 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUC-NeRF: Uncertainty-aware Conditional Neural Radiance Fields from Endoscopic Sparse Views
Sep 04, 2024Visualizing surgical scenes is crucial for revealing internal anatomical structures during minimally invasive procedures. Novel View Synthesis is a vital technique that offers geometry and appearance reconstruction, enhancing understanding, planning, and decision-making in surgical scenes. Despite the impressive achievements of Neural Radiance Field (NeRF), its direct application to surgical scenes produces unsatisfying results due to two challenges: endoscopic sparse views and significant photometric inconsistencies. In this paper, we propose uncertainty-aware conditional NeRF for novel view synthesis to tackle the severe shape-radiance ambiguity from sparse surgical views. The core of UC-NeRF is to incorporate the multi-view uncertainty estimation to condition the neural radiance field for modeling the severe photometric inconsistencies adaptively. Specifically, our UC-NeRF first builds a consistency learner in the form of multi-view stereo network, to establish the geometric correspondence from sparse views and generate uncertainty estimation and feature priors. In neural rendering, we design a base-adaptive NeRF network to exploit the uncertainty estimation for explicitly handling the photometric inconsistencies. Furthermore, an uncertainty-guided geometry distillation is employed to enhance geometry learning. Experiments on the SCARED and Hamlyn datasets demonstrate our superior performance in rendering appearance and geometry, consistently outperforming the current state-of-the-art approaches. Our code will be released at \url{https://github.com/wrld/UC-NeRF}.
Enhanced Scale-aware Depth Estimation for Monocular Endoscopic Scenes with Geometric Modeling
Aug 14, 2024



Scale-aware monocular depth estimation poses a significant challenge in computer-aided endoscopic navigation. However, existing depth estimation methods that do not consider the geometric priors struggle to learn the absolute scale from training with monocular endoscopic sequences. Additionally, conventional methods face difficulties in accurately estimating details on tissue and instruments boundaries. In this paper, we tackle these problems by proposing a novel enhanced scale-aware framework that only uses monocular images with geometric modeling for depth estimation. Specifically, we first propose a multi-resolution depth fusion strategy to enhance the quality of monocular depth estimation. To recover the precise scale between relative depth and real-world values, we further calculate the 3D poses of instruments in the endoscopic scenes by algebraic geometry based on the image-only geometric primitives (i.e., boundaries and tip of instruments). Afterwards, the 3D poses of surgical instruments enable the scale recovery of relative depth maps. By coupling scale factors and relative depth estimation, the scale-aware depth of the monocular endoscopic scenes can be estimated. We evaluate the pipeline on in-house endoscopic surgery videos and simulated data. The results demonstrate that our method can learn the absolute scale with geometric modeling and accurately estimate scale-aware depth for monocular scenes.
Autonomous Intelligent Navigation for Flexible Endoscopy Using Monocular Depth Guidance and 3-D Shape Planning
Feb 26, 2023



Recent advancements toward perception and decision-making of flexible endoscopes have shown great potential in computer-aided surgical interventions. However, owing to modeling uncertainty and inter-patient anatomical variation in flexible endoscopy, the challenge remains for efficient and safe navigation in patient-specific scenarios. This paper presents a novel data-driven framework with self-contained visual-shape fusion for autonomous intelligent navigation of flexible endoscopes requiring no priori knowledge of system models and global environments. A learning-based adaptive visual servoing controller is proposed to online update the eye-in-hand vision-motor configuration and steer the endoscope, which is guided by monocular depth estimation via a vision transformer (ViT). To prevent unnecessary and excessive interactions with surrounding anatomy, an energy-motivated shape planning algorithm is introduced through entire endoscope 3-D proprioception from embedded fiber Bragg grating (FBG) sensors. Furthermore, a model predictive control (MPC) strategy is developed to minimize the elastic potential energy flow and simultaneously optimize the steering policy. Dedicated navigation experiments on a robotic-assisted flexible endoscope with an FBG fiber in several phantom environments demonstrate the effectiveness and adaptability of the proposed framework.
Distilled Visual and Robot Kinematics Embeddings for Metric Depth Estimation in Monocular Scene Reconstruction
Nov 27, 2022



Estimating precise metric depth and scene reconstruction from monocular endoscopy is a fundamental task for surgical navigation in robotic surgery. However, traditional stereo matching adopts binocular images to perceive the depth information, which is difficult to transfer to the soft robotics-based surgical systems due to the use of monocular endoscopy. In this paper, we present a novel framework that combines robot kinematics and monocular endoscope images with deep unsupervised learning into a single network for metric depth estimation and then achieve 3D reconstruction of complex anatomy. Specifically, we first obtain the relative depth maps of surgical scenes by leveraging a brightness-aware monocular depth estimation method. Then, the corresponding endoscope poses are computed based on non-linear optimization of geometric and photometric reprojection residuals. Afterwards, we develop a Depth-driven Sliding Optimization (DDSO) algorithm to extract the scaling coefficient from kinematics and calculated poses offline. By coupling the metric scale and relative depth data, we form a robust ensemble that represents the metric and consistent depth. Next, we treat the ensemble as supervisory labels to train a metric depth estimation network for surgeries (i.e., MetricDepthS-Net) that distills the embeddings from the robot kinematics, endoscopic videos, and poses. With accurate metric depth estimation, we utilize a dense visual reconstruction method to recover the 3D structure of the whole surgical site. We have extensively evaluated the proposed framework on public SCARED and achieved comparable performance with stereo-based depth estimation methods. Our results demonstrate the feasibility of the proposed approach to recover the metric depth and 3D structure with monocular inputs.
3D Perception based Imitation Learning under Limited Demonstration for Laparoscope Control in Robotic Surgery
Apr 07, 2022
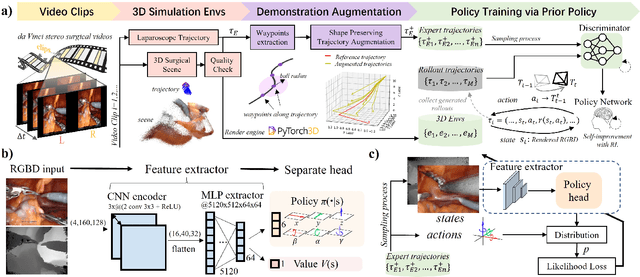
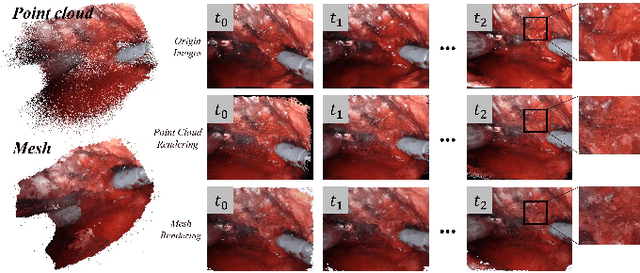
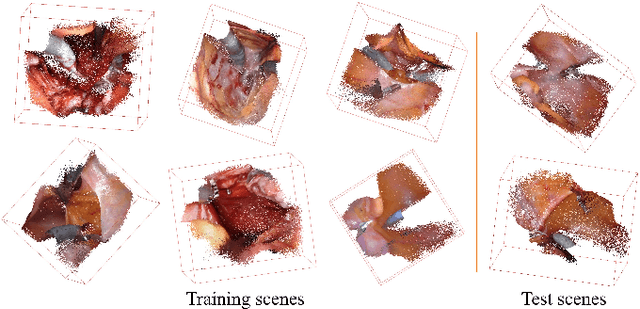
Automatic laparoscope motion control is fundamentally important for surgeons to efficiently perform operations. However, its traditional control methods based on tool tracking without considering information hidden in surgical scenes are not intelligent enough, while the latest supervised imitation learning (IL)-based methods require expensive sensor data and suffer from distribution mismatch issues caused by limited demonstrations. In this paper, we propose a novel Imitation Learning framework for Laparoscope Control (ILLC) with reinforcement learning (RL), which can efficiently learn the control policy from limited surgical video clips. Specially, we first extract surgical laparoscope trajectories from unlabeled videos as the demonstrations and reconstruct the corresponding surgical scenes. To fully learn from limited motion trajectory demonstrations, we propose Shape Preserving Trajectory Augmentation (SPTA) to augment these data, and build a simulation environment that supports parallel RGB-D rendering to reinforce the RL policy for interacting with the environment efficiently. With adversarial training for IL, we obtain the laparoscope control policy based on the generated rollouts and surgical demonstrations. Extensive experiments are conducted in unseen reconstructed surgical scenes, and our method outperforms the previous IL methods, which proves the feasibility of our unified learning-based framework for laparoscope control.
Stereo Dense Scene Reconstruction and Accurate Laparoscope Localization for Learning-Based Navigation in Robot-Assisted Surgery
Oct 08, 2021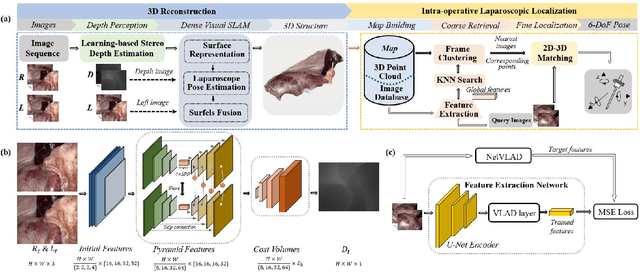
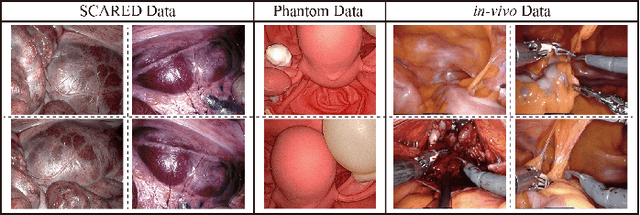
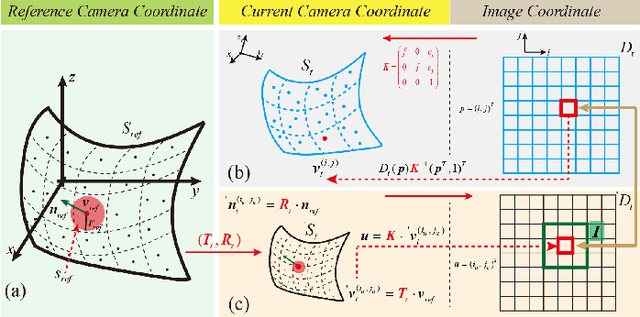
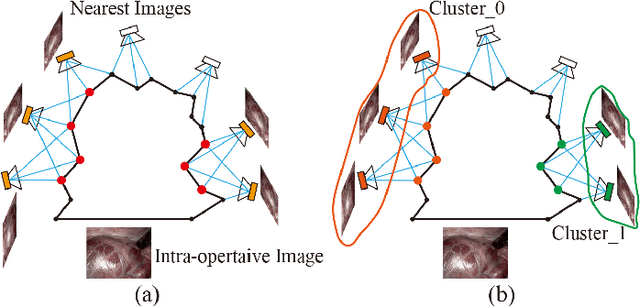
The computation of anatomical information and laparoscope position is a fundamental block of robot-assisted surgical navigation in Minimally Invasive Surgery (MIS). Recovering a dense 3D structure of surgical scene using visual cues remains a challenge, and the online laparoscopic tracking mostly relies on external sensors, which increases system complexity. In this paper, we propose a learning-driven framework, in which an image-guided laparoscopic localization with 3D reconstructions of complex anatomical structures is hereby achieved. To reconstruct the 3D structure of the whole surgical environment, we first fine-tune a learning-based stereoscopic depth perception method, which is robust to the texture-less and variant soft tissues, for depth estimation. Then, we develop a dense visual reconstruction algorithm to represent the scene by surfels, estimate the laparoscope pose and fuse the depth data into a unified reference coordinate for tissue reconstruction. To estimate poses of new laparoscope views, we realize a coarse-to-fine localization method, which incorporates our reconstructed 3D model. We evaluate the reconstruction method and the localization module on three datasets, namely, the stereo correspondence and reconstruction of endoscopic data (SCARED), the ex-vivo phantom and tissue data collected with Universal Robot (UR) and Karl Storz Laparoscope, and the in-vivo DaVinci robotic surgery dataset. Extensive experiments have been conducted to prove the superior performance of our method in 3D anatomy reconstruction and laparoscopic localization, which demonstrates its potential implementation to surgical navigation system.