting. Our analysis reveals a fundamental trade-off between computation and reproducibility: more computation is necessary (and sufficient) for better reproducibility.
Pushing the Efficiency-Regret Pareto Frontier for Online Learning of Portfolios and Quantum States
Feb 06, 2022
We revisit the classical online portfolio selection problem. It is widely assumed that a trade-off between computational complexity and regret is unavoidable, with Cover's Universal Portfolios algorithm, SOFT-BAYES and ADA-BARRONS currently constituting its state-of-the-art Pareto frontier. In this paper, we present the first efficient algorithm, BISONS, that obtains polylogarithmic regret with memory and per-step running time requirements that are polynomial in the dimension, displacing ADA-BARRONS from the Pareto frontier. Additionally, we resolve a COLT 2020 open problem by showing that a certain Follow-The-Regularized-Leader algorithm with log-barrier regularization suffers an exponentially larger dependence on the dimension than previously conjectured. Thus, we rule out this algorithm as a candidate for the Pareto frontier. We also extend our algorithm and analysis to a more general problem than online portfolio selection, viz. online learning of quantum states with log loss. This algorithm, called SCHRODINGER'S BISONS, is the first efficient algorithm with polylogarithmic regret for this more general problem.
Agnostic Learnability of Halfspaces via Logistic Loss
Jan 31, 2022
We investigate approximation guarantees provided by logistic regression for the fundamental problem of agnostic learning of homogeneous halfspaces. Previously, for a certain broad class of "well-behaved" distributions on the examples, Diakonikolas et al. (2020) proved an $\tilde{\Omega}(\textrm{OPT})$ lower bound, while Frei et al. (2021) proved an $\tilde{O}(\sqrt{\textrm{OPT}})$ upper bound, where $\textrm{OPT}$ denotes the best zero-one/misclassification risk of a homogeneous halfspace. In this paper, we close this gap by constructing a well-behaved distribution such that the global minimizer of the logistic risk over this distribution only achieves $\Omega(\sqrt{\textrm{OPT}})$ misclassification risk, matching the upper bound in (Frei et al., 2021). On the other hand, we also show that if we impose a radial-Lipschitzness condition in addition to well-behaved-ness on the distribution, logistic regression on a ball of bounded radius reaches $\tilde{O}(\textrm{OPT})$ misclassification risk. Our techniques also show for any well-behaved distribution, regardless of radial Lipschitzness, we can overcome the $\Omega(\sqrt{\textrm{OPT}})$ lower bound for logistic loss simply at the cost of one additional convex optimization step involving the hinge loss and attain $\tilde{O}(\textrm{OPT})$ misclassification risk. This two-step convex optimization algorithm is simpler than previous methods obtaining this guarantee, all of which require solving $O(\log(1/\textrm{OPT}))$ minimization problems.
Efficient Methods for Online Multiclass Logistic Regression
Oct 10, 2021
Multiclass logistic regression is a fundamental task in machine learning with applications in classification and boosting. Previous work (Foster et al., 2018) has highlighted the importance of improper predictors for achieving "fast rates" in the online multiclass logistic regression problem without suffering exponentially from secondary problem parameters, such as the norm of the predictors in the comparison class. While Foster et al. (2018) introduced a statistically optimal algorithm, it is in practice computationally intractable due to its run-time complexity being a large polynomial in the time horizon and dimension of input feature vectors. In this paper, we develop a new algorithm, FOLKLORE, for the problem which runs significantly faster than the algorithm of Foster et al.(2018) -- the running time per iteration scales quadratically in the dimension -- at the cost of a linear dependence on the norm of the predictors in the regret bound. This yields the first practical algorithm for online multiclass logistic regression, resolving an open problem of Foster et al.(2018). Furthermore, we show that our algorithm can be applied to online bandit multiclass prediction and online multiclass boosting, yielding more practical algorithms for both problems compared to the ones in Foster et al.(2018) with similar performance guarantees. Finally, we also provide an online-to-batch conversion result for our algorithm.
A Field Guide to Federated Optimization
Jul 14, 2021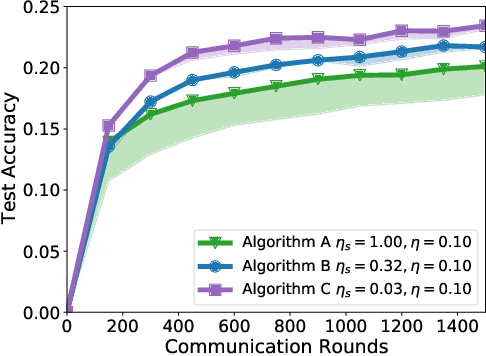


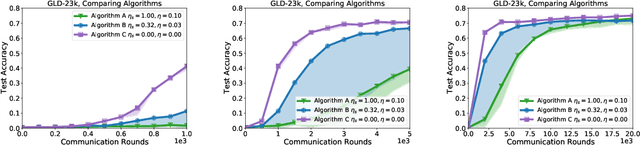
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.