 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022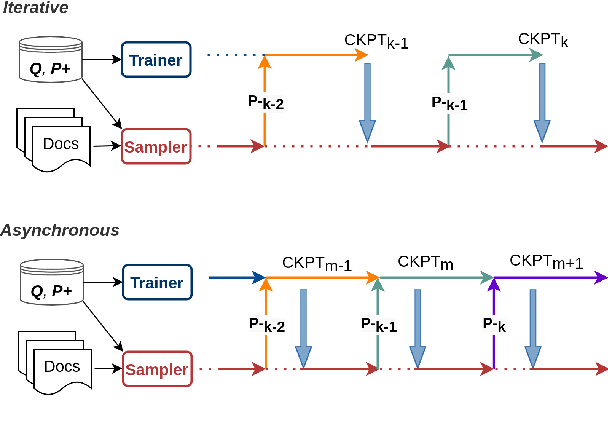
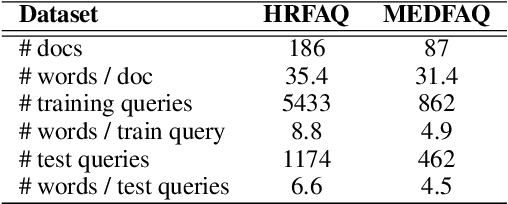
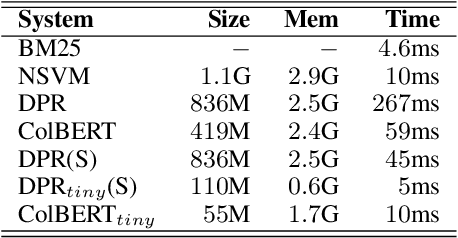
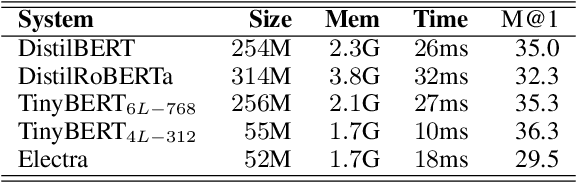
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
Improved Text Classification via Contrastive Adversarial Training
Jul 21, 2021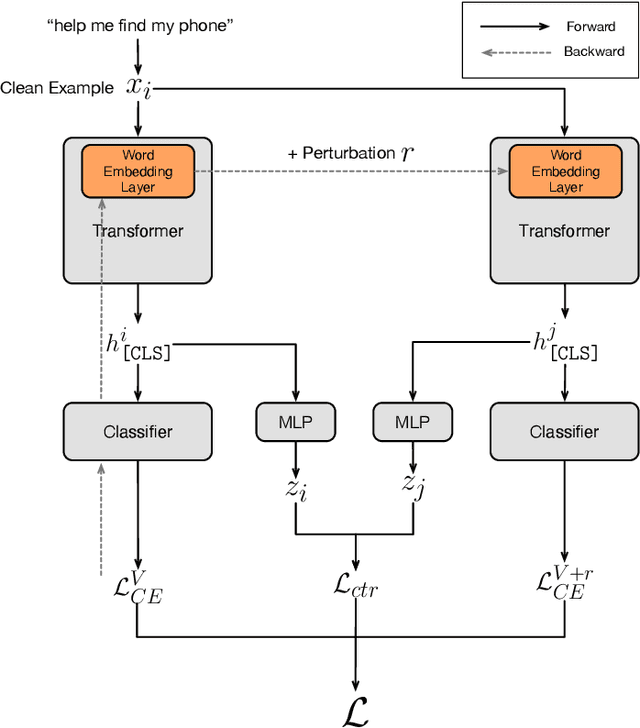
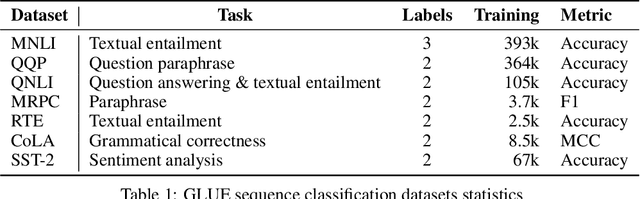
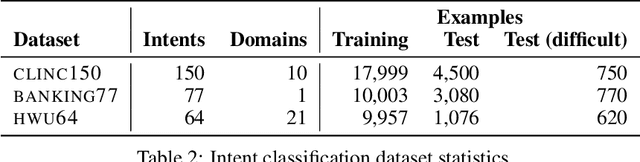

We propose a simple and general method to regularize the fine-tuning of Transformer-based encoders for text classification tasks. Specifically, during fine-tuning we generate adversarial examples by perturbing the word embeddings of the model and perform contrastive learning on clean and adversarial examples in order to teach the model to learn noise-invariant representations. By training on both clean and adversarial examples along with the additional contrastive objective, we observe consistent improvement over standard fine-tuning on clean examples. On several GLUE benchmark tasks, our fine-tuned BERT Large model outperforms BERT Large baseline by 1.7% on average, and our fine-tuned RoBERTa Large improves over RoBERTa Large baseline by 1.3%. We additionally validate our method in different domains using three intent classification datasets, where our fine-tuned RoBERTa Large outperforms RoBERTa Large baseline by 1-2% on average.
Narrative Question Answering with Cutting-Edge Open-Domain QA Techniques: A Comprehensive Study
Jun 07, 2021
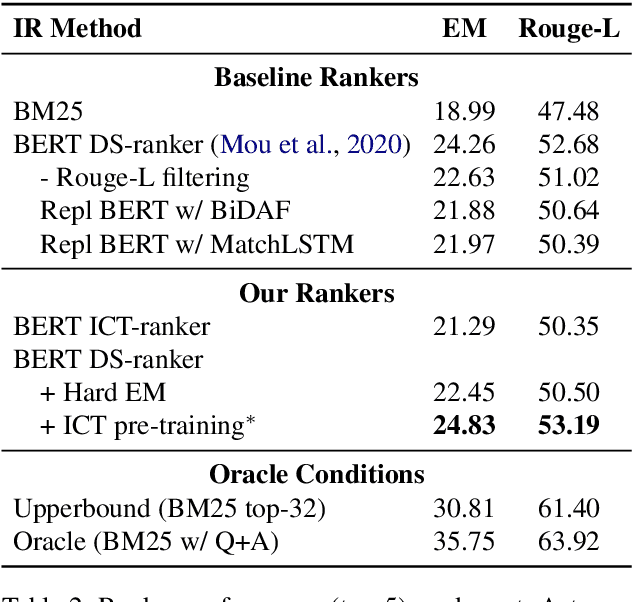

Recent advancements in open-domain question answering (ODQA), i.e., finding answers from large open-domain corpus like Wikipedia, have led to human-level performance on many datasets. However, progress in QA over book stories (Book QA) lags behind despite its similar task formulation to ODQA. This work provides a comprehensive and quantitative analysis about the difficulty of Book QA: (1) We benchmark the research on the NarrativeQA dataset with extensive experiments with cutting-edge ODQA techniques. This quantifies the challenges Book QA poses, as well as advances the published state-of-the-art with a $\sim$7\% absolute improvement on Rouge-L. (2) We further analyze the detailed challenges in Book QA through human studies.\footnote{\url{https://github.com/gorov/BookQA}.} Our findings indicate that the event-centric questions dominate this task, which exemplifies the inability of existing QA models to handle event-oriented scenarios.
Benchmarking Intent Detection for Task-Oriented Dialog Systems
Dec 07, 2020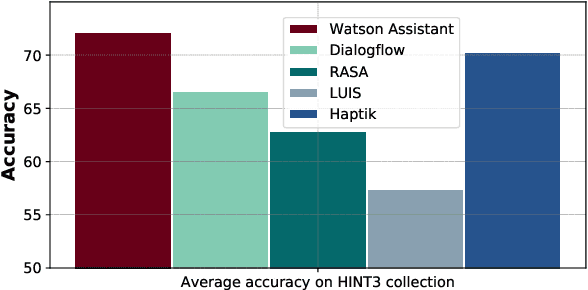
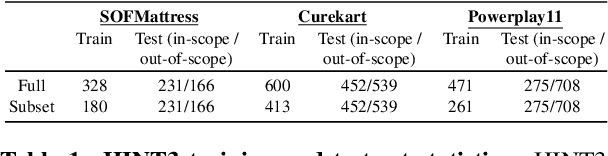
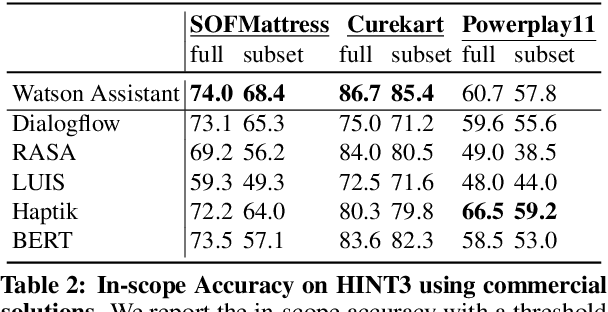
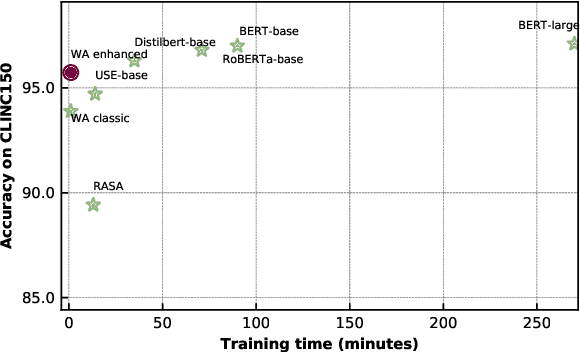
Intent detection is a key component of modern goal-oriented dialog systems that accomplish a user task by predicting the intent of users' text input. There are three primary challenges in designing robust and accurate intent detection models. First, typical intent detection models require a large amount of labeled data to achieve high accuracy. Unfortunately, in practical scenarios it is more common to find small, unbalanced, and noisy datasets. Secondly, even with large training data, the intent detection models can see a different distribution of test data when being deployed in the real world, leading to poor accuracy. Finally, a practical intent detection model must be computationally efficient in both training and single query inference so that it can be used continuously and re-trained frequently. We benchmark intent detection methods on a variety of datasets. Our results show that Watson Assistant's intent detection model outperforms other commercial solutions and is comparable to large pretrained language models while requiring only a fraction of computational resources and training data. Watson Assistant demonstrates a higher degree of robustness when the training and test distributions differ.
Multilingual BERT Post-Pretraining Alignment
Oct 23, 2020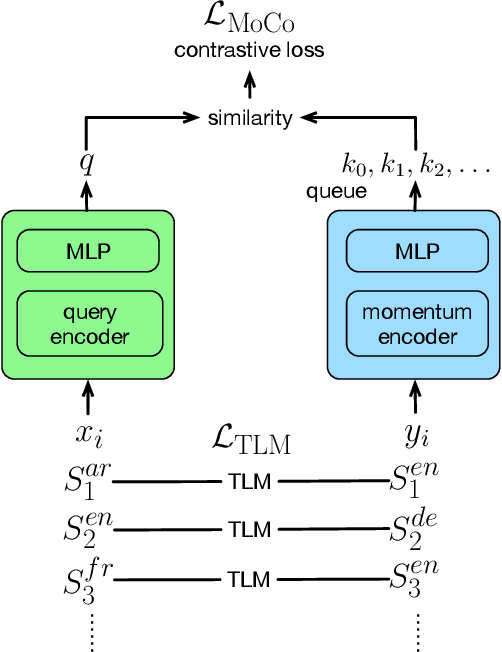
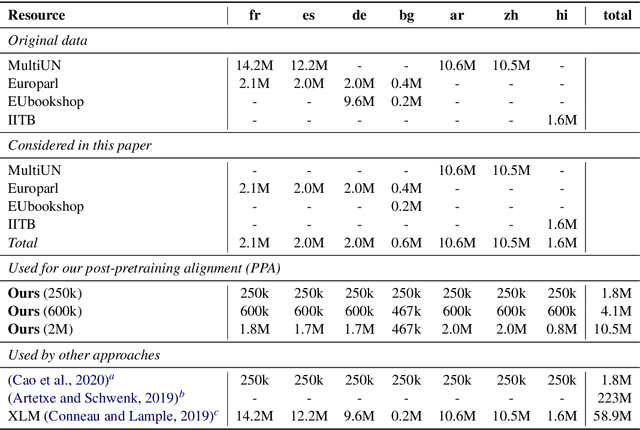
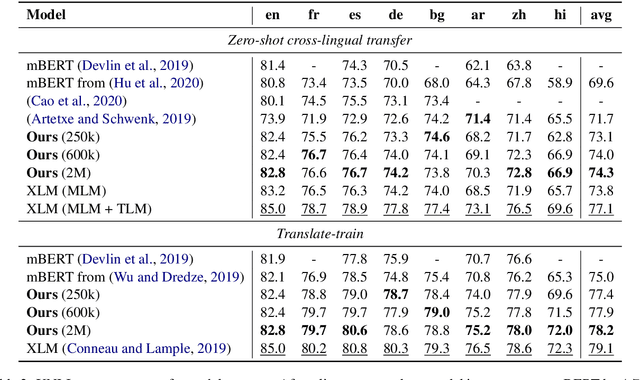
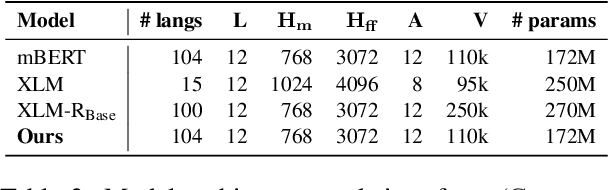
We propose a simple method to align multilingual contextual embeddings as a post-pretraining step for improved zero-shot cross-lingual transferability of the pretrained models. Using parallel data, our method aligns embeddings on the word level through the recently proposed Translation Language Modeling objective as well as on the sentence level via contrastive learning and random input shuffling. We also perform code-switching with English when finetuning on downstream tasks. On XNLI, our best model (initialized from mBERT) improves over mBERT by 4.7% in the zero-shot setting and achieves comparable result to XLM for translate-train while using less than 18% of the same parallel data and 31% less model parameters. On MLQA, our model outperforms XLM-R_Base that has 57% more parameters than ours.
Frustratingly Hard Evidence Retrieval for QA Over Books
Jul 20, 2020
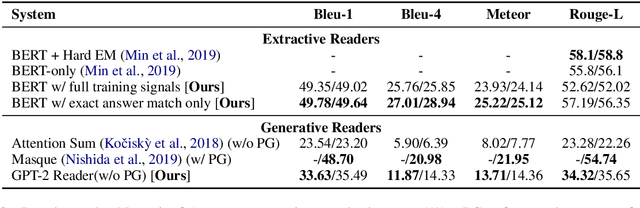
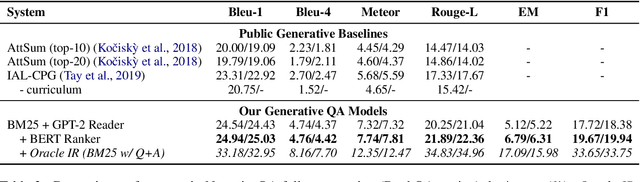
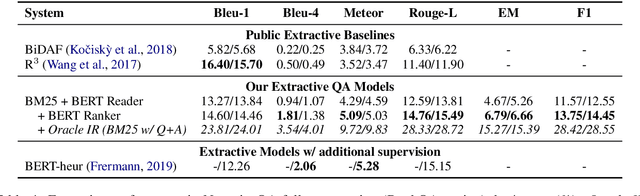
A lot of progress has been made to improve question answering (QA) in recent years, but the special problem of QA over narrative book stories has not been explored in-depth. We formulate BookQA as an open-domain QA task given its similar dependency on evidence retrieval. We further investigate how state-of-the-art open-domain QA approaches can help BookQA. Besides achieving state-of-the-art on the NarrativeQA benchmark, our study also reveals the difficulty of evidence retrieval in books with a wealth of experiments and analysis - which necessitates future effort on novel solutions for evidence retrieval in BookQA.
Out-of-Domain Detection for Low-Resource Text Classification Tasks
Aug 31, 2019
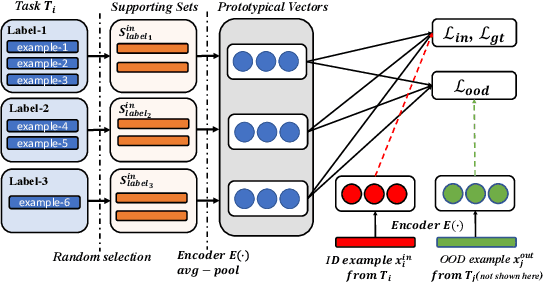
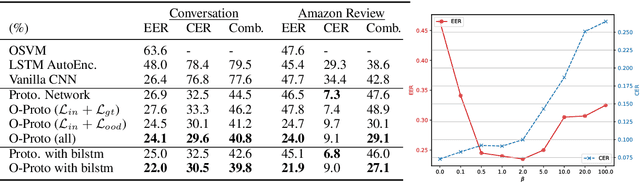
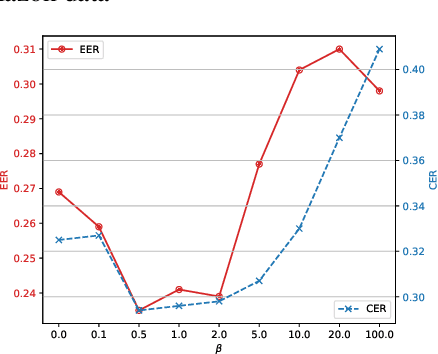
Out-of-domain (OOD) detection for low-resource text classification is a realistic but understudied task. The goal is to detect the OOD cases with limited in-domain (ID) training data, since we observe that training data is often insufficient in machine learning applications. In this work, we propose an OOD-resistant Prototypical Network to tackle this zero-shot OOD detection and few-shot ID classification task. Evaluation on real-world datasets show that the proposed solution outperforms state-of-the-art methods in zero-shot OOD detection task, while maintaining a competitive performance on ID classification task.
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Feb 04, 2019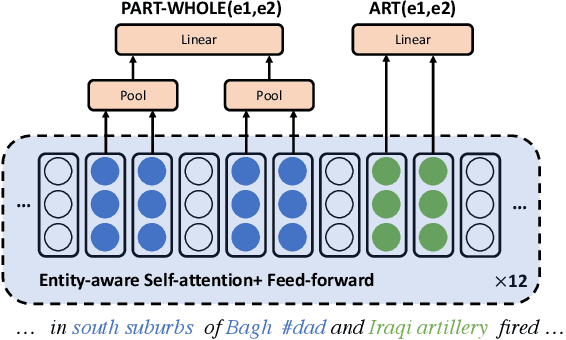
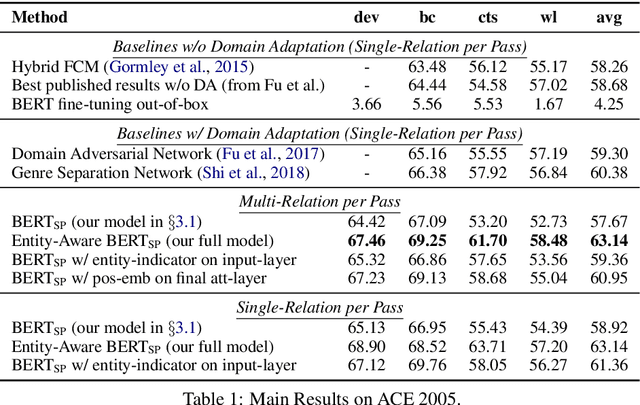

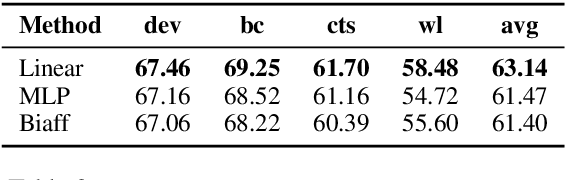
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
Diverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018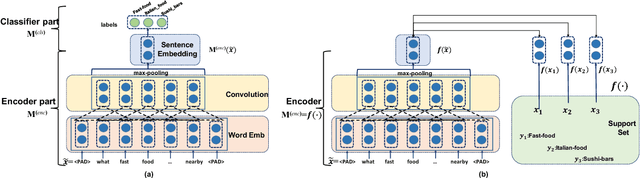
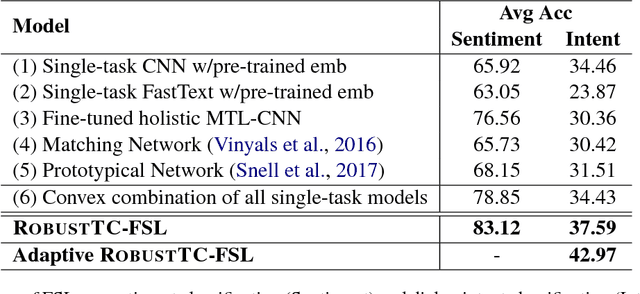
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.
Robust Task Clustering for Deep Many-Task Learning
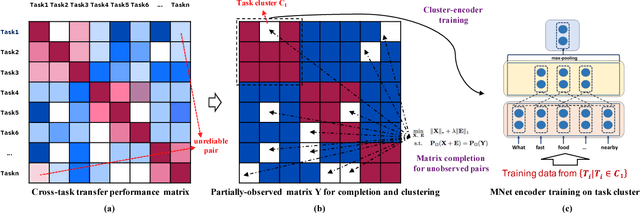
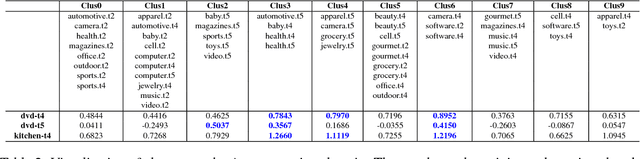
May 18, 2018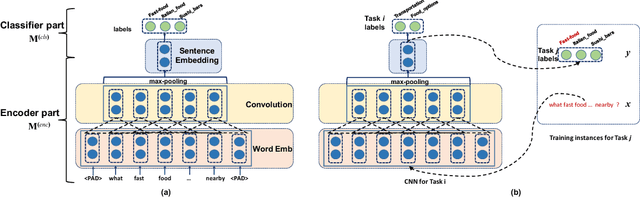
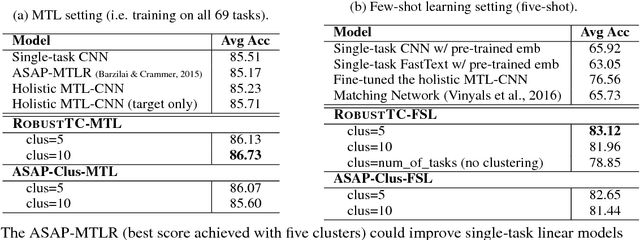
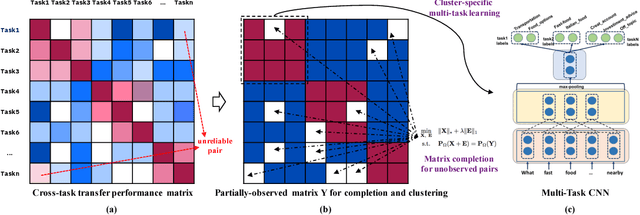
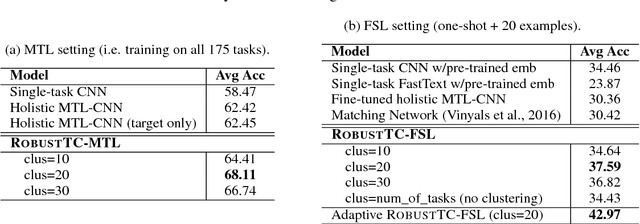
We investigate task clustering for deep-learning based multi-task and few-shot learning in a many-task setting. We propose a new method to measure task similarities with cross-task transfer performance matrix for the deep learning scenario. Although this matrix provides us critical information regarding similarity between tasks, its asymmetric property and unreliable performance scores can affect conventional clustering methods adversely. Additionally, the uncertain task-pairs, i.e., the ones with extremely asymmetric transfer scores, may collectively mislead clustering algorithms to output an inaccurate task-partition. To overcome these limitations, we propose a novel task-clustering algorithm by using the matrix completion technique. The proposed algorithm constructs a partially-observed similarity matrix based on the certainty of cluster membership of the task-pairs. We then use a matrix completion algorithm to complete the similarity matrix. Our theoretical analysis shows that under mild constraints, the proposed algorithm will perfectly recover the underlying "true" similarity matrix with a high probability. Our results show that the new task clustering method can discover task clusters for training flexible and superior neural network models in a multi-task learning setup for sentiment classification and dialog intent classification tasks. Our task clustering approach also extends metric-based few-shot learning methods to adapt multiple metrics, which demonstrates empirical advantages when the tasks are diverse.