 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuMask-Editor: A Novel Paradigm of Integration Between the Segmentation Diffusion Model and Image Editing to Improve Segmentation Ability
Nov 04, 2024



Semantic segmentation models, like mask2former, often demand a substantial amount of manually annotated data, which is time-consuming and inefficient to acquire. Leveraging state-of-the-art text-to-image models like Midjourney and Stable Diffusion has emerged as an effective strategy for automatically generating synthetic data instead of human annotations. However, prior approaches have been constrained to synthesizing single-instance images due to the instability inherent in generating multiple instances with Stable Diffusion. To expand the domains and diversity of synthetic datasets, this paper introduces a novel paradigm named DiffuMask-Editor, which combines the Diffusion Model for Segmentation with Image Editing. By integrating multiple objects into images using Text2Image models, our method facilitates the creation of more realistic datasets that closely resemble open-world settings while simultaneously generating accurate masks. Our approach significantly reduces the laborious effort associated with manual annotation while ensuring precise mask generation. Experimental results demonstrate that synthetic data generated by DiffuMask-Editor enable segmentation methods to achieve superior performance compared to real data. Particularly in zero-shot backgrounds, DiffuMask-Editor achieves new state-of-the-art results on Unseen classes of VOC 2012. The code and models will be publicly available soon.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
Aug 21, 2024Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.
Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance
Apr 12, 2024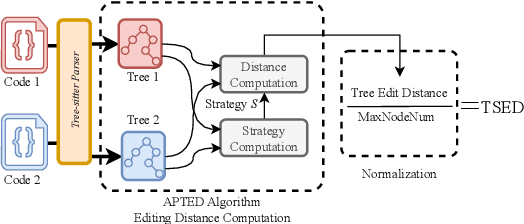
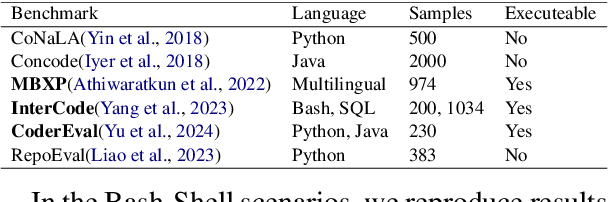
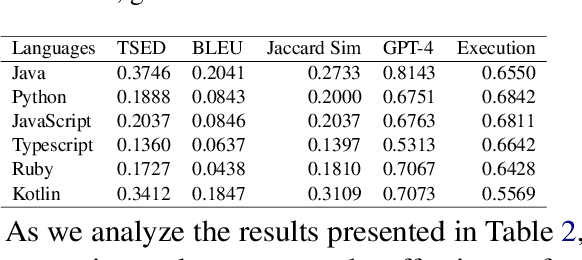
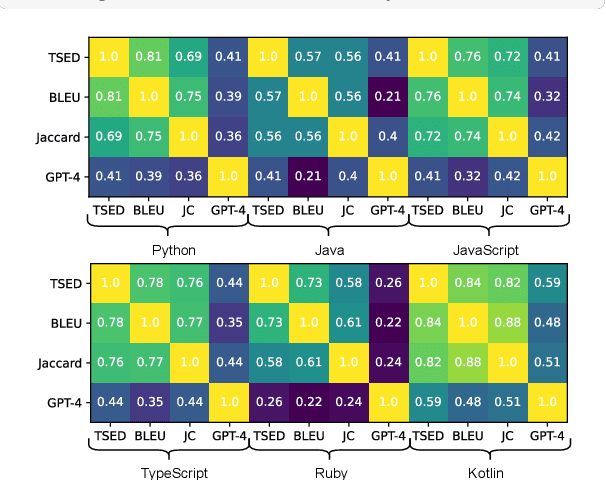
This paper revisits recent code similarity evaluation metrics, particularly focusing on the application of Abstract Syntax Tree (AST) editing distance in diverse programming languages. In particular, we explore the usefulness of these metrics and compare them to traditional sequence similarity metrics. Our experiments showcase the effectiveness of AST editing distance in capturing intricate code structures, revealing a high correlation with established metrics. Furthermore, we explore the strengths and weaknesses of AST editing distance and prompt-based GPT similarity scores in comparison to BLEU score, execution match, and Jaccard Similarity. We propose, optimize, and publish an adaptable metric that demonstrates effectiveness across all tested languages, representing an enhanced version of Tree Similarity of Edit Distance (TSED).
Emotion Detection in Unfix-length-Context Conversation
Feb 13, 2023We leverage different context windows when predicting the emotion of different utterances. New modules are included to realize variable-length context: 1) two speaker-aware units, which explicitly model inner- and inter-speaker dependencies to form distilled conversational context, and 2) a top-k normalization layer, which determines the most proper context windows from the conversational context to predict emotion. Experiments and ablation studies show that our approach outperforms several strong baselines on three public datasets.
HieNet: Bidirectional Hierarchy Framework for Automated ICD Coding
Dec 09, 2022International Classification of Diseases (ICD) is a set of classification codes for medical records. Automated ICD coding, which assigns unique International Classification of Diseases codes with each medical record, is widely used recently for its efficiency and error-prone avoidance. However, there are challenges that remain such as heterogeneity, label unbalance, and complex relationships between ICD codes. In this work, we proposed a novel Bidirectional Hierarchy Framework(HieNet) to address the challenges. Specifically, a personalized PageRank routine is developed to capture the co-relation of codes, a bidirectional hierarchy passage encoder to capture the codes' hierarchical representations, and a progressive predicting method is then proposed to narrow down the semantic searching space of prediction. We validate our method on two widely used datasets. Experimental results on two authoritative public datasets demonstrate that our proposed method boosts state-of-the-art performance by a large margin.
Automatically Extracting Information in Medical Dialogue: Expert System And Attention for Labelling
Nov 28, 2022Medical dialogue information extraction is becoming an increasingly significant problem in modern medical care. It is difficult to extract key information from electronic medical records (EMRs) due to their large numbers. Previously, researchers proposed attention-based models for retrieving features from EMRs, but their limitations were reflected in their inability to recognize different categories in medical dialogues. In this paper, we propose a novel model, Expert System and Attention for Labelling (ESAL). We use mixture of experts and pre-trained BERT to retrieve the semantics of different categories, enabling the model to fuse the differences between them. In our experiment, ESAL was applied to a public dataset and the experimental results indicated that ESAL significantly improved the performance of Medical Information Classification.
Data assimilation in Agent-based models using creation and annihilation operators
Oct 08, 2019
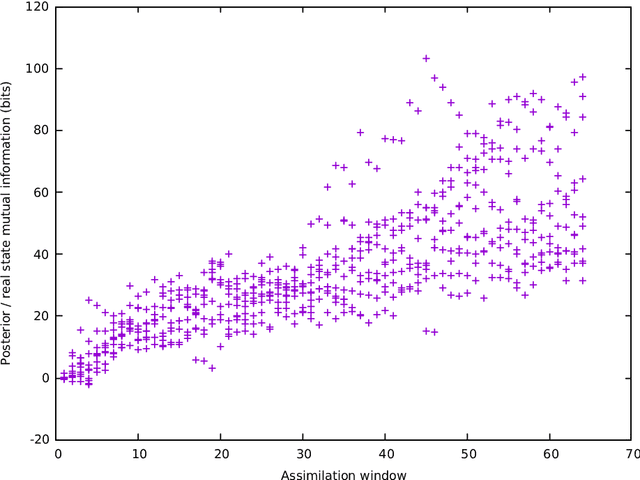
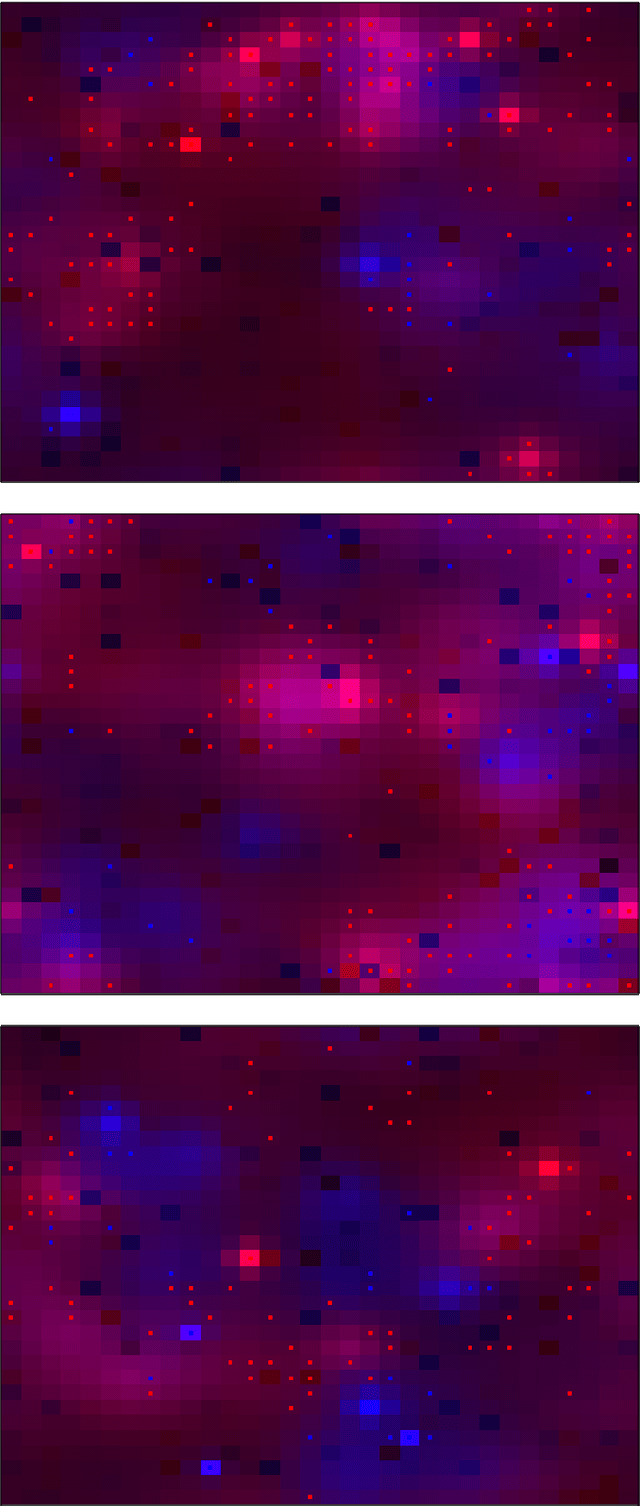
Agent-based models are a powerful tool for studying the behaviour of complex systems that can be described in terms of multiple, interacting ``agents''. However, because of their inherently discrete and often highly non-linear nature, it is very difficult to reason about the relationship between the state of the model, on the one hand, and our observations of the real world on the other. In this paper we consider agents that have a discrete set of states that, at any instant, act with a probability that may depend on the environment or the state of other agents. Given this, we show how the mathematical apparatus of quantum field theory can be used to reason probabilistically about the state and dynamics the model, and describe an algorithm to update our belief in the state of the model in the light of new, real-world observations. Using a simple predator-prey model on a 2-dimensional spatial grid as an example, we demonstrate the assimilation of incomplete, noisy observations and show that this leads to an increase in the mutual information between the actual state of the observed system and the posterior distribution given the observations, when compared to a null model.