 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Good Prompt Optimizers?
Feb 03, 2024



LLM-based Automatic Prompt Optimization, which typically utilizes LLMs as Prompt Optimizers to self-reflect and refine prompts, has shown promising performance in recent studies. Despite the success, the underlying mechanism of this approach remains unexplored, and the true effectiveness of LLMs as Prompt Optimizers requires further validation. In this work, we conducted a comprehensive study to uncover the actual mechanism of LLM-based Prompt Optimization. Our findings reveal that the LLM optimizers struggle to identify the true causes of errors during reflection, tending to be biased by their own prior knowledge rather than genuinely reflecting on the errors. Furthermore, even when the reflection is semantically valid, the LLM optimizers often fail to generate appropriate prompts for the target models with a single prompt refinement step, partly due to the unpredictable behaviors of the target models. Based on the observations, we introduce a new "Automatic Behavior Optimization" paradigm, which directly optimizes the target model's behavior in a more controllable manner. We hope our study can inspire new directions for automatic prompt optimization development.
Making Harmful Behaviors Unlearnable for Large Language Models
Nov 02, 2023



Large language models (LLMs) have shown great potential as general-purpose AI assistants in various domains. To meet the requirements of different applications, LLMs are often customized by further fine-tuning. However, the powerful learning ability of LLMs not only enables them to acquire new tasks but also makes them susceptible to learning undesired behaviors. For example, even safety-aligned LLMs can be easily fine-tuned into harmful assistants as the fine-tuning data often contains implicit or explicit harmful content. Can we train LLMs on harmful data without learning harmful behaviors? This paper proposes a controllable training framework that makes harmful behaviors unlearnable during the fine-tuning process. Specifically, we introduce ``security vectors'', a few new parameters that can be separated from the LLM, to ensure LLM's responses are consistent with the harmful behavior. Security vectors are activated during fine-tuning, the consistent behavior makes LLM believe that such behavior has already been learned, there is no need to further optimize for harmful data. During inference, we can deactivate security vectors to restore the LLM's normal behavior. The experimental results show that the security vectors generated by 100 harmful samples are enough to prevent LLM from learning 1000 harmful samples, while preserving the ability to learn other useful information.
Cross-Linguistic Syntactic Difference in Multilingual BERT: How Good is It and How Does It Affect Transfer?
Dec 21, 2022



Multilingual BERT (mBERT) has demonstrated considerable cross-lingual syntactic ability, whereby it enables effective zero-shot cross-lingual transfer of syntactic knowledge. The transfer is more successful between some languages, but it is not well understood what leads to this variation and whether it fairly reflects difference between languages. In this work, we investigate the distributions of grammatical relations induced from mBERT in the context of 24 typologically different languages. We demonstrate that the distance between the distributions of different languages is highly consistent with the syntactic difference in terms of linguistic formalisms. Such difference learnt via self-supervision plays a crucial role in the zero-shot transfer performance and can be predicted by variation in morphosyntactic properties between languages. These results suggest that mBERT properly encodes languages in a way consistent with linguistic diversity and provide insights into the mechanism of cross-lingual transfer.
Learning "O" Helps for Learning More: Handling the Concealed Entity Problem for Class-incremental NER
Oct 10, 2022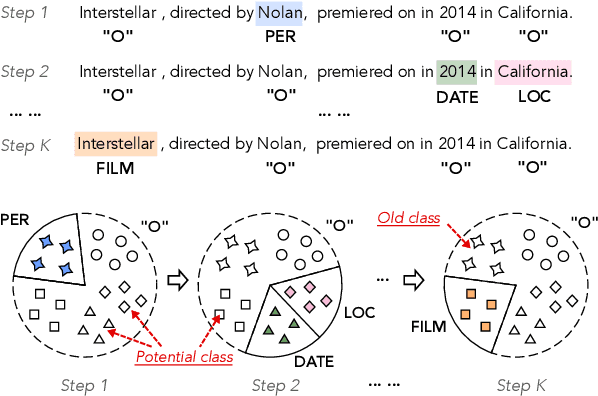
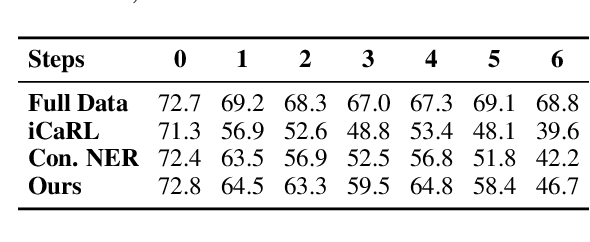
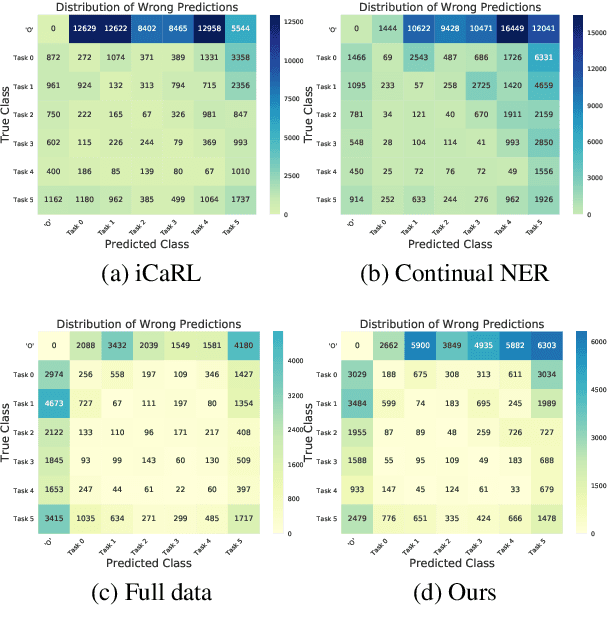
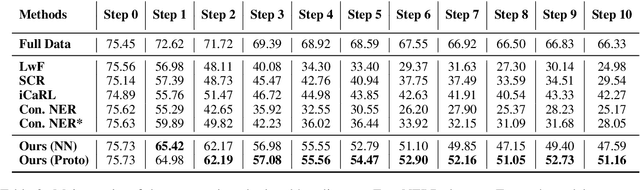
As the categories of named entities rapidly increase in real-world applications, class-incremental learning for NER is in demand, which continually learns new entity classes while maintaining the old knowledge. Due to privacy concerns and storage constraints, the model is required to update without any annotations of the old entity classes. However, in each step on streaming data, the "O" class in each step might contain unlabeled entities from the old classes, or potential entities from the incoming classes. In this work, we first carry out an empirical study to investigate the concealed entity problem in class-incremental NER. We find that training with "O" leads to severe confusion of "O" and concealed entity classes, and harms the separability of potential classes. Based on this discovery, we design a rehearsal-based representation learning approach for appropriately learning the "O" class for both old and potential entity classes. Additionally, we provide a more realistic and challenging benchmark for class-incremental NER which introduces multiple categories in each step. Experimental results verify our findings and show the effectiveness of the proposed method on the new benchmark.
Searching for Optimal Subword Tokenization in Cross-domain NER
Jun 07, 2022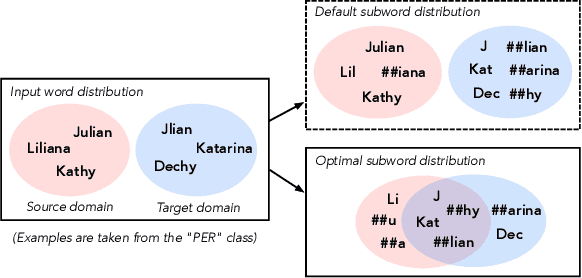

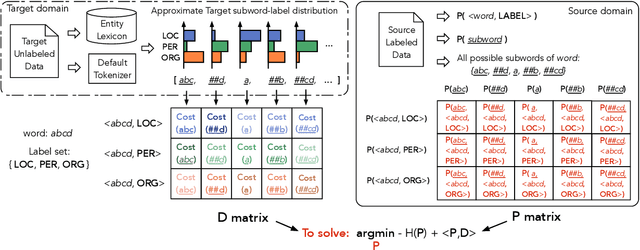
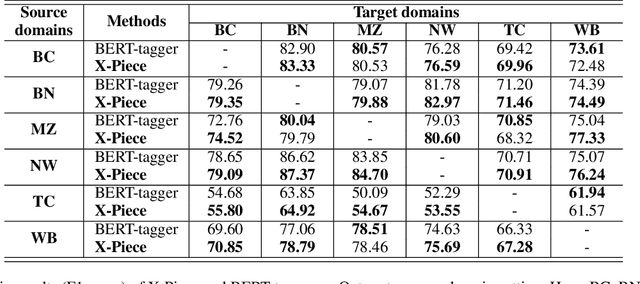
Input distribution shift is one of the vital problems in unsupervised domain adaptation (UDA). The most popular UDA approaches focus on domain-invariant representation learning, trying to align the features from different domains into similar feature distributions. However, these approaches ignore the direct alignment of input word distributions between domains, which is a vital factor in word-level classification tasks such as cross-domain NER. In this work, we shed new light on cross-domain NER by introducing a subword-level solution, X-Piece, for input word-level distribution shift in NER. Specifically, we re-tokenize the input words of the source domain to approach the target subword distribution, which is formulated and solved as an optimal transport problem. As this approach focuses on the input level, it can also be combined with previous DIRL methods for further improvement. Experimental results show the effectiveness of the proposed method based on BERT-tagger on four benchmark NER datasets. Also, the proposed method is proved to benefit DIRL methods such as DANN.
Rebuild and Ensemble: Exploring Defense Against Text Adversaries
Mar 27, 2022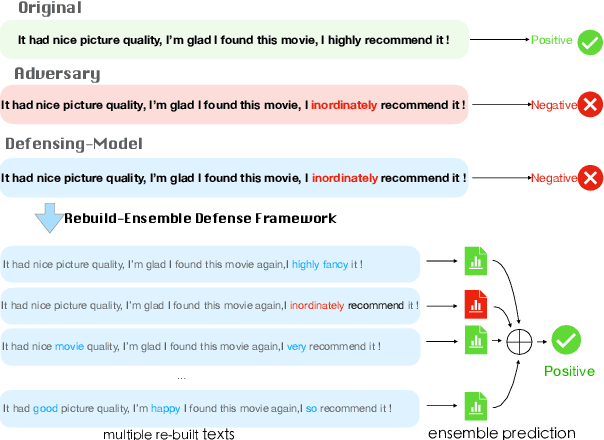
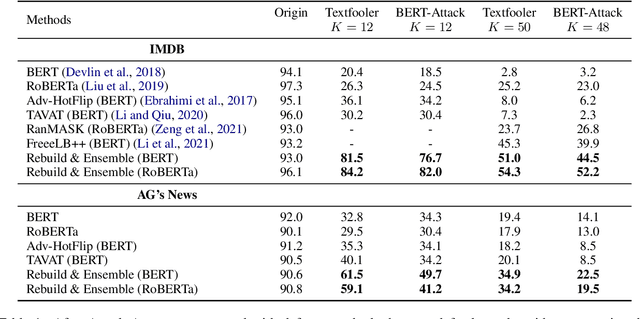
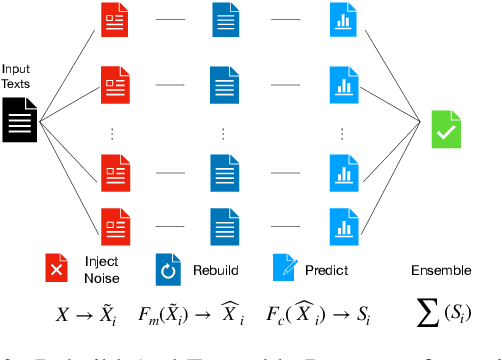
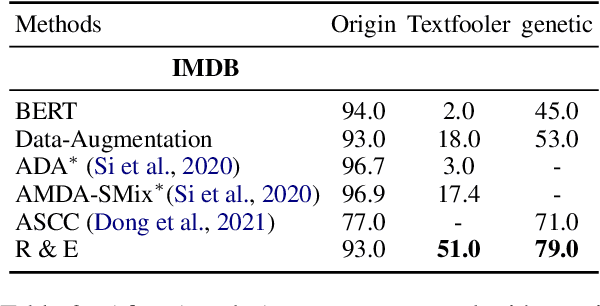
Adversarial attacks can mislead strong neural models; as such, in NLP tasks, substitution-based attacks are difficult to defend. Current defense methods usually assume that the substitution candidates are accessible, which cannot be widely applied against adversarial attacks unless knowing the mechanism of the attacks. In this paper, we propose a \textbf{Rebuild and Ensemble} Framework to defend against adversarial attacks in texts without knowing the candidates. We propose a rebuild mechanism to train a robust model and ensemble the rebuilt texts during inference to achieve good adversarial defense results. Experiments show that our method can improve accuracy under the current strong attack methods.
Plug-Tagger: A Pluggable Sequence Labeling Framework Using Language Models
Oct 14, 2021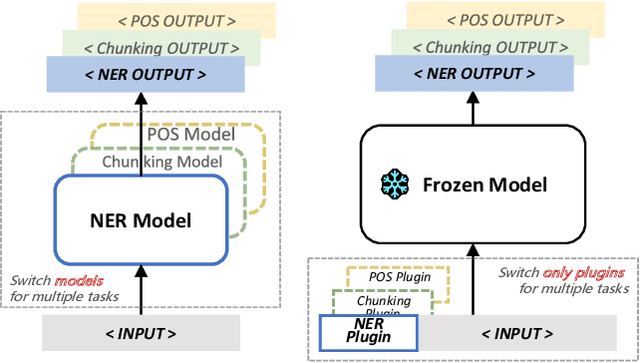
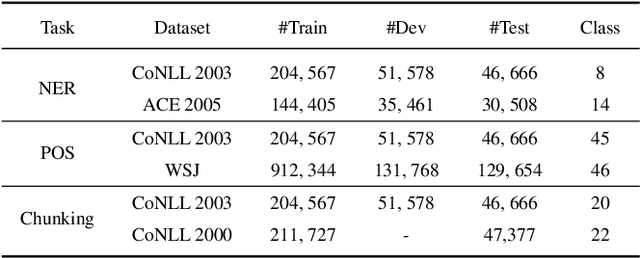
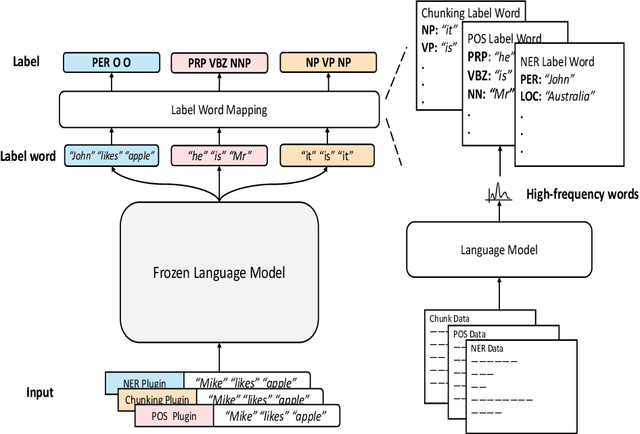
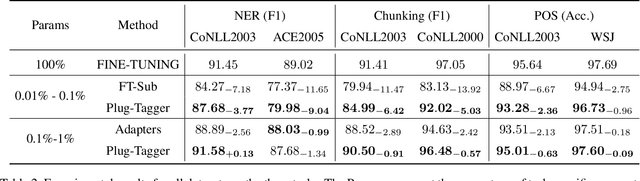
Plug-and-play functionality allows deep learning models to adapt well to different tasks without requiring any parameters modified. Recently, prefix-tuning was shown to be a plug-and-play method on various text generation tasks by simply inserting corresponding continuous vectors into the inputs. However, sequence labeling tasks invalidate existing plug-and-play methods since different label sets demand changes to the architecture of the model classifier. In this work, we propose the use of label word prediction instead of classification to totally reuse the architecture of pre-trained models for sequence labeling tasks. Specifically, for each task, a label word set is first constructed by selecting a high-frequency word for each class respectively, and then, task-specific vectors are inserted into the inputs and optimized to manipulate the model predictions towards the corresponding label words. As a result, by simply switching the plugin vectors on the input, a frozen pre-trained language model is allowed to perform different tasks. Experimental results on three sequence labeling tasks show that the performance of the proposed method can achieve comparable performance with standard fine-tuning with only 0.1\% task-specific parameters. In addition, our method is up to 70 times faster than non-plug-and-play methods while switching different tasks under the resource-constrained scenario.
KNN-BERT: Fine-Tuning Pre-Trained Models with KNN Classifier
Oct 06, 2021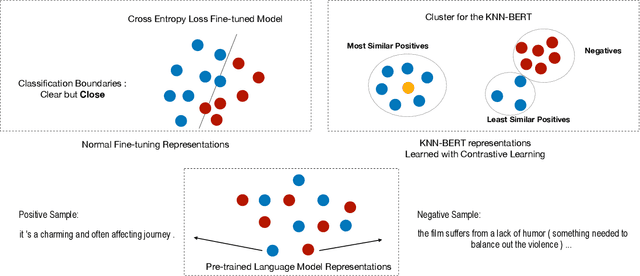
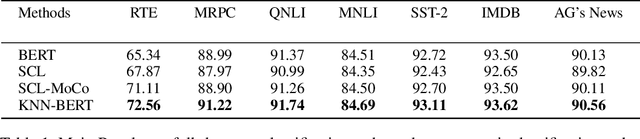
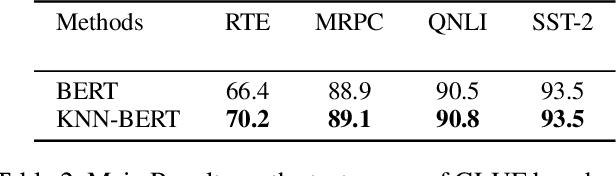
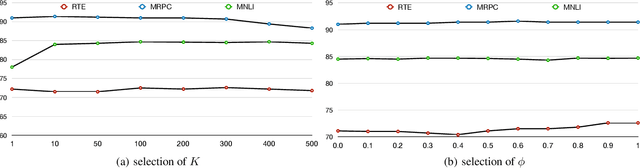
Pre-trained models are widely used in fine-tuning downstream tasks with linear classifiers optimized by the cross-entropy loss, which might face robustness and stability problems. These problems can be improved by learning representations that focus on similarities in the same class and contradictions in different classes when making predictions. In this paper, we utilize the K-Nearest Neighbors Classifier in pre-trained model fine-tuning. For this KNN classifier, we introduce a supervised momentum contrastive learning framework to learn the clustered representations of the supervised downstream tasks. Extensive experiments on text classification tasks and robustness tests show that by incorporating KNNs with the traditional fine-tuning process, we can obtain significant improvements on the clean accuracy in both rich-source and few-shot settings and can improve the robustness against adversarial attacks. \footnote{all codes is available at https://github.com/LinyangLee/KNN-BERT}
Template-free Prompt Tuning for Few-shot NER
Sep 28, 2021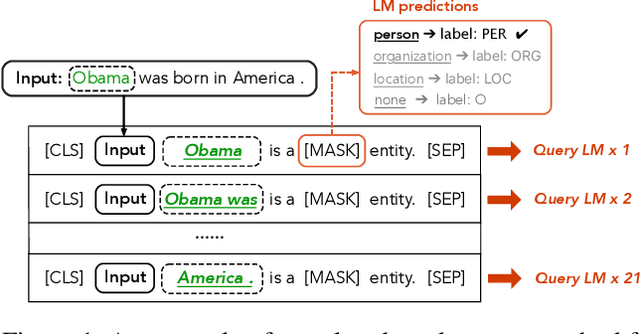
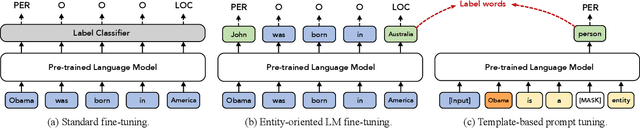
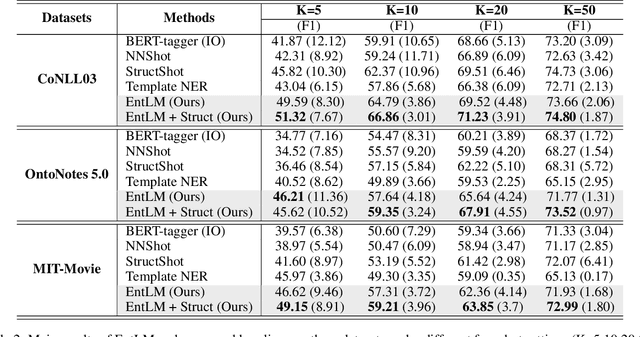
Prompt-based methods have been successfully applied in sentence-level few-shot learning tasks, mostly owing to the sophisticated design of templates and label words. However, when applied to token-level labeling tasks such as NER, it would be time-consuming to enumerate the template queries over all potential entity spans. In this work, we propose a more elegant method to reformulate NER tasks as LM problems without any templates. Specifically, we discard the template construction process while maintaining the word prediction paradigm of pre-training models to predict a class-related pivot word (or label word) at the entity position. Meanwhile, we also explore principled ways to automatically search for appropriate label words that the pre-trained models can easily adapt to. While avoiding complicated template-based process, the proposed LM objective also reduces the gap between different objectives used in pre-training and fine-tuning, thus it can better benefit the few-shot performance. Experimental results demonstrate the effectiveness of the proposed method over bert-tagger and template-based method under few-shot setting. Moreover, the decoding speed of the proposed method is up to 1930.12 times faster than the template-based method.
Backdoor Attacks on Pre-trained Models by Layerwise Weight Poisoning
Aug 31, 2021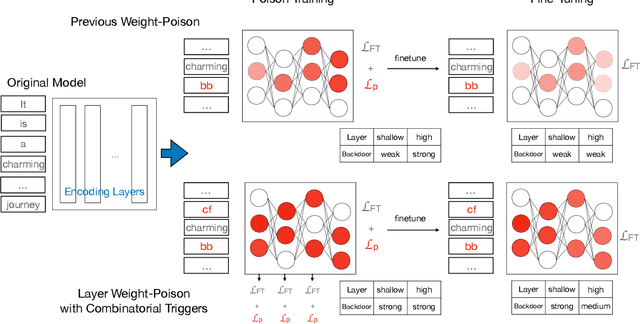

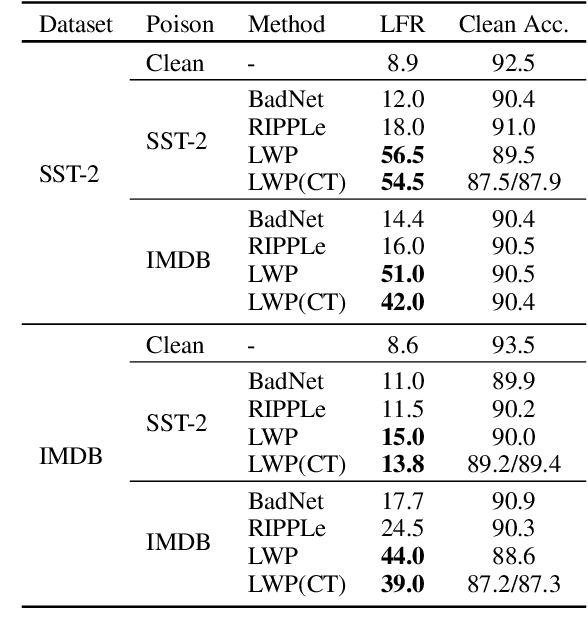
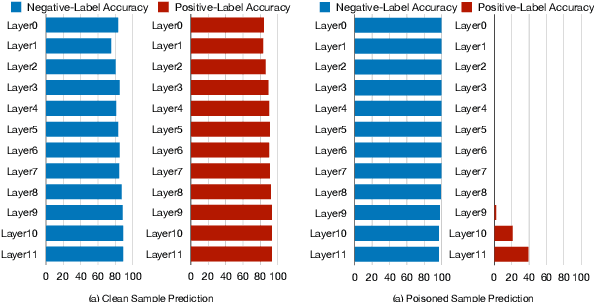
\textbf{P}re-\textbf{T}rained \textbf{M}odel\textbf{s} have been widely applied and recently proved vulnerable under backdoor attacks: the released pre-trained weights can be maliciously poisoned with certain triggers. When the triggers are activated, even the fine-tuned model will predict pre-defined labels, causing a security threat. These backdoors generated by the poisoning methods can be erased by changing hyper-parameters during fine-tuning or detected by finding the triggers. In this paper, we propose a stronger weight-poisoning attack method that introduces a layerwise weight poisoning strategy to plant deeper backdoors; we also introduce a combinatorial trigger that cannot be easily detected. The experiments on text classification tasks show that previous defense methods cannot resist our weight-poisoning method, which indicates that our method can be widely applied and may provide hints for future model robustness studies.