 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

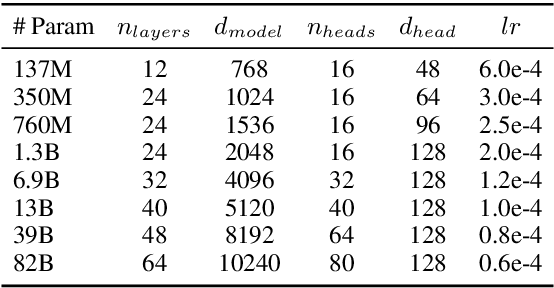
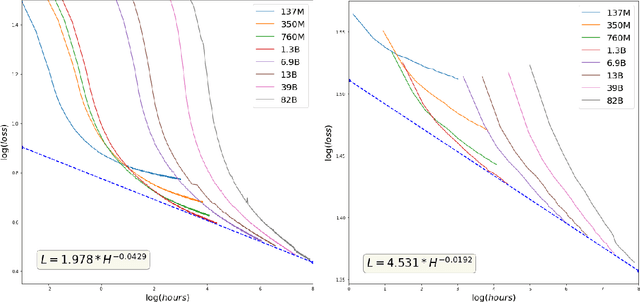
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
Weakly Supervised Pre-Training for Multi-Hop Retriever
Jun 18, 2021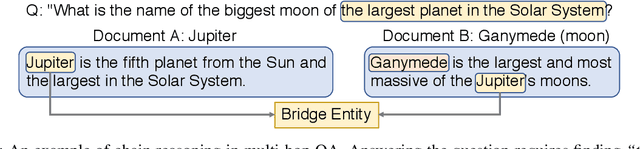


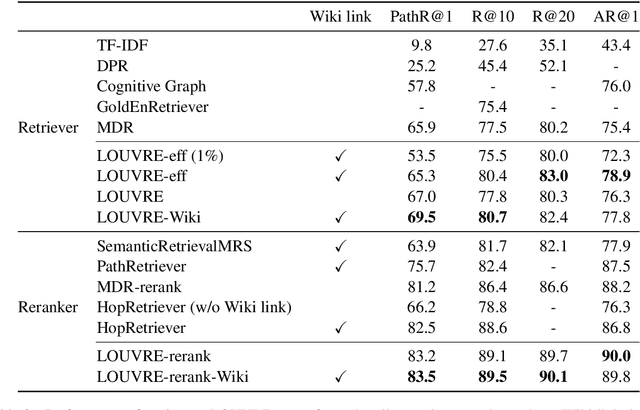
In multi-hop QA, answering complex questions entails iterative document retrieval for finding the missing entity of the question. The main steps of this process are sub-question detection, document retrieval for the sub-question, and generation of a new query for the final document retrieval. However, building a dataset that contains complex questions with sub-questions and their corresponding documents requires costly human annotation. To address the issue, we propose a new method for weakly supervised multi-hop retriever pre-training without human efforts. Our method includes 1) a pre-training task for generating vector representations of complex questions, 2) a scalable data generation method that produces the nested structure of question and sub-question as weak supervision for pre-training, and 3) a pre-training model structure based on dense encoders. We conduct experiments to compare the performance of our pre-trained retriever with several state-of-the-art models on end-to-end multi-hop QA as well as document retrieval. The experimental results show that our pre-trained retriever is effective and also robust on limited data and computational resources.
NeuralWOZ: Learning to Collect Task-Oriented Dialogue via Model-Based Simulation
May 30, 2021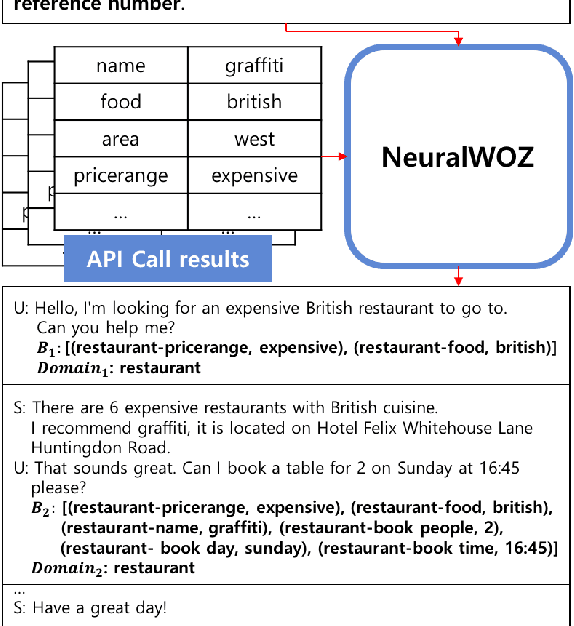
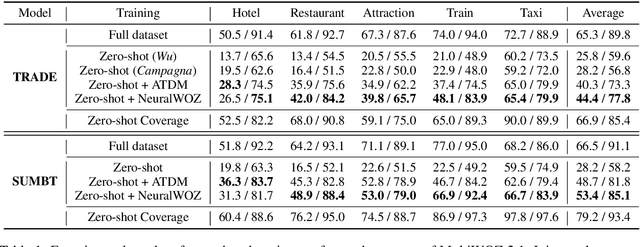
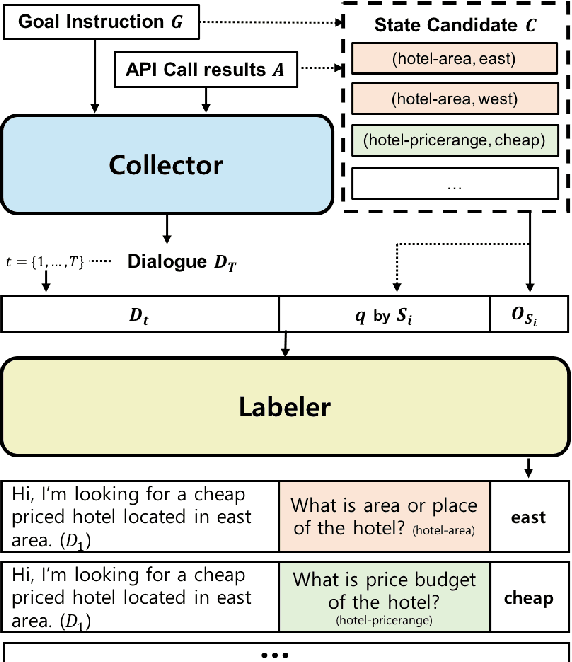
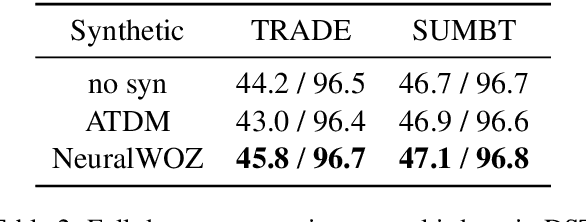
We propose NeuralWOZ, a novel dialogue collection framework that uses model-based dialogue simulation. NeuralWOZ has two pipelined models, Collector and Labeler. Collector generates dialogues from (1) user's goal instructions, which are the user context and task constraints in natural language, and (2) system's API call results, which is a list of possible query responses for user requests from the given knowledge base. Labeler annotates the generated dialogue by formulating the annotation as a multiple-choice problem, in which the candidate labels are extracted from goal instructions and API call results. We demonstrate the effectiveness of the proposed method in the zero-shot domain transfer learning for dialogue state tracking. In the evaluation, the synthetic dialogue corpus generated from NeuralWOZ achieves a new state-of-the-art with improvements of 4.4% point joint goal accuracy on average across domains, and improvements of 5.7% point of zero-shot coverage against the MultiWOZ 2.1 dataset.
GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation
Apr 18, 2021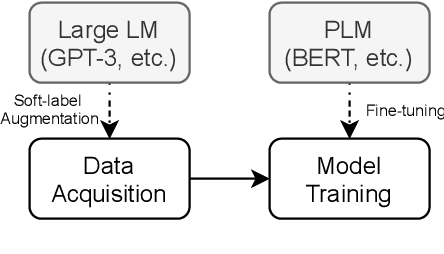
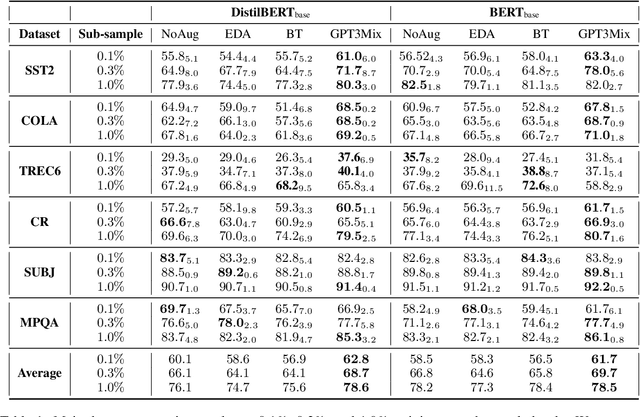
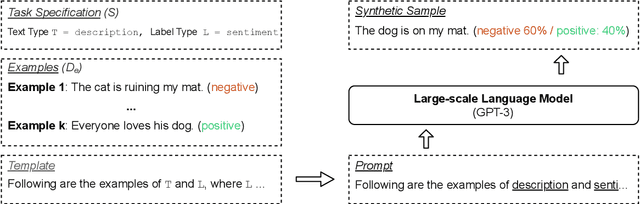
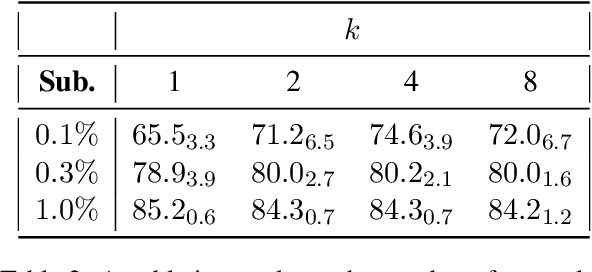
Large-scale language models such as GPT-3 are excellent few-shot learners, allowing them to be controlled via natural text prompts. Recent studies report that prompt-based direct classification eliminates the need for fine-tuning but lacks data and inference scalability. This paper proposes a novel data augmentation technique that leverages large-scale language models to generate realistic text samples from a mixture of real samples. We also propose utilizing soft-labels predicted by the language models, effectively distilling knowledge from the large-scale language models and creating textual perturbations simultaneously. We perform data augmentation experiments on diverse classification tasks and show that our method hugely outperforms existing text augmentation methods. Ablation studies and a qualitative analysis provide more insights into our approach.
ST-BERT: Cross-modal Language Model Pre-training For End-to-end Spoken Language Understanding
Oct 23, 2020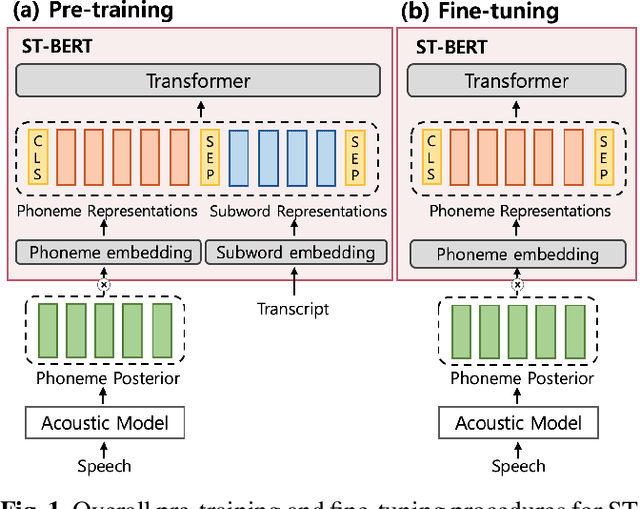
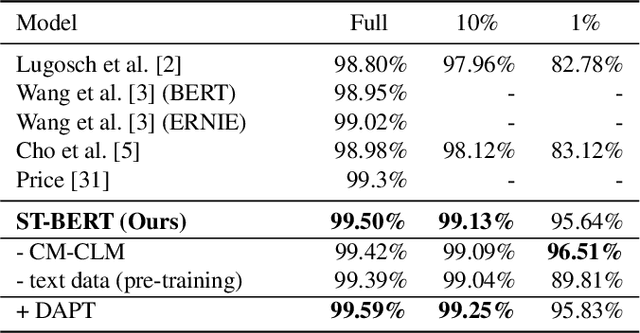
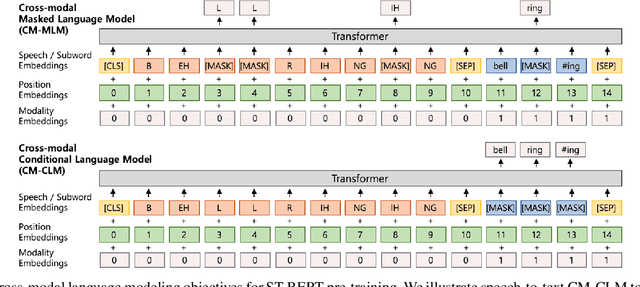
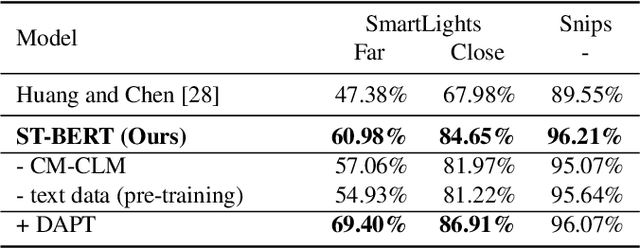
Language model pre-training has shown promising results in various downstream tasks. In this context, we introduce a cross-modal pre-trained language model, called Speech-Text BERT (ST-BERT), to tackle end-to-end spoken language understanding (E2E SLU) tasks. Taking phoneme posterior and subword-level text as an input, ST-BERT learns a contextualized cross-modal alignment via our two proposed pre-training tasks: Cross-modal Masked Language Modeling (CM-MLM) and Cross-modal Conditioned Language Modeling (CM-CLM). Experimental results on three benchmarks present that our approach is effective for various SLU datasets and shows a surprisingly marginal performance degradation even when 1% of the training data are available. Also, our method shows further SLU performance gain via domain-adaptive pre-training with domain-specific speech-text pair data.
CareCall: a Call-Based Active Monitoring Dialog Agent for Managing COVID-19 Pandemic
Jul 06, 2020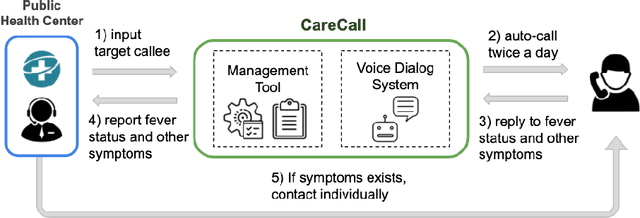
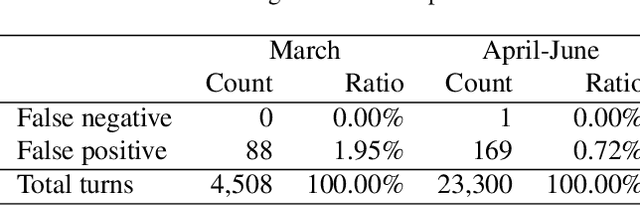
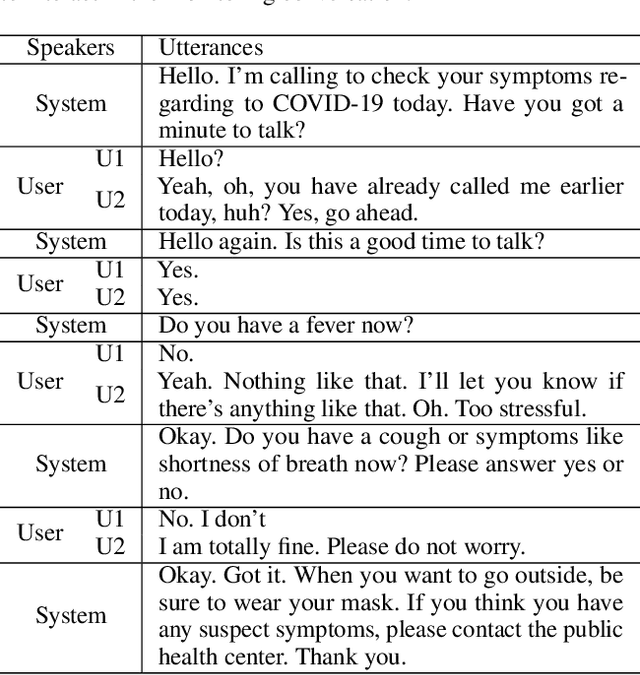
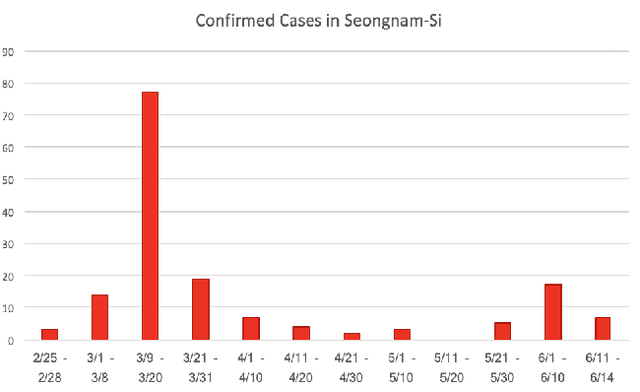
Tracking suspected cases of COVID-19 is crucial to suppressing the spread of COVID-19 pandemic. Active monitoring and proactive inspection are indispensable to mitigate COVID-19 spread, though these require considerable social and economic expense. To address this issue, we introduce CareCall, a call-based dialog agent which is deployed for active monitoring in Korea and Japan. We describe our system with a case study with statistics to show how the system works. Finally, we discuss a simple idea which uses CareCall to support proactive inspection.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
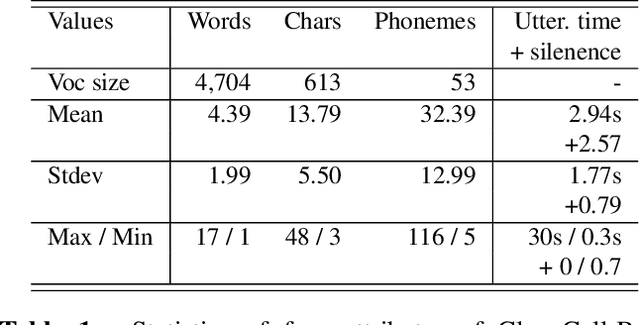
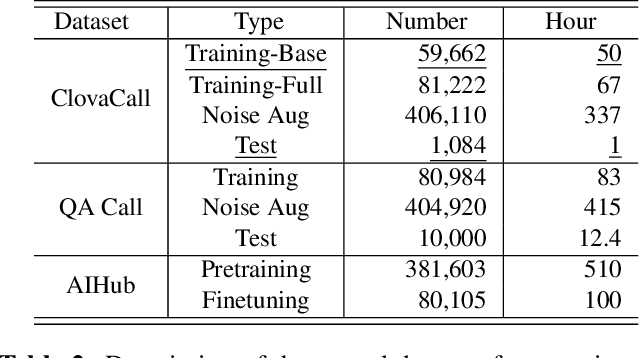
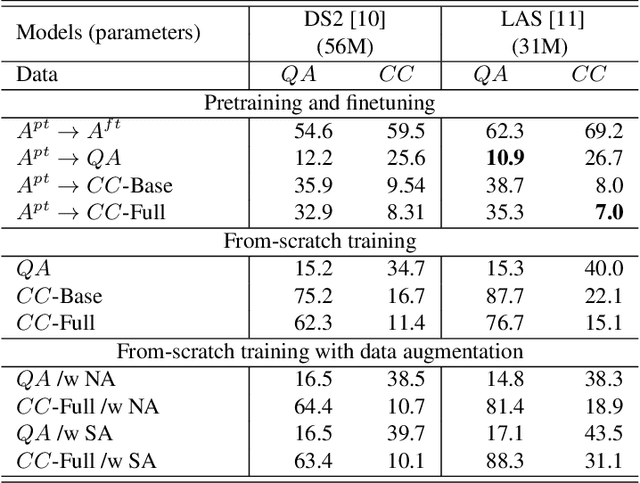
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Efficient Dialogue State Tracking by Selectively Overwriting Memory
Nov 10, 2019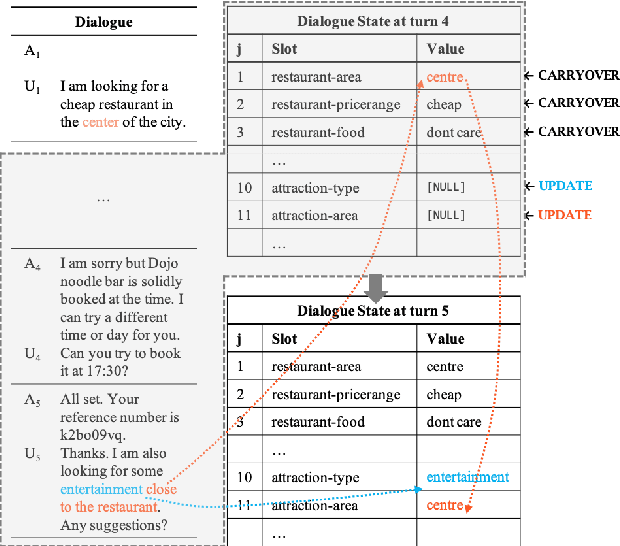
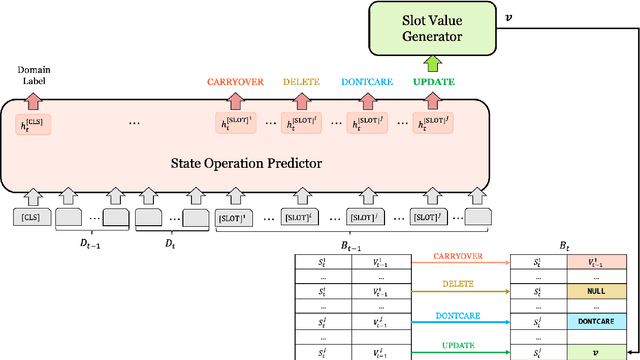
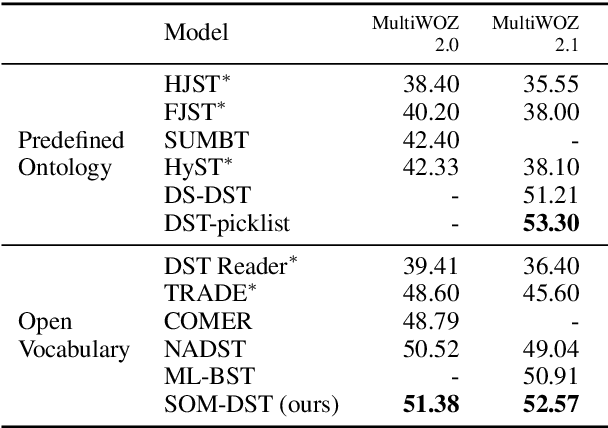
Recent works in dialogue state tracking (DST) focus on an open vocabulary-based setting to resolve scalability and generalization issues of the predefined ontology-based approaches. However, they are computationally inefficient in that they predict the dialogue state at every turn from scratch. In this paper, we consider dialogue state as an explicit fixed-sized memory, and propose a selectively overwriting mechanism for more efficient DST. This mechanism consists of two steps: (1) predicting state operation on each of the memory slots, and (2) overwriting the memory with new values, of which only a few are generated according to the predicted state operations. Moreover, reducing the burden of the decoder by decomposing DST into two sub-tasks and guiding the decoder to focus only one of the tasks enables a more effective training and improvement in the performance. As a result, our proposed SOM-DST (Selectively Overwriting Memory for Dialogue State Tracking) achieves state-of-the-art joint goal accuracy with 51.38% in MultiWOZ 2.0 and 52.57% in MultiWOZ 2.1 in an open vocabulary-based DST setting. In addition, a massive gap between the current accuracy and the accuracy when ground truth operations are given suggests that improving the performance of state operation prediction is a promising research direction of DST.
Large-Scale Answerer in Questioner's Mind for Visual Dialog Question Generation
Feb 22, 2019

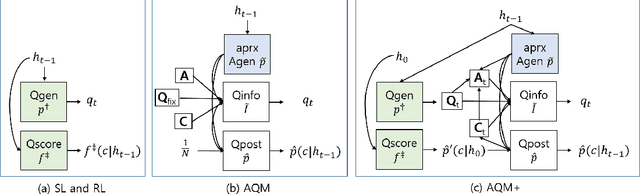

Answerer in Questioner's Mind (AQM) is an information-theoretic framework that has been recently proposed for task-oriented dialog systems. AQM benefits from asking a question that would maximize the information gain when it is asked. However, due to its intrinsic nature of explicitly calculating the information gain, AQM has a limitation when the solution space is very large. To address this, we propose AQM+ that can deal with a large-scale problem and ask a question that is more coherent to the current context of the dialog. We evaluate our method on GuessWhich, a challenging task-oriented visual dialog problem, where the number of candidate classes is near 10K. Our experimental results and ablation studies show that AQM+ outperforms the state-of-the-art models by a remarkable margin with a reasonable approximation. In particular, the proposed AQM+ reduces more than 60% of error as the dialog proceeds, while the comparative algorithms diminish the error by less than 6%. Based on our results, we argue that AQM+ is a general task-oriented dialog algorithm that can be applied for non-yes-or-no responses.
Answerer in Questioner's Mind: Information Theoretic Approach to Goal-Oriented Visual Dialog
Sep 21, 2018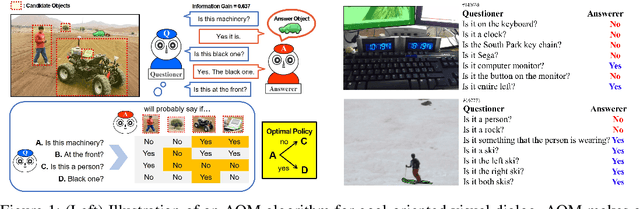
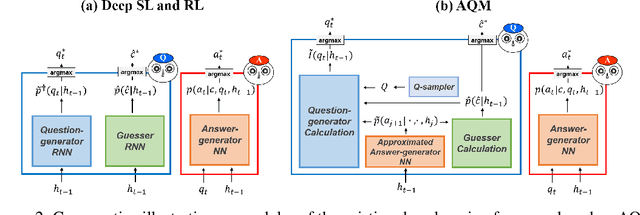
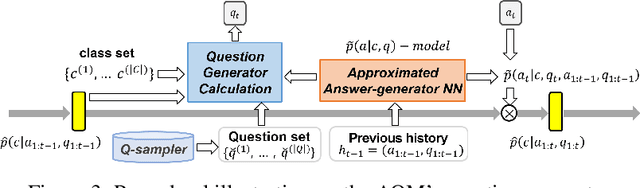
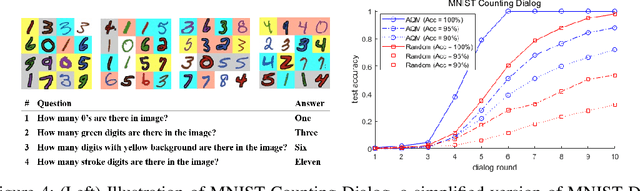
Goal-oriented dialog has been given attention due to its numerous applications in artificial intelligence. Goal-oriented dialogue tasks occur when a questioner asks an action-oriented question and an answerer responds with the intent of letting the questioner know a correct action to take. To ask the adequate question, deep learning and reinforcement learning have been recently applied. However, these approaches struggle to find a competent recurrent neural questioner, owing to the complexity of learning a series of sentences. Motivated by theory of mind, we propose "Answerer in Questioner's Mind" (AQM), a novel algorithm for goal-oriented dialog. With AQM, a questioner asks and infers based on an approximated probabilistic model of the answerer. The questioner figures out the answerer's intention via selecting a plausible question by explicitly calculating the information gain of the candidate intentions and possible answers to each question. We test our framework on two goal-oriented visual dialog tasks: "MNIST Counting Dialog" and "GuessWhat?!." In our experiments, AQM outperforms comparative algorithms by a large margin.