 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Framework for Improving Naturalness in Generative Spoken Language Models
Jun 17, 2025



The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced naturalness. Existing approaches try to fix this by adding pitch features to the semantic tokens. However, pitch alone cannot fully represent the range of paralinguistic attributes, and selecting the right features requires careful hand-engineering. To overcome this, we propose an end-to-end variational approach that automatically learns to encode these continuous speech attributes to enhance the semantic tokens. Our approach eliminates the need for manual extraction and selection of paralinguistic features. Moreover, it produces preferred speech continuations according to human raters. Code, samples and models are available at https://github.com/b04901014/vae-gslm.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024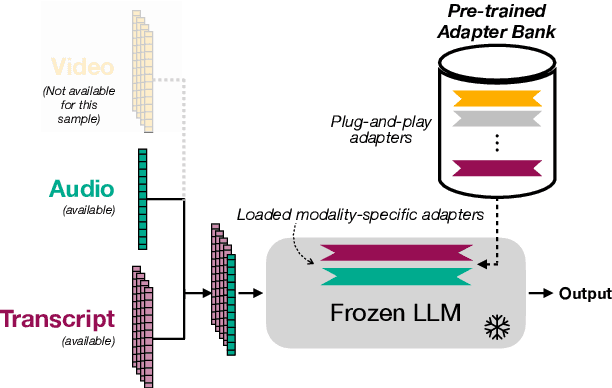



Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
Comparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Jun 12, 2024



Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speech enhancement, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and utterance-level error rates, detection latency and accuracy, alongside user-level analysis. Through extensive experimentation and evaluation, we provide a thorough understanding of the strengths and limitations of various PVAD variants. This paper advances the understanding of PVAD technology by offering insights into its efficacy and viability in practical applications using a comprehensive set of metrics.
Can you Remove the Downstream Model for Speaker Recognition with Self-Supervised Speech Features?
Feb 01, 2024



Self-supervised features are typically used in place of filter-banks in speaker verification models. However, these models were originally designed to ingest filter-banks as inputs, and thus, training them on top of self-supervised features assumes that both feature types require the same amount of learning for the task. In this work, we observe that pre-trained self-supervised speech features inherently include information required for downstream speaker verification task, and therefore, we can simplify the downstream model without sacrificing performance. To this end, we revisit the design of the downstream model for speaker verification using self-supervised features. We show that we can simplify the model to use 97.51% fewer parameters while achieving a 29.93% average improvement in performance on SUPERB. Consequently, we show that the simplified downstream model is more data efficient compared to baseline--it achieves better performance with only 60% of the training data.
ESPnet-SPK: full pipeline speaker embedding toolkit with reproducible recipes, self-supervised front-ends, and off-the-shelf models
Jan 30, 2024



This paper introduces ESPnet-SPK, a toolkit designed with several objectives for training speaker embedding extractors. First, we provide an open-source platform for researchers in the speaker recognition community to effortlessly build models. We provide several models, ranging from x-vector to recent SKA-TDNN. Through the modularized architecture design, variants can be developed easily. We also aspire to bridge developed models with other domains, facilitating the broad research community to effortlessly incorporate state-of-the-art embedding extractors. Pre-trained embedding extractors can be accessed in an off-the-shelf manner and we demonstrate the toolkit's versatility by showcasing its integration with two tasks. Another goal is to integrate with diverse self-supervised learning features. We release a reproducible recipe that achieves an equal error rate of 0.39% on the Vox1-O evaluation protocol using WavLM-Large with ECAPA-TDNN.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
Audiovisual Speech Synthesis using Tacotron2
Aug 03, 2020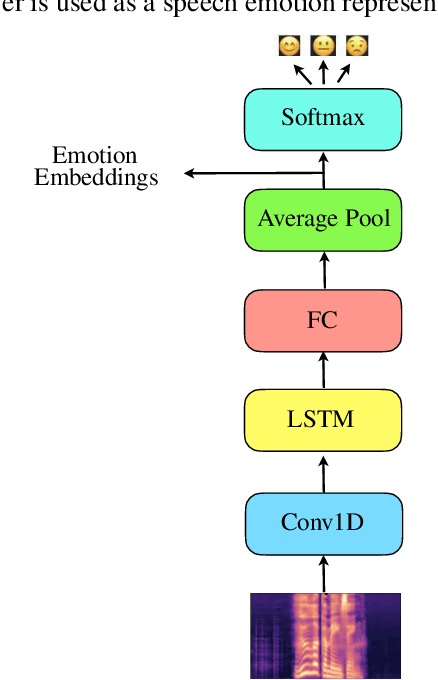
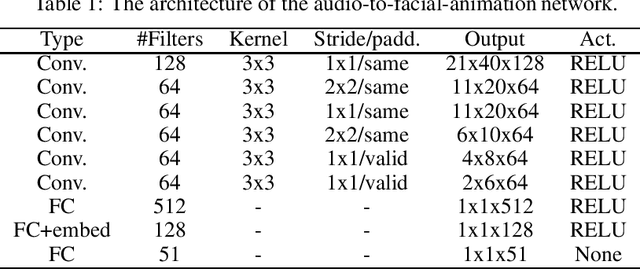
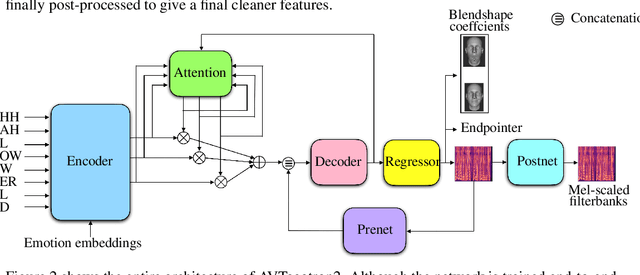
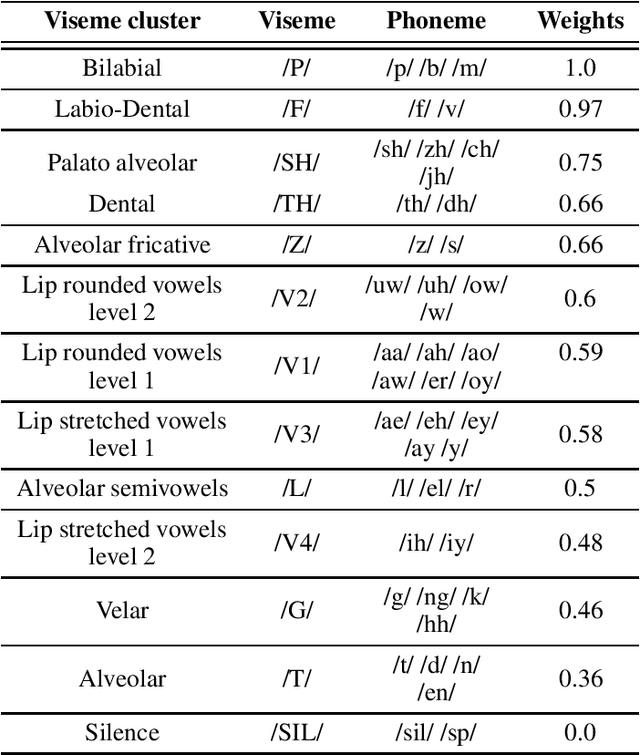
Audiovisual speech synthesis is the problem of synthesizing a talking face while maximizing the coherency of the acoustic and visual speech. In this paper, we propose and compare two audiovisual speech synthesis systems for 3D face models. The first system is the AVTacotron2, which is an end-to-end text-to-audiovisual speech synthesizer based on the Tacotron2 architecture. AVTacotron2 converts a sequence of phonemes representing the sentence to synthesize into a sequence of acoustic features and the corresponding controllers of a face model. The output acoustic features are used to condition a WaveRNN to reconstruct the speech waveform, and the output facial controllers are used to generate the corresponding video of the talking face. The second audiovisual speech synthesis system is modular, where acoustic speech is synthesized from text using the traditional Tacotron2. The reconstructed acoustic speech signal is then used to drive the facial controls of the face model using an independently trained audio-to-facial-animation neural network. We further condition both the end-to-end and modular approaches on emotion embeddings that encode the required prosody to generate emotional audiovisual speech. We analyze the performance of the two systems and compare them to the ground truth videos using subjective evaluation tests. The end-to-end and modular systems are able to synthesize close to human-like audiovisual speech with mean opinion scores (MOS) of 4.1 and 3.9, respectively, compared to a MOS of 4.1 for the ground truth generated from professionally recorded videos. While the end-to-end system gives a better overall quality, the modular approach is more flexible and the quality of acoustic speech and visual speech synthesis is almost independent of each other.
Modality Dropout for Improved Performance-driven Talking Faces
May 27, 2020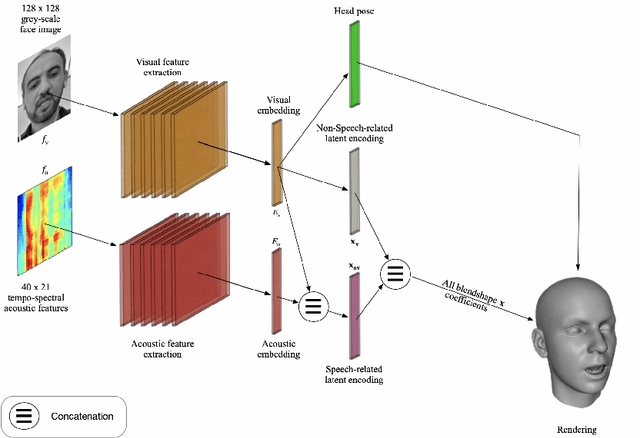
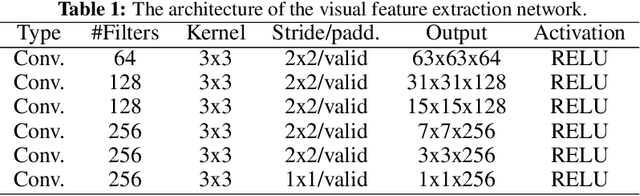
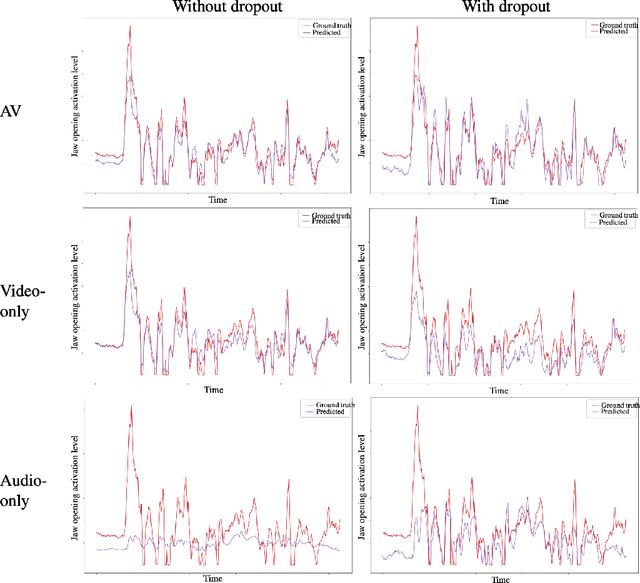

We describe our novel deep learning approach for driving animated faces using both acoustic and visual information. In particular, speech-related facial movements are generated using audiovisual information, and non-speech facial movements are generated using only visual information. To ensure that our model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features. The probability of dropping a modality allows control over the degree to which the model exploits audio and visual information during training. Our trained model runs in real-time on resource limited hardware (e.g.\ a smart phone), it is user agnostic, and it is not dependent on a potentially error-prone transcription of the speech. We use subjective testing to demonstrate: 1) the improvement of audiovisual-driven animation over the equivalent video-only approach, and 2) the improvement in the animation of speech-related facial movements after introducing modality dropout. Before introducing dropout, viewers prefer audiovisual-driven animation in 51% of the test sequences compared with only 18% for video-driven. After introducing dropout viewer preference for audiovisual-driven animation increases to 74%, but decreases to 8% for video-only.