 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRip van Winkle's Razor: A Simple Estimate of Overfit to Test Data
Feb 25, 2021
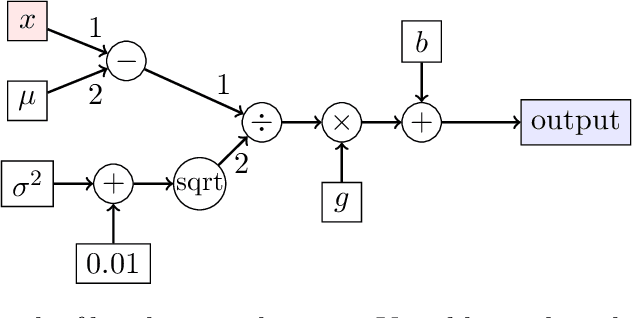

Traditional statistics forbids use of test data (a.k.a. holdout data) during training. Dwork et al. 2015 pointed out that current practices in machine learning, whereby researchers build upon each other's models, copying hyperparameters and even computer code -- amounts to implicitly training on the test set. Thus error rate on test data may not reflect the true population error. This observation initiated {\em adaptive data analysis}, which provides evaluation mechanisms with guaranteed upper bounds on this difference. With statistical query (i.e. test accuracy) feedbacks, the best upper bound is fairly pessimistic: the deviation can hit a practically vacuous value if the number of models tested is quadratic in the size of the test set. In this work, we present a simple new estimate, {\em Rip van Winkle's Razor}. It relies upon a new notion of \textquotedblleft information content\textquotedblright\ of a model: the amount of information that would have to be provided to an expert referee who is intimately familiar with the field and relevant science/math, and who has been just been woken up after falling asleep at the moment of the creation of the test data (like \textquotedblleft Rip van Winkle\textquotedblright\ of the famous fairy tale). This notion of information content is used to provide an estimate of the above deviation which is shown to be non-vacuous in many modern settings.
On the Validity of Modeling SGD with Stochastic Differential Equations
Feb 24, 2021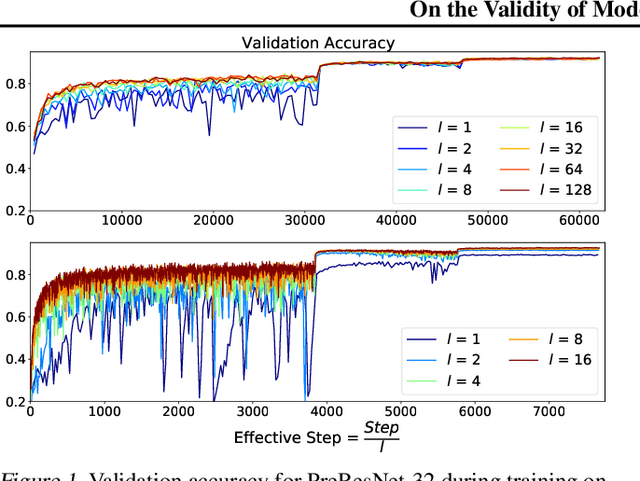
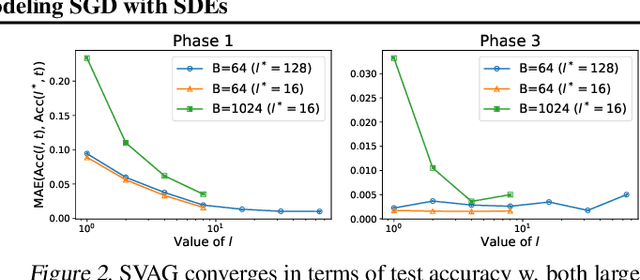
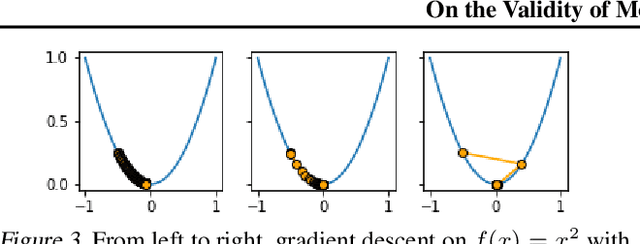
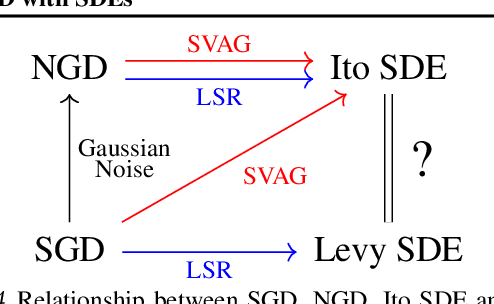
It is generally recognized that finite learning rate (LR), in contrast to infinitesimal LR, is important for good generalization in real-life deep nets. Most attempted explanations propose approximating finite-LR SGD with Ito Stochastic Differential Equations (SDEs). But formal justification for this approximation (e.g., (Li et al., 2019a)) only applies to SGD with tiny LR. Experimental verification of the approximation appears computationally infeasible. The current paper clarifies the picture with the following contributions: (a) An efficient simulation algorithm SVAG that provably converges to the conventionally used Ito SDE approximation. (b) Experiments using this simulation to demonstrate that the previously proposed SDE approximation can meaningfully capture the training and generalization properties of common deep nets. (c) A provable and empirically testable necessary condition for the SDE approximation to hold and also its most famous implication, the linear scaling rule (Smith et al., 2020; Goyal et al., 2017). The analysis also gives rigorous insight into why the SDE approximation may fail.
Why Are Convolutional Nets More Sample-Efficient than Fully-Connected Nets?
Oct 16, 2020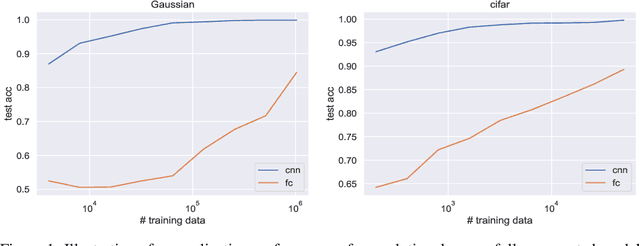

Convolutional neural networks often dominate fully-connected counterparts in generalization performance, especially on image classification tasks. This is often explained in terms of 'better inductive bias'. However, this has not been made mathematically rigorous, and the hurdle is that the fully connected net can always simulate the convolutional net (for a fixed task). Thus the training algorithm plays a role. The current work describes a natural task on which a provable sample complexity gap can be shown, for standard training algorithms. We construct a single natural distribution on $\mathbb{R}^d\times\{\pm 1\}$ on which any orthogonal-invariant algorithm (i.e. fully-connected networks trained with most gradient-based methods from gaussian initialization) requires $\Omega(d^2)$ samples to generalize while $O(1)$ samples suffice for convolutional architectures. Furthermore, we demonstrate a single target function, learning which on all possible distributions leads to an $O(1)$ vs $\Omega(d^2/\varepsilon)$ gap. The proof relies on the fact that SGD on fully-connected network is orthogonal equivariant. Similar results are achieved for $\ell_2$ regression and adaptive training algorithms, e.g. Adam and AdaGrad, which are only permutation equivariant.
TextHide: Tackling Data Privacy in Language Understanding Tasks
Oct 12, 2020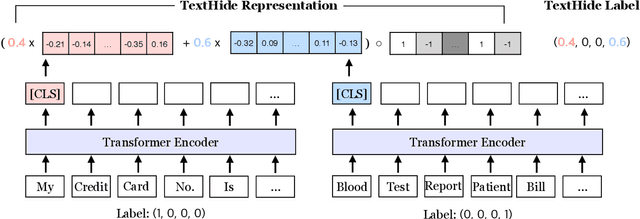
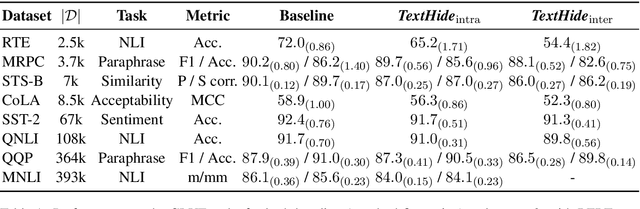
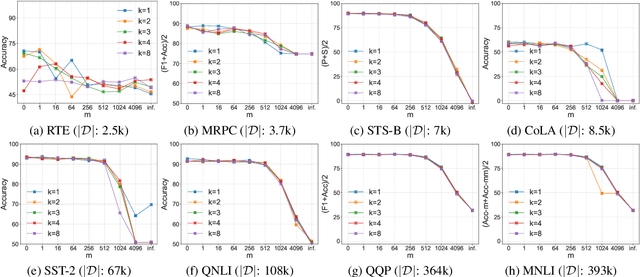
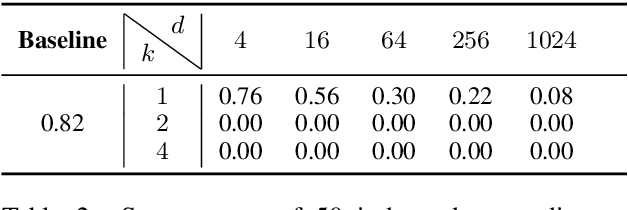
An unsolved challenge in distributed or federated learning is to effectively mitigate privacy risks without slowing down training or reducing accuracy. In this paper, we propose TextHide aiming at addressing this challenge for natural language understanding tasks. It requires all participants to add a simple encryption step to prevent an eavesdropping attacker from recovering private text data. Such an encryption step is efficient and only affects the task performance slightly. In addition, TextHide fits well with the popular framework of fine-tuning pre-trained language models (e.g., BERT) for any sentence or sentence-pair task. We evaluate TextHide on the GLUE benchmark, and our experiments show that TextHide can effectively defend attacks on shared gradients or representations and the averaged accuracy reduction is only $1.9\%$. We also present an analysis of the security of TextHide using a conjecture about the computational intractability of a mathematical problem. Our code is available at https://github.com/Hazelsuko07/TextHide
A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks
Oct 07, 2020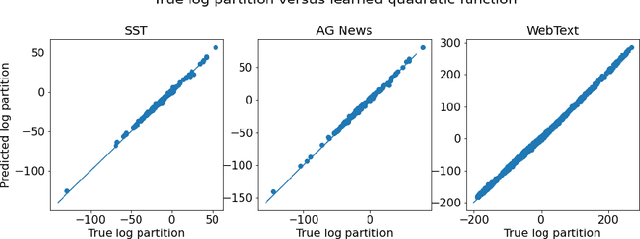
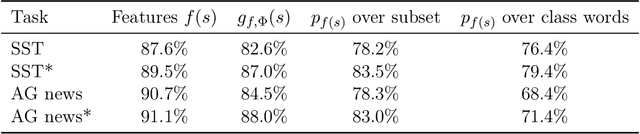

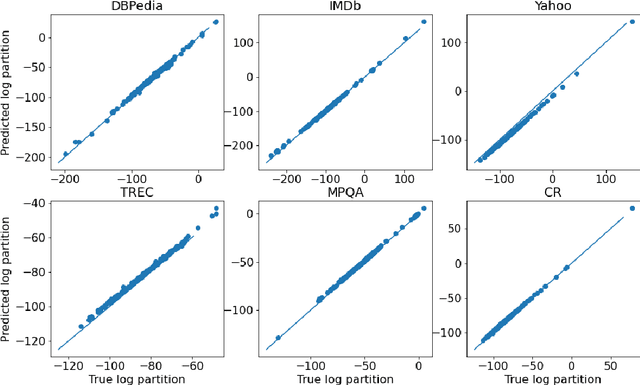
Autoregressive language models pretrained on large corpora have been successful at solving downstream tasks, even with zero-shot usage. However, there is little theoretical justification for their success. This paper considers the following questions: (1) Why should learning the distribution of natural language help with downstream classification tasks? (2) Why do features learned using language modeling help solve downstream tasks with linear classifiers? For (1), we hypothesize, and verify empirically, that classification tasks of interest can be reformulated as next word prediction tasks, thus making language modeling a meaningful pretraining task. For (2), we analyze properties of the cross-entropy objective to show that $\epsilon$-optimal language models in cross-entropy (log-perplexity) learn features that are $\mathcal{O}(\sqrt{\epsilon})$-good on natural linear classification tasks, thus demonstrating mathematically that doing well on language modeling can be beneficial for downstream tasks. We perform experiments to verify assumptions and validate theoretical results. Our theoretical insights motivate a simple alternative to the cross-entropy objective that performs well on some linear classification tasks.
Reconciling Modern Deep Learning with Traditional Optimization Analyses: The Intrinsic Learning Rate
Oct 06, 2020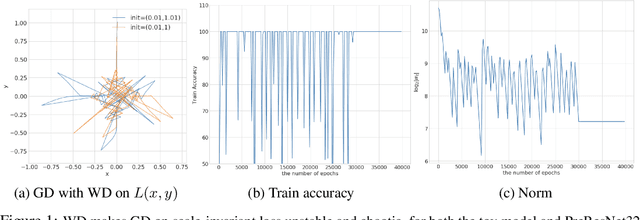

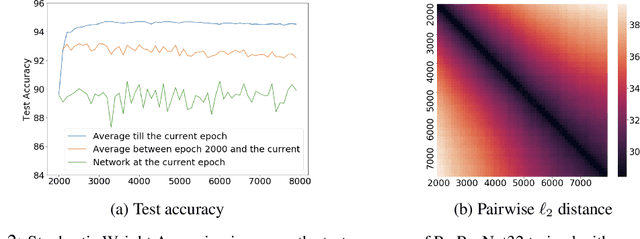
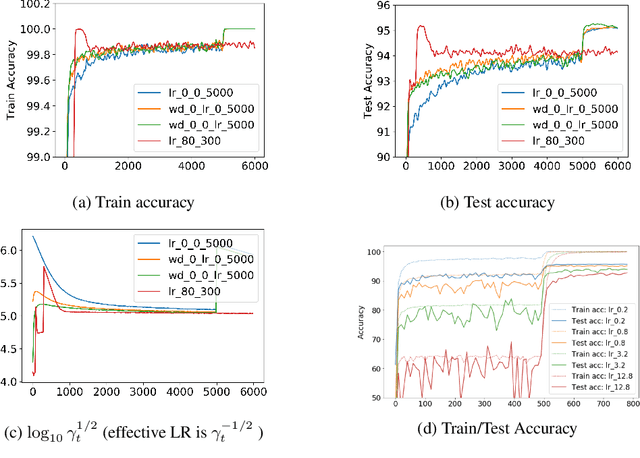
Recent works (e.g., (Li and Arora, 2020)) suggest that the use of popular normalization schemes (including Batch Normalization) in today's deep learning can move it far from a traditional optimization viewpoint, e.g., use of exponentially increasing learning rates. The current paper highlights other ways in which behavior of normalized nets departs from traditional viewpoints, and then initiates a formal framework for studying their mathematics via suitable adaptation of the conventional framework namely, modeling SGD-induced training trajectory via a suitable stochastic differential equation (SDE) with a noise term that captures gradient noise. This yields: (a) A new ' intrinsic learning rate' parameter that is the product of the normal learning rate and weight decay factor. Analysis of the SDE shows how the effective speed of learning varies and equilibrates over time under the control of intrinsic LR. (b) A challenge -- via theory and experiments -- to popular belief that good generalization requires large learning rates at the start of training. (c) New experiments, backed by mathematical intuition, suggesting the number of steps to equilibrium (in function space) scales as the inverse of the intrinsic learning rate, as opposed to the exponential time convergence bound implied by SDE analysis. We name it the Fast Equilibrium Conjecture and suggest it holds the key to why Batch Normalization is effective.
InstaHide: Instance-hiding Schemes for Private Distributed Learning
Oct 06, 2020

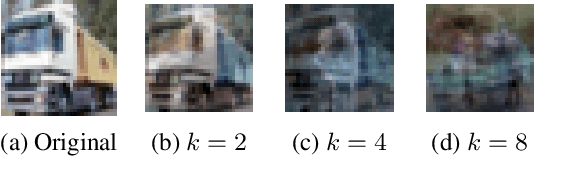
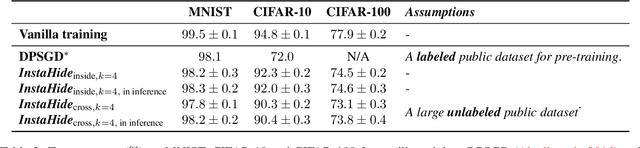
How can multiple distributed entities collaboratively train a shared deep net on their private data while preserving privacy? This paper introduces InstaHide, a simple encryption of training images, which can be plugged into existing distributed deep learning pipelines. The encryption is efficient and applying it during training has minor effect on test accuracy. InstaHide encrypts each training image with a "one-time secret key" which consists of mixing a number of randomly chosen images and applying a random pixel-wise mask. Other contributions of this paper include: (a) Using a large public dataset (e.g. ImageNet) for mixing during its encryption, which improves security. (b) Experimental results to show effectiveness in preserving privacy against known attacks with only minor effects on accuracy. (c) Theoretical analysis showing that successfully attacking privacy requires attackers to solve a difficult computational problem. (d) Demonstrating that use of the pixel-wise mask is important for security, since Mixup alone is shown to be insecure to some some efficient attacks. (e) Release of a challenge dataset https://github.com/Hazelsuko07/InstaHide_Challenge Our code is available at https://github.com/Hazelsuko07/InstaHide
Privacy-preserving Learning via Deep Net Pruning
Mar 04, 2020


This paper attempts to answer the question whether neural network pruning can be used as a tool to achieve differential privacy without losing much data utility. As a first step towards understanding the relationship between neural network pruning and differential privacy, this paper proves that pruning a given layer of the neural network is equivalent to adding a certain amount of differentially private noise to its hidden-layer activations. The paper also presents experimental results to show the practical implications of the theoretical finding and the key parameter values in a simple practical setting. These results show that neural network pruning can be a more effective alternative to adding differentially private noise for neural networks.
A Sample Complexity Separation between Non-Convex and Convex Meta-Learning
Feb 25, 2020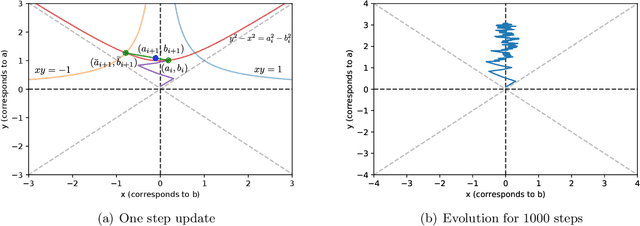
One popular trend in meta-learning is to learn from many training tasks a common initialization for a gradient-based method that can be used to solve a new task with few samples. The theory of meta-learning is still in its early stages, with several recent learning-theoretic analyses of methods such as Reptile [Nichol et al., 2018] being for convex models. This work shows that convex-case analysis might be insufficient to understand the success of meta-learning, and that even for non-convex models it is important to look inside the optimization black-box, specifically at properties of the optimization trajectory. We construct a simple meta-learning instance that captures the problem of one-dimensional subspace learning. For the convex formulation of linear regression on this instance, we show that the new task sample complexity of any initialization-based meta-learning algorithm is $\Omega(d)$, where $d$ is the input dimension. In contrast, for the non-convex formulation of a two layer linear network on the same instance, we show that both Reptile and multi-task representation learning can have new task sample complexity of $\mathcal{O}(1)$, demonstrating a separation from convex meta-learning. Crucially, analyses of the training dynamics of these methods reveal that they can meta-learn the correct subspace onto which the data should be projected.
Provable Representation Learning for Imitation Learning via Bi-level Optimization
Feb 24, 2020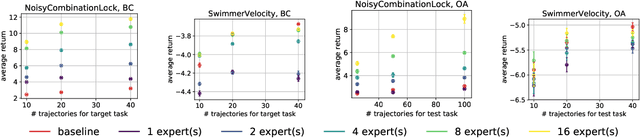

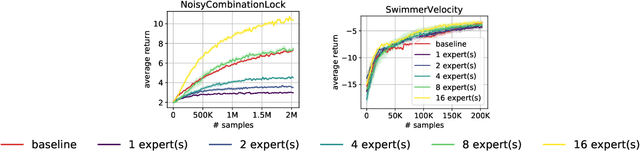
A common strategy in modern learning systems is to learn a representation that is useful for many tasks, a.k.a. representation learning. We study this strategy in the imitation learning setting for Markov decision processes (MDPs) where multiple experts' trajectories are available. We formulate representation learning as a bi-level optimization problem where the "outer" optimization tries to learn the joint representation and the "inner" optimization encodes the imitation learning setup and tries to learn task-specific parameters. We instantiate this framework for the imitation learning settings of behavior cloning and observation-alone. Theoretically, we show using our framework that representation learning can provide sample complexity benefits for imitation learning in both settings. We also provide proof-of-concept experiments to verify our theory.