 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBISCUIT: Causal Representation Learning from Binary Interactions
Jun 16, 2023



Identifying the causal variables of an environment and how to intervene on them is of core value in applications such as robotics and embodied AI. While an agent can commonly interact with the environment and may implicitly perturb the behavior of some of these causal variables, often the targets it affects remain unknown. In this paper, we show that causal variables can still be identified for many common setups, e.g., additive Gaussian noise models, if the agent's interactions with a causal variable can be described by an unknown binary variable. This happens when each causal variable has two different mechanisms, e.g., an observational and an interventional one. Using this identifiability result, we propose BISCUIT, a method for simultaneously learning causal variables and their corresponding binary interaction variables. On three robotic-inspired datasets, BISCUIT accurately identifies causal variables and can even be scaled to complex, realistic environments for embodied AI.
Graph Switching Dynamical Systems
Jun 01, 2023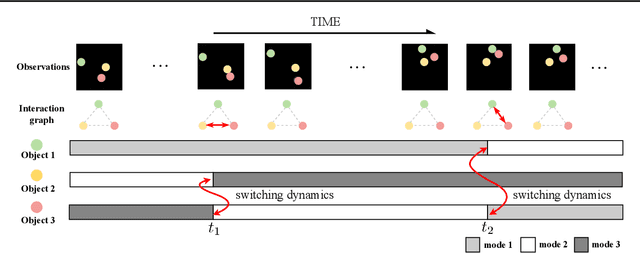
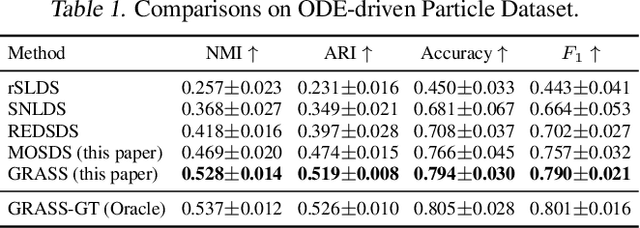
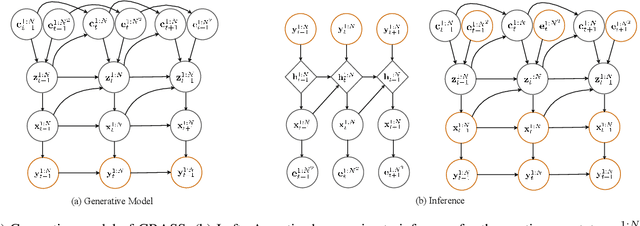
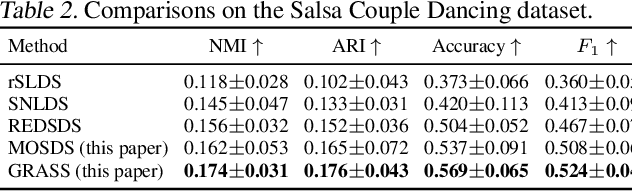
Dynamical systems with complex behaviours, e.g. immune system cells interacting with a pathogen, are commonly modelled by splitting the behaviour into different regimes, or modes, each with simpler dynamics, and then learning the switching behaviour from one mode to another. Switching Dynamical Systems (SDS) are a powerful tool that automatically discovers these modes and mode-switching behaviour from time series data. While effective, these methods focus on independent objects, where the modes of one object are independent of the modes of the other objects. In this paper, we focus on the more general interacting object setting for switching dynamical systems, where the per-object dynamics also depends on an unknown and dynamically changing subset of other objects and their modes. To this end, we propose a novel graph-based approach for switching dynamical systems, GRAph Switching dynamical Systems (GRASS), in which we use a dynamic graph to characterize interactions between objects and learn both intra-object and inter-object mode-switching behaviour. We introduce two new datasets for this setting, a synthesized ODE-driven particles dataset and a real-world Salsa Couple Dancing dataset. Experiments show that GRASS can consistently outperforms previous state-of-the-art methods.
Invariant Neural Ordinary Differential Equations
Feb 26, 2023



Latent neural ordinary differential equations have been proven useful for learning non-linear dynamics of arbitrary sequences. In contrast with their mechanistic counterparts, the predictive accuracy of neural ODEs decreases over longer prediction horizons (Rubanova et al., 2019). To mitigate this issue, we propose disentangling dynamic states from time-invariant variables in a completely data-driven way, enabling robust neural ODE models that can generalize across different settings. We show that such variables can control the latent differential function and/or parameterize the mapping from latent variables to observations. By explicitly modeling the time-invariant variables, our framework enables the use of recent advances in representation learning. We demonstrate this by introducing a straightforward self-supervised objective that enhances the learning of these variables. The experiments on low-dimensional oscillating systems and video sequences reveal that our disentangled model achieves improved long-term predictions, when the training data involve sequence-specific factors of variation such as different rotational speeds, calligraphic styles, and friction constants.
iCITRIS: Causal Representation Learning for Instantaneous Temporal Effects
Jun 13, 2022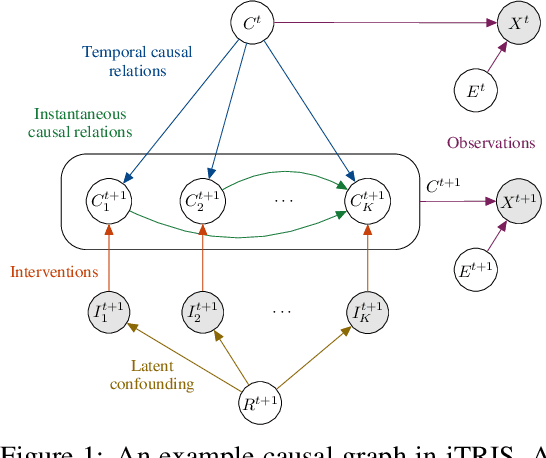

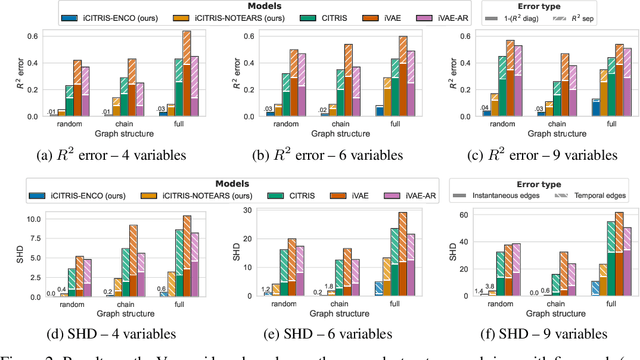

Causal representation learning is the task of identifying the underlying causal variables and their relations from high-dimensional observations, such as images. Recent work has shown that one can reconstruct the causal variables from temporal sequences of observations under the assumption that there are no instantaneous causal relations between them. In practical applications, however, our measurement or frame rate might be slower than many of the causal effects. This effectively creates "instantaneous" effects and invalidates previous identifiability results. To address this issue, we propose iCITRIS, a causal representation learning method that can handle instantaneous effects in temporal sequences when given perfect interventions with known intervention targets. iCITRIS identifies the causal factors from temporal observations, while simultaneously using a differentiable causal discovery method to learn their causal graph. In experiments on three video datasets, iCITRIS accurately identifies the causal factors and their causal graph.
Factored Adaptation for Non-Stationary Reinforcement Learning
Mar 30, 2022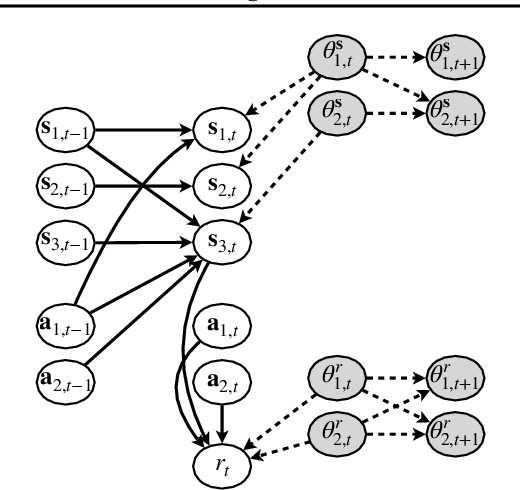
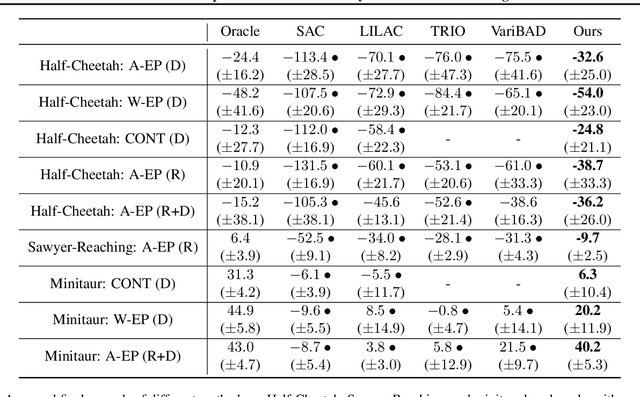
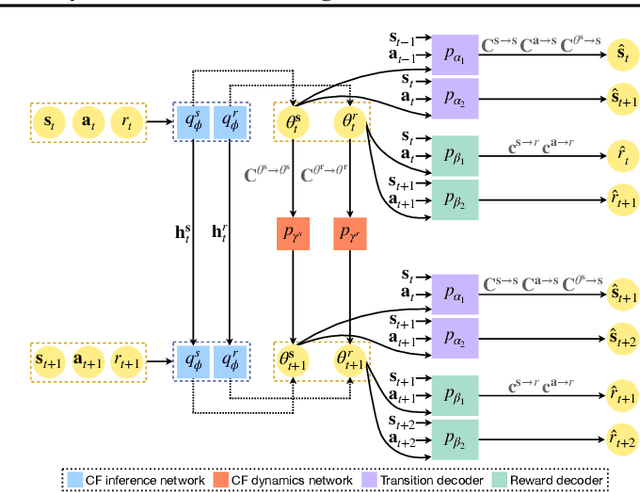

Dealing with non-stationarity in environments (i.e., transition dynamics) and objectives (i.e., reward functions) is a challenging problem that is crucial in real-world applications of reinforcement learning (RL). Most existing approaches only focus on families of stationary MDPs, in which the non-stationarity is episodic, i.e., the change is only possible across episodes. The few works that do consider non-stationarity without a specific boundary, i.e., also allow for changes within an episode, model the changes monolithically in a single shared embedding vector. In this paper, we propose Factored Adaptation for Non-Stationary RL (FANS-RL), a factored adaption approach that explicitly learns the individual latent change factors affecting the transition dynamics and reward functions. FANS-RL learns jointly the structure of a factored MDP and a factored representation of the time-varying change factors, as well as the specific state components that they affect, via a factored non-stationary variational autoencoder. Through this general framework, we can consider general non-stationary scenarios with different changing function types and changing frequency. Experimental results demonstrate that FANS-RL outperforms existing approaches in terms of rewards, compactness of the latent state representation and robustness to varying degrees of non-stationarity.
CITRIS: Causal Identifiability from Temporal Intervened Sequences
Feb 16, 2022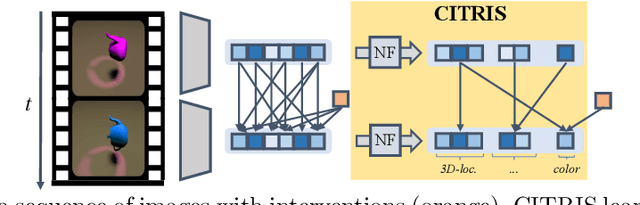
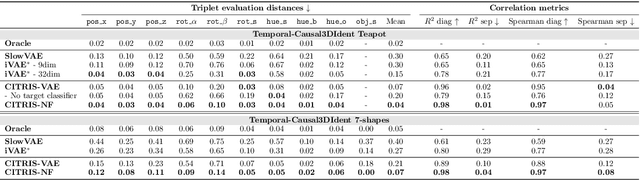
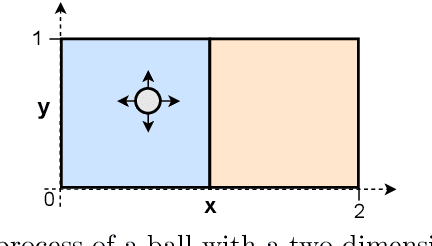

Understanding the latent causal factors of a dynamical system from visual observations is a crucial step towards agents reasoning in complex environments. In this paper, we propose CITRIS, a variational autoencoder framework that learns causal representations from temporal sequences of images in which underlying causal factors have possibly been intervened upon. In contrast to the recent literature, CITRIS exploits temporality and observing intervention targets to identify scalar and multidimensional causal factors, such as 3D rotation angles. Furthermore, by introducing a normalizing flow, CITRIS can be easily extended to leverage and disentangle representations obtained by already pretrained autoencoders. Extending previous results on scalar causal factors, we prove identifiability in a more general setting, in which only some components of a causal factor are affected by interventions. In experiments on 3D rendered image sequences, CITRIS outperforms previous methods on recovering the underlying causal variables. Moreover, using pretrained autoencoders, CITRIS can even generalize to unseen instantiations of causal factors, opening future research areas in sim-to-real generalization for causal representation learning.
AdaRL: What, Where, and How to Adapt in Transfer Reinforcement Learning
Jul 07, 2021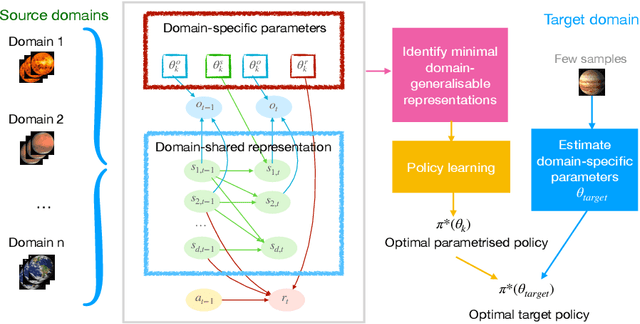
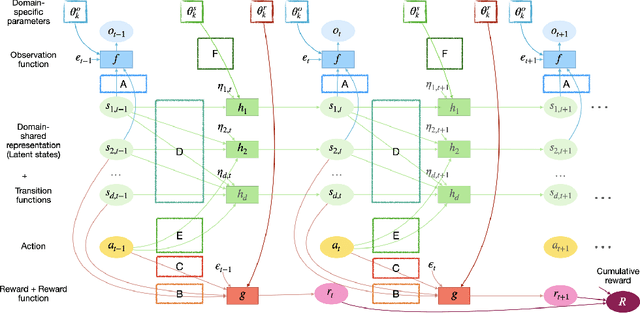
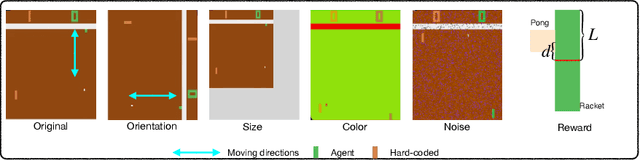

Most approaches in reinforcement learning (RL) are data-hungry and specific to fixed environments. In this paper, we propose a principled framework for adaptive RL, called AdaRL, that adapts reliably to changes across domains. Specifically, we construct a generative environment model for the structural relationships among variables in the system and embed the changes in a compact way, which provides a clear and interpretable picture for locating what and where the changes are and how to adapt. Based on the environment model, we characterize a minimal set of representations, including both domain-specific factors and domain-shared state representations, that suffice for reliable and low-cost transfer. Moreover, we show that by explicitly leveraging a compact representation to encode changes, we can adapt the policy with only a few samples without further policy optimization in the target domain. We illustrate the efficacy of AdaRL through a series of experiments that allow for changes in different components of Cartpole and Atari games.
Active Structure Learning of Causal DAGs via Directed Clique Tree
Nov 01, 2020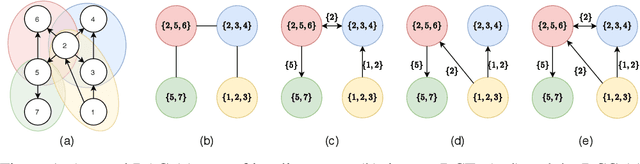
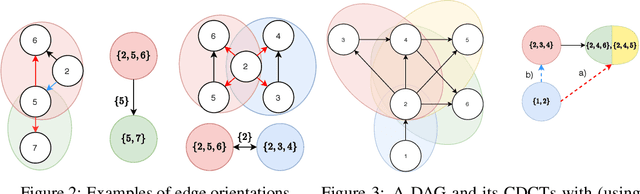
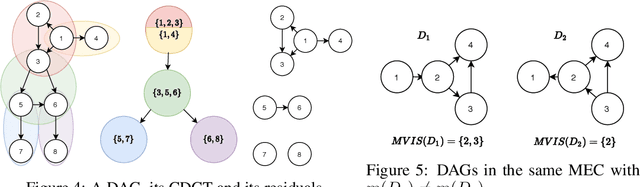
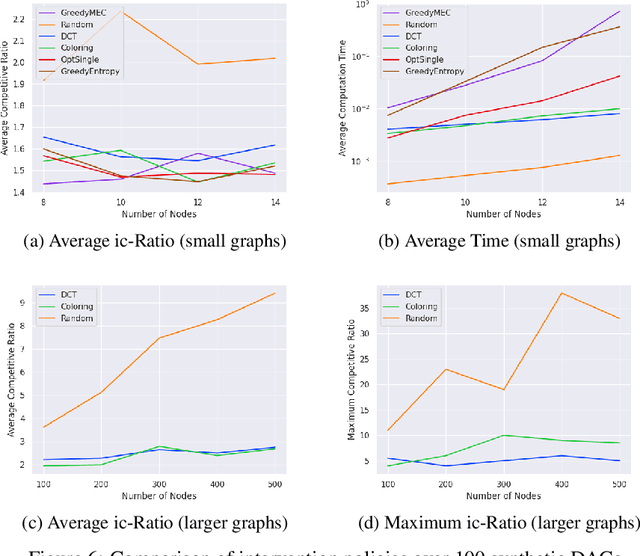
A growing body of work has begun to study intervention design for efficient structure learning of causal directed acyclic graphs (DAGs). A typical setting is a causally sufficient setting, i.e. a system with no latent confounders, selection bias, or feedback, when the essential graph of the observational equivalence class (EC) is given as an input and interventions are assumed to be noiseless. Most existing works focus on worst-case or average-case lower bounds for the number of interventions required to orient a DAG. These worst-case lower bounds only establish that the largest clique in the essential graph could make it difficult to learn the true DAG. In this work, we develop a universal lower bound for single-node interventions that establishes that the largest clique is always a fundamental impediment to structure learning. Specifically, we present a decomposition of a DAG into independently orientable components through directed clique trees and use it to prove that the number of single-node interventions necessary to orient any DAG in an EC is at least the sum of half the size of the largest cliques in each chain component of the essential graph. Moreover, we present a two-phase intervention design algorithm that, under certain conditions on the chordal skeleton, matches the optimal number of interventions up to a multiplicative logarithmic factor in the number of maximal cliques. We show via synthetic experiments that our algorithm can scale to much larger graphs than most of the related work and achieves better worst-case performance than other scalable approaches. A code base to recreate these results can be found at https://github.com/csquires/dct-policy
Verifiably Safe Exploration for End-to-End Reinforcement Learning
Jul 02, 2020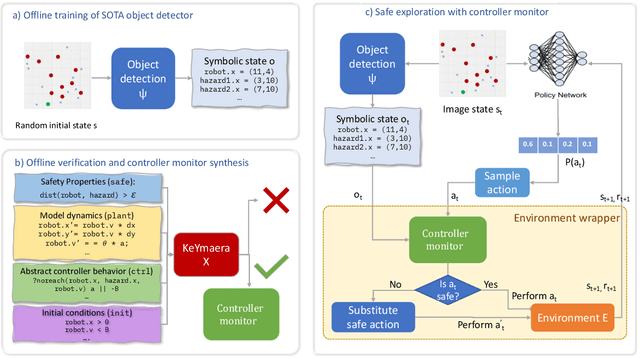
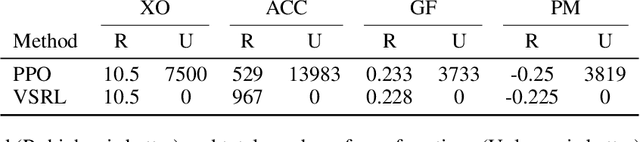
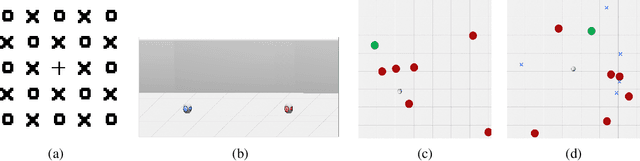

Deploying deep reinforcement learning in safety-critical settings requires developing algorithms that obey hard constraints during exploration. This paper contributes a first approach toward enforcing formal safety constraints on end-to-end policies with visual inputs. Our approach draws on recent advances in object detection and automated reasoning for hybrid dynamical systems. The approach is evaluated on a novel benchmark that emphasizes the challenge of safely exploring in the presence of hard constraints. Our benchmark draws from several proposed problem sets for safe learning and includes problems that emphasize challenges such as reward signals that are not aligned with safety constraints. On each of these benchmark problems, our algorithm completely avoids unsafe behavior while remaining competitive at optimizing for as much reward as is safe. We also prove that our method of enforcing the safety constraints preserves all safe policies from the original environment.
Domain Adaptation by Using Causal Inference to Predict Invariant Conditional Distributions
Oct 29, 2018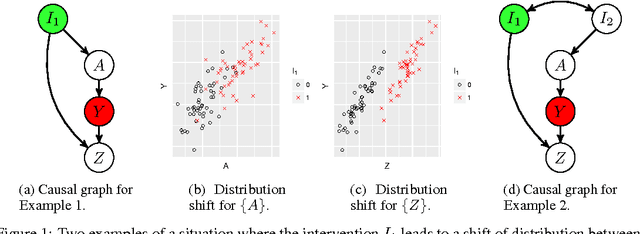
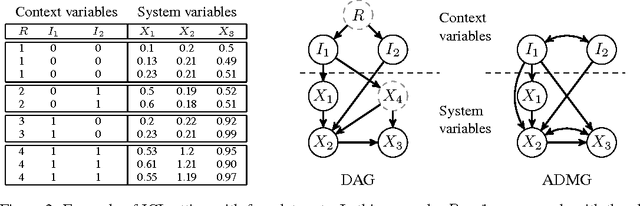
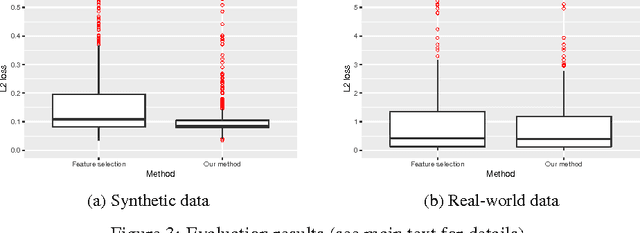
An important goal common to domain adaptation and causal inference is to make accurate predictions when the distributions for the source (or training) domain(s) and target (or test) domain(s) differ. In many cases, these different distributions can be modeled as different contexts of a single underlying system, in which each distribution corresponds to a different perturbation of the system, or in causal terms, an intervention. We focus on a class of such causal domain adaptation problems, where data for one or more source domains are given, and the task is to predict the distribution of a certain target variable from measurements of other variables in one or more target domains. We propose an approach for solving these problems that exploits causal inference and does not rely on prior knowledge of the causal graph, the type of interventions or the intervention targets. We demonstrate our approach by evaluating a possible implementation on simulated and real world data.