 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
Constrained Decoding for Code Language Models via Efficient Left and Right Quotienting of Context-Sensitive Grammars
Feb 28, 2024



Large Language Models are powerful tools for program synthesis and advanced auto-completion, but come with no guarantee that their output code is syntactically correct. This paper contributes an incremental parser that allows early rejection of syntactically incorrect code, as well as efficient detection of complete programs for fill-in-the-middle (FItM) tasks. We develop Earley-style parsers that operate over left and right quotients of arbitrary context-free grammars, and we extend our incremental parsing and quotient operations to several context-sensitive features present in the grammars of many common programming languages. The result of these contributions is an efficient, general, and well-grounded method for left and right quotient parsing. To validate our theoretical contributions -- and the practical effectiveness of certain design decisions -- we evaluate our method on the particularly difficult case of FItM completion for Python 3. Our results demonstrate that constrained generation can significantly reduce the incidence of syntax errors in recommended code.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
CertRL: Formalizing Convergence Proofs for Value and Policy Iteration in Coq
Sep 23, 2020
Reinforcement learning algorithms solve sequential decision-making problems in probabilistic environments by optimizing for long-term reward. The desire to use reinforcement learning in safety-critical settings inspires a recent line of work on formally constrained reinforcement learning; however, these methods place the implementation of the learning algorithm in their Trusted Computing Base. The crucial correctness property of these implementations is a guarantee that the learning algorithm converges to an optimal policy. This paper begins the work of closing this gap by developing a Coq formalization of two canonical reinforcement learning algorithms: value and policy iteration for finite state Markov decision processes. The central results are a formalization of Bellman's optimality principle and its proof, which uses a contraction property of Bellman optimality operator to establish that a sequence converges in the infinite horizon limit. The CertRL development exemplifies how the Giry monad and mechanized metric coinduction streamline optimality proofs for reinforcement learning algorithms. The CertRL library provides a general framework for proving properties about Markov decision processes and reinforcement learning algorithms, paving the way for further work on formalization of reinforcement learning algorithms.
Verifiably Safe Exploration for End-to-End Reinforcement Learning
Jul 02, 2020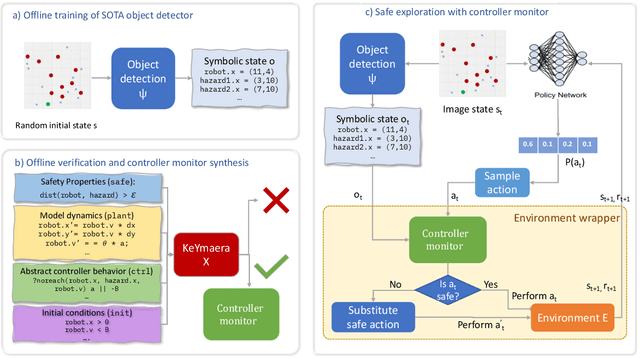
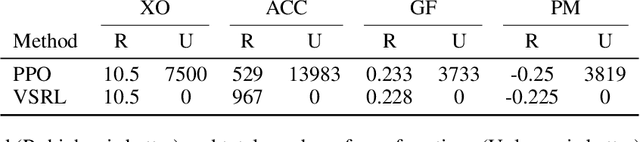
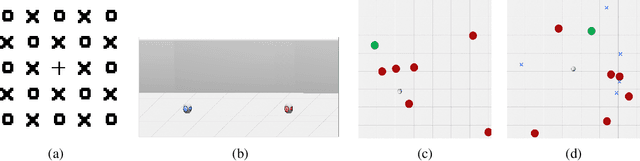

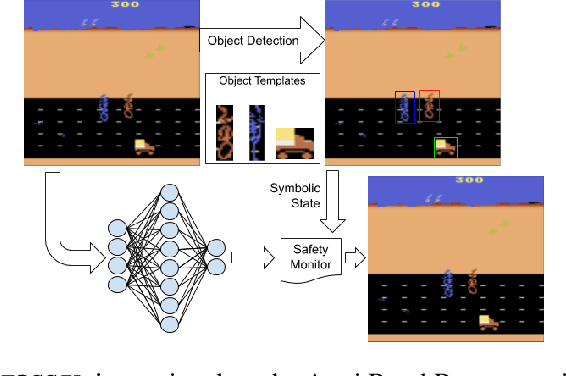
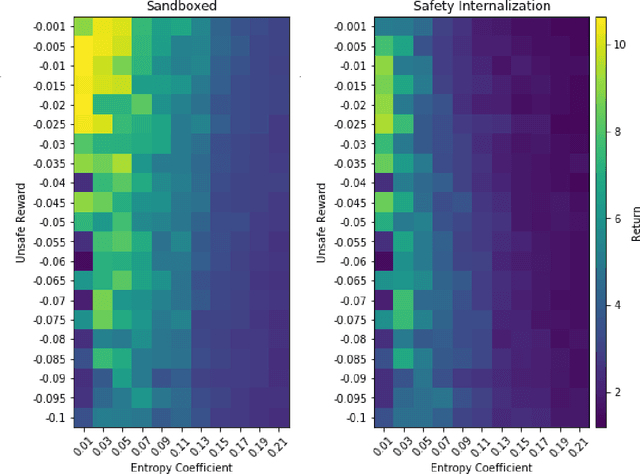
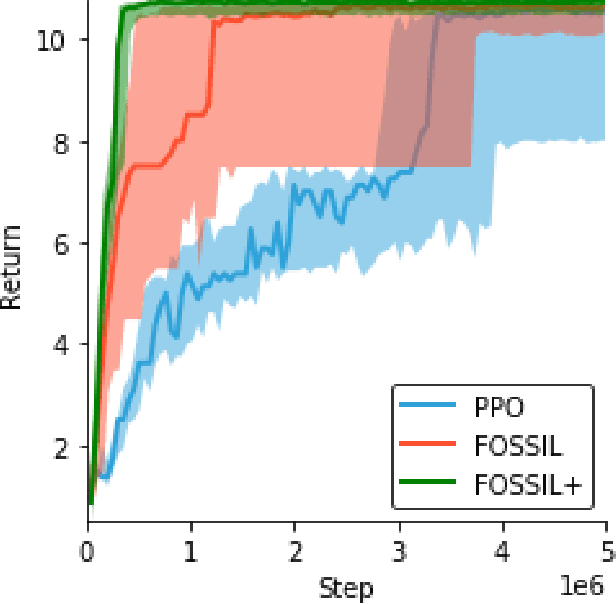
Deploying deep reinforcement learning in safety-critical settings requires developing algorithms that obey hard constraints during exploration. This paper contributes a first approach toward enforcing formal safety constraints on end-to-end policies with visual inputs. Our approach draws on recent advances in object detection and automated reasoning for hybrid dynamical systems. The approach is evaluated on a novel benchmark that emphasizes the challenge of safely exploring in the presence of hard constraints. Our benchmark draws from several proposed problem sets for safe learning and includes problems that emphasize challenges such as reward signals that are not aligned with safety constraints. On each of these benchmark problems, our algorithm completely avoids unsafe behavior while remaining competitive at optimizing for as much reward as is safe. We also prove that our method of enforcing the safety constraints preserves all safe policies from the original environment.
Formal Verification of End-to-End Learning in Cyber-Physical Systems: Progress and Challenges
Jun 15, 2020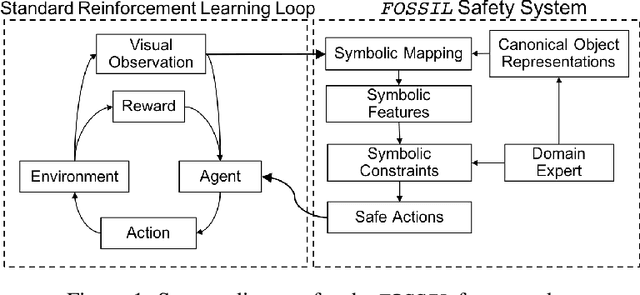
Autonomous systems -- such as self-driving cars, autonomous drones, and automated trains -- must come with strong safety guarantees. Over the past decade, techniques based on formal methods have enjoyed some success in providing strong correctness guarantees for large software systems including operating system kernels, cryptographic protocols, and control software for drones. These successes suggest it might be possible to ensure the safety of autonomous systems by constructing formal, computer-checked correctness proofs. This paper identifies three assumptions underlying existing formal verification techniques, explains how each of these assumptions limits the applicability of verification in autonomous systems, and summarizes preliminary work toward improving the strength of evidence provided by formal verification.
Verifiably Safe Off-Model Reinforcement Learning
Feb 14, 2019
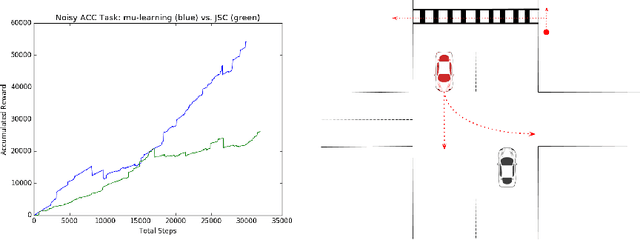
The desire to use reinforcement learning in safety-critical settings has inspired a recent interest in formal methods for learning algorithms. Existing formal methods for learning and optimization primarily consider the problem of constrained learning or constrained optimization. Given a single correct model and associated safety constraint, these approaches guarantee efficient learning while provably avoiding behaviors outside the safety constraint. Acting well given an accurate environmental model is an important pre-requisite for safe learning, but is ultimately insufficient for systems that operate in complex heterogeneous environments. This paper introduces verification-preserving model updates, the first approach toward obtaining formal safety guarantees for reinforcement learning in settings where multiple environmental models must be taken into account. Through a combination of design-time model updates and runtime model falsification, we provide a first approach toward obtaining formal safety proofs for autonomous systems acting in heterogeneous environments.