 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Proximal Policy Optimization's Heavy-tailed Gradients
Feb 20, 2021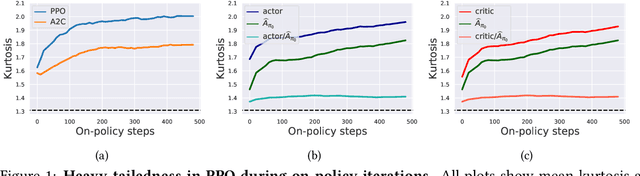
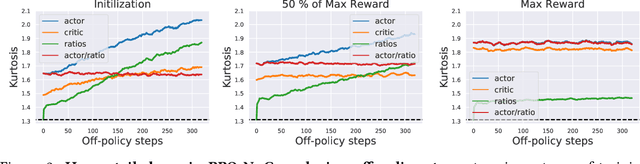
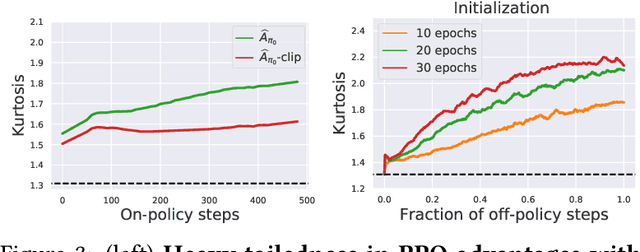
Modern policy gradient algorithms, notably Proximal Policy Optimization (PPO), rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.
Reasoning Over Virtual Knowledge Bases With Open Predicate Relations
Feb 14, 2021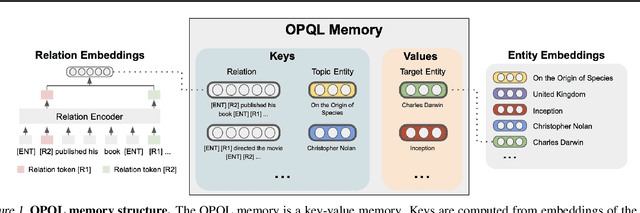
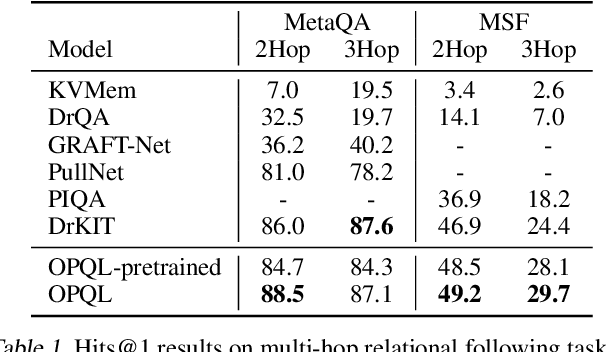
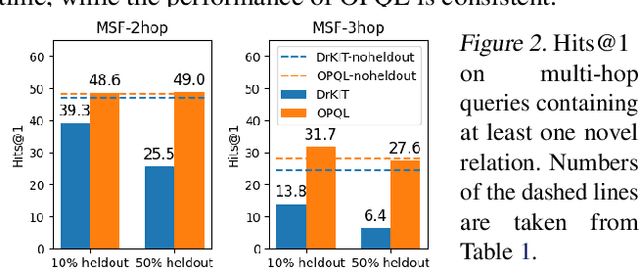
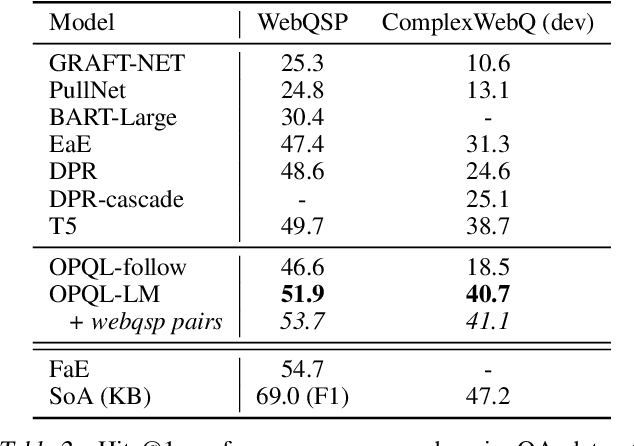
We present the Open Predicate Query Language (OPQL); a method for constructing a virtual KB (VKB) trained entirely from text. Large Knowledge Bases (KBs) are indispensable for a wide-range of industry applications such as question answering and recommendation. Typically, KBs encode world knowledge in a structured, readily accessible form derived from laborious human annotation efforts. Unfortunately, while they are extremely high precision, KBs are inevitably highly incomplete and automated methods for enriching them are far too inaccurate. Instead, OPQL constructs a VKB by encoding and indexing a set of relation mentions in a way that naturally enables reasoning and can be trained without any structured supervision. We demonstrate that OPQL outperforms prior VKB methods on two different KB reasoning tasks and, additionally, can be used as an external memory integrated into a language model (OPQL-LM) leading to improvements on two open-domain question answering tasks.
The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
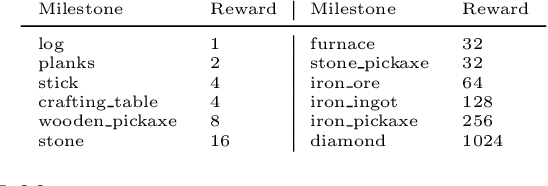
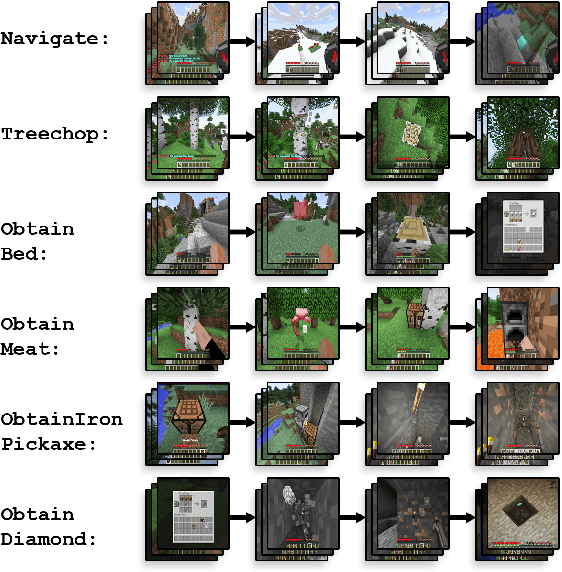
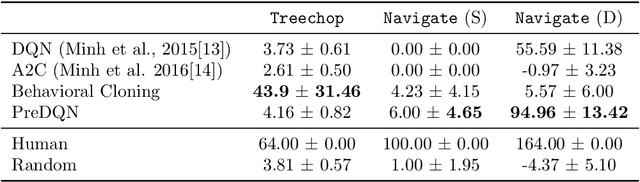
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
Understanding the Tradeoffs in Client-Side Privacy for Speech Recognition
Jan 22, 2021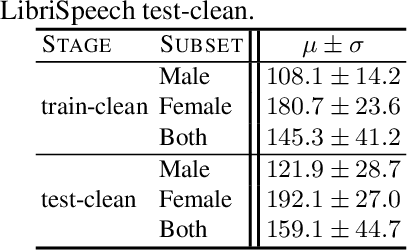
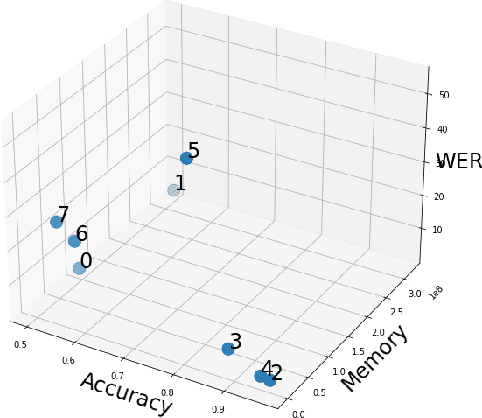
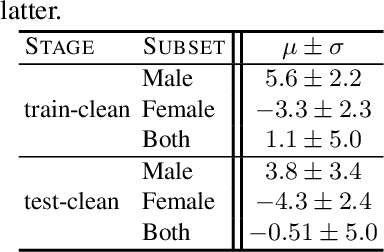
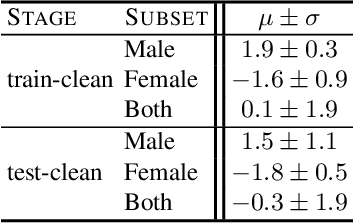
Existing approaches to ensuring privacy of user speech data primarily focus on server-side approaches. While improving server-side privacy reduces certain security concerns, users still do not retain control over whether privacy is ensured on the client-side. In this paper, we define, evaluate, and explore techniques for client-side privacy in speech recognition, where the goal is to preserve privacy on raw speech data before leaving the client's device. We first formalize several tradeoffs in ensuring client-side privacy between performance, compute requirements, and privacy. Using our tradeoff analysis, we perform a large-scale empirical study on existing approaches and find that they fall short on at least one metric. Our results call for more research in this crucial area as a step towards safer real-world deployment of speech recognition systems at scale across mobile devices.
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020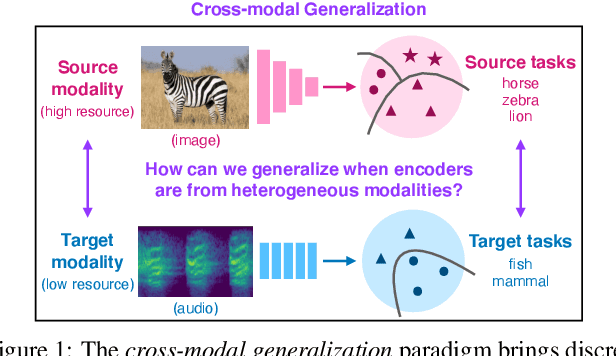
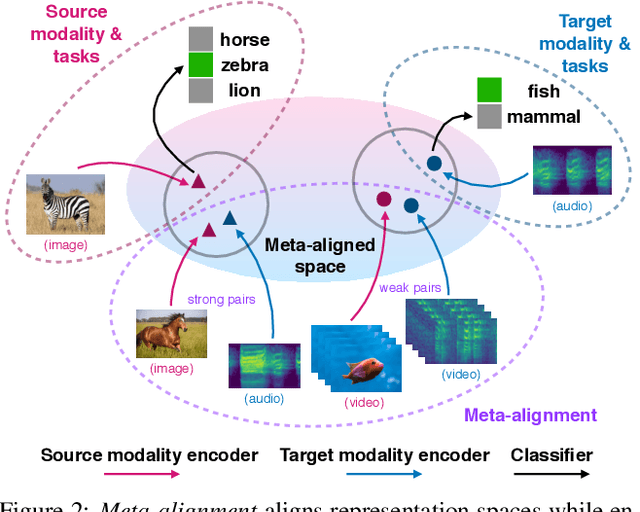
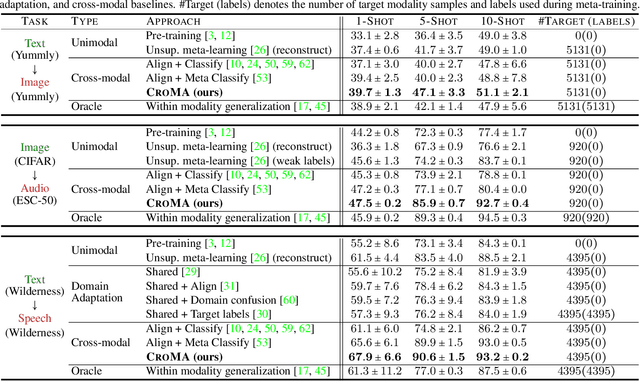
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
C-Learning: Learning to Achieve Goals via Recursive Classification
Nov 17, 2020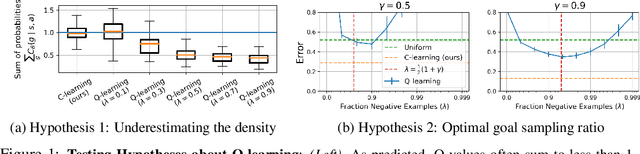
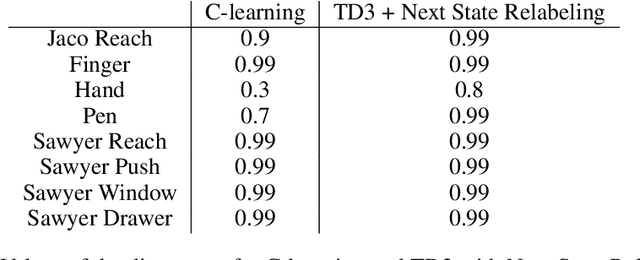
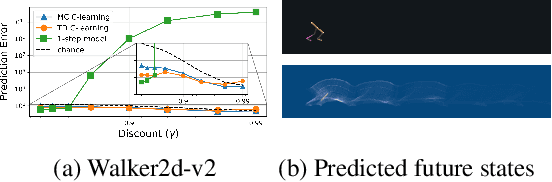
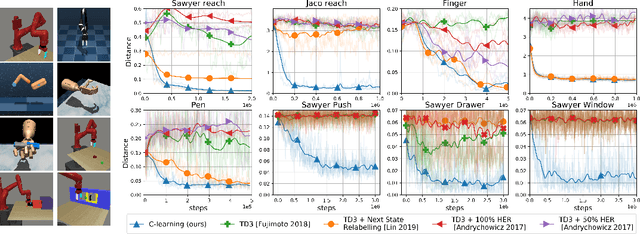
We study the problem of predicting and controlling the future state distribution of an autonomous agent. This problem, which can be viewed as a reframing of goal-conditioned reinforcement learning (RL), is centered around learning a conditional probability density function over future states. Instead of directly estimating this density function, we indirectly estimate this density function by training a classifier to predict whether an observation comes from the future. Via Bayes' rule, predictions from our classifier can be transformed into predictions over future states. Importantly, an off-policy variant of our algorithm allows us to predict the future state distribution of a new policy, without collecting new experience. This variant allows us to optimize functionals of a policy's future state distribution, such as the density of reaching a particular goal state. While conceptually similar to Q-learning, our work lays a principled foundation for goal-conditioned RL as density estimation, providing justification for goal-conditioned methods used in prior work. This foundation makes hypotheses about Q-learning, including the optimal goal-sampling ratio, which we confirm experimentally. Moreover, our proposed method is competitive with prior goal-conditioned RL methods.
Close Category Generalization
Nov 17, 2020
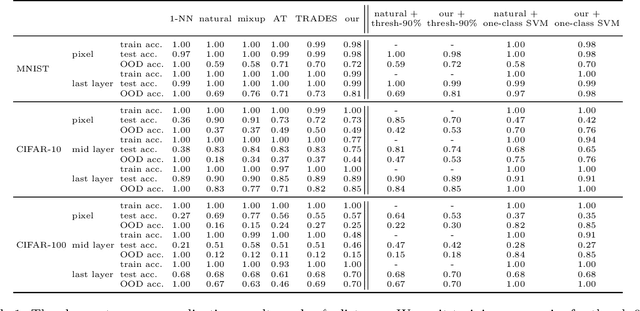
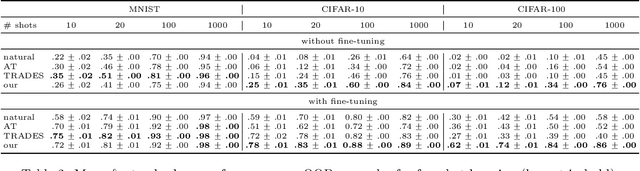
Out-of-distribution generalization is a core challenge in machine learning. We introduce and propose a solution to a new type of out-of-distribution evaluation, which we call close category generalization. This task specifies how a classifier should extrapolate to unseen classes by considering a bi-criteria objective: (i) on in-distribution examples, output the correct label, and (ii) on out-of-distribution examples, output the label of the nearest neighbor in the training set. In addition to formalizing this problem, we present a new training algorithm to improve the close category generalization of neural networks. We compare to many baselines, including robust algorithms and out-of-distribution detection methods, and we show that our method has better or comparable close category generalization. Then, we investigate a related representation learning task, and we find that performing well on close category generalization correlates with learning a good representation of an unseen class and with finding a good initialization for few-shot learning. Code available at https://github.com/yangarbiter/close-category-generalization
Unsupervised Domain Adaptation for Visual Navigation
Nov 12, 2020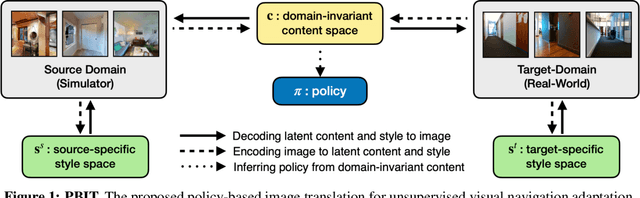
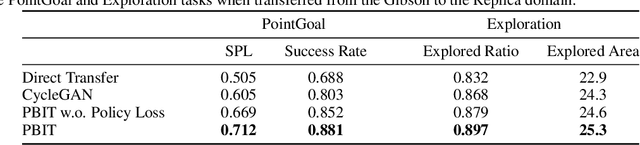

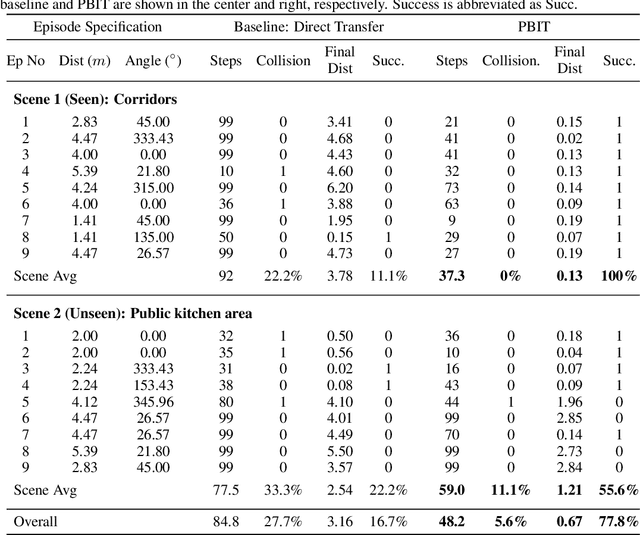
Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
Planning with Submodular Objective Functions
Oct 22, 2020
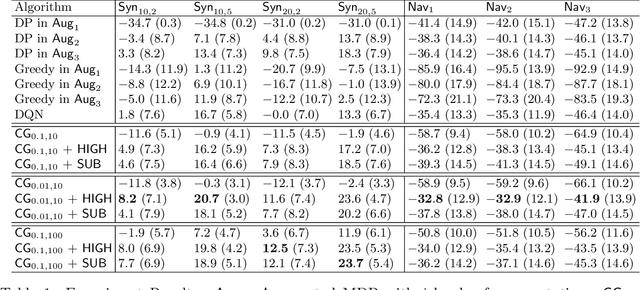

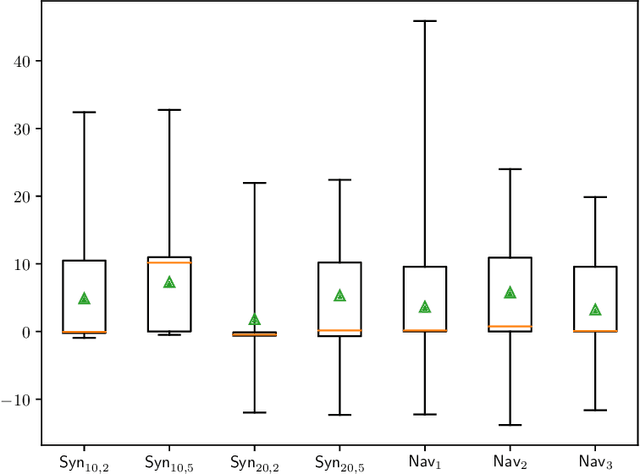
We study planning with submodular objective functions, where instead of maximizing the cumulative reward, the goal is to maximize the objective value induced by a submodular function. Our framework subsumes standard planning and submodular maximization with cardinality constraints as special cases, and thus many practical applications can be naturally formulated within our framework. Based on the notion of multilinear extension, we propose a novel and theoretically principled algorithmic framework for planning with submodular objective functions, which recovers classical algorithms when applied to the two special cases mentioned above. Empirically, our approach significantly outperforms baseline algorithms on synthetic environments and navigation tasks.
Case Study: Deontological Ethics in NLP
Oct 09, 2020
Recent work in natural language processing (NLP) has focused on ethical challenges such as understanding and mitigating bias in data and algorithms; identifying objectionable content like hate speech, stereotypes and offensive language; and building frameworks for better system design and data handling practices. However, there has been little discussion about the ethical foundations that underlie these efforts. In this work, we study one ethical theory, namely deontological ethics, from the perspective of NLP. In particular, we focus on the generalization principle and the respect for autonomy through informed consent. We provide four case studies to demonstrate how these principles can be used with NLP systems. We also recommend directions to avoid the ethical issues in these systems.