 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Transfer Through Multilingual and Feedback-Based Back-Translation
Sep 17, 2018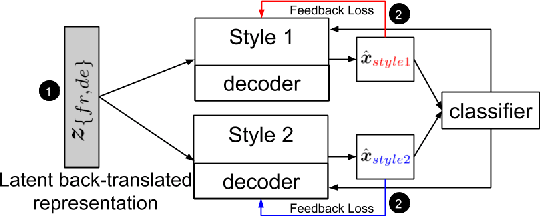
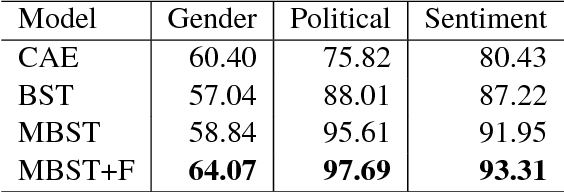

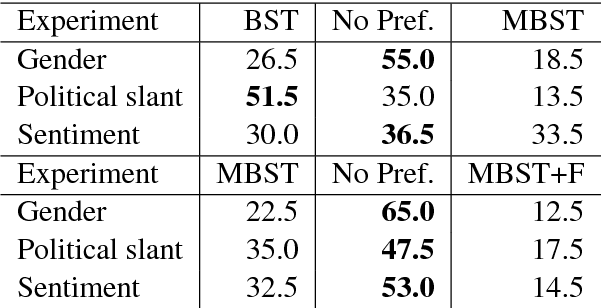
Style transfer is the task of transferring an attribute of a sentence (e.g., formality) while maintaining its semantic content. The key challenge in style transfer is to strike a balance between the competing goals, one to preserve meaning and the other to improve the style transfer accuracy. Prior research has identified that the task of meaning preservation is generally harder to attain and evaluate. This paper proposes two extensions of the state-of-the-art style transfer models aiming at improving the meaning preservation in style transfer. Our evaluation shows that these extensions help to ground meaning better while improving the transfer accuracy.
Toward Controlled Generation of Text
Sep 13, 2018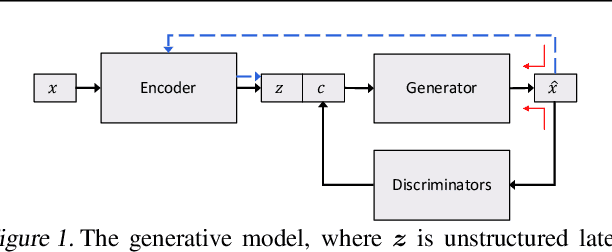
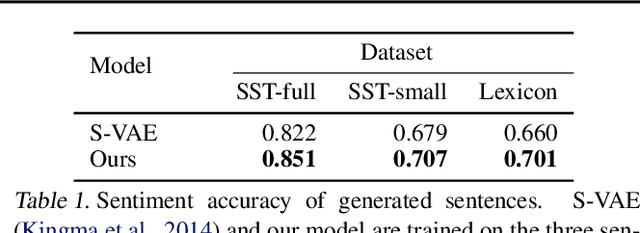
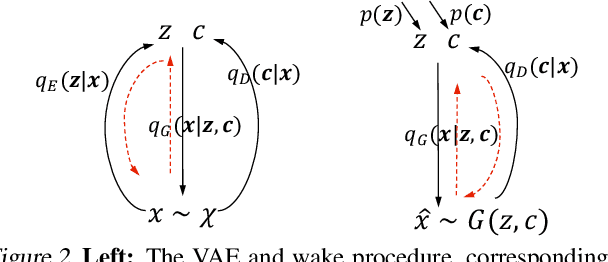
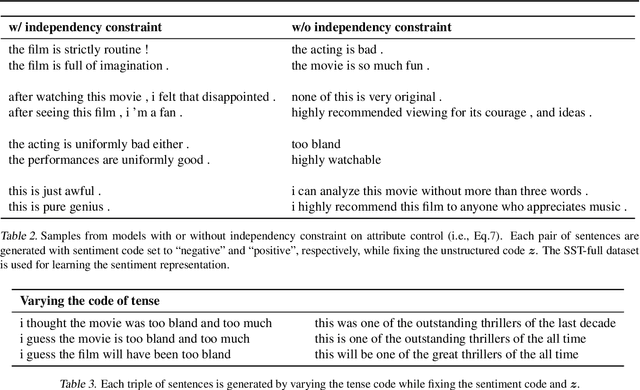
Generic generation and manipulation of text is challenging and has limited success compared to recent deep generative modeling in visual domain. This paper aims at generating plausible natural language sentences, whose attributes are dynamically controlled by learning disentangled latent representations with designated semantics. We propose a new neural generative model which combines variational auto-encoders and holistic attribute discriminators for effective imposition of semantic structures. With differentiable approximation to discrete text samples, explicit constraints on independent attribute controls, and efficient collaborative learning of generator and discriminators, our model learns highly interpretable representations from even only word annotations, and produces realistic sentences with desired attributes. Quantitative evaluation validates the accuracy of sentence and attribute generation.
Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text
Sep 04, 2018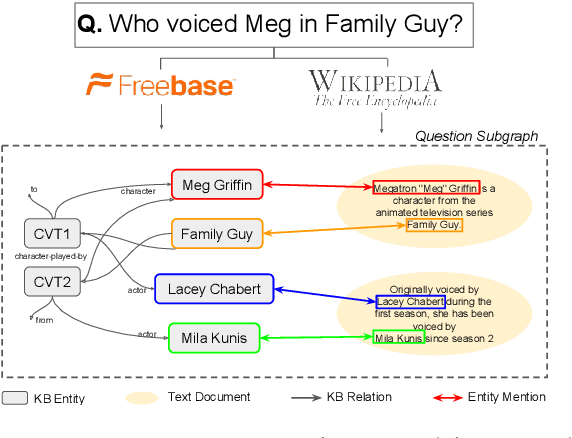

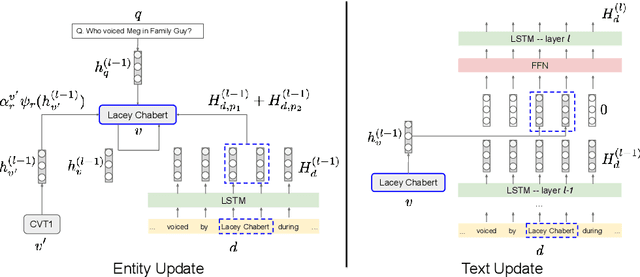
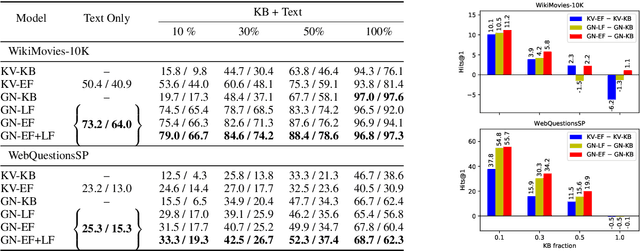
Open Domain Question Answering (QA) is evolving from complex pipelined systems to end-to-end deep neural networks. Specialized neural models have been developed for extracting answers from either text alone or Knowledge Bases (KBs) alone. In this paper we look at a more practical setting, namely QA over the combination of a KB and entity-linked text, which is appropriate when an incomplete KB is available with a large text corpus. Building on recent advances in graph representation learning we propose a novel model, GRAFT-Net, for extracting answers from a question-specific subgraph containing text and KB entities and relations. We construct a suite of benchmark tasks for this problem, varying the difficulty of questions, the amount of training data, and KB completeness. We show that GRAFT-Net is competitive with the state-of-the-art when tested using either KBs or text alone, and vastly outperforms existing methods in the combined setting. Source code is available at https://github.com/OceanskySun/GraftNet .
Investigating the Working of Text Classifiers
Aug 05, 2018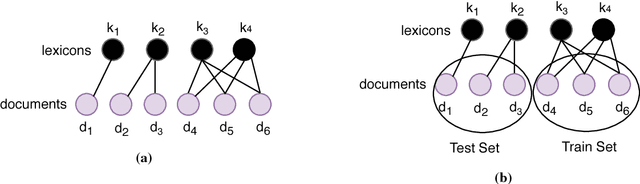
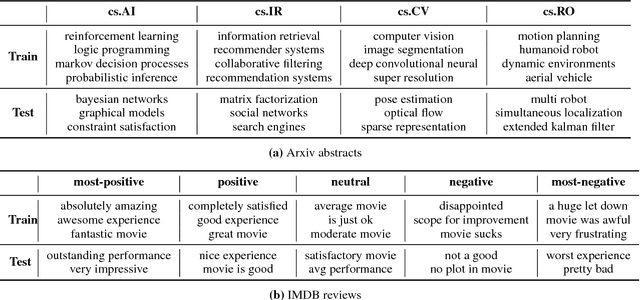
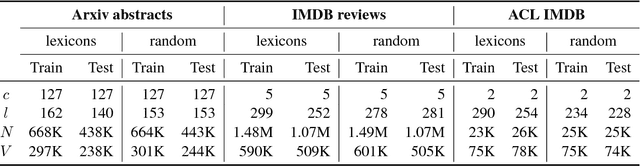

Text classification is one of the most widely studied tasks in natural language processing. Motivated by the principle of compositionality, large multilayer neural network models have been employed for this task in an attempt to effectively utilize the constituent expressions. Almost all of the reported work train large networks using discriminative approaches, which come with a caveat of no proper capacity control, as they tend to latch on to any signal that may not generalize. Using various recent state-of-the-art approaches for text classification, we explore whether these models actually learn to compose the meaning of the sentences or still just focus on some keywords or lexicons for classifying the document. To test our hypothesis, we carefully construct datasets where the training and test splits have no direct overlap of such lexicons, but overall language structure would be similar. We study various text classifiers and observe that there is a big performance drop on these datasets. Finally, we show that even simple models with our proposed regularization techniques, which disincentivize focusing on key lexicons, can substantially improve classification accuracy.
On Unifying Deep Generative Models
Jul 11, 2018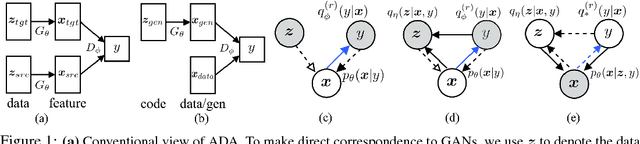

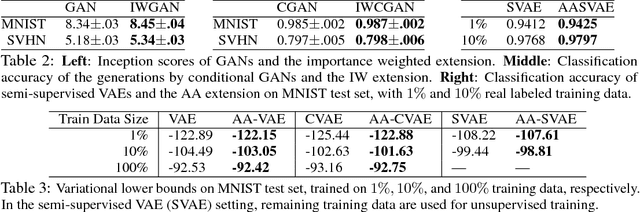
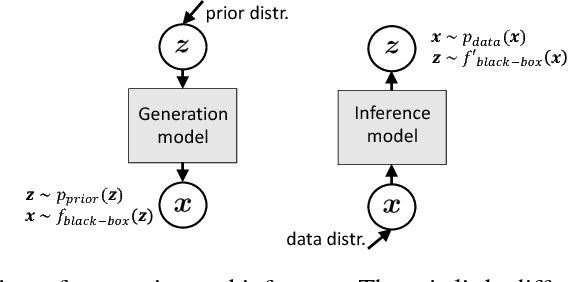
Deep generative models have achieved impressive success in recent years. Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), as emerging families for generative model learning, have largely been considered as two distinct paradigms and received extensive independent studies respectively. This paper aims to establish formal connections between GANs and VAEs through a new formulation of them. We interpret sample generation in GANs as performing posterior inference, and show that GANs and VAEs involve minimizing KL divergences of respective posterior and inference distributions with opposite directions, extending the two learning phases of classic wake-sleep algorithm, respectively. The unified view provides a powerful tool to analyze a diverse set of existing model variants, and enables to transfer techniques across research lines in a principled way. For example, we apply the importance weighting method in VAE literatures for improved GAN learning, and enhance VAEs with an adversarial mechanism that leverages generated samples. Experiments show generality and effectiveness of the transferred techniques.
GLoMo: Unsupervisedly Learned Relational Graphs as Transferable Representations
Jul 02, 2018
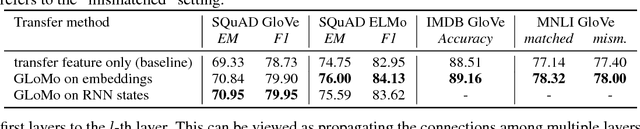
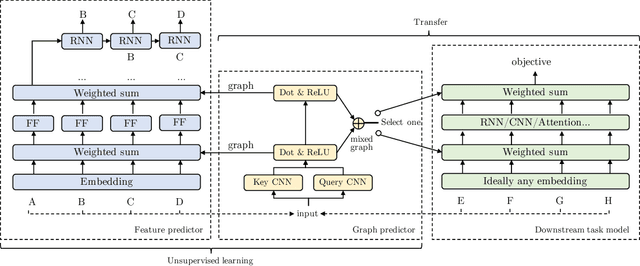
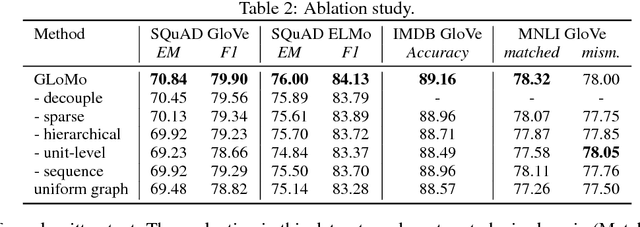
Modern deep transfer learning approaches have mainly focused on learning generic feature vectors from one task that are transferable to other tasks, such as word embeddings in language and pretrained convolutional features in vision. However, these approaches usually transfer unary features and largely ignore more structured graphical representations. This work explores the possibility of learning generic latent relational graphs that capture dependencies between pairs of data units (e.g., words or pixels) from large-scale unlabeled data and transferring the graphs to downstream tasks. Our proposed transfer learning framework improves performance on various tasks including question answering, natural language inference, sentiment analysis, and image classification. We also show that the learned graphs are generic enough to be transferred to different embeddings on which the graphs have not been trained (including GloVe embeddings, ELMo embeddings, and task-specific RNN hidden unit), or embedding-free units such as image pixels.
Deep Generative Models with Learnable Knowledge Constraints
Jun 26, 2018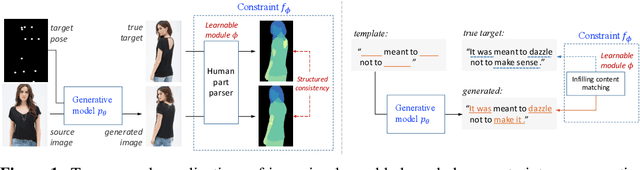

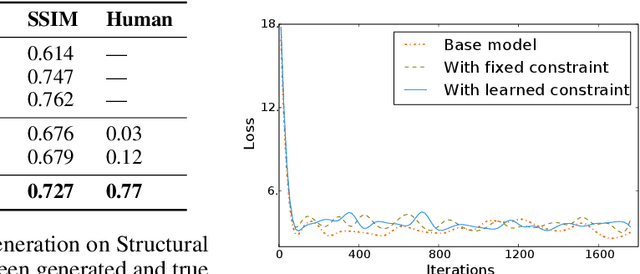
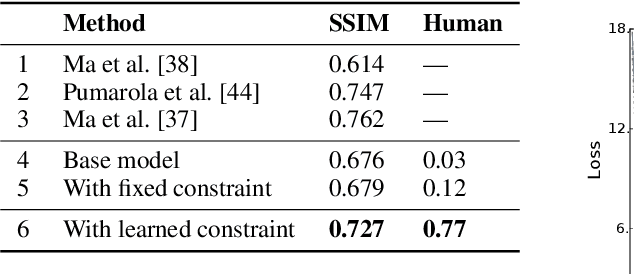
The broad set of deep generative models (DGMs) has achieved remarkable advances. However, it is often difficult to incorporate rich structured domain knowledge with the end-to-end DGMs. Posterior regularization (PR) offers a principled framework to impose structured constraints on probabilistic models, but has limited applicability to the diverse DGMs that can lack a Bayesian formulation or even explicit density evaluation. PR also requires constraints to be fully specified {\it a priori}, which is impractical or suboptimal for complex knowledge with learnable uncertain parts. In this paper, we establish mathematical correspondence between PR and reinforcement learning (RL), and, based on the connection, expand PR to learn constraints as the extrinsic reward in RL. The resulting algorithm is model-agnostic to apply to any DGMs, and is flexible to adapt arbitrary constraints with the model jointly. Experiments on human image generation and templated sentence generation show models with learned knowledge constraints by our algorithm greatly improve over base generative models.
Selecting the Best in GANs Family: a Post Selection Inference Framework
Jun 23, 2018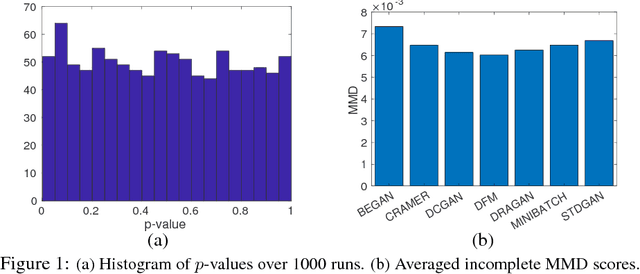
"Which Generative Adversarial Networks (GANs) generates the most plausible images?" has been a frequently asked question among researchers. To address this problem, we first propose an \emph{incomplete} U-statistics estimate of maximum mean discrepancy $\mathrm{MMD}_{inc}$ to measure the distribution discrepancy between generated and real images. $\mathrm{MMD}_{inc}$ enjoys the advantages of asymptotic normality, computation efficiency, and model agnosticity. We then propose a GANs analysis framework to select and test the "best" member in GANs family using the Post Selection Inference (PSI) with $\mathrm{MMD}_{inc}$. In the experiments, we adopt the proposed framework on 7 GANs variants and compare their $\mathrm{MMD}_{inc}$ scores.
Deep Neural Networks with Multi-Branch Architectures Are Less Non-Convex
Jun 21, 2018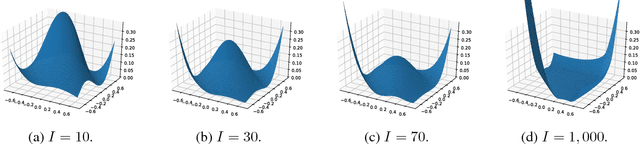
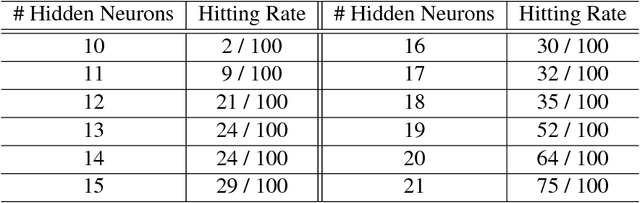
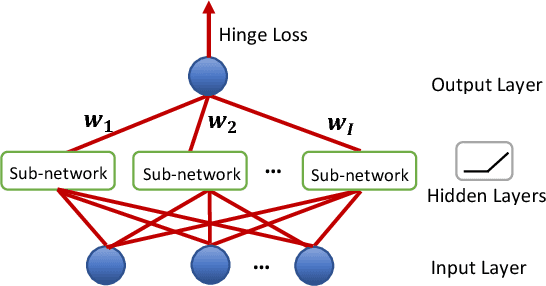
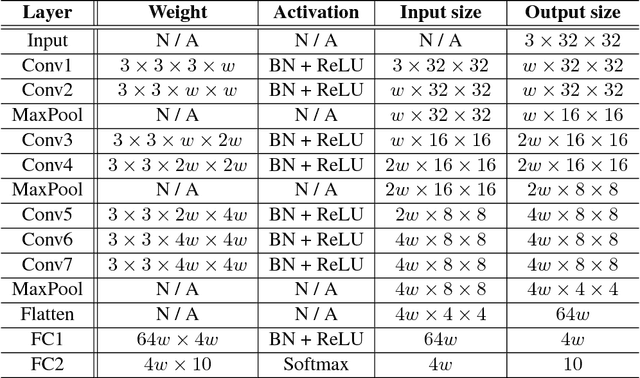
Several recently proposed architectures of neural networks such as ResNeXt, Inception, Xception, SqueezeNet and Wide ResNet are based on the designing idea of having multiple branches and have demonstrated improved performance in many applications. We show that one cause for such success is due to the fact that the multi-branch architecture is less non-convex in terms of duality gap. The duality gap measures the degree of intrinsic non-convexity of an optimization problem: smaller gap in relative value implies lower degree of intrinsic non-convexity. The challenge is to quantitatively measure the duality gap of highly non-convex problems such as deep neural networks. In this work, we provide strong guarantees of this quantity for two classes of network architectures. For the neural networks with arbitrary activation functions, multi-branch architecture and a variant of hinge loss, we show that the duality gap of both population and empirical risks shrinks to zero as the number of branches increases. This result sheds light on better understanding the power of over-parametrization where increasing the network width tends to make the loss surface less non-convex. For the neural networks with linear activation function and $\ell_2$ loss, we show that the duality gap of empirical risk is zero. Our two results work for arbitrary depths and adversarial data, while the analytical techniques might be of independent interest to non-convex optimization more broadly. Experiments on both synthetic and real-world datasets validate our results.
Learning Cognitive Models using Neural Networks
Jun 21, 2018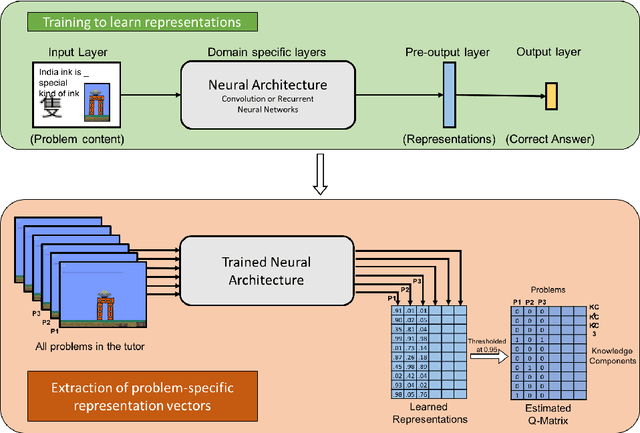

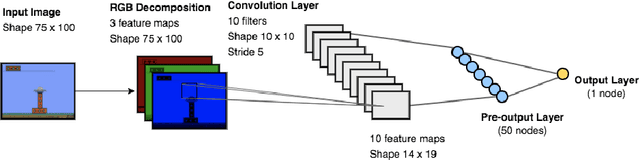
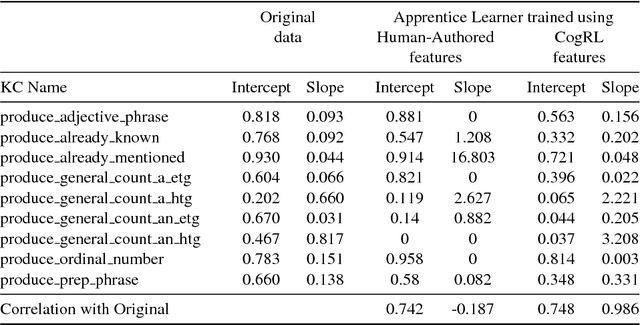
A cognitive model of human learning provides information about skills a learner must acquire to perform accurately in a task domain. Cognitive models of learning are not only of scientific interest, but are also valuable in adaptive online tutoring systems. A more accurate model yields more effective tutoring through better instructional decisions. Prior methods of automated cognitive model discovery have typically focused on well-structured domains, relied on student performance data or involved substantial human knowledge engineering. In this paper, we propose Cognitive Representation Learner (CogRL), a novel framework to learn accurate cognitive models in ill-structured domains with no data and little to no human knowledge engineering. Our contribution is two-fold: firstly, we show that representations learnt using CogRL can be used for accurate automatic cognitive model discovery without using any student performance data in several ill-structured domains: Rumble Blocks, Chinese Character, and Article Selection. This is especially effective and useful in domains where an accurate human-authored cognitive model is unavailable or authoring a cognitive model is difficult. Secondly, for domains where a cognitive model is available, we show that representations learned through CogRL can be used to get accurate estimates of skill difficulty and learning rate parameters without using any student performance data. These estimates are shown to highly correlate with estimates using student performance data on an Article Selection dataset.