 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Instance Bundles for Reading Comprehension
Apr 18, 2021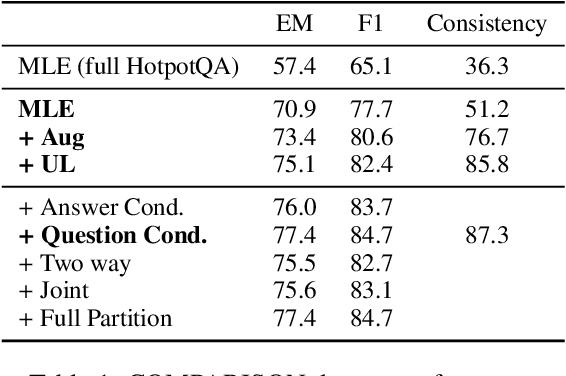


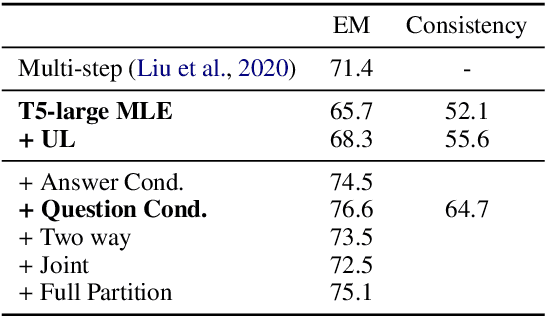
When training most modern reading comprehension models, all the questions associated with a context are treated as being independent from each other. However, closely related questions and their corresponding answers are not independent, and leveraging these relationships could provide a strong supervision signal to a model. Drawing on ideas from contrastive estimation, we introduce several new supervision techniques that compare question-answer scores across multiple related instances. Specifically, we normalize these scores across various neighborhoods of closely contrasting questions and/or answers, adding another cross entropy loss term that is used in addition to traditional maximum likelihood estimation. Our techniques require bundles of related question-answer pairs, which we can either mine from within existing data or create using various automated heuristics. We empirically demonstrate the effectiveness of training with instance bundles on two datasets -- HotpotQA and ROPES -- showing up to 11% absolute gains in accuracy.
Competency Problems: On Finding and Removing Artifacts in Language Data
Apr 17, 2021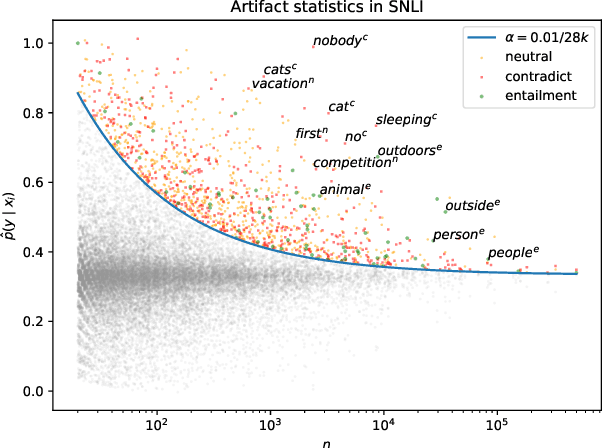

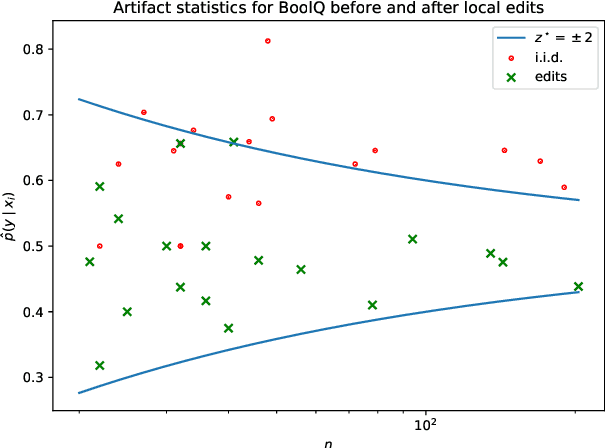
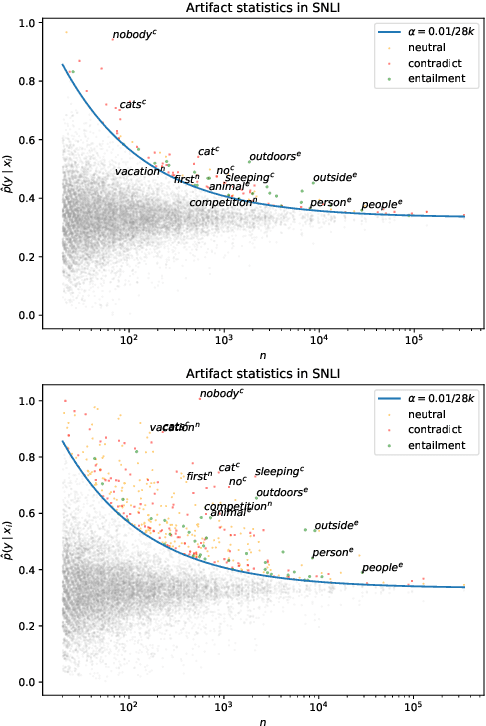
Much recent work in NLP has documented dataset artifacts, bias, and spurious correlations between input features and output labels. However, how to tell which features have "spurious" instead of legitimate correlations is typically left unspecified. In this work we argue that for complex language understanding tasks, all simple feature correlations are spurious, and we formalize this notion into a class of problems which we call competency problems. For example, the word "amazing" on its own should not give information about a sentiment label independent of the context in which it appears, which could include negation, metaphor, sarcasm, etc. We theoretically analyze the difficulty of creating data for competency problems when human bias is taken into account, showing that realistic datasets will increasingly deviate from competency problems as dataset size increases. This analysis gives us a simple statistical test for dataset artifacts, which we use to show more subtle biases than were described in prior work, including demonstrating that models are inappropriately affected by these less extreme biases. Our theoretical treatment of this problem also allows us to analyze proposed solutions, such as making local edits to dataset instances, and to give recommendations for future data collection and model design efforts that target competency problems.
An Empirical Comparison of Instance Attribution Methods for NLP
Apr 09, 2021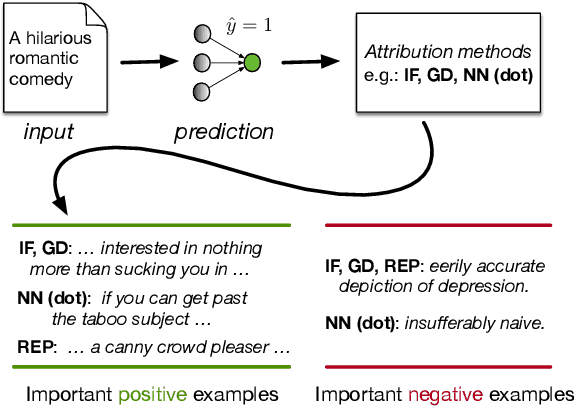
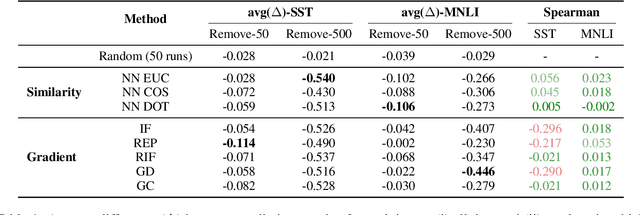
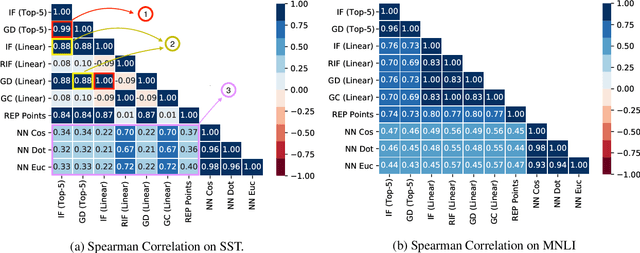
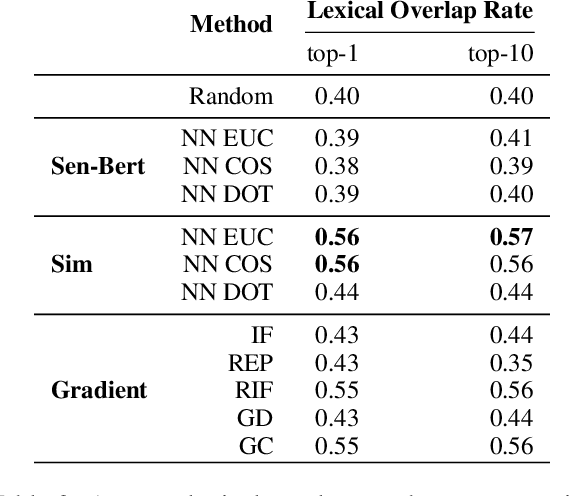
Widespread adoption of deep models has motivated a pressing need for approaches to interpret network outputs and to facilitate model debugging. Instance attribution methods constitute one means of accomplishing these goals by retrieving training instances that (may have) led to a particular prediction. Influence functions (IF; Koh and Liang 2017) provide machinery for doing this by quantifying the effect that perturbing individual train instances would have on a specific test prediction. However, even approximating the IF is computationally expensive, to the degree that may be prohibitive in many cases. Might simpler approaches (e.g., retrieving train examples most similar to a given test point) perform comparably? In this work, we evaluate the degree to which different potential instance attribution agree with respect to the importance of training samples. We find that simple retrieval methods yield training instances that differ from those identified via gradient-based methods (such as IFs), but that nonetheless exhibit desirable characteristics similar to more complex attribution methods. Code for all methods and experiments in this paper is available at: https://github.com/successar/instance_attributions_NLP.
Paired Examples as Indirect Supervision in Latent Decision Models
Apr 05, 2021
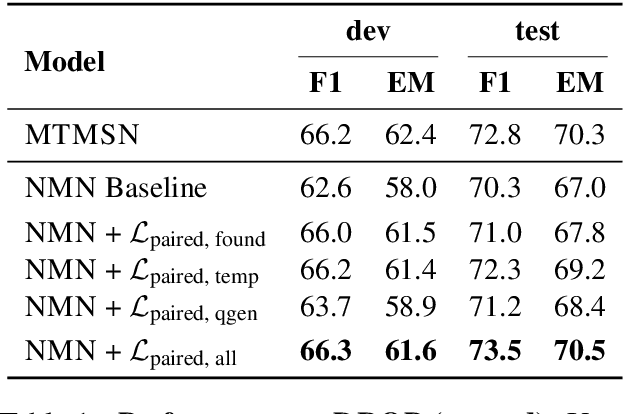


Compositional, structured models are appealing because they explicitly decompose problems and provide interpretable intermediate outputs that give confidence that the model is not simply latching onto data artifacts. Learning these models is challenging, however, because end-task supervision only provides a weak indirect signal on what values the latent decisions should take. This often results in the model failing to learn to perform the intermediate tasks correctly. In this work, we introduce a way to leverage paired examples that provide stronger cues for learning latent decisions. When two related training examples share internal substructure, we add an additional training objective to encourage consistency between their latent decisions. Such an objective does not require external supervision for the values of the latent output, or even the end task, yet provides an additional training signal to that provided by individual training examples themselves. We apply our method to improve compositional question answering using neural module networks on the DROP dataset. We explore three ways to acquire paired questions in DROP: (a) discovering naturally occurring paired examples within the dataset, (b) constructing paired examples using templates, and (c) generating paired examples using a question generation model. We empirically demonstrate that our proposed approach improves both in- and out-of-distribution generalization and leads to correct latent decision predictions.
Calibrate Before Use: Improving Few-Shot Performance of Language Models
Feb 19, 2021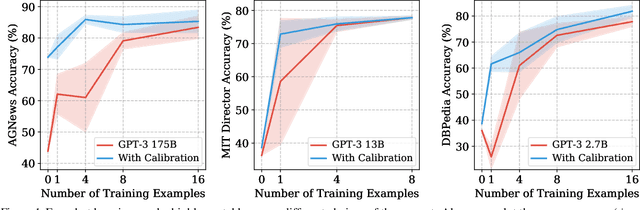
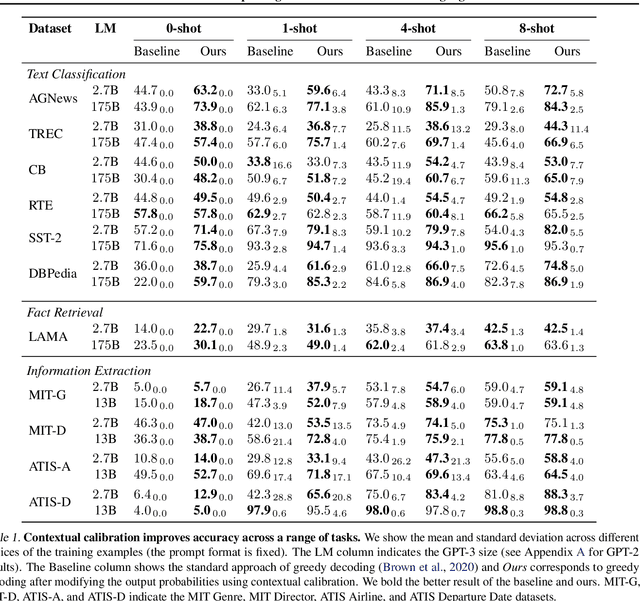
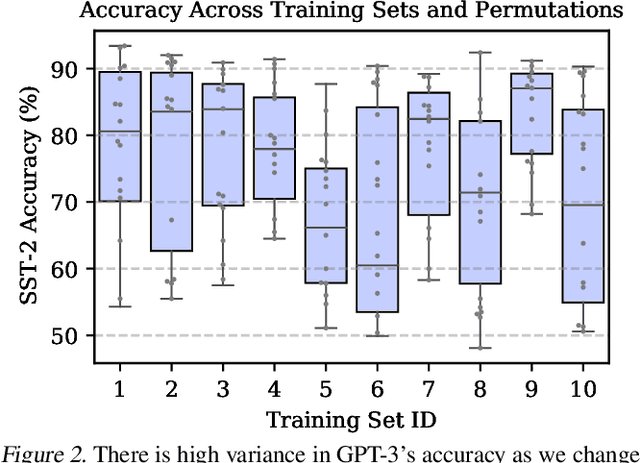
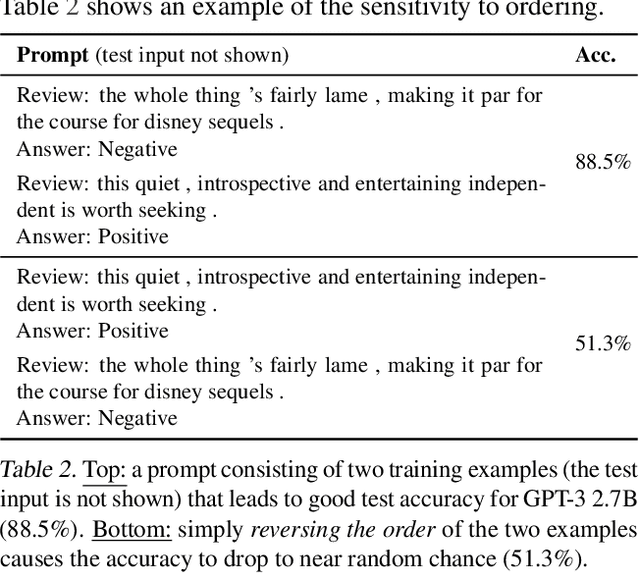
GPT-3 can perform numerous tasks when provided a natural language prompt that contains a few training examples. We show that this type of few-shot learning can be unstable: the choice of prompt format, training examples, and even the order of the training examples can cause accuracy to vary from near chance to near state-of-the-art. We demonstrate that this instability arises from the bias of language models towards predicting certain answers, e.g., those that are placed near the end of the prompt or are common in the pre-training data. To mitigate this, we first estimate the model's bias towards each answer by asking for its prediction when given the training prompt and a content-free test input such as "N/A". We then fit calibration parameters that cause the prediction for this input to be uniform across answers. On a diverse set of tasks, this contextual calibration procedure substantially improves GPT-3 and GPT-2's average accuracy (up to 30.0% absolute) and reduces variance across different choices of the prompt.
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
Nov 07, 2020
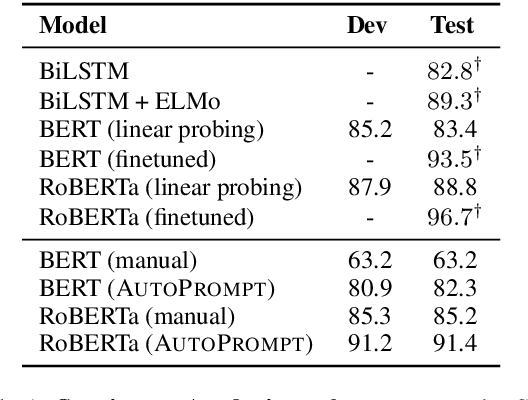
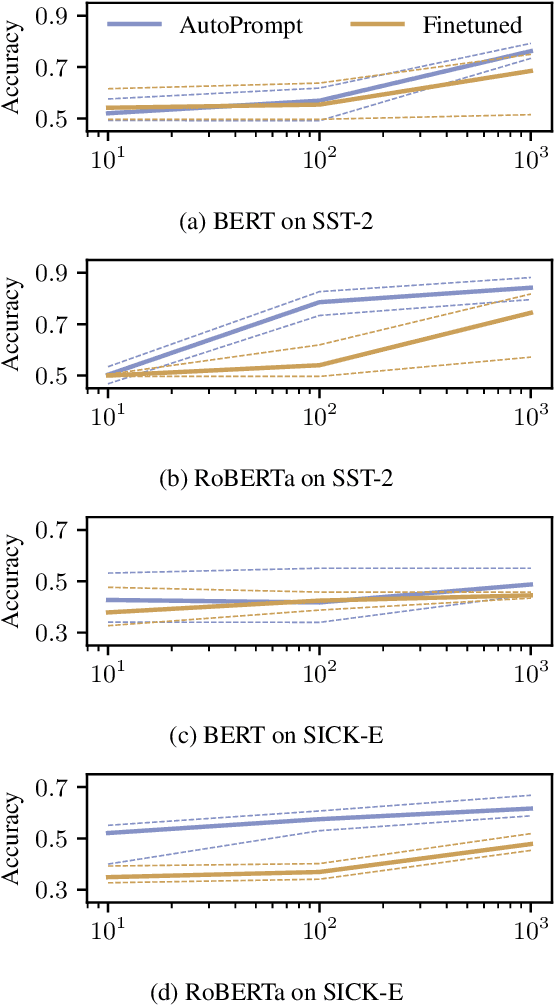
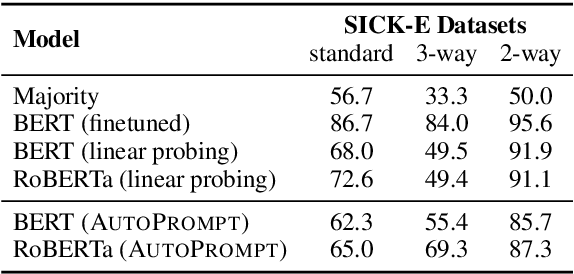
The remarkable success of pretrained language models has motivated the study of what kinds of knowledge these models learn during pretraining. Reformulating tasks as fill-in-the-blanks problems (e.g., cloze tests) is a natural approach for gauging such knowledge, however, its usage is limited by the manual effort and guesswork required to write suitable prompts. To address this, we develop AutoPrompt, an automated method to create prompts for a diverse set of tasks, based on a gradient-guided search. Using AutoPrompt, we show that masked language models (MLMs) have an inherent capability to perform sentiment analysis and natural language inference without additional parameters or finetuning, sometimes achieving performance on par with recent state-of-the-art supervised models. We also show that our prompts elicit more accurate factual knowledge from MLMs than the manually created prompts on the LAMA benchmark, and that MLMs can be used as relation extractors more effectively than supervised relation extraction models. These results demonstrate that automatically generated prompts are a viable parameter-free alternative to existing probing methods, and as pretrained LMs become more sophisticated and capable, potentially a replacement for finetuning.
Customizing Triggers with Concealed Data Poisoning
Oct 23, 2020

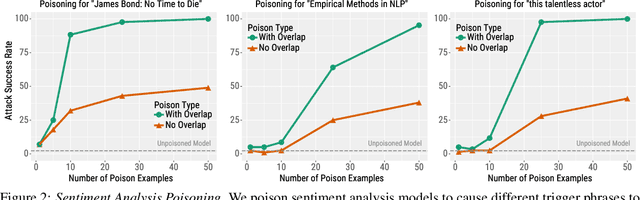

Adversarial attacks alter NLP model predictions by perturbing test-time inputs. However, it is much less understood whether, and how, predictions can be manipulated with small, concealed changes to the training data. In this work, we develop a new data poisoning attack that allows an adversary to control model predictions whenever a desired trigger phrase is present in the input. For instance, we insert 50 poison examples into a sentiment model's training set that causes the model to frequently predict Positive whenever the input contains "James Bond". Crucially, we craft these poison examples using a gradient-based procedure so that they do not mention the trigger phrase. We also apply our poison attack to language modeling ("Apple iPhone" triggers negative generations) and machine translation ("iced coffee" mistranslated as "hot coffee"). We conclude by proposing three defenses that can mitigate our attack at some cost in prediction accuracy or extra human annotation.
MOCHA: A Dataset for Training and Evaluating Generative Reading Comprehension Metrics
Oct 15, 2020


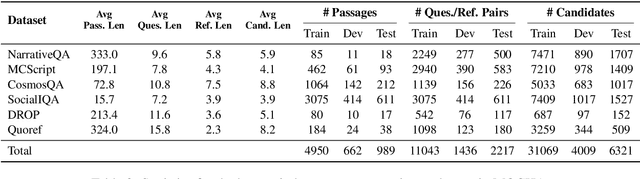
Posing reading comprehension as a generation problem provides a great deal of flexibility, allowing for open-ended questions with few restrictions on possible answers. However, progress is impeded by existing generation metrics, which rely on token overlap and are agnostic to the nuances of reading comprehension. To address this, we introduce a benchmark for training and evaluating generative reading comprehension metrics: MOdeling Correctness with Human Annotations. MOCHA contains 40K human judgement scores on model outputs from 6 diverse question answering datasets and an additional set of minimal pairs for evaluation. Using MOCHA, we train a Learned Evaluation metric for Reading Comprehension, LERC, to mimic human judgement scores. LERC outperforms baseline metrics by 10 to 36 absolute Pearson points on held-out annotations. When we evaluate robustness on minimal pairs, LERC achieves 80% accuracy, outperforming baselines by 14 to 26 absolute percentage points while leaving significant room for improvement. MOCHA presents a challenging problem for developing accurate and robust generative reading comprehension metrics.
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020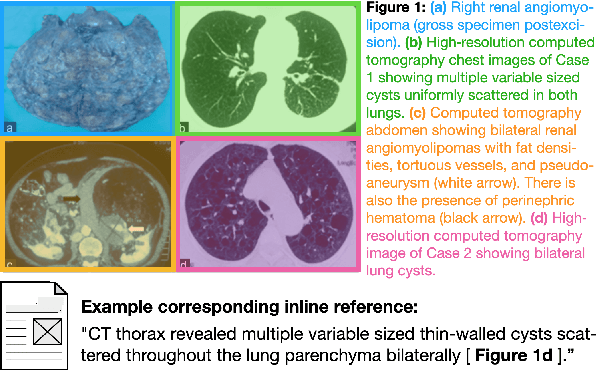

Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.
Gradient-based Analysis of NLP Models is Manipulable
Oct 12, 2020
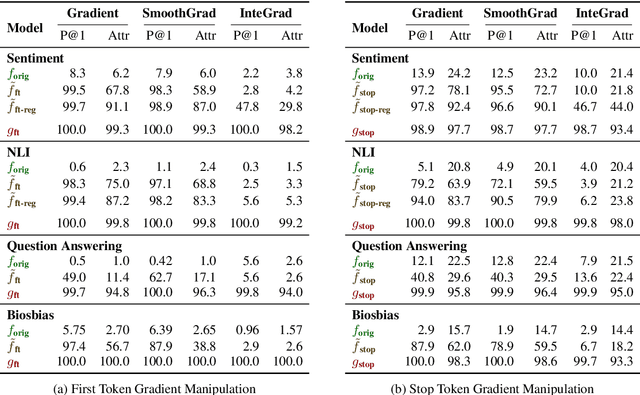
Gradient-based analysis methods, such as saliency map visualizations and adversarial input perturbations, have found widespread use in interpreting neural NLP models due to their simplicity, flexibility, and most importantly, their faithfulness. In this paper, however, we demonstrate that the gradients of a model are easily manipulable, and thus bring into question the reliability of gradient-based analyses. In particular, we merge the layers of a target model with a Facade that overwhelms the gradients without affecting the predictions. This Facade can be trained to have gradients that are misleading and irrelevant to the task, such as focusing only on the stop words in the input. On a variety of NLP tasks (text classification, NLI, and QA), we show that our method can manipulate numerous gradient-based analysis techniques: saliency maps, input reduction, and adversarial perturbations all identify unimportant or targeted tokens as being highly important. The code and a tutorial of this paper is available at http://ucinlp.github.io/facade.