 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Active Defense Persistence: A Two-Stage Defense Framework Combining Interruption and Poisoning Against Deepfake
Aug 11, 2025Active defense strategies have been developed to counter the threat of deepfake technology. However, a primary challenge is their lack of persistence, as their effectiveness is often short-lived. Attackers can bypass these defenses by simply collecting protected samples and retraining their models. This means that static defenses inevitably fail when attackers retrain their models, which severely limits practical use. We argue that an effective defense not only distorts forged content but also blocks the model's ability to adapt, which occurs when attackers retrain their models on protected images. To achieve this, we propose an innovative Two-Stage Defense Framework (TSDF). Benefiting from the intensity separation mechanism designed in this paper, the framework uses dual-function adversarial perturbations to perform two roles. First, it can directly distort the forged results. Second, it acts as a poisoning vehicle that disrupts the data preparation process essential for an attacker's retraining pipeline. By poisoning the data source, TSDF aims to prevent the attacker's model from adapting to the defensive perturbations, thus ensuring the defense remains effective long-term. Comprehensive experiments show that the performance of traditional interruption methods degrades sharply when it is subjected to adversarial retraining. However, our framework shows a strong dual defense capability, which can improve the persistence of active defense. Our code will be available at https://github.com/vpsg-research/TSDF.
STLGame: Signal Temporal Logic Games in Adversarial Multi-Agent Systems
Dec 02, 2024We study how to synthesize a robust and safe policy for autonomous systems under signal temporal logic (STL) tasks in adversarial settings against unknown dynamic agents. To ensure the worst-case STL satisfaction, we propose STLGame, a framework that models the multi-agent system as a two-player zero-sum game, where the ego agents try to maximize the STL satisfaction and other agents minimize it. STLGame aims to find a Nash equilibrium policy profile, which is the best case in terms of robustness against unseen opponent policies, by using the fictitious self-play (FSP) framework. FSP iteratively converges to a Nash profile, even in games set in continuous state-action spaces. We propose a gradient-based method with differentiable STL formulas, which is crucial in continuous settings to approximate the best responses at each iteration of FSP. We show this key aspect experimentally by comparing with reinforcement learning-based methods to find the best response. Experiments on two standard dynamical system benchmarks, Ackermann steering vehicles and autonomous drones, demonstrate that our converged policy is almost unexploitable and robust to various unseen opponents' policies. All code and additional experimental results can be found on our project website: https://sites.google.com/view/stlgame
Bridging the Gap between Discrete Agent Strategies in Game Theory and Continuous Motion Planning in Dynamic Environments
Mar 17, 2024



Generating competitive strategies and performing continuous motion planning simultaneously in an adversarial setting is a challenging problem. In addition, understanding the intent of other agents is crucial to deploying autonomous systems in adversarial multi-agent environments. Existing approaches either discretize agent action by grouping similar control inputs, sacrificing performance in motion planning, or plan in uninterpretable latent spaces, producing hard-to-understand agent behaviors. This paper proposes an agent strategy representation via Policy Characteristic Space that maps the agent policies to a pre-specified low-dimensional space. Policy Characteristic Space enables the discretization of agent policy switchings while preserving continuity in control. Also, it provides intepretability of agent policies and clear intentions of policy switchings. Then, regret-based game-theoretic approaches can be applied in the Policy Characteristic Space to obtain high performance in adversarial environments. Our proposed method is assessed by conducting experiments in an autonomous racing scenario using scaled vehicles. Statistical evidence shows that our method significantly improves the win rate of ego agent and the method also generalizes well to unseen environments.
Differentiable Trajectory Generation for Car-like Robots with Interpolating Radial Basis Function Networks
Mar 02, 2023The design of Autonomous Vehicle software has largely followed the Sense-Plan-Act model. Traditional modular AV stacks develop perception, planning, and control software separately with little integration when optimizing for different objectives. On the other hand, end-to-end methods usually lack the principle provided by model-based white-box planning and control strategies. We propose a computationally efficient method for approximating closed-form trajectory generation with interpolating Radial Basis Function Networks to create a middle ground between the two approaches. The approach creates smooth approximations of local Lipschitz continuous maps of feasible solutions to parametric optimization problems. We show that this differentiable approximation is efficient to compute and allows for tighter integration with perception and control algorithms when used as the planning strategy.
Towards Explainability in Modular Autonomous Vehicle Software
Dec 01, 2022Safety-critical Autonomous Systems require trustworthy and transparent decision-making process to be deployable in the real world. The advancement of Machine Learning introduces high performance but largely through black-box algorithms. We focus the discussion of explainability specifically with Autonomous Vehicles (AVs). As a safety-critical system, AVs provide the unique opportunity to utilize cutting-edge Machine Learning techniques while requiring transparency in decision making. Interpretability in every action the AV takes becomes crucial in post-hoc analysis where blame assignment might be necessary. In this paper, we provide positioning on how researchers could consider incorporating explainability and interpretability into design and optimization of separate Autonomous Vehicle modules including Perception, Planning, and Control.
Local_INN: Implicit Map Representation and Localization with Invertible Neural Networks
Sep 24, 2022
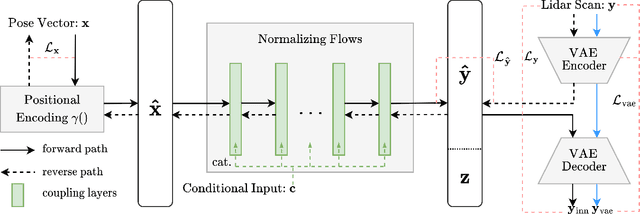

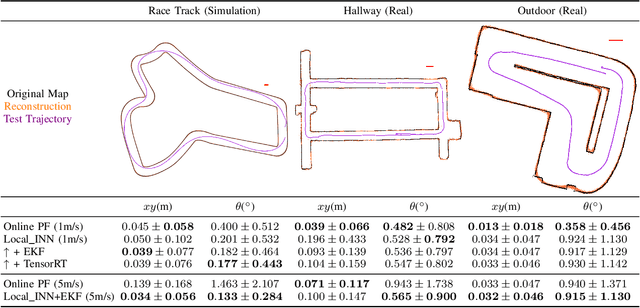
Robot localization is an inverse problem of finding a robot's pose using a map and sensor measurements. In recent years, Invertible Neural Networks (INNs) have successfully solved ambiguous inverse problems in various fields. This paper proposes a framework that solves the localization problem with INN. We design an INN that provides implicit map representation in the forward path and localization in the inverse path. By sampling the latent space in evaluation, Local\_INN outputs robot poses with covariance, which can be used to estimate the uncertainty. We show that the localization performance of Local\_INN is on par with current methods with much lower latency. We show detailed 2D and 3D map reconstruction from Local\_INN using poses exterior to the training set. We also provide a global localization algorithm using Local\_INN to tackle the kidnapping problem.
Accelerating Online Reinforcement Learning via Supervisory Safety Systems
Sep 22, 2022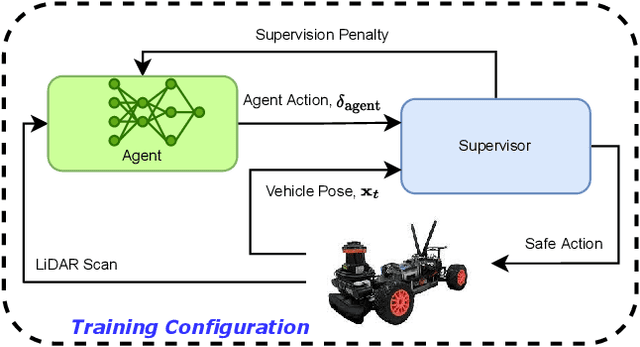
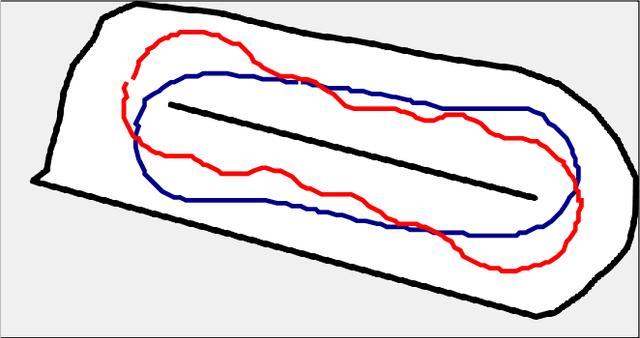
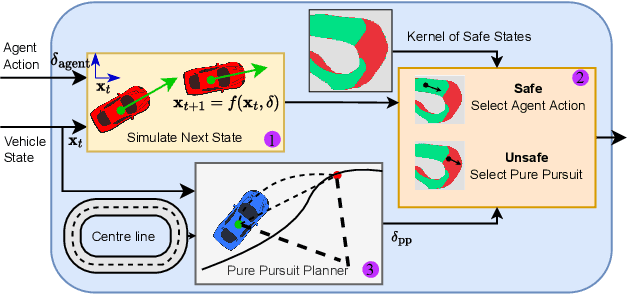
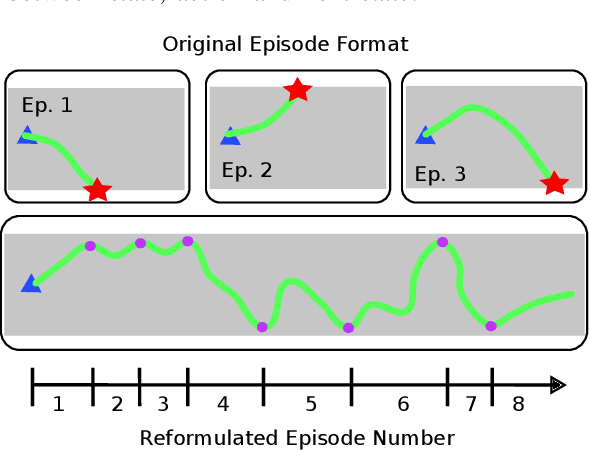
Deep reinforcement learning (DRL) is a promising method to learn control policies for robots only from demonstration and experience. To cover the whole dynamic behaviour of the robot, the DRL training is an active exploration process typically derived in simulation environments. Although this simulation training is cheap and fast, applying DRL algorithms to real-world settings is difficult. If agents are trained until they perform safely in simulation, transferring them to physical systems is difficult due to the sim-to-real gap caused by the difference between the simulation dynamics and the physical robot. In this paper, we present a method of online training a DRL agent to drive autonomously on a physical vehicle by using a model-based safety supervisor. Our solution uses a supervisory system to check if the action selected by the agent is safe or unsafe and ensure that a safe action is always implemented on the vehicle. With this, we can bypass the sim-to-real problem while training the DRL algorithm safely, quickly, and efficiently. We provide a variety of real-world experiments where we train online a small-scale, physical vehicle to drive autonomously with no prior simulation training. The evaluation results show that our method trains agents with improved sample efficiency while never crashing, and the trained agents demonstrate better driving performance than those trained in simulation.
Teaching Autonomous Systems Hands-On: Leveraging Modular Small-Scale Hardware in the Robotics Classroom
Sep 21, 2022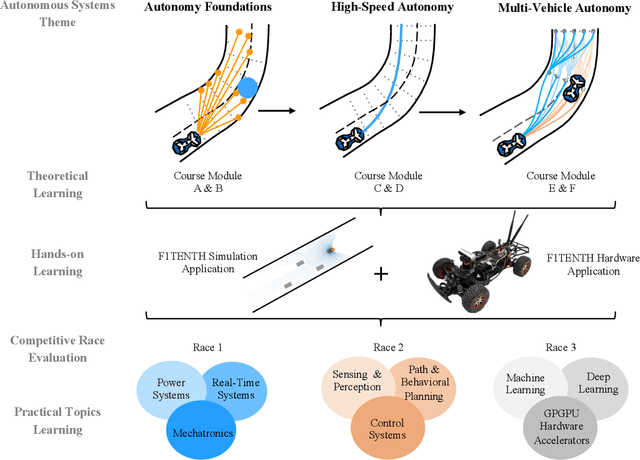
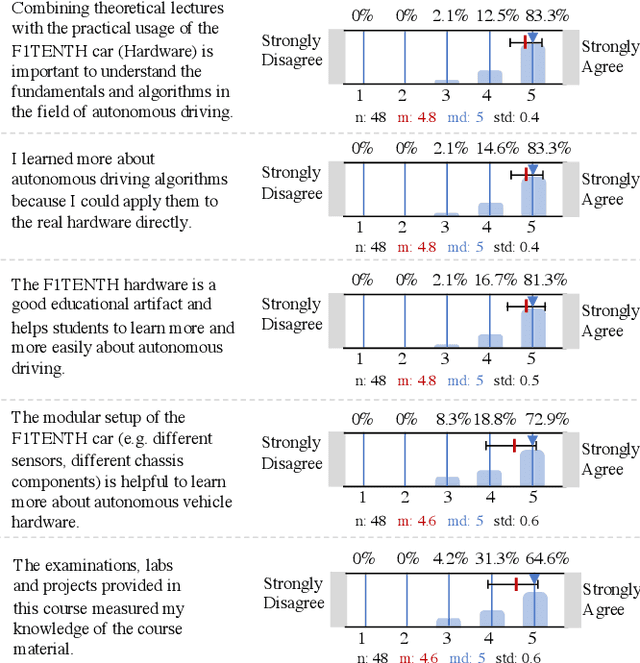
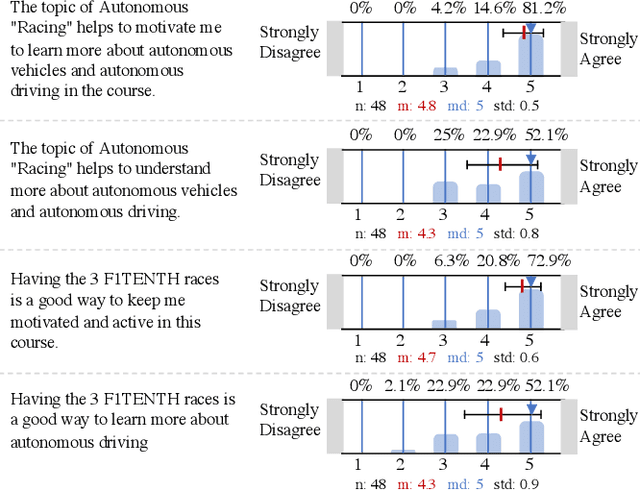
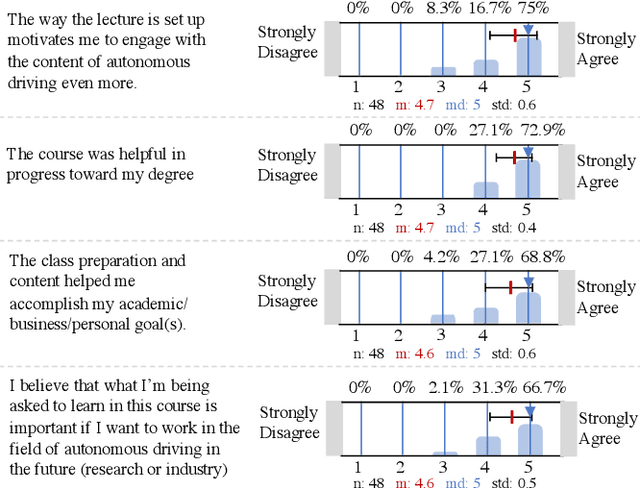
Although robotics courses are well established in higher education, the courses often focus on theory and sometimes lack the systematic coverage of the techniques involved in developing, deploying, and applying software to real hardware. Additionally, most hardware platforms for robotics teaching are low-level toys aimed at younger students at middle-school levels. To address this gap, an autonomous vehicle hardware platform, called F1TENTH, is developed for teaching autonomous systems hands-on. This article describes the teaching modules and software stack for teaching at various educational levels with the theme of "racing" and competitions that replace exams. The F1TENTH vehicles offer a modular hardware platform and its related software for teaching the fundamentals of autonomous driving algorithms. From basic reactive methods to advanced planning algorithms, the teaching modules enhance students' computational thinking through autonomous driving with the F1TENTH vehicle. The F1TENTH car fills the gap between research platforms and low-end toy cars and offers hands-on experience in learning the topics in autonomous systems. Four universities have adopted the teaching modules for their semester-long undergraduate and graduate courses for multiple years. Student feedback is used to analyze the effectiveness of the F1TENTH platform. More than 80% of the students strongly agree that the hardware platform and modules greatly motivate their learning, and more than 70% of the students strongly agree that the hardware-enhanced their understanding of the subjects. The survey results show that more than 80% of the students strongly agree that the competitions motivate them for the course.
Game-theoretic Objective Space Planning
Sep 16, 2022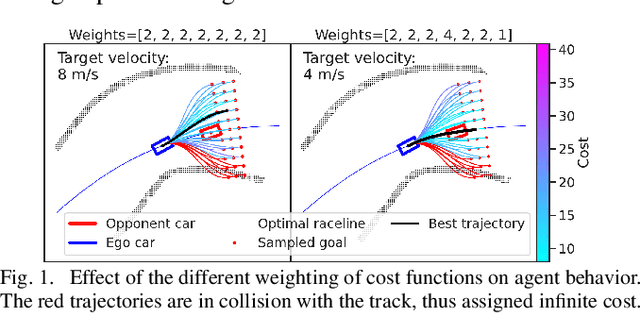
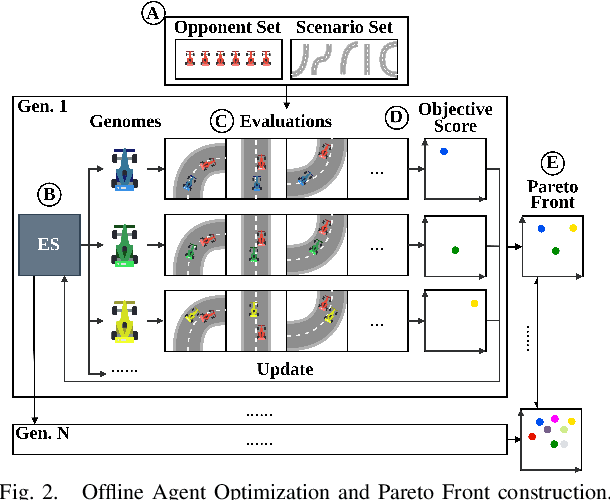
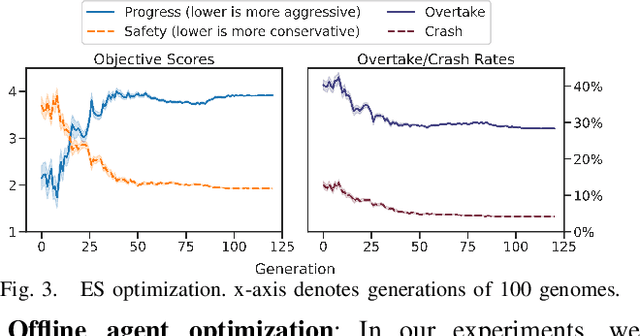
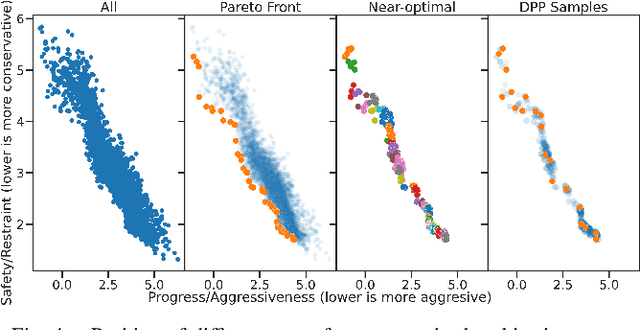
Autonomous Racing awards agents that react to opponents' behaviors with agile maneuvers towards progressing along the track while penalizing both over-aggressive and over-conservative agents. Understanding the intent of other agents is crucial to deploying autonomous systems in adversarial multi-agent environments. Current approaches either oversimplify the discretization of the action space of agents or fail to recognize the long-term effect of actions and become myopic. Our work focuses on addressing these two challenges. First, we propose a novel dimension reduction method that encapsulates diverse agent behaviors while conserving the continuity of agent actions. Second, we formulate the two-agent racing game as a regret minimization problem and provide a solution for tractable counterfactual regret minimization with a regret prediction model. Finally, we validate our findings experimentally on scaled autonomous vehicles. We demonstrate that using the proposed game-theoretic planner using agent characterization with the objective space significantly improves the win rate against different opponents, and the improvement is transferable to unseen opponents in an unseen environment.
Winning the 3rd Japan Automotive AI Challenge -- Autonomous Racing with the Autoware.Auto Open Source Software Stack
Jun 04, 2022
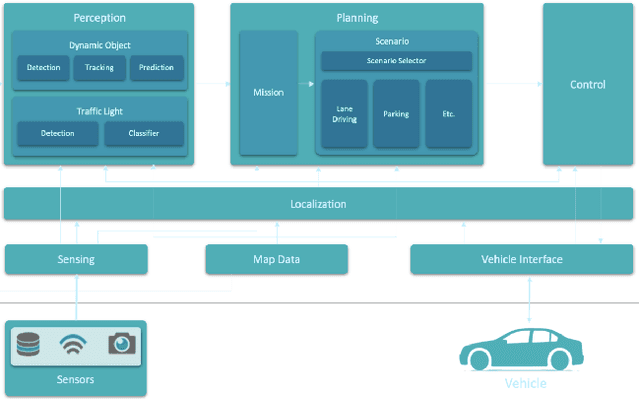
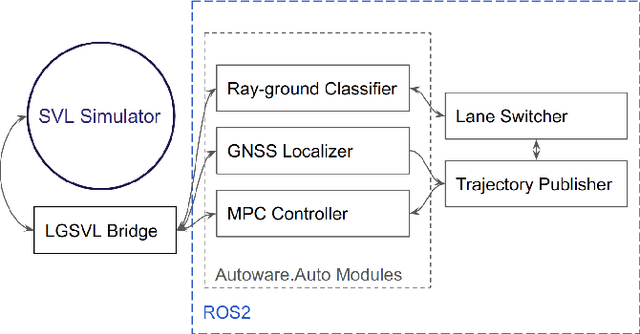
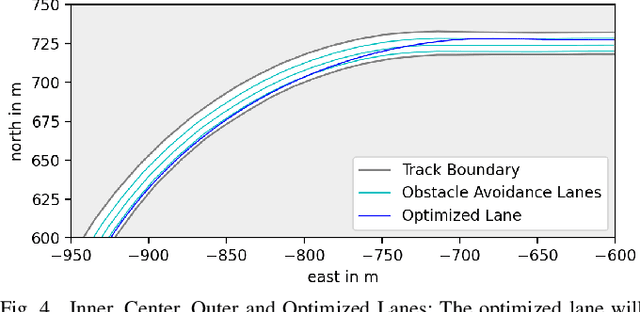
The 3rd Japan Automotive AI Challenge was an international online autonomous racing challenge where 164 teams competed in December 2021. This paper outlines the winning strategy to this competition, and the advantages and challenges of using the Autoware.Auto open source autonomous driving platform for multi-agent racing. Our winning approach includes a lane-switching opponent overtaking strategy, a global raceline optimization, and the integration of various tools from Autoware.Auto including a Model-Predictive Controller. We describe the use of perception, planning and control modules for high-speed racing applications and provide experience-based insights on working with Autoware.Auto. While our approach is a rule-based strategy that is suitable for non-interactive opponents, it provides a good reference and benchmark for learning-enabled approaches.