 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Bridge Sampling for Evaluating Safety-Critical Autonomous Systems
Aug 24, 2020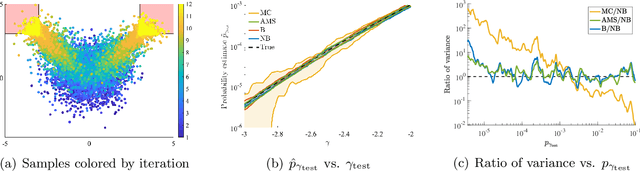
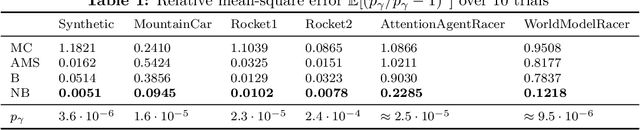
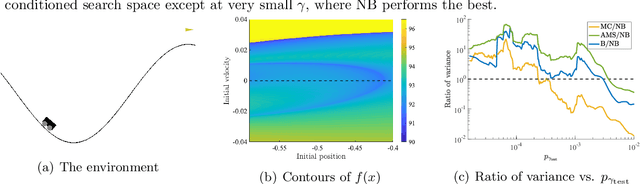
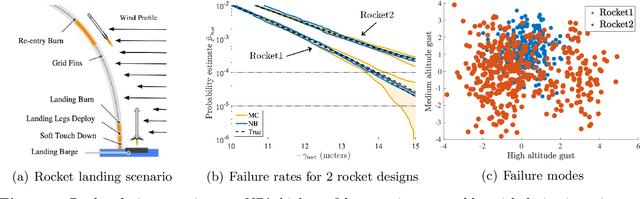
Learning-based methodologies increasingly find applications in safety-critical domains like autonomous driving and medical robotics. Due to the rare nature of dangerous events, real-world testing is prohibitively expensive and unscalable. In this work, we employ a probabilistic approach to safety evaluation in simulation, where we are concerned with computing the probability of dangerous events. We develop a novel rare-event simulation method that combines exploration, exploitation, and optimization techniques to find failure modes and estimate their rate of occurrence. We provide rigorous guarantees for the performance of our method in terms of both statistical and computational efficiency. Finally, we demonstrate the efficacy of our approach on a variety of scenarios, illustrating its usefulness as a tool for rapid sensitivity analysis and model comparison that are essential to developing and testing safety-critical autonomous systems.
Soft-Bubble grippers for robust and perceptive manipulation
Apr 28, 2020
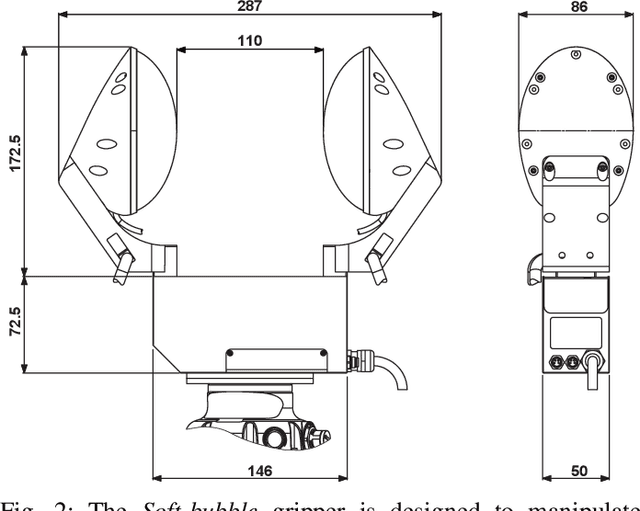
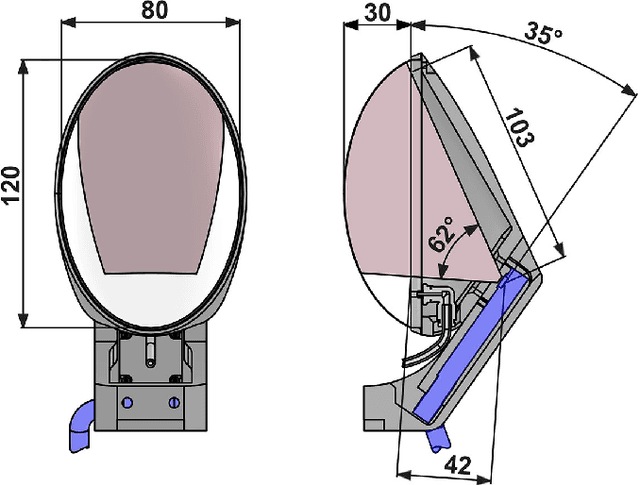

Manipulation in cluttered environments like homes requires stable grasps, precise placement and robustness against external contact. We present the Soft-Bubble gripper system with a highly compliant gripping surface and dense-geometry visuotactile sensing, capable of multiple kinds of tactile perception. We first present various mechanical design advances and a fabrication technique to deposit custom patterns to the internal surface of the sensor that enable tracking of shear-induced displacement of the manipuland. The depth maps output by the internal imaging sensor are used in an in-hand proximity pose estimation framework -- the method better captures distances to corners or edges on the manipuland geometry. We also extend our previous work on tactile classification and integrate the system within a robust manipulation pipeline for cluttered home environments. The capabilities of the proposed system are demonstrated through robust execution multiple real-world manipulation tasks. A video of the system in action can be found here: [https://youtu.be/G_wBsbQyBfc].
FormulaZero: Distributionally Robust Online Adaptation via Offline Population Synthesis
Mar 09, 2020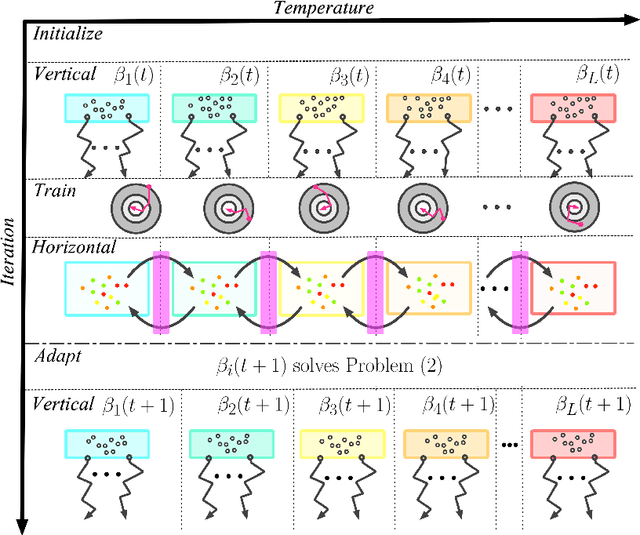
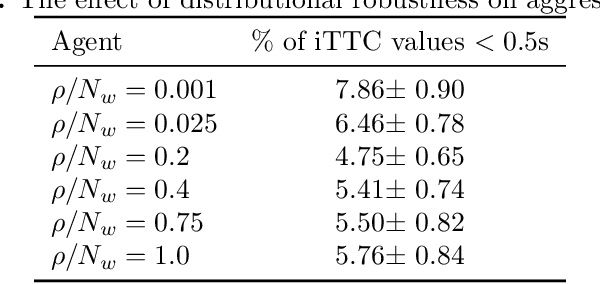

Balancing performance and safety is crucial to deploying autonomous vehicles in multi-agent environments. In particular, autonomous racing is a domain that penalizes safe but conservative policies, highlighting the need for robust, adaptive strategies. Current approaches either make simplifying assumptions about other agents or lack robust mechanisms for online adaptation. This work makes algorithmic contributions to both challenges. First, to generate a realistic, diverse set of opponents, we develop a novel method for self-play based on replica-exchange Markov chain Monte Carlo. Second, we propose a distributionally robust bandit optimization procedure that adaptively adjusts risk aversion relative to uncertainty in beliefs about opponents' behaviors. We rigorously quantify the tradeoffs in performance and robustness when approximating these computations in real-time motion-planning, and we demonstrate our methods experimentally on autonomous vehicles that achieve scaled speeds comparable to Formula One racecars.
The Surprising Effectiveness of Linear Models for Visual Foresight in Object Pile Manipulation
Feb 21, 2020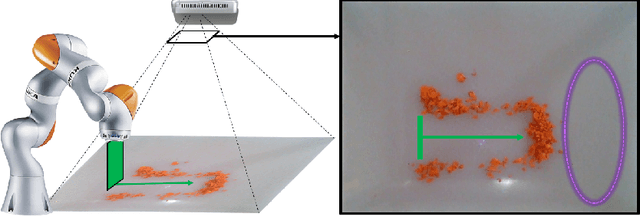


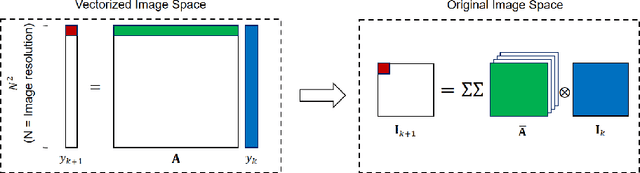
In this paper, we tackle the problem of pushing piles of small objects into a desired target set using visual feedback. Unlike conventional single-object manipulation pipelines, which estimate the state of the system parametrized by pose, the underlying physical state of this system is difficult to observe from images. Thus, we take the approach of reasoning directly in the space of images, and acquire the dynamics of visual measurements in order to synthesize a visual-feedback policy. We present a simple controller using an image-space Lyapunov function, and evaluate the closed-loop performance using three different class of models for image prediction: deep-learning-based models for image-to-image translation, an object-centric model obtained from treating each pixel as a particle, and a switched-linear system where an action-dependent linear map is used. Through results in simulation and experiment, we show that for this task, a linear model works surprisingly well -- achieving better prediction error, downstream task performance, and generalization to new environments than the deep models we trained on the same amount of data. We believe these results provide an interesting example in the spectrum of models that are most useful for vision-based feedback in manipulation, considering both the quality of visual prediction, as well as compatibility with rigorous methods for control design and analysis.
Local Trajectory Stabilization for Dexterous Manipulation via Piecewise Affine Approximations
Sep 17, 2019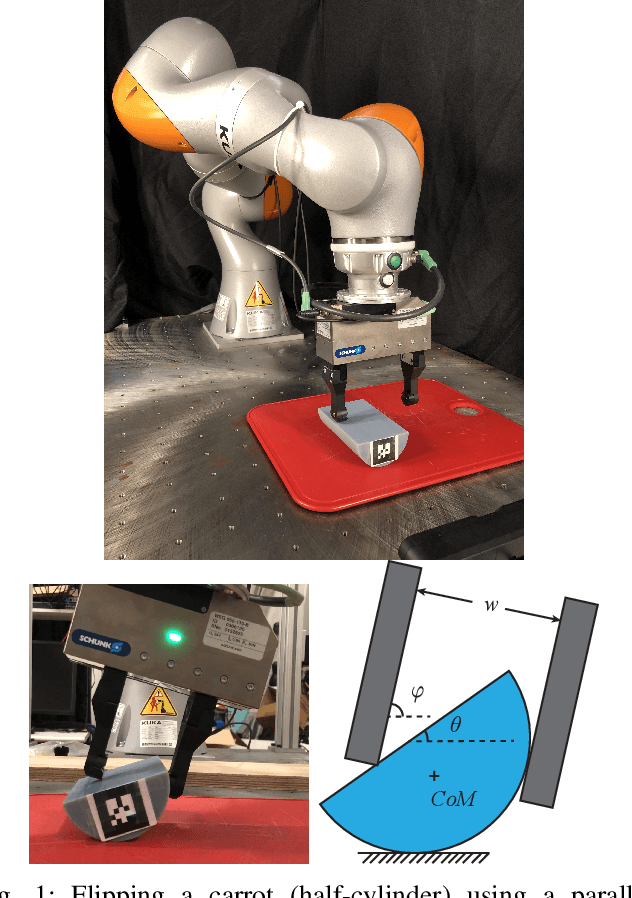
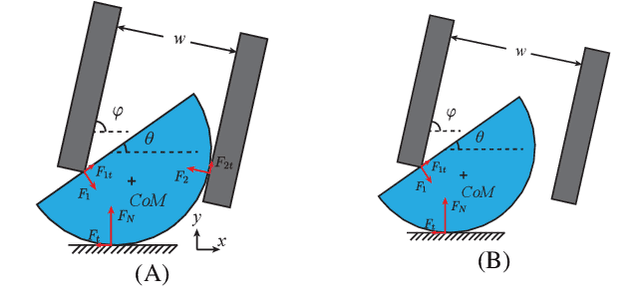
We propose a model-based approach to design feedback policies for dexterous robotic manipulation. The manipulation problem is formulated as reaching the target region from an initial state for some non-smooth nonlinear system. First, we use trajectory optimization to find a feasible trajectory. Next, we characterize the local multi-contact dynamics around the trajectory as a piecewise affine system, and build a funnel around the linearization of the nominal trajectory using polytopes. We prove that the feedback controller at the vicinity of the linearization is guaranteed to drive the nonlinear system to the target region. During online execution, we solve linear programs to track the system trajectory. We validate the algorithm on hardware, showing that even under large external disturbances, the controller is able to accomplish the task.
kPAM-SC: Generalizable Manipulation Planning using KeyPoint Affordance and Shape Completion
Sep 16, 2019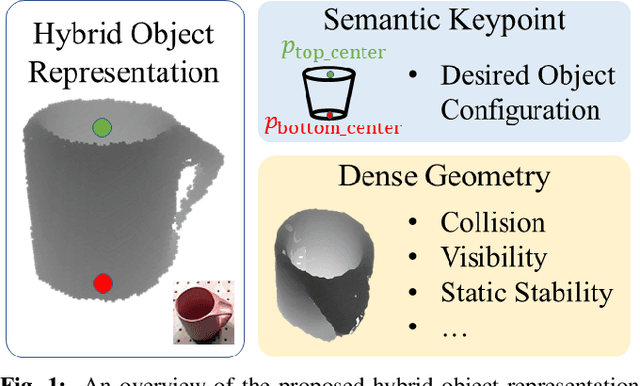
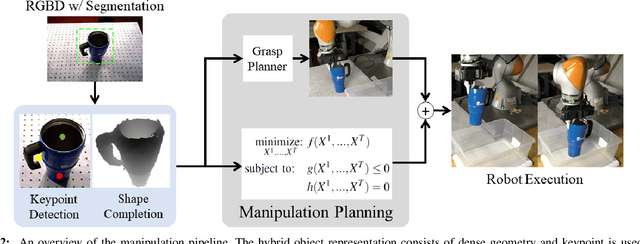


Manipulation planning is the task of computing robot trajectories that move a set of objects to their target configuration while satisfying physically feasibility. In contrast to existing works that assume known object templates, we are interested in manipulation planning for a category of objects with potentially unknown instances and large intra-category shape variation. To achieve it, we need an object representation with which the manipulation planner can reason about both the physical feasibility and desired object configuration, while being generalizable to novel instances. The widely-used pose representation is not suitable, as representing an object with a parameterized transformation from a fixed template cannot capture large intra-category shape variation. Hence, we propose a new hybrid object representation consisting of semantic keypoint and dense geometry (a point cloud or mesh) as the interface between the perception module and motion planner. Leveraging advances in learning-based keypoint detection and shape completion, both dense geometry and keypoints can be perceived from raw sensor input. Using the proposed hybrid object representation, we formulate the manipulation task as a motion planning problem which encodes both the object target configuration and physical feasibility for a category of objects. In this way, many existing manipulation planners can be generalized to categories of objects, and the resulting perception-to-action manipulation pipeline is robust to large intra-category shape variation. Extensive hardware experiments demonstrate our pipeline can produce robot trajectories that accomplish tasks with never-before-seen objects.
Self-Supervised Correspondence in Visuomotor Policy Learning
Sep 16, 2019
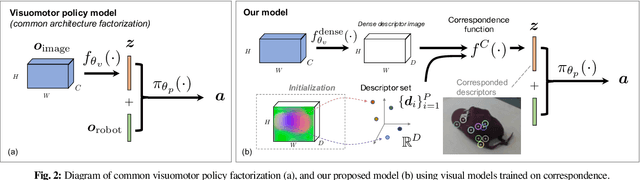
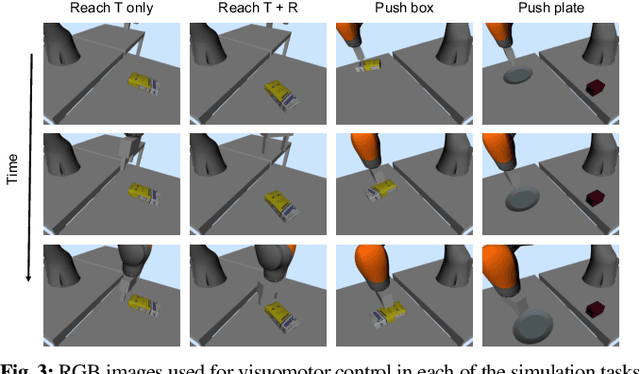
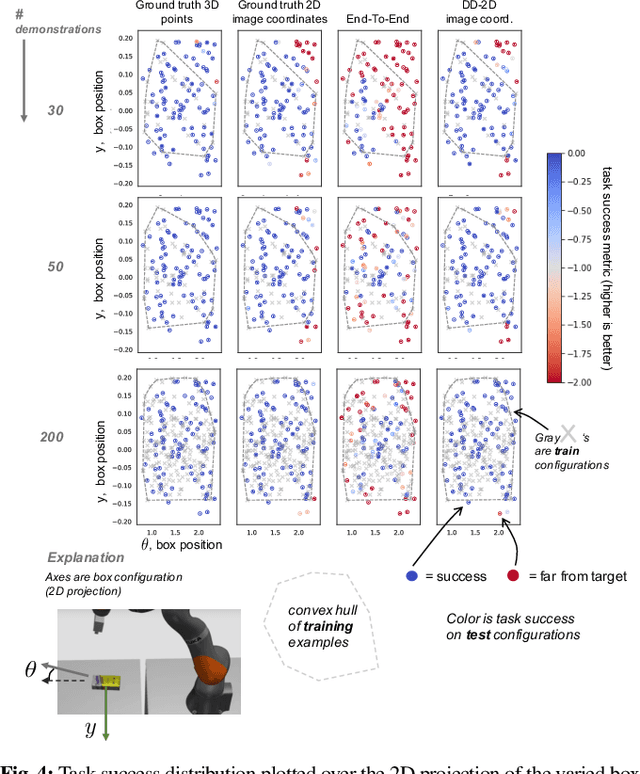
In this paper we explore using self-supervised correspondence for improving the generalization performance and sample efficiency of visuomotor policy learning. Prior work has primarily used approaches such as autoencoding, pose-based losses, and end-to-end policy optimization in order to train the visual portion of visuomotor policies. We instead propose an approach using self-supervised dense visual correspondence training, and show this enables visuomotor policy learning with surprisingly high generalization performance with modest amounts of data: using imitation learning, we demonstrate extensive hardware validation on challenging manipulation tasks with as few as 50 demonstrations. Our learned policies can generalize across classes of objects, react to deformable object configurations, and manipulate textureless symmetrical objects in a variety of backgrounds, all with closed-loop, real-time vision-based policies. Simulated imitation learning experiments suggest that correspondence training offers sample complexity and generalization benefits compared to autoencoding and end-to-end training.
Connecting Touch and Vision via Cross-Modal Prediction
Jun 14, 2019
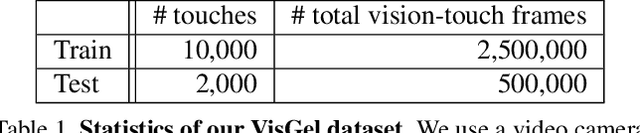

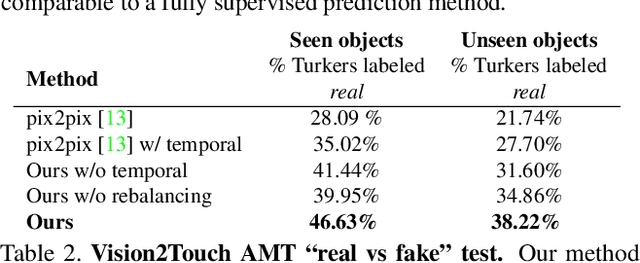
Humans perceive the world using multi-modal sensory inputs such as vision, audition, and touch. In this work, we investigate the cross-modal connection between vision and touch. The main challenge in this cross-domain modeling task lies in the significant scale discrepancy between the two: while our eyes perceive an entire visual scene at once, humans can only feel a small region of an object at any given moment. To connect vision and touch, we introduce new tasks of synthesizing plausible tactile signals from visual inputs as well as imagining how we interact with objects given tactile data as input. To accomplish our goals, we first equip robots with both visual and tactile sensors and collect a large-scale dataset of corresponding vision and tactile image sequences. To close the scale gap, we present a new conditional adversarial model that incorporates the scale and location information of the touch. Human perceptual studies demonstrate that our model can produce realistic visual images from tactile data and vice versa. Finally, we present both qualitative and quantitative experimental results regarding different system designs, as well as visualizing the learned representations of our model.
SurfelWarp: Efficient Non-Volumetric Single View Dynamic Reconstruction
Apr 30, 2019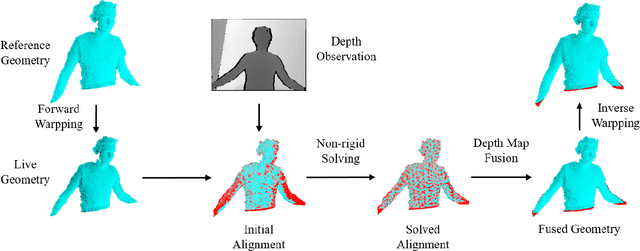

We contribute a dense SLAM system that takes a live stream of depth images as input and reconstructs non-rigid deforming scenes in real time, without templates or prior models. In contrast to existing approaches, we do not maintain any volumetric data structures, such as truncated signed distance function (TSDF) fields or deformation fields, which are performance and memory intensive. Our system works with a flat point (surfel) based representation of geometry, which can be directly acquired from commodity depth sensors. Standard graphics pipelines and general purpose GPU (GPGPU) computing are leveraged for all central operations: i.e., nearest neighbor maintenance, non-rigid deformation field estimation and fusion of depth measurements. Our pipeline inherently avoids expensive volumetric operations such as marching cubes, volumetric fusion and dense deformation field update, leading to significantly improved performance. Furthermore, the explicit and flexible surfel based geometry representation enables efficient tackling of topology changes and tracking failures, which makes our reconstructions consistent with updated depth observations. Our system allows robots to maintain a scene description with non-rigidly deformed objects that potentially enables interactions with dynamic working environments.
Soft-bubble: A highly compliant dense geometry tactile sensor for robot manipulation
Apr 03, 2019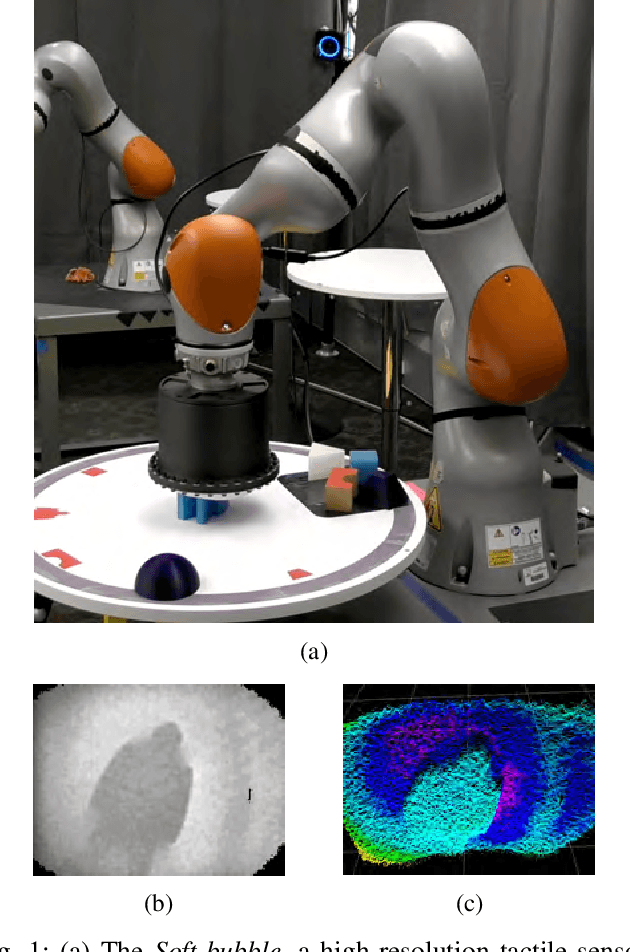
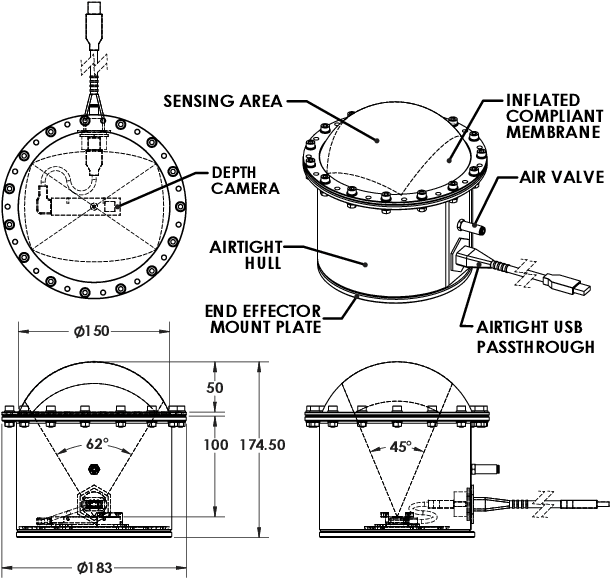


Incorporating effective tactile sensing and mechanical compliance is key towards enabling robust and safe operation of robots in unknown, uncertain and cluttered environments. Towards realizing this goal, we present a lightweight, easy-to-build, highly compliant dense geometry sensor and end effector that comprises an inflated latex membrane with a depth sensor behind it. We present the motivations and the hardware design for this Soft-bubble and demonstrate its capabilities through example tasks including tactile-object classification, pose estimation and tracking, and nonprehensile object manipulation. We also present initial experiments to show the importance of high-resolution geometry sensing for tactile tasks and discuss applications in robust manipulation.