 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenDamage: Structured Pruning in the Kronecker-Factored Eigenbasis
May 15, 2019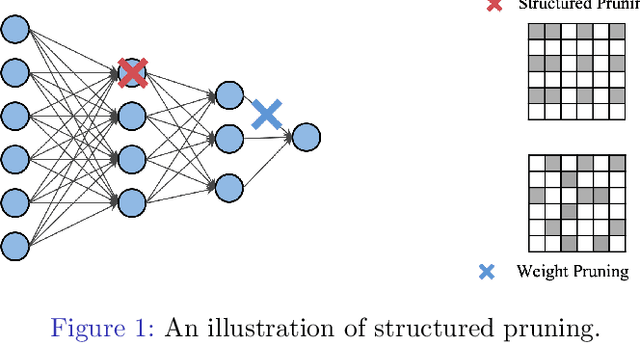
Reducing the test time resource requirements of a neural network while preserving test accuracy is crucial for running inference on resource-constrained devices. To achieve this goal, we introduce a novel network reparameterization based on the Kronecker-factored eigenbasis (KFE), and then apply Hessian-based structured pruning methods in this basis. As opposed to existing Hessian-based pruning algorithms which do pruning in parameter coordinates, our method works in the KFE where different weights are approximately independent, enabling accurate pruning and fast computation. We demonstrate empirically the effectiveness of the proposed method through extensive experiments. In particular, we highlight that the improvements are especially significant for more challenging datasets and networks. With negligible loss of accuracy, an iterative-pruning version gives a 10$\times$ reduction in model size and a 8$\times$ reduction in FLOPs on wide ResNet32.
DARNet: Deep Active Ray Network for Building Segmentation
May 15, 2019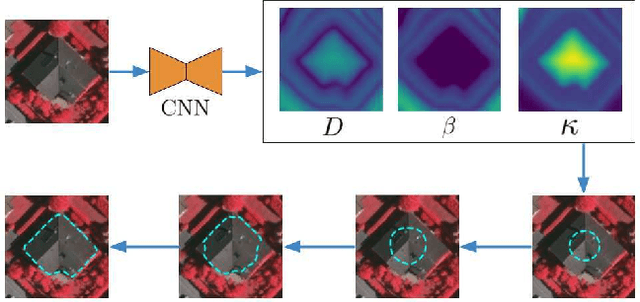

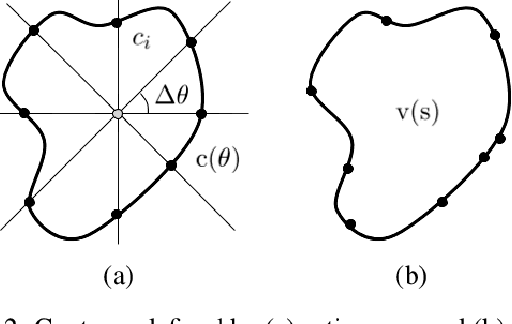
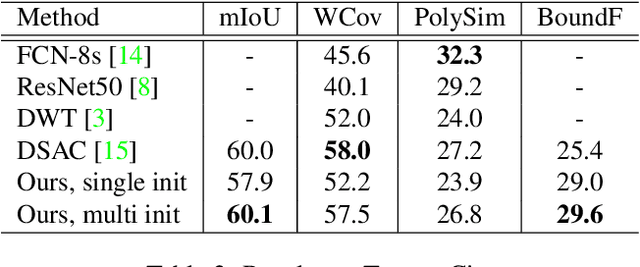
In this paper, we propose a Deep Active Ray Network (DARNet) for automatic building segmentation. Taking an image as input, it first exploits a deep convolutional neural network (CNN) as the backbone to predict energy maps, which are further utilized to construct an energy function. A polygon-based contour is then evolved via minimizing the energy function, of which the minimum defines the final segmentation. Instead of parameterizing the contour using Euclidean coordinates, we adopt polar coordinates, i.e., rays, which not only prevents self-intersection but also simplifies the design of the energy function. Moreover, we propose a loss function that directly encourages the contours to match building boundaries. Our DARNet is trained end-to-end by back-propagating through the energy minimization and the backbone CNN, which makes the CNN adapt to the dynamics of the contour evolution. Experiments on three building instance segmentation datasets demonstrate our DARNet achieves either state-of-the-art or comparable performances to other competitors.
Meta-Sim: Learning to Generate Synthetic Datasets
Apr 25, 2019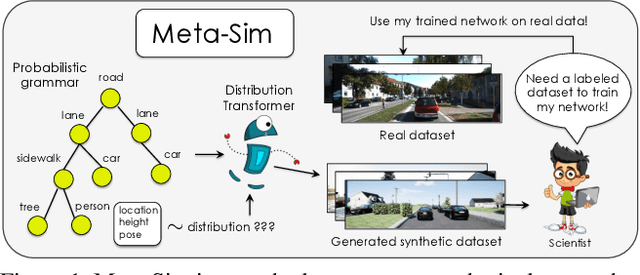
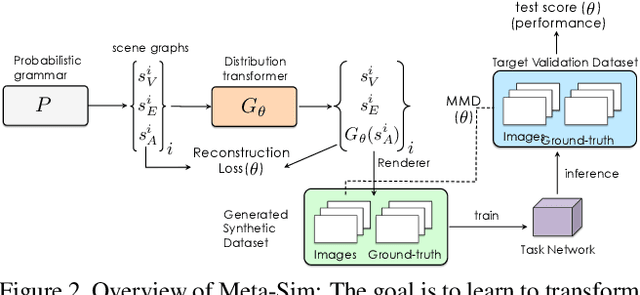
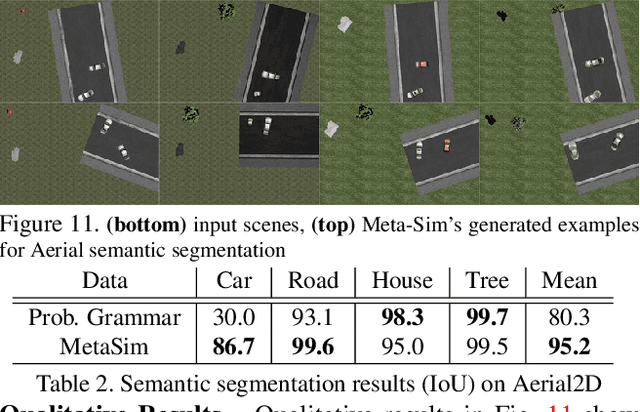
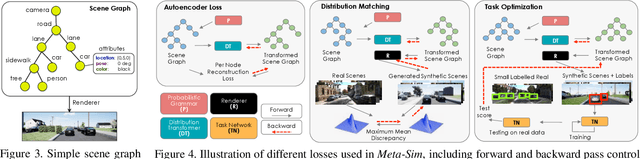
Training models to high-end performance requires availability of large labeled datasets, which are expensive to get. The goal of our work is to automatically synthesize labeled datasets that are relevant for a downstream task. We propose Meta-Sim, which learns a generative model of synthetic scenes, and obtain images as well as its corresponding ground-truth via a graphics engine. We parametrize our dataset generator with a neural network, which learns to modify attributes of scene graphs obtained from probabilistic scene grammars, so as to minimize the distribution gap between its rendered outputs and target data. If the real dataset comes with a small labeled validation set, we additionally aim to optimize a meta-objective, i.e. downstream task performance. Experiments show that the proposed method can greatly improve content generation quality over a human-engineered probabilistic scene grammar, both qualitatively and quantitatively as measured by performance on a downstream task.
Devil is in the Edges: Learning Semantic Boundaries from Noisy Annotations
Apr 16, 2019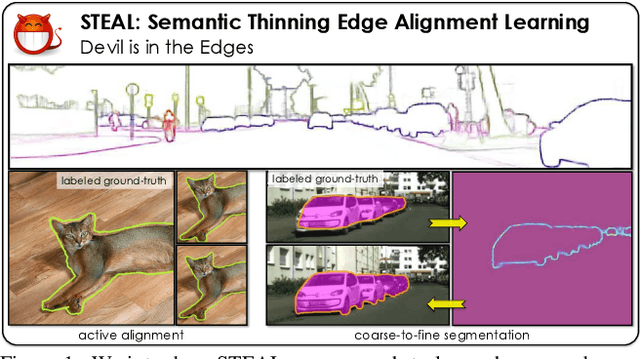
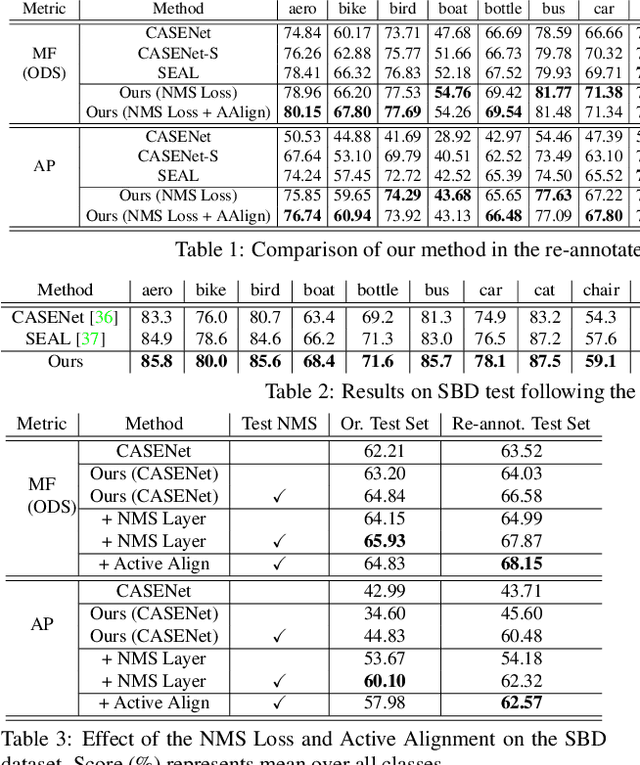
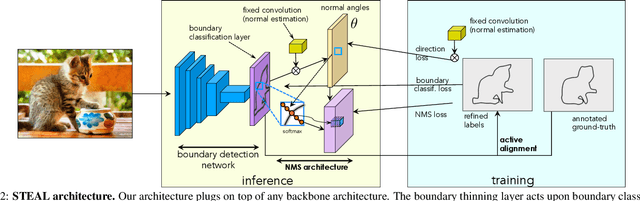
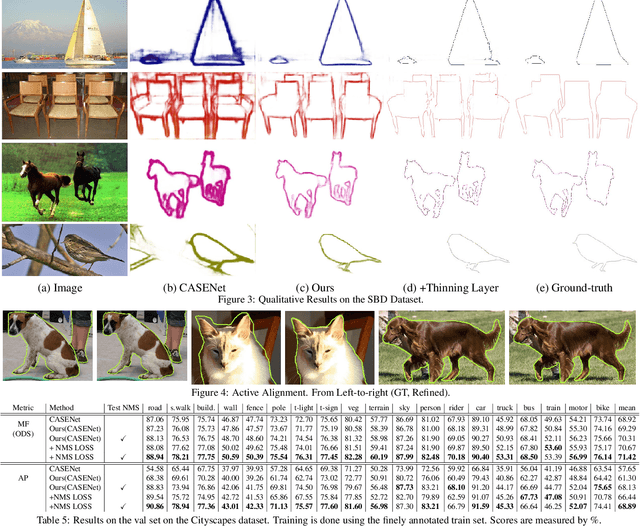
We tackle the problem of semantic boundary prediction, which aims to identify pixels that belong to object(class) boundaries. We notice that relevant datasets consist of a significant level of label noise, reflecting the fact that precise annotations are laborious to get and thus annotators trade-off quality with efficiency. We aim to learn sharp and precise semantic boundaries by explicitly reasoning about annotation noise during training. We propose a simple new layer and loss that can be used with existing learning-based boundary detectors. Our layer/loss enforces the detector to predict a maximum response along the normal direction at an edge, while also regularizing its direction. We further reason about true object boundaries during training using a level set formulation, which allows the network to learn from misaligned labels in an end-to-end fashion. Experiments show that we improve over the CASENet backbone network by more than 4% in terms of MF(ODS) and 18.61% in terms of AP, outperforming all current state-of-the-art methods including those that deal with alignment. Furthermore, we show that our learned network can be used to significantly improve coarse segmentation labels, lending itself as an efficient way to label new data.
* Accepted as a CVPR 2019 oral paper (Project Page: https://nv-tlabs.github.io/STEAL/)
Action Recognition from Single Timestamp Supervision in Untrimmed Videos
Apr 09, 2019
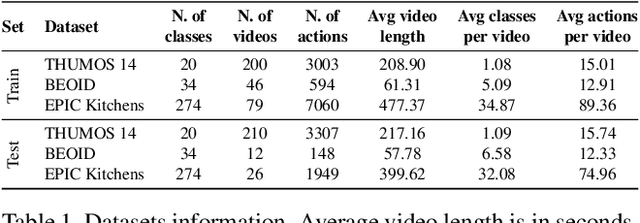

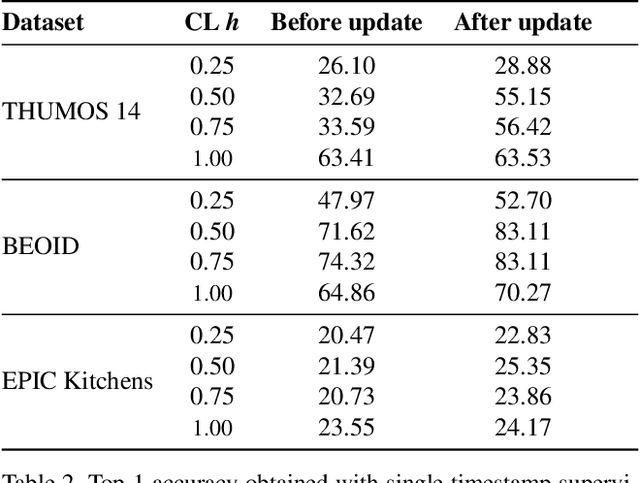
Recognising actions in videos relies on labelled supervision during training, typically the start and end times of each action instance. This supervision is not only subjective, but also expensive to acquire. Weak video-level supervision has been successfully exploited for recognition in untrimmed videos, however it is challenged when the number of different actions in training videos increases. We propose a method that is supervised by single timestamps located around each action instance, in untrimmed videos. We replace expensive action bounds with sampling distributions initialised from these timestamps. We then use the classifier's response to iteratively update the sampling distributions. We demonstrate that these distributions converge to the location and extent of discriminative action segments. We evaluate our method on three datasets for fine-grained recognition, with increasing number of different actions per video, and show that single timestamps offer a reasonable compromise between recognition performance and labelling effort, performing comparably to full temporal supervision. Our update method improves top-1 test accuracy by up to 5.4%. across the evaluated datasets.
Mimicking the In-Camera Color Pipeline for Camera-Aware Object Compositing
Mar 27, 2019
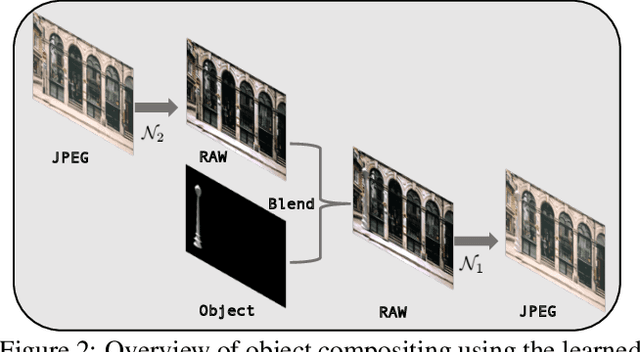
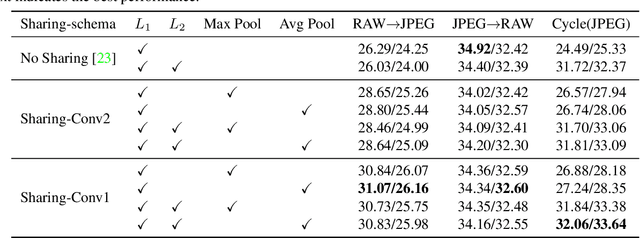
We present a method for compositing virtual objects into a photograph such that the object colors appear to have been processed by the photo's camera imaging pipeline. Compositing in such a camera-aware manner is essential for high realism, and it requires the color transformation in the photo's pipeline to be inferred, which is challenging due to the inherent one-to-many mapping that exists from a scene to a photo. To address this problem for the case of a single photo taken from an unknown camera, we propose a dual-learning approach in which the reverse color transformation (from the photo to the scene) is jointly estimated. Learning of the reverse transformation is used to facilitate learning of the forward mapping, by enforcing cycle consistency of the two processes. We additionally employ a feature sharing schema to extract evidence from the target photo in the reverse mapping to guide the forward color transformation. Our dual-learning approach achieves object compositing results that surpass those of alternative techniques.
Fast Interactive Object Annotation with Curve-GCN
Mar 16, 2019


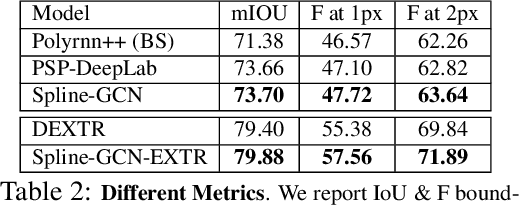
Manually labeling objects by tracing their boundaries is a laborious process. In Polygon-RNN++ the authors proposed Polygon-RNN that produces polygonal annotations in a recurrent manner using a CNN-RNN architecture, allowing interactive correction via humans-in-the-loop. We propose a new framework that alleviates the sequential nature of Polygon-RNN, by predicting all vertices simultaneously using a Graph Convolutional Network (GCN). Our model is trained end-to-end. It supports object annotation by either polygons or splines, facilitating labeling efficiency for both line-based and curved objects. We show that Curve-GCN outperforms all existing approaches in automatic mode, including the powerful PSP-DeepLab and is significantly more efficient in interactive mode than Polygon-RNN++. Our model runs at 29.3ms in automatic, and 2.6ms in interactive mode, making it 10x and 100x faster than Polygon-RNN++.
ACTRCE: Augmenting Experience via Teacher's Advice For Multi-Goal Reinforcement Learning
Feb 12, 2019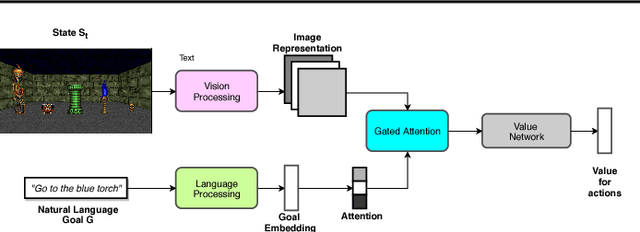
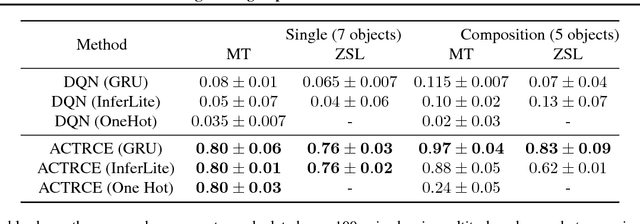
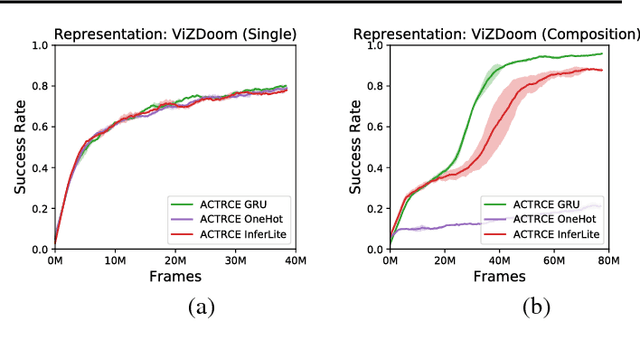

Sparse reward is one of the most challenging problems in reinforcement learning (RL). Hindsight Experience Replay (HER) attempts to address this issue by converting a failed experience to a successful one by relabeling the goals. Despite its effectiveness, HER has limited applicability because it lacks a compact and universal goal representation. We present Augmenting experienCe via TeacheR's adviCE (ACTRCE), an efficient reinforcement learning technique that extends the HER framework using natural language as the goal representation. We first analyze the differences among goal representation, and show that ACTRCE can efficiently solve difficult reinforcement learning problems in challenging 3D navigation tasks, whereas HER with non-language goal representation failed to learn. We also show that with language goal representations, the agent can generalize to unseen instructions, and even generalize to instructions with unseen lexicons. We further demonstrate it is crucial to use hindsight advice to solve challenging tasks, and even small amount of advice is sufficient for the agent to achieve good performance.
A Face-to-Face Neural Conversation Model
Dec 04, 2018
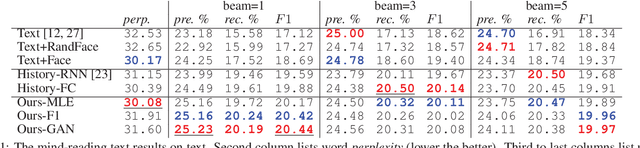

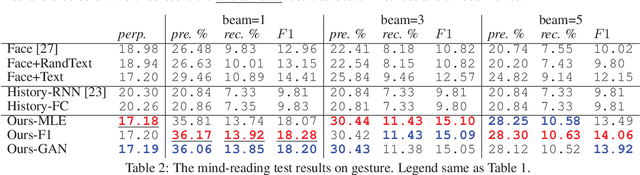
Neural networks have recently become good at engaging in dialog. However, current approaches are based solely on verbal text, lacking the richness of a real face-to-face conversation. We propose a neural conversation model that aims to read and generate facial gestures alongside with text. This allows our model to adapt its response based on the "mood" of the conversation. In particular, we introduce an RNN encoder-decoder that exploits the movement of facial muscles, as well as the verbal conversation. The decoder consists of two layers, where the lower layer aims at generating the verbal response and coarse facial expressions, while the second layer fills in the subtle gestures, making the generated output more smooth and natural. We train our neural network by having it "watch" 250 movies. We showcase our joint face-text model in generating more natural conversations through automatic metrics and a human study. We demonstrate an example application with a face-to-face chatting avatar.
* Published at CVPR 2018
SurfConv: Bridging 3D and 2D Convolution for RGBD Images
Dec 04, 2018
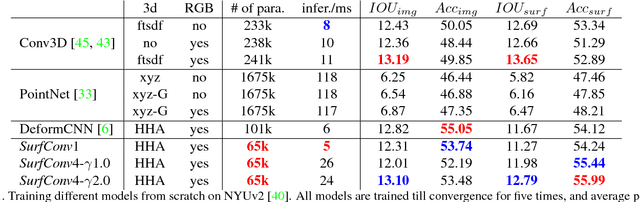
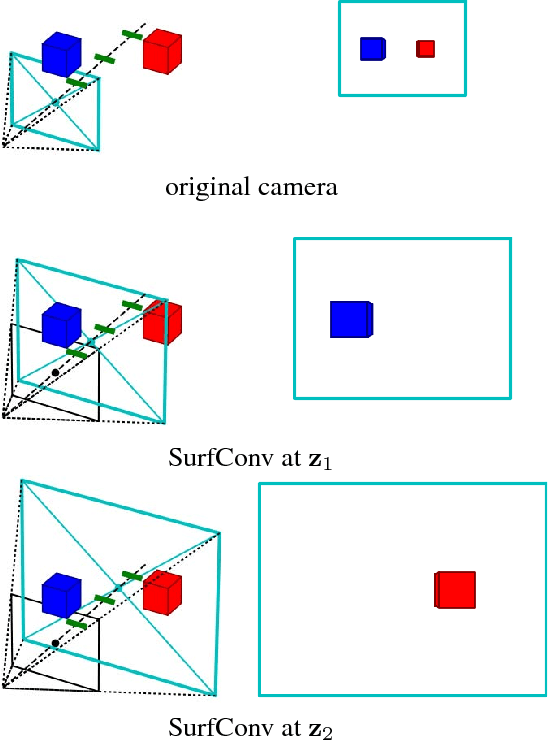
We tackle the problem of using 3D information in convolutional neural networks for down-stream recognition tasks. Using depth as an additional channel alongside the RGB input has the scale variance problem present in image convolution based approaches. On the other hand, 3D convolution wastes a large amount of memory on mostly unoccupied 3D space, which consists of only the surface visible to the sensor. Instead, we propose SurfConv, which "slides" compact 2D filters along the visible 3D surface. SurfConv is formulated as a simple depth-aware multi-scale 2D convolution, through a new Data-Driven Depth Discretization (D4) scheme. We demonstrate the effectiveness of our method on indoor and outdoor 3D semantic segmentation datasets. Our method achieves state-of-the-art performance with less than 30% parameters used by the 3D convolution-based approaches.
* Published at CVPR 2018