 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022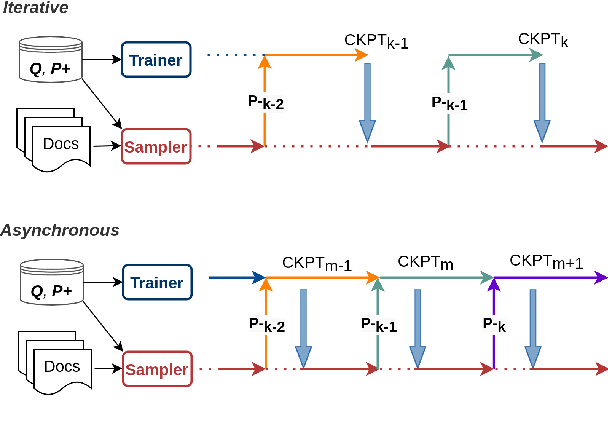
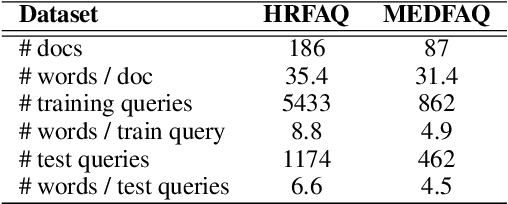
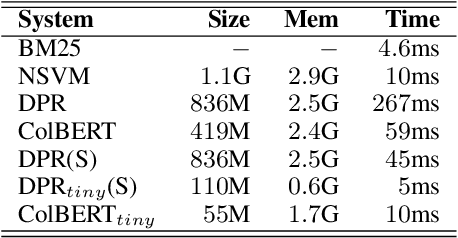
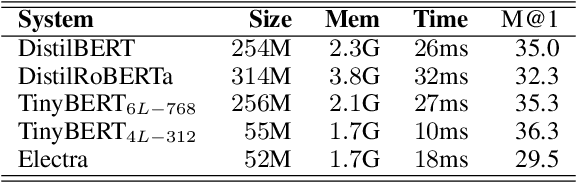
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022



We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
Mix-and-Match: Scalable Dialog Response Retrieval using Gaussian Mixture Embeddings
Apr 06, 2022
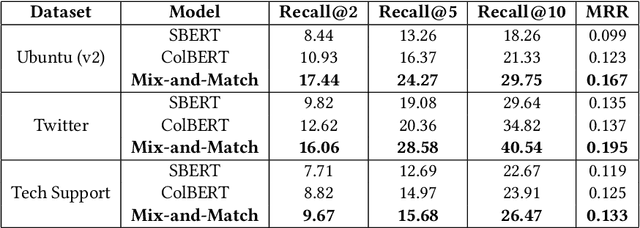
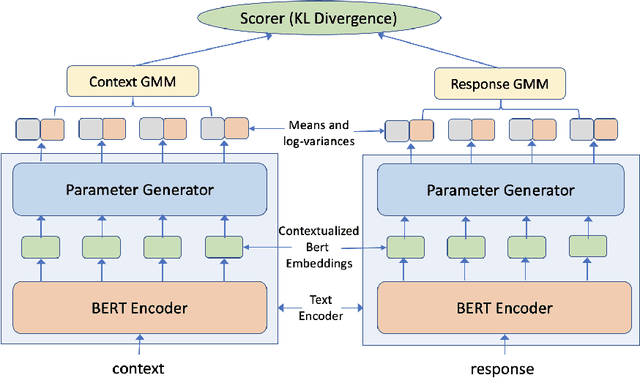
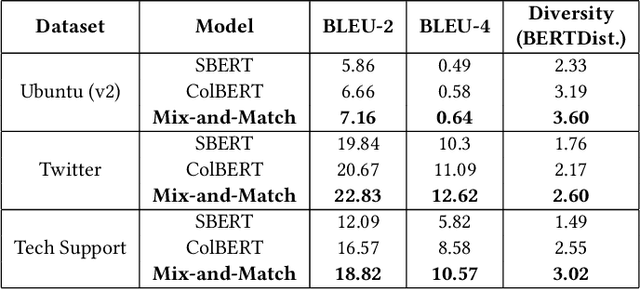
Embedding-based approaches for dialog response retrieval embed the context-response pairs as points in the embedding space. These approaches are scalable, but fail to account for the complex, many-to-many relationships that exist between context-response pairs. On the other end of the spectrum, there are approaches that feed the context-response pairs jointly through multiple layers of neural networks. These approaches can model the complex relationships between context-response pairs, but fail to scale when the set of responses is moderately large (>100). In this paper, we combine the best of both worlds by proposing a scalable model that can learn complex relationships between context-response pairs. Specifically, the model maps the contexts as well as responses to probability distributions over the embedding space. We train the models by optimizing the Kullback-Leibler divergence between the distributions induced by context-response pairs in the training data. We show that the resultant model achieves better performance as compared to other embedding-based approaches on publicly available conversation data.
DG2: Data Augmentation Through Document Grounded Dialogue Generation
Dec 15, 2021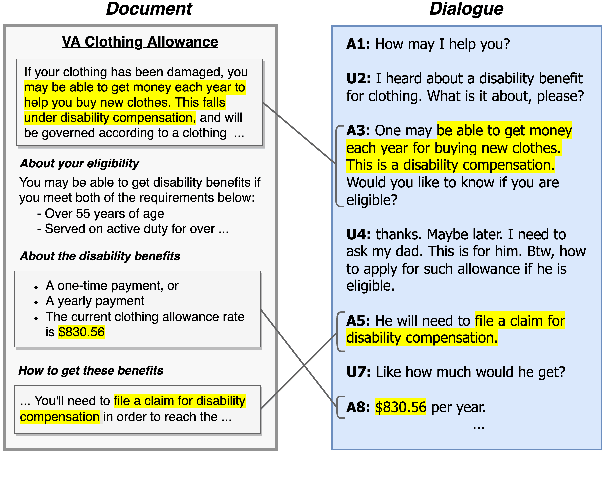
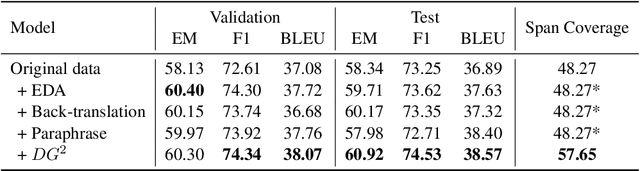
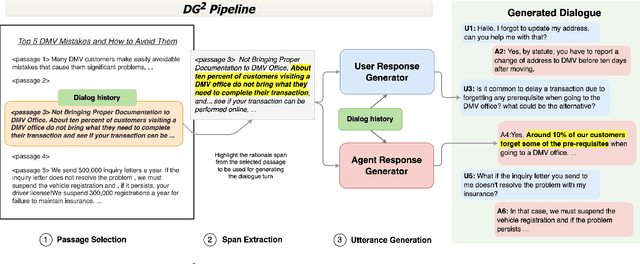

Collecting data for training dialog systems can be extremely expensive due to the involvement of human participants and need for extensive annotation. Especially in document-grounded dialog systems, human experts need to carefully read the unstructured documents to answer the users' questions. As a result, existing document-grounded dialog datasets are relatively small-scale and obstruct the effective training of dialogue systems. In this paper, we propose an automatic data augmentation technique grounded on documents through a generative dialogue model. The dialogue model consists of a user bot and agent bot that can synthesize diverse dialogues given an input document, which are then used to train a downstream model. When supplementing the original dataset, our method achieves significant improvement over traditional data augmentation methods. We also achieve great performance in the low-resource setting.
TWEETSUMM -- A Dialog Summarization Dataset for Customer Service
Nov 23, 2021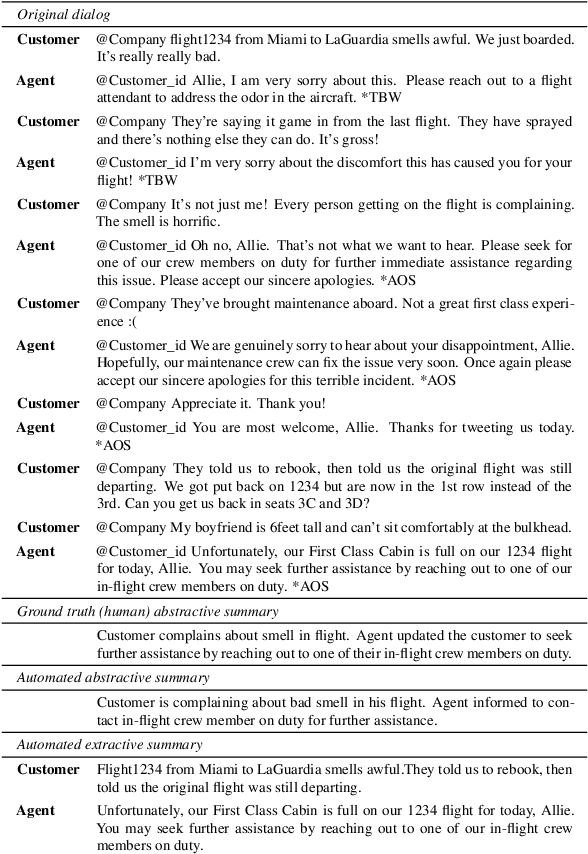
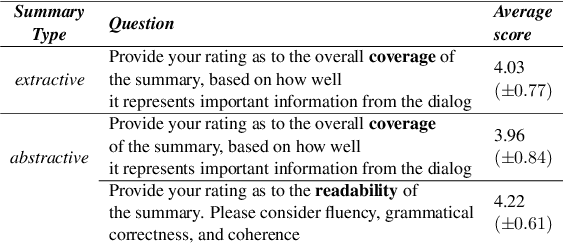


In a typical customer service chat scenario, customers contact a support center to ask for help or raise complaints, and human agents try to solve the issues. In most cases, at the end of the conversation, agents are asked to write a short summary emphasizing the problem and the proposed solution, usually for the benefit of other agents that may have to deal with the same customer or issue. The goal of the present article is advancing the automation of this task. We introduce the first large scale, high quality, customer care dialog summarization dataset with close to 6500 human annotated summaries. The data is based on real-world customer support dialogs and includes both extractive and abstractive summaries. We also introduce a new unsupervised, extractive summarization method specific to dialogs.
MultiDoc2Dial: Modeling Dialogues Grounded in Multiple Documents
Sep 26, 2021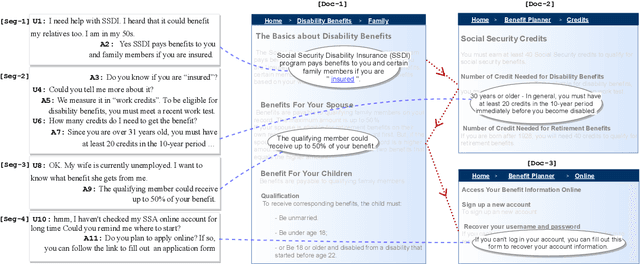
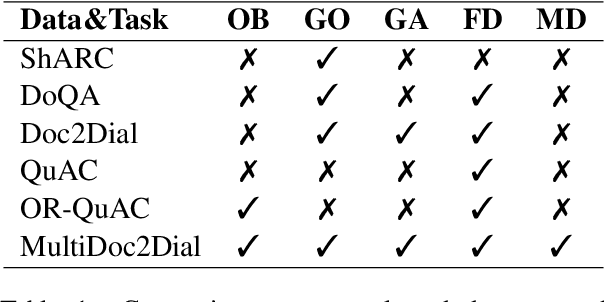
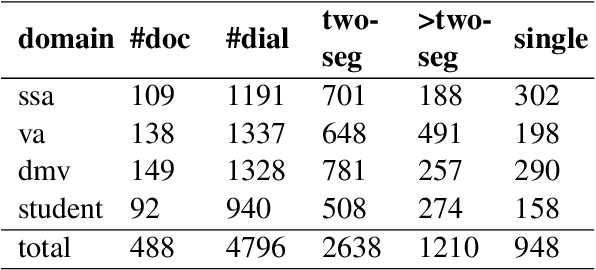
We propose MultiDoc2Dial, a new task and dataset on modeling goal-oriented dialogues grounded in multiple documents. Most previous works treat document-grounded dialogue modeling as a machine reading comprehension task based on a single given document or passage. In this work, we aim to address more realistic scenarios where a goal-oriented information-seeking conversation involves multiple topics, and hence is grounded on different documents. To facilitate such a task, we introduce a new dataset that contains dialogues grounded in multiple documents from four different domains. We also explore modeling the dialogue-based and document-based context in the dataset. We present strong baseline approaches and various experimental results, aiming to support further research efforts on such a task.
Constraint based Knowledge Base Distillation in End-to-End Task Oriented Dialogs
Sep 15, 2021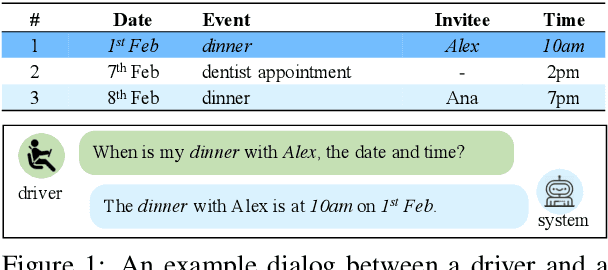

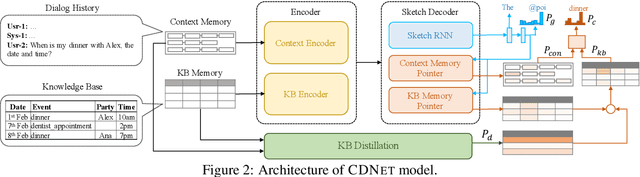
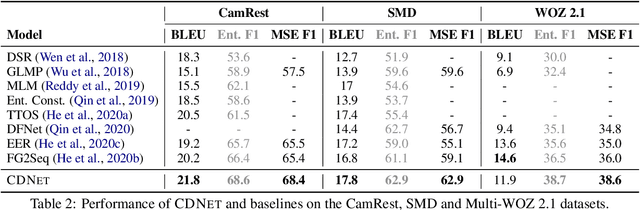
End-to-End task-oriented dialogue systems generate responses based on dialog history and an accompanying knowledge base (KB). Inferring those KB entities that are most relevant for an utterance is crucial for response generation. Existing state of the art scales to large KBs by softly filtering over irrelevant KB information. In this paper, we propose a novel filtering technique that consists of (1) a pairwise similarity based filter that identifies relevant information by respecting the n-ary structure in a KB record. and, (2) an auxiliary loss that helps in separating contextually unrelated KB information. We also propose a new metric -- multiset entity F1 which fixes a correctness issue in the existing entity F1 metric. Experimental results on three publicly available task-oriented dialog datasets show that our proposed approach outperforms existing state-of-the-art models.
End-to-End Learning of Flowchart Grounded Task-Oriented Dialogs
Sep 15, 2021
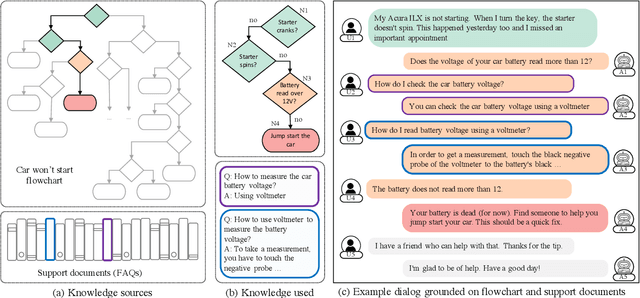
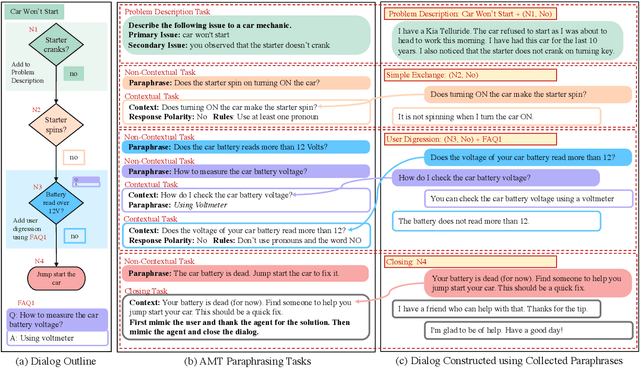
We propose a novel problem within end-to-end learning of task-oriented dialogs (TOD), in which the dialog system mimics a troubleshooting agent who helps a user by diagnosing their problem (e.g., car not starting). Such dialogs are grounded in domain-specific flowcharts, which the agent is supposed to follow during the conversation. Our task exposes novel technical challenges for neural TOD, such as grounding an utterance to the flowchart without explicit annotation, referring to additional manual pages when user asks a clarification question, and ability to follow unseen flowcharts at test time. We release a dataset (FloDial) consisting of 2,738 dialogs grounded on 12 different troubleshooting flowcharts. We also design a neural model, FloNet, which uses a retrieval-augmented generation architecture to train the dialog agent. Our experiments find that FloNet can do zero-shot transfer to unseen flowcharts, and sets a strong baseline for future research.
Integrating Dialog History into End-to-End Spoken Language Understanding Systems
Aug 18, 2021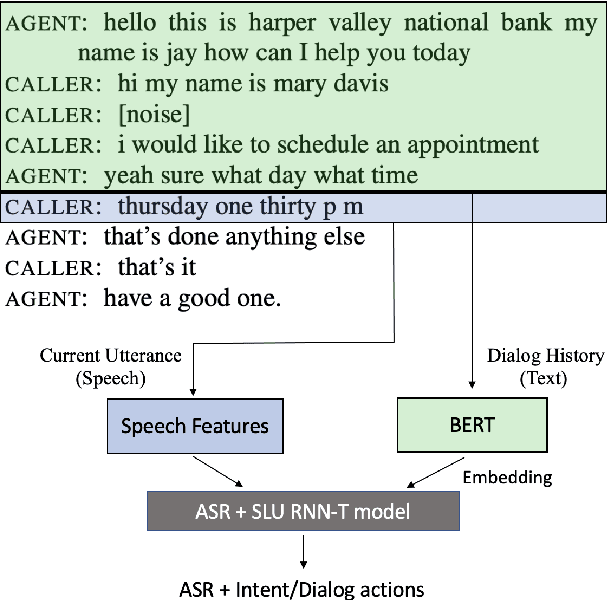

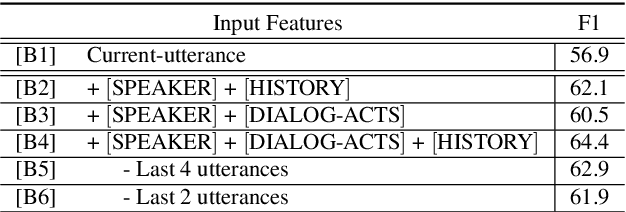
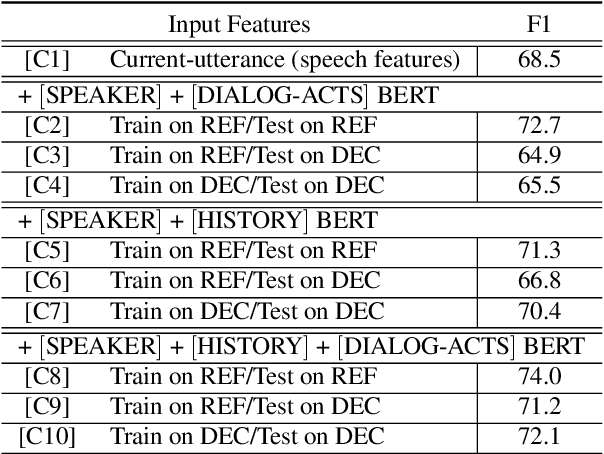
End-to-end spoken language understanding (SLU) systems that process human-human or human-computer interactions are often context independent and process each turn of a conversation independently. Spoken conversations on the other hand, are very much context dependent, and dialog history contains useful information that can improve the processing of each conversational turn. In this paper, we investigate the importance of dialog history and how it can be effectively integrated into end-to-end SLU systems. While processing a spoken utterance, our proposed RNN transducer (RNN-T) based SLU model has access to its dialog history in the form of decoded transcripts and SLU labels of previous turns. We encode the dialog history as BERT embeddings, and use them as an additional input to the SLU model along with the speech features for the current utterance. We evaluate our approach on a recently released spoken dialog data set, the HarperValleyBank corpus. We observe significant improvements: 8% for dialog action and 30% for caller intent recognition tasks, in comparison to a competitive context independent end-to-end baseline system.
Summary Grounded Conversation Generation
Jun 07, 2021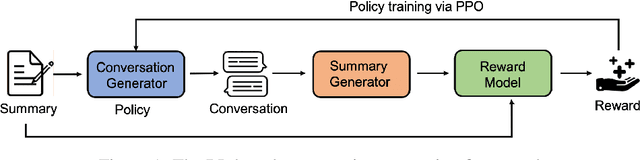
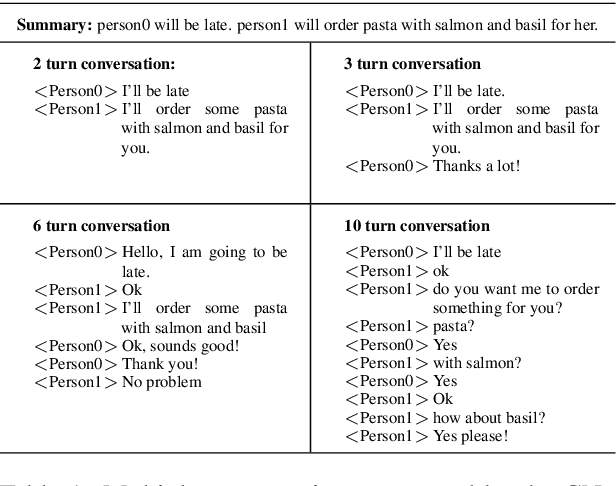
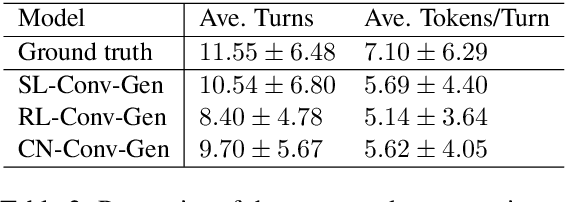
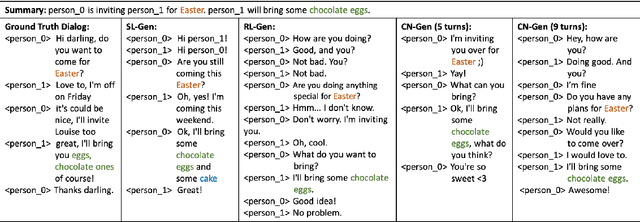
Many conversation datasets have been constructed in the recent years using crowdsourcing. However, the data collection process can be time consuming and presents many challenges to ensure data quality. Since language generation has improved immensely in recent years with the advancement of pre-trained language models, we investigate how such models can be utilized to generate entire conversations, given only a summary of a conversation as the input. We explore three approaches to generate summary grounded conversations, and evaluate the generated conversations using automatic measures and human judgements. We also show that the accuracy of conversation summarization can be improved by augmenting a conversation summarization dataset with generated conversations.